






1.Standalone运行模式(单机版,仅仅依靠Flink包就可以运行)
Standalone就是flink自己运行,不依赖第三方的集群资源
在本地Windows开发环境里面运行的,就是Standalone运行模式
运行起来之后,我们可以通过localhost查看job的运行情况

写这个代码才能启动ui界面
JobManager:作业管理者
TaskManager:工作节点
FlinkClient:提交job
任务管理器

任务槽 :并行度,越多越好

正在运行的作业
job的一个流程:source(数据源)-> transform转换(map、flatmap、filter等)->keyBy、Aggregate(聚合)-> sink(输出:Print输出到控制台、kafka、Mysql、文件、Es)
并行度(parallelism):一个任务交给多个cpu并行处理,一台计算机最大并行度就是这台计算机的cpu的核数
可以在代码中设置并行度:

2.提交到集群里面,用standalone去运行
虚拟机运行standalone得执行以下命令
![]()
Yarn运行模式 (动态分配资源调度)
Flink会根据运行jobManger上得作业所需要得slot数量动态分配
Yarn部署过程:客户端把Flink应用提交给yarn的
首先要启动haddop集群:hdp.sh start
接着要启动历史服务器:bin/historyserver.sh start
在linux中yarn打包启动flink任务:
输入以下命令
![]()
bin/flink run-application -t yarn-application -c com.bw.wcDemo ./Demos/
Flink1.17-1.0-SNAPSHOT.jar
bin/flink list -t yarn-application -Dyarn.application.id=c961721caaecf8222ca3656535089d89
bin/flink cancel -t yarn-application -Dyarn.application.id=任务id 后面还得跟 上一步输出得id
bin/flink cancel -t yarn-application -Dyarn.application.id=application_1710301172371_0003
数据源
第一种:

第二种:DataGen


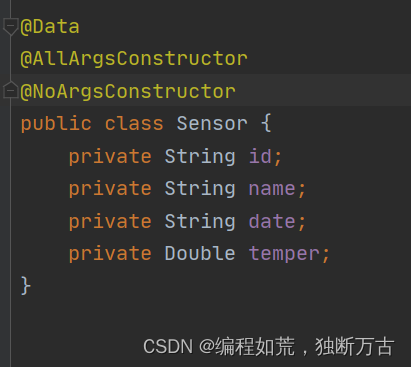
如果dataGen不加无参构造就会报错















 881
881











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









