







青衿之志
履践致远
堆排序(Heapsort) 是指利用 堆 这种数据结构所设计的一种排序算法,它是 选择排序 的一种。它是通过堆来进行选择数据。需要注意的是排升序要建大堆,排降序建小堆。
🎥二叉堆
🎥二叉树
🔥期待小伙伴们的支持与关注
目录

堆的创建
堆创建的方法
下面我们给出一个数组,这个数组逻辑上可以看做一颗完全二叉树,但是还不是一个堆,现在我们通过算法,把它构建成一个堆。
int a[] = {1,5,3,8,7,6};我们一般采用 从下往上 建堆的方法,采用 向下调整 算法来建堆:
从倒数的 第一个非叶子节点的子树 开始调整,一直调整到 根节点 的树,就可以调整成堆
建堆的时间复杂度
因为堆是完全二叉树,而满二叉树也是完全二叉树,此处为了 简化 使用满二叉树来证明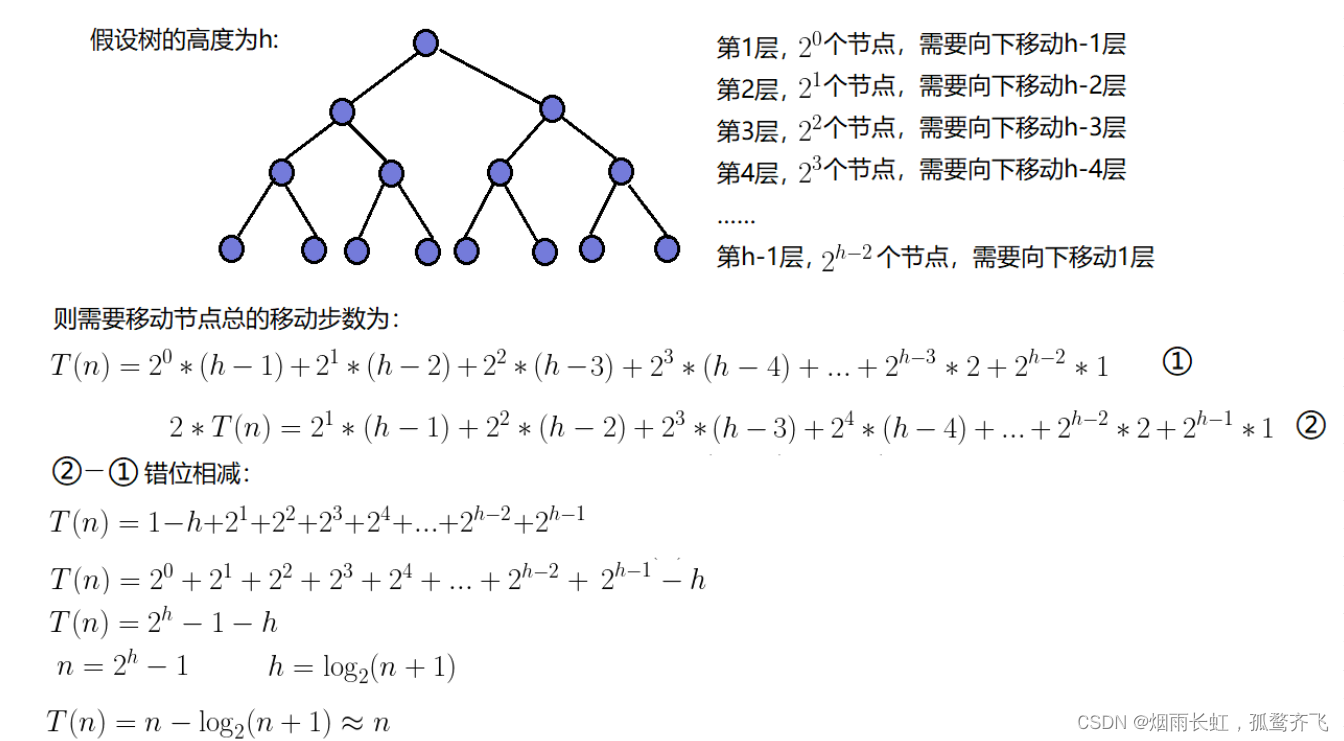
叶子节点不需要堆化,所以需要堆化的节点从倒数第二层开始
每个节点堆化的过程中,需要 比较 和 交换 的节点个数,跟这个节点的高度 h 成正比
我们只需要将 每个节点的高度求和 ,得出的就是建堆的时间复杂度
因为是 等比 数列,我们可以用 错位相减法 计算时间复杂度所以建堆的时间复杂度为 O(n)for (int i = (n - 1 - 1) / 2; i >= 0; i--) { AdjustDown(arr, n, i); }这里的 (n - 1 - 1) / 2, n-1 表示下标,其次是套公式 parent = (child-1) /2
求出 第一个非叶子节点的子树 并开始向下调整
向下调整算法
void AdjustDown(int* data, int n, int parent) { int child = parent * 2 + 1; while (child < n) { if (child + 1 < n && data[child + 1] > data[child]) { child++; } if (data[child] > data[parent]) { Swap(&data[child], &data[parent]); parent = child; child = parent * 2 + 1; } else { break; } } }我们这里采用了 大根堆 的算法,目的是为了 排升序
为啥排升序需要大根堆呢?
int a[] = {1,5,3,8,7,6};我们还是以这个树为栗子
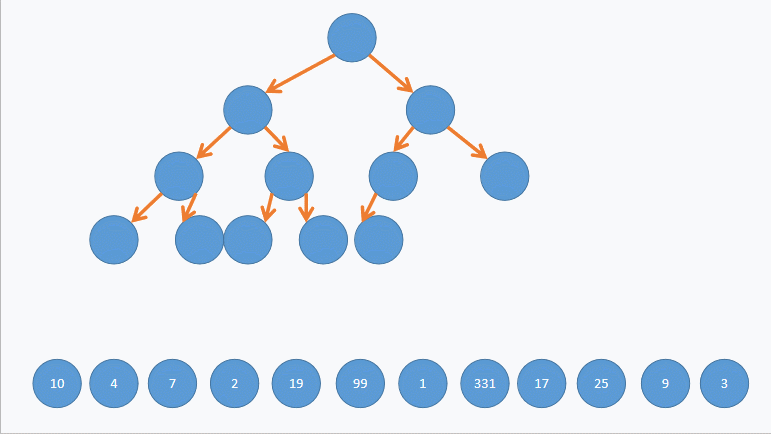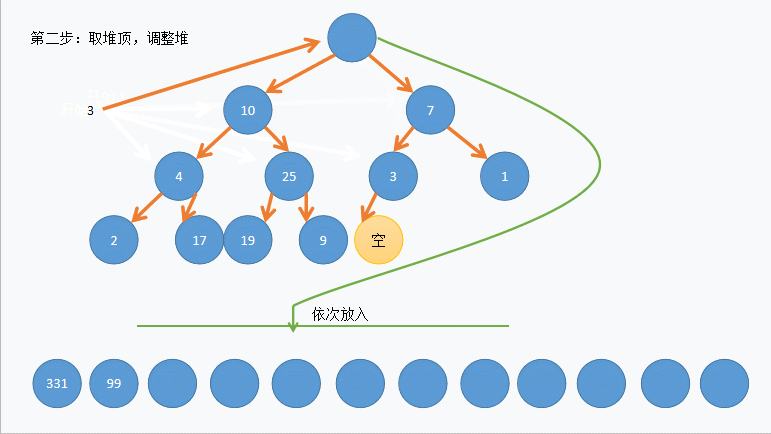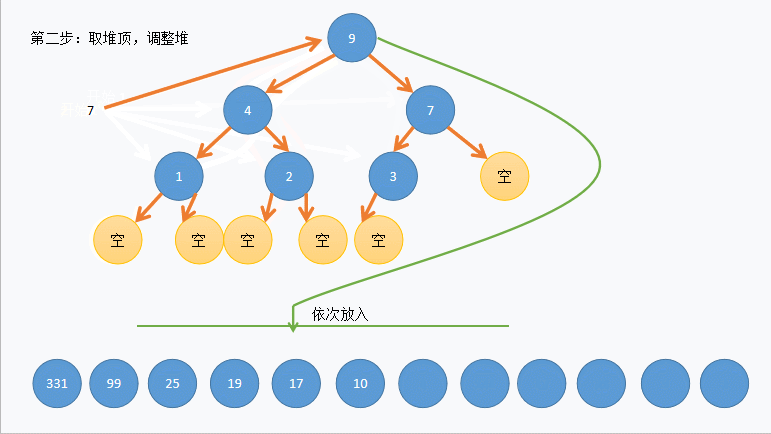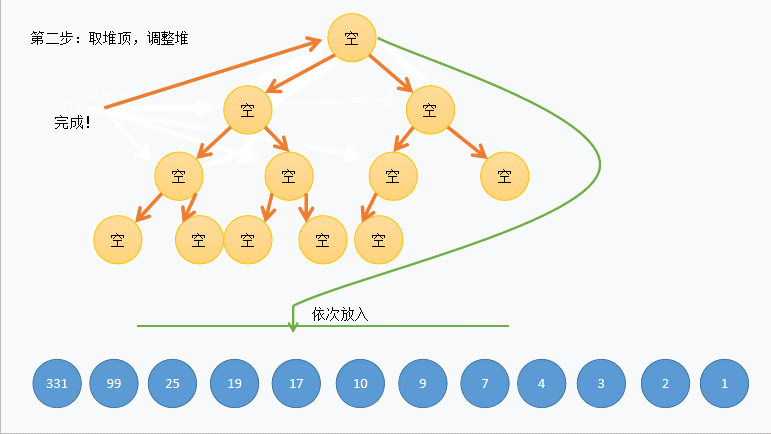
<1>我们可以先交换 堆顶数据 和 堆末数据 ,在进行 向下调整 算法维护堆的性质
<2>因为这样升序待排数据就能先在数据末尾有序,并不断向前推进,最终有序
<3>如果我们采用的是小根堆,我们排的就是降序
结论:排升序建大堆 排降序建小堆
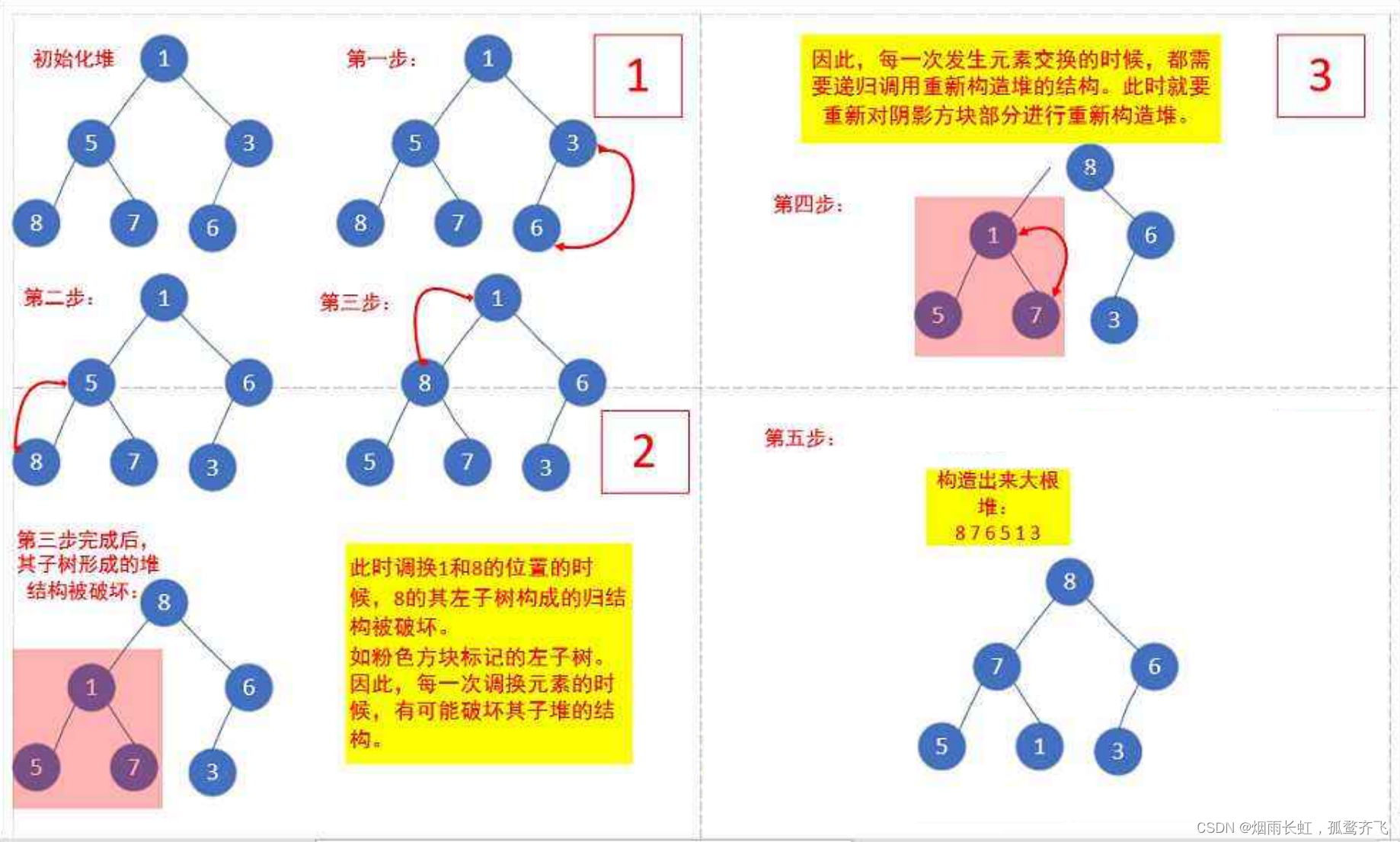
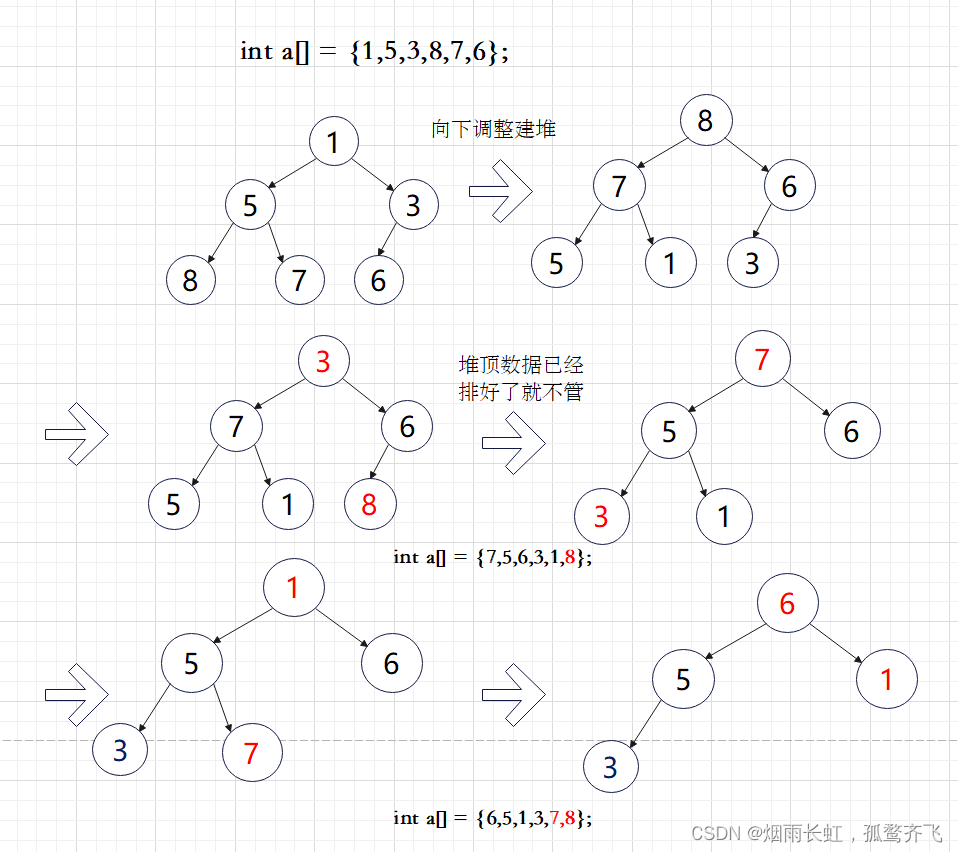
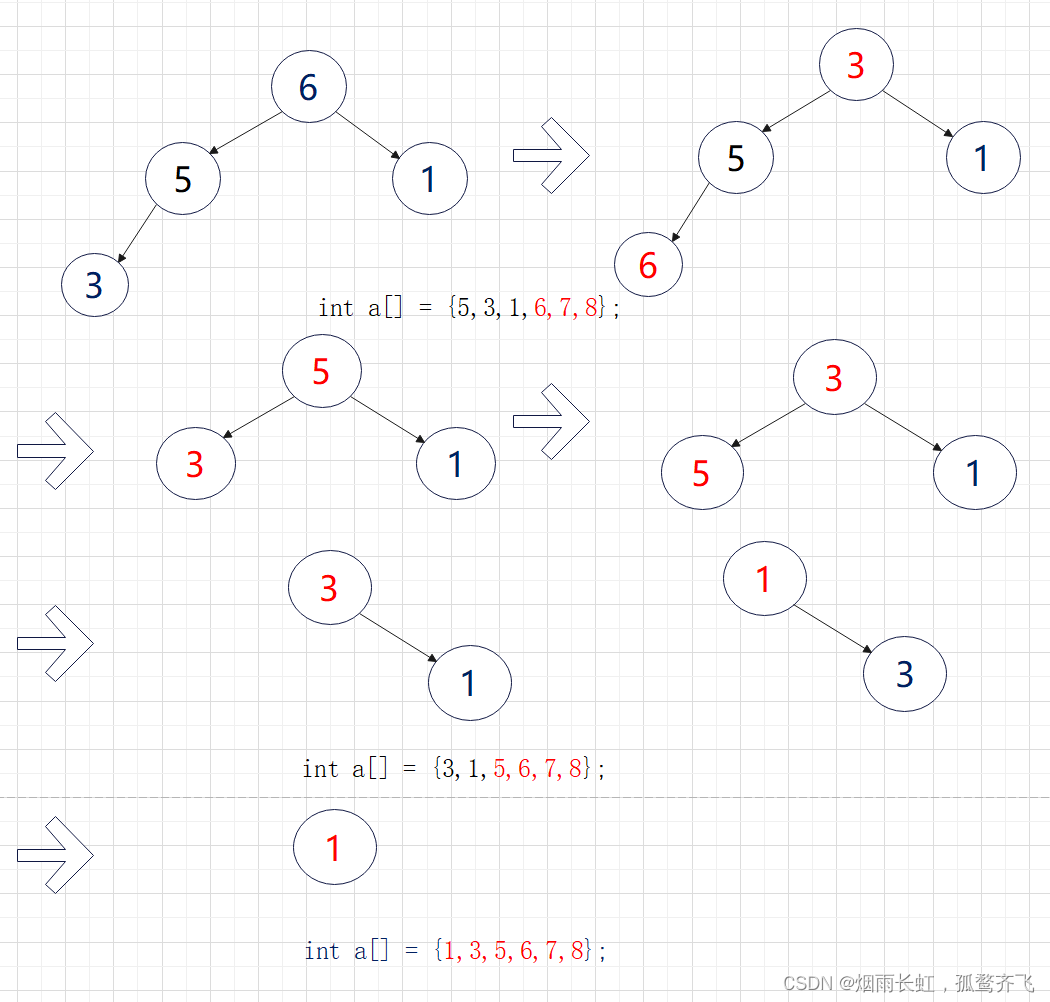
这里给老铁们动图展示:
堆排序的实现
void HeapSort(int* arr, int n) { //建堆 for (int i = (n - 1 - 1) / 2; i >= 0; i--) { AdjustDown(arr, n, i); } //堆排序 int len = n - 1; while (len) { //堆顶数据和堆末数据交换 Swap(&arr[0],& arr[len]); //维护树的性质 AdjustDown(arr, len, 0); //剔除已排好的数据 len--; } }

堆排序代码测试
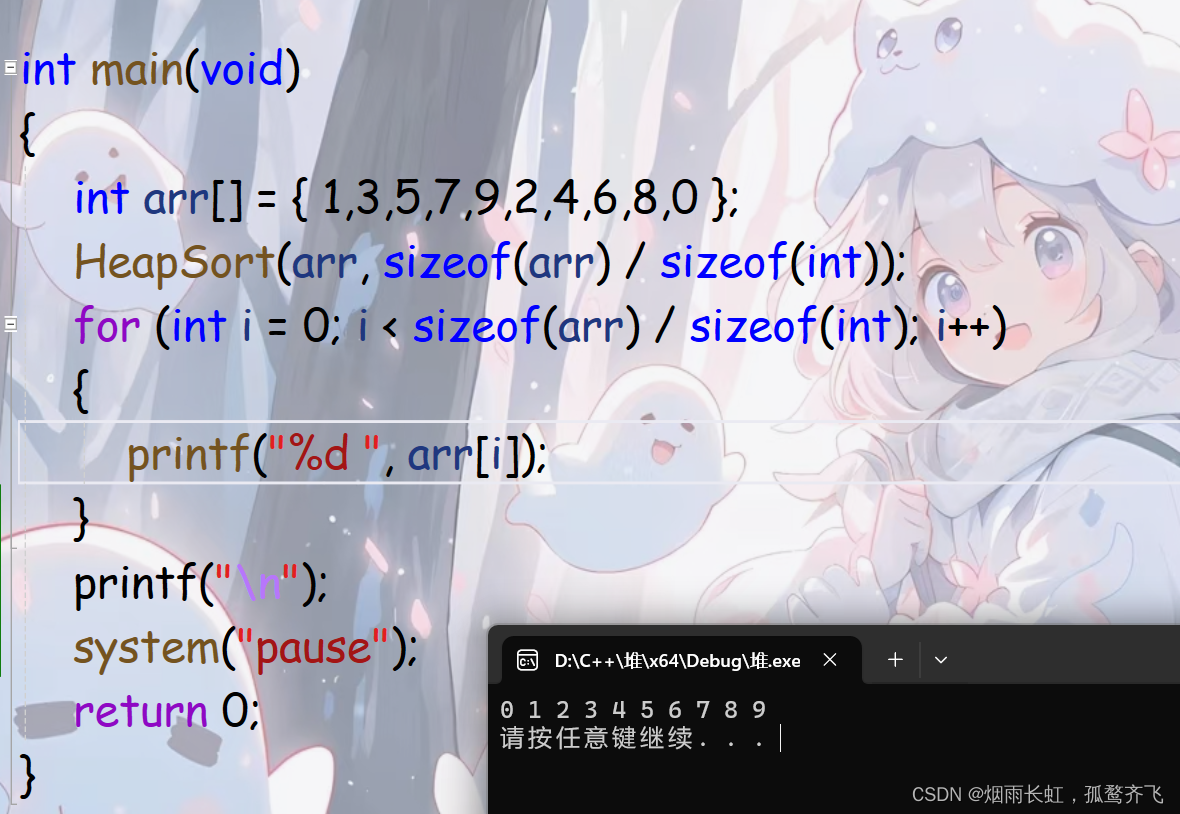
int main(void) { int arr[] = { 1,3,5,7,9,2,4,6,8,0 }; HeapSort(arr, sizeof(arr) / sizeof(int)); for (int i = 0; i < sizeof(arr) / sizeof(int); i++) { printf("%d ", arr[i]); } printf("\n"); system("pause"); return 0; }
整体代码实现
#include<stdio.h> #include<stdlib.h> void Swap(int* n, int* m) { int tmp = *n; *n = *m; *m = tmp; } void AdjustDown(int* data, int n, int parent) { int child = parent * 2 + 1; while (child < n) { if (child + 1 < n && data[child + 1] > data[child]) { child++; } if (data[child] > data[parent]) { Swap(&data[child], &data[parent]); parent = child; child = parent * 2 + 1; } else { break; } } } void HeapSort(int* arr, int n) { for (int i = (n - 1 - 1) / 2; i >= 0; i--) { AdjustDown(arr, n, i); } int len = n - 1; while (len) { Swap(&arr[0],& arr[len]); AdjustDown(arr, len, 0); len--; } } int main(void) { int arr[] = { 1,3,5,7,9,2,4,6,8,0 }; HeapSort(arr, sizeof(arr) / sizeof(int)); for (int i = 0; i < sizeof(arr) / sizeof(int); i++) { printf("%d ", arr[i]); } printf("\n"); system("pause"); return 0; }
总结✨
由于我们建堆的时间复杂度为 O(n)
排序的时间复杂度为 O(nlogn)
所以整体时间复杂度为O(nlogn)
稳定性
同选择排序一样,由于其中交换位置的操作,所以是不稳定的排序算法
时间复杂度
堆排序的最优时间复杂度、平均时间复杂度、最坏时间复杂度均为 O(nlogn)
空间复杂度
是一种原地排序算法,不需要额外的辅助存储空间,只需要原数组上进行元素的交换和调整
不适用于小数据集
堆排序的性能相对较好,但对于小规模的数据集来说,其常数项较大,不如快速排序等算法效率高
✨堆排序的主要优点在于它具有稳定的时间复杂度 O(nlogn),适用于大规模数据集的排序,而且是一种原地排序算法,不需要额外的空间。但它并不适用于小规模数据集,因为其常数项较大。堆排序也不是稳定排序,即相同值的元素在排序后的相对位置可能会改变。
















 866
866

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











