







 本文详细介绍了快速排序的基本概念、步骤、原始框架,包括快排的最优和最坏时间复杂度分析,以及针对部分有序数组的随机数取key法和三数取中策略。此外,还讨论了如何通过小区间优化和非递归实现来提高效率。
本文详细介绍了快速排序的基本概念、步骤、原始框架,包括快排的最优和最坏时间复杂度分析,以及针对部分有序数组的随机数取key法和三数取中策略。此外,还讨论了如何通过小区间优化和非递归实现来提高效率。
欲寄彩笺兼尺素
山长水阔知何处
目录

快排的介绍
快速排序(Quicksort):是由 冒泡排序 的一种改进,由 Hoare 在1960年提出。
快速排序是指通过 一趟排序 将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要 小 ,然后再按此方法对这两部分数据分别进行快速排序。整个排序过程可以 递归 进行,以此达到整个数据变成有序序列。
快排的步骤
快排思想
任取待排序元素序列中的某元素作为 基准值 ,按照该排序将待排序集合分割成两子序列,左子序列中所有元素均 小于 基准值,右子序列中所有元素均 大于 基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
快排步骤
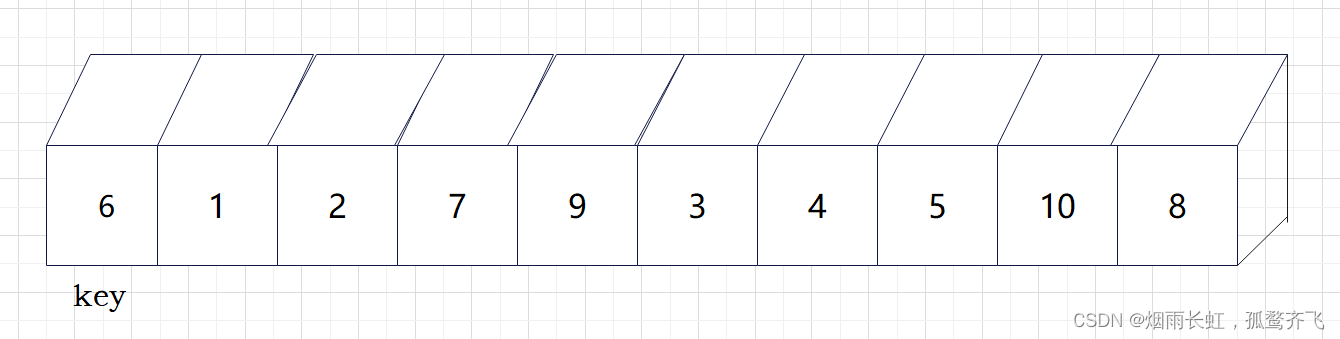
| ✨<1>我们任意选取数为基准值 key (我们先以最左边的数为基准做例子) |

| ✨<2>我们定义两个指针 left (公生)、right (熏) 分别指向数组的首尾 |

| ✨<3>熏先往前移动,找到比基准 key 小的位置时一直等待(保持不动) |
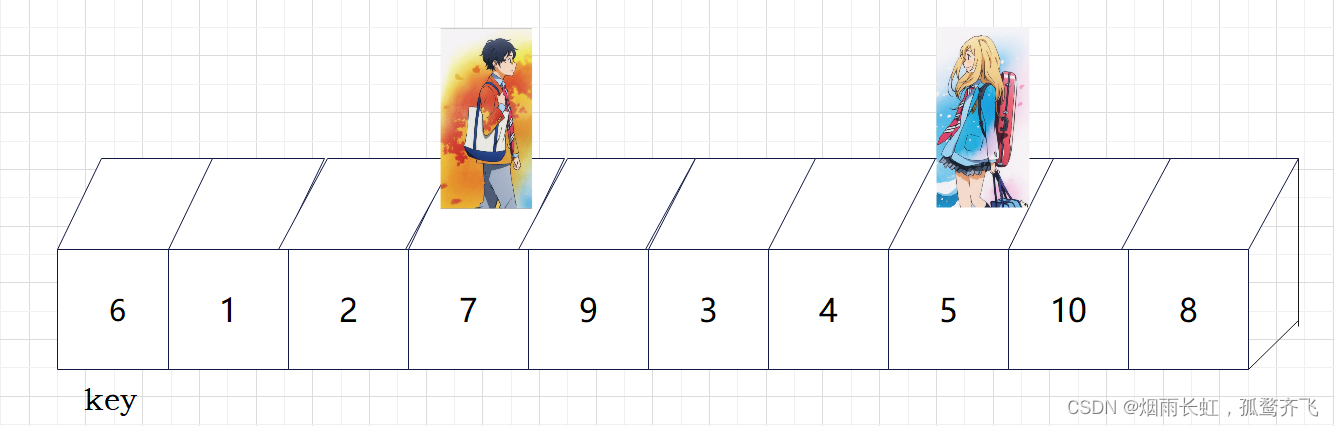
| ✨<4>公生再往后走找到比基准 key 大的位置 |
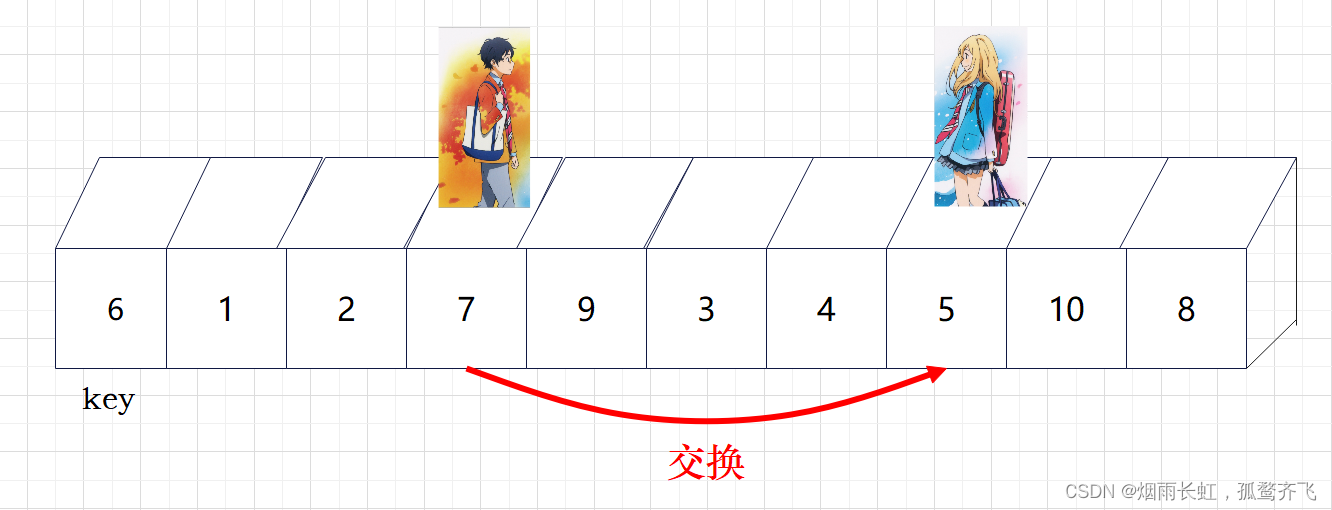
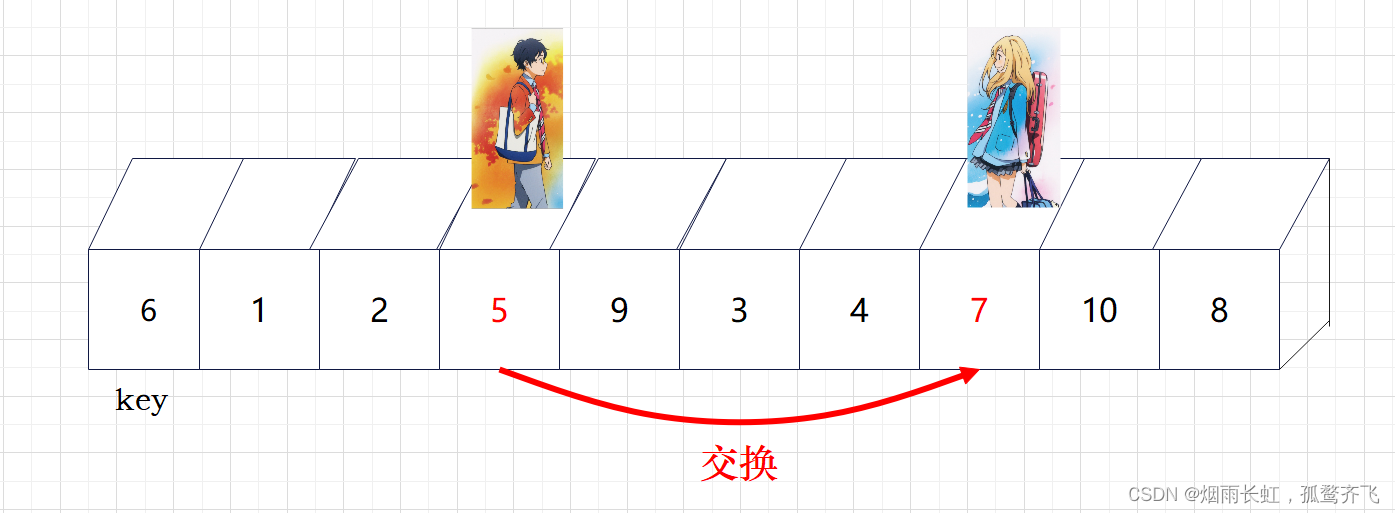
| ✨<5>到达相应的位置后,就交换他们的数值 |
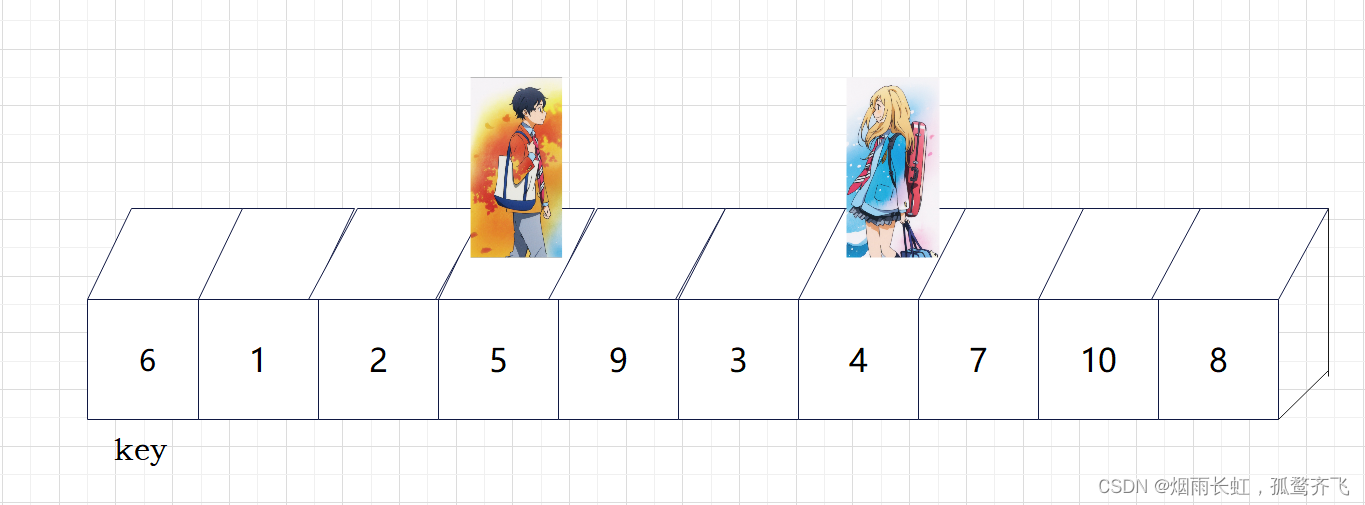
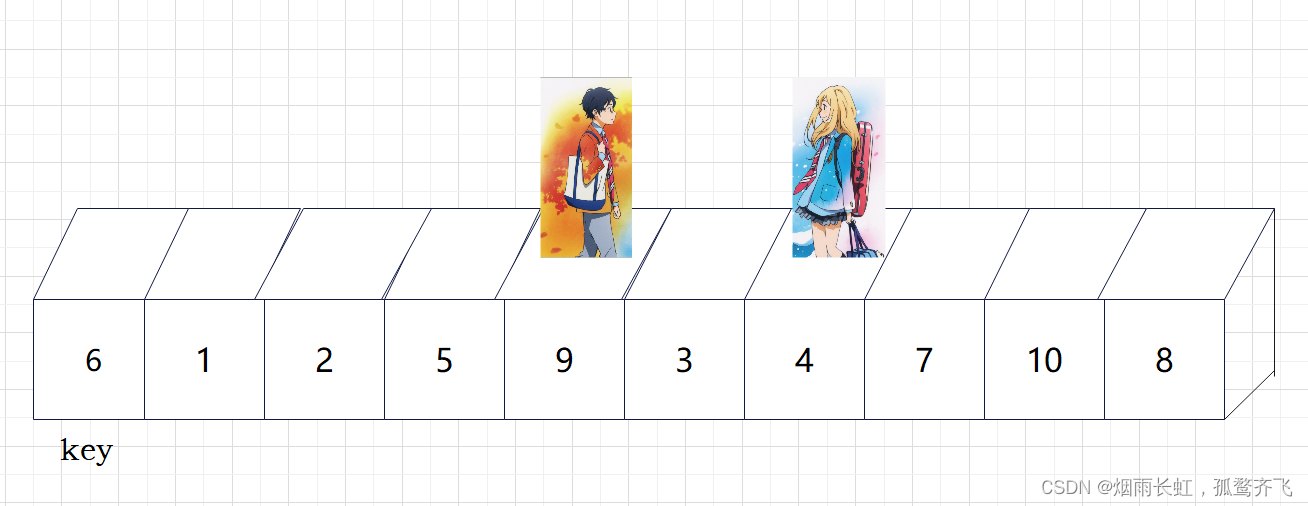
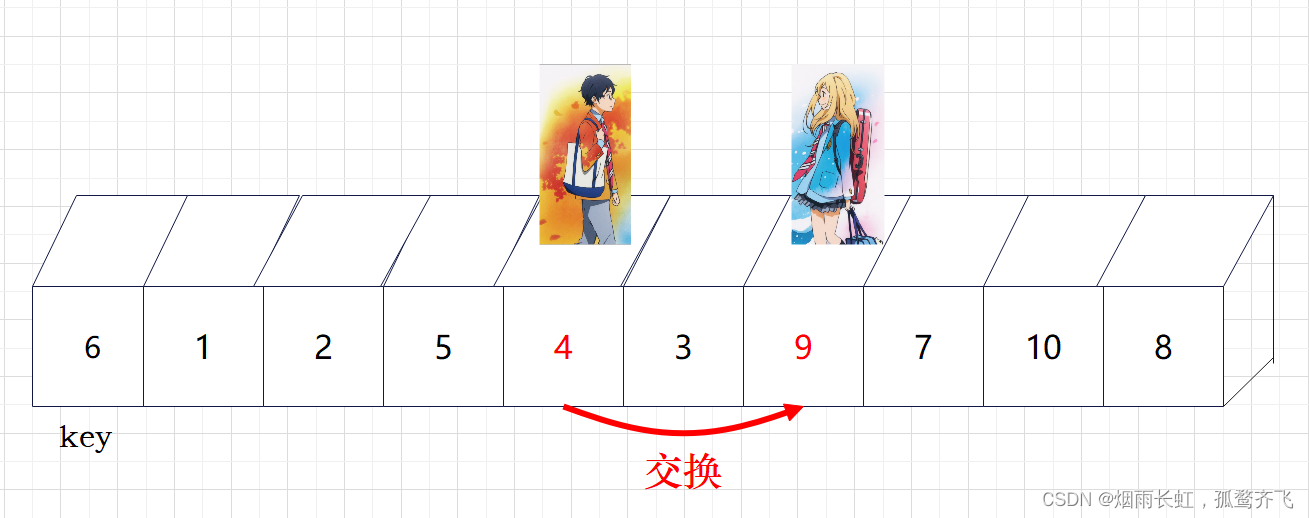
| 🎥重复上述步骤 |
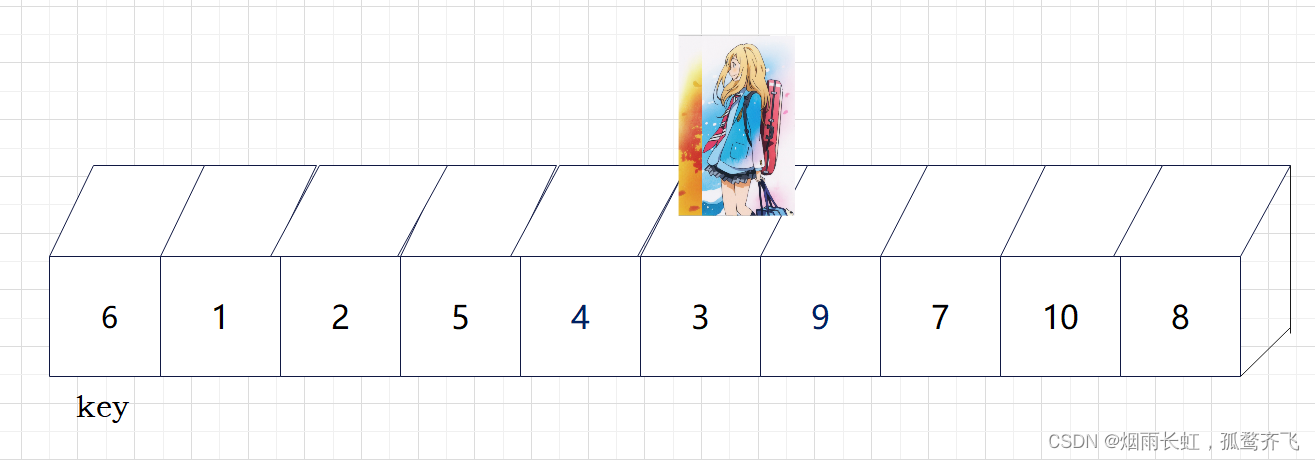
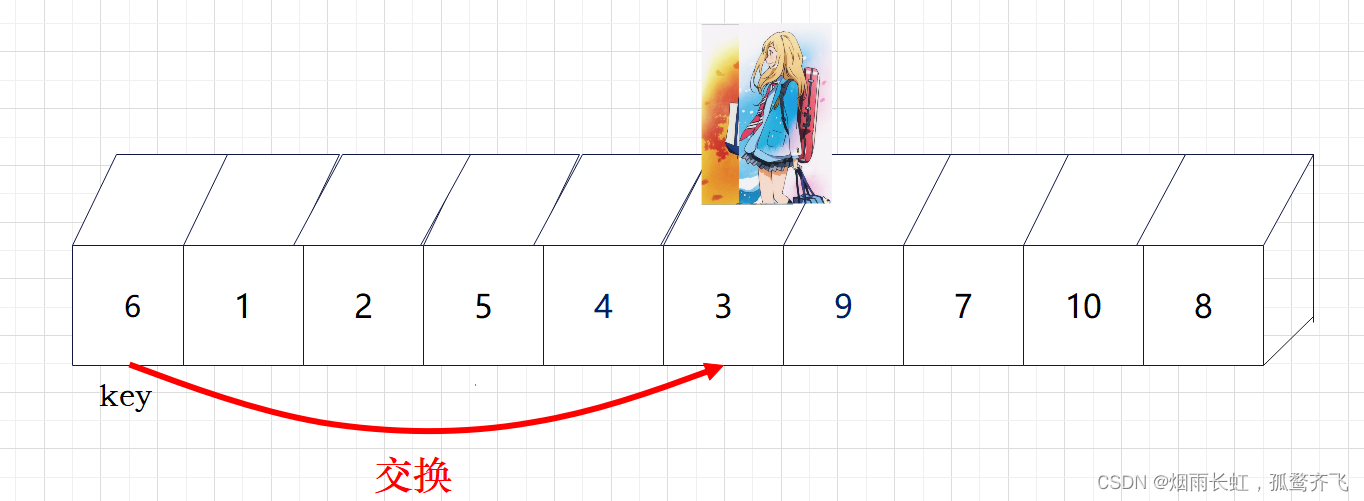
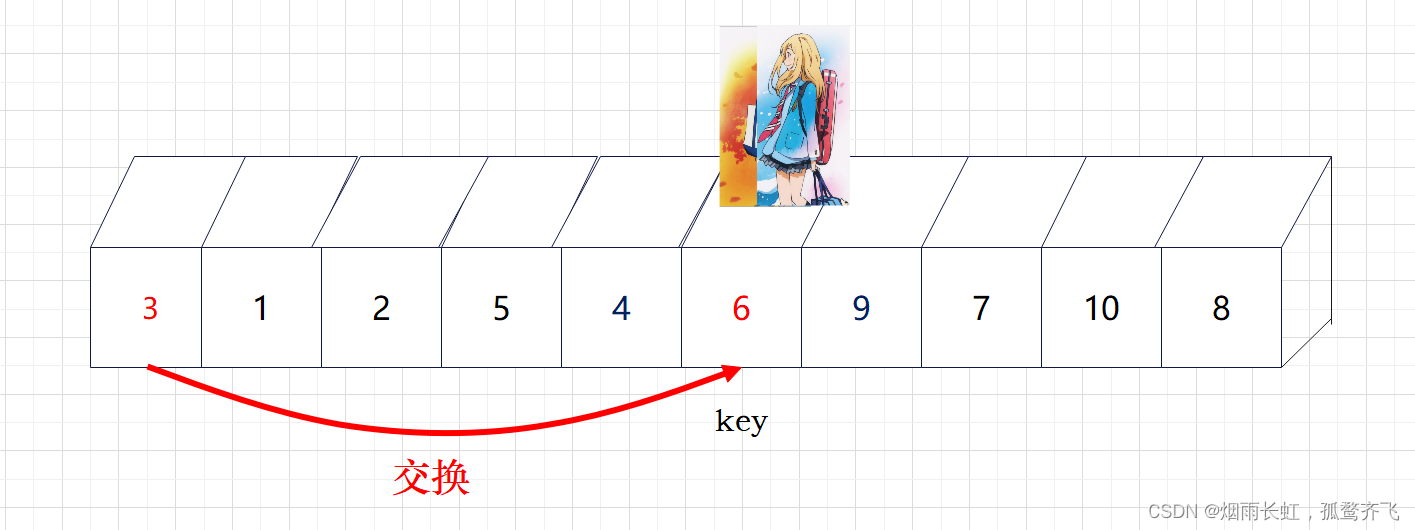
| ✨<6>相遇时将 key 与相遇点进行交换,这样就满足左边皆小于 key ,右边皆大于 key |
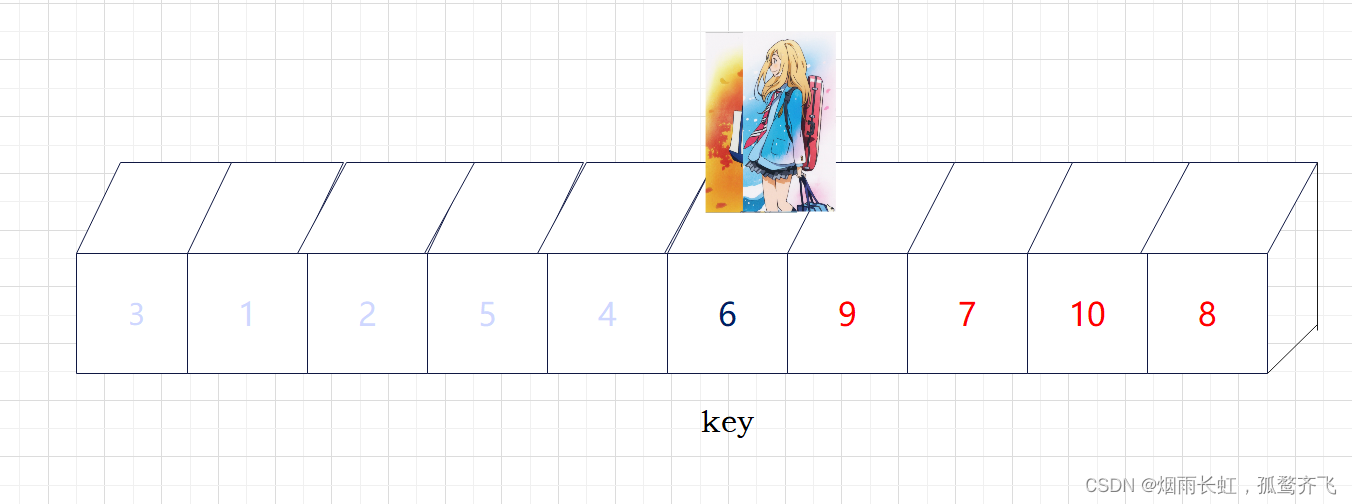
💞现在基准数 key 已经归位,它正好处在序列的第 6 位。此时我们已经将原来的序列,以 key 为分界点拆分成了两个序列,左边的序列是 3 1 2 5 4 ,右边的序列是 9 7 10 8 。接下来还需要分别处理这两个序列。因为 key 左右边的序列目前都还不是有序的。
💞我们可以采用 分治思想 将 3 1 2 5 4 看成是一个新的序列,将这个序列以最左边的数 3 为基准 key 进行调整,使得 key 左边的数都小于等于 3 ,key 右边的数都大于等于 3 。循环反复我们的数组就有序了。
以下是动画展示 
快排的原始框架
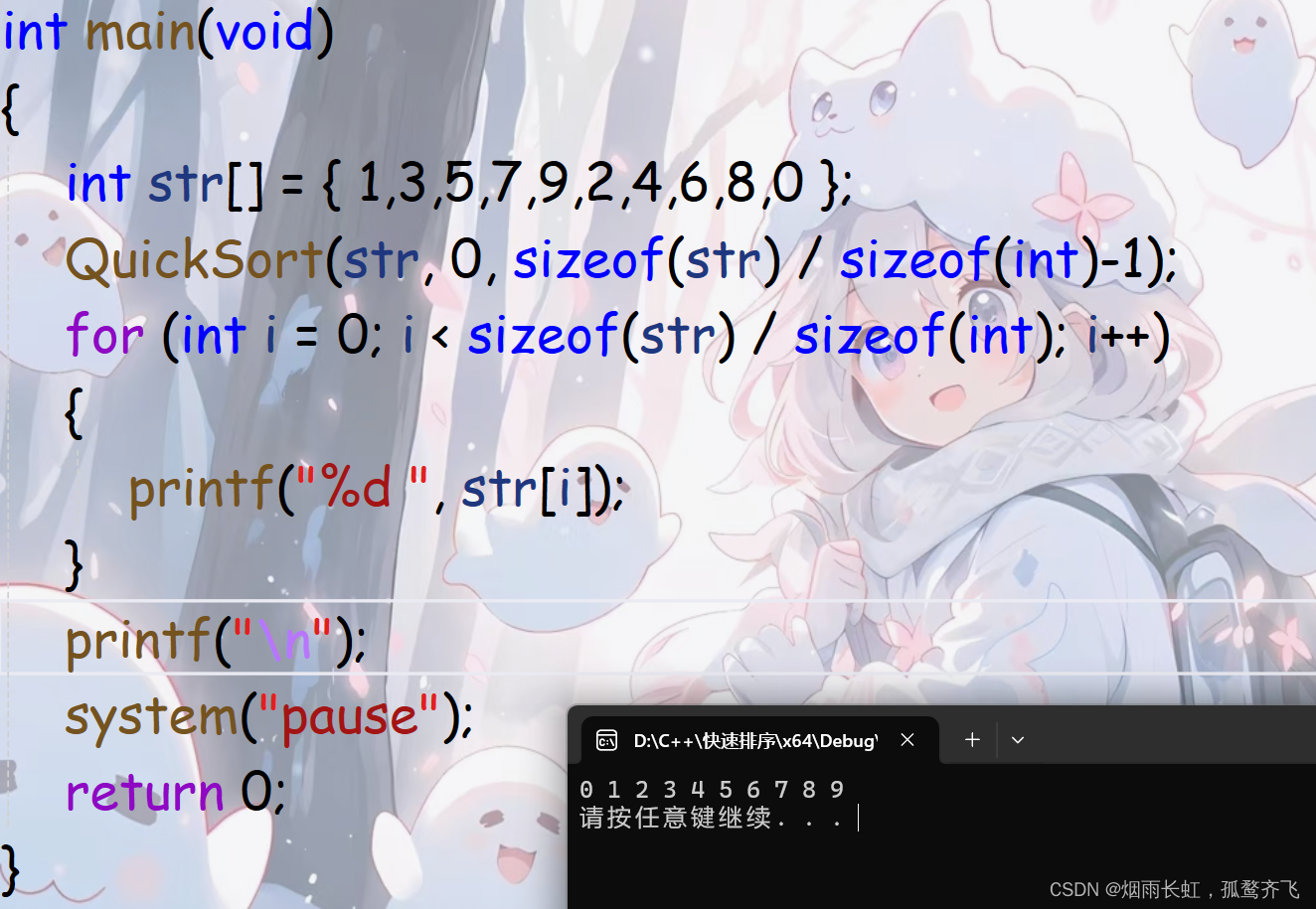
这是我们实现的一个最朴素的快速排序算法,一个不含任何添加剂,纯洁无暇的快速排序算法
void Swap(int* n, int* m) { int tmp = *n; *n = *m; *m = tmp; } void QuickSort(int* a, int left, int right) { //区间只有一个值或者不存在就是最小子问题 if (left >= right) return; int begin = left, end = right; int key = left; while (left < right) { //右边先走,找比 key 小的数 while (left < right && a[right] >= a[key]) { right--; } //左边后走,找比 key 大的数 while (left < right && a[left] <= a[key]) { left++; } Swap(&a[left], &a[right]); } Swap(&a[left], &a[key]); key = left; //[begin,key-1]key[key+1,end] QuickSort(a, 0, key - 1); QuickSort(a, key + 1, end); }代码测试
时间复杂度的分析
✨时间复杂度最好情形
数学归纳法推导:
| T(n)≤ 2T(n/2) + n,T(1)= 0 |
| T(n)≤ 2(2T(n/4)+ n/2) +n = 4T(n/4)+ 2n |
| T(n)≤ 4(2T(n/8)+ n/4) +2n = 8T(n/8)+ 3n |
| T(n)< 8(2(T(n/16)+ n/8)+3n = 16T(n/16)+ 4n |
| … … |
| T(n)≤nT(1)+(log2n)×n= O(nlogn) |
最好情况发生在每次分区时,待排序数组的中位数恰好被选为 key ,这时候每一次分区都可以将待排序数组平均分成两个子数组,分别包含大于或小于中位数的元素。因此,在最好情况下,快速排序的递归树的深度为 logn ,每层需要比较的次数为 n ,因此总的比较次数为 nlogn 。
快排的代码优化
快速排序的平均时间复杂度是 O(nlogn),但是在实际排序中,时间复杂度和基准元素 key 的选择有关。
如果 key 选取不好,那么快速排序有可能就会退化为冒泡排序,时间复杂度为O(n^2)。
那么快排什么时候最坏呢?答:当数组有序/接近有序的时候
✨时间复杂度最坏情形
对于每一个区间,我们在处理的时候,选取的 key 刚好就是这个区间的最大值或者最小值。比如我们需要对 n 个数排序,而每一次进行处理的时候,选取的 key 刚好都是区间的最小值。于是第一次操作,经过调换元素顺序的操作后,最小值被放在了第一个位置,剩余
n-1个数占据了2到n个位置;第二次操作,处理剩下的n-1个元素,又将这个子区间的最小值放在了当前区间的第1个位置,以此类推每次操作,都只能将最小值放到第一个位置,而剩下的元素,则没有任何变化。所以对于n个数来说,需要操作n次,才能为n个数排好序。而每一次操作都需要遍历一次剩下的所有元素,这个操作的时间复杂度是O(n)所以总时间复杂度为
O(n^2)
随机数取key法
🎉在待排序列是部分有序时,固定选取key使快排效率底下,要缓解这种情况,就引入了随机选取key法,这样就避免了 key 总是区间最值的情况
void Swap(int* n, int* m) { int tmp = *n; *n = *m; *m = tmp; } void QuickSort(int* a, int left, int right) { if (left >= right) return; int begin = left, end = right; //选取区间的随机数做key int randi = rand()%(right - left+1); randi += left; Swap(&a[left], &a[randi]); int key = left; while (left < right) { while (left < right && a[right] >= a[key]) { right--; } while (left < right && a[left] <= a[key]) { left++; } Swap(&a[left], &a[right]); } Swap(&a[left], &a[key]); key = left; QuickSort(a, 0, key - 1); QuickSort(a, key + 1, end); }
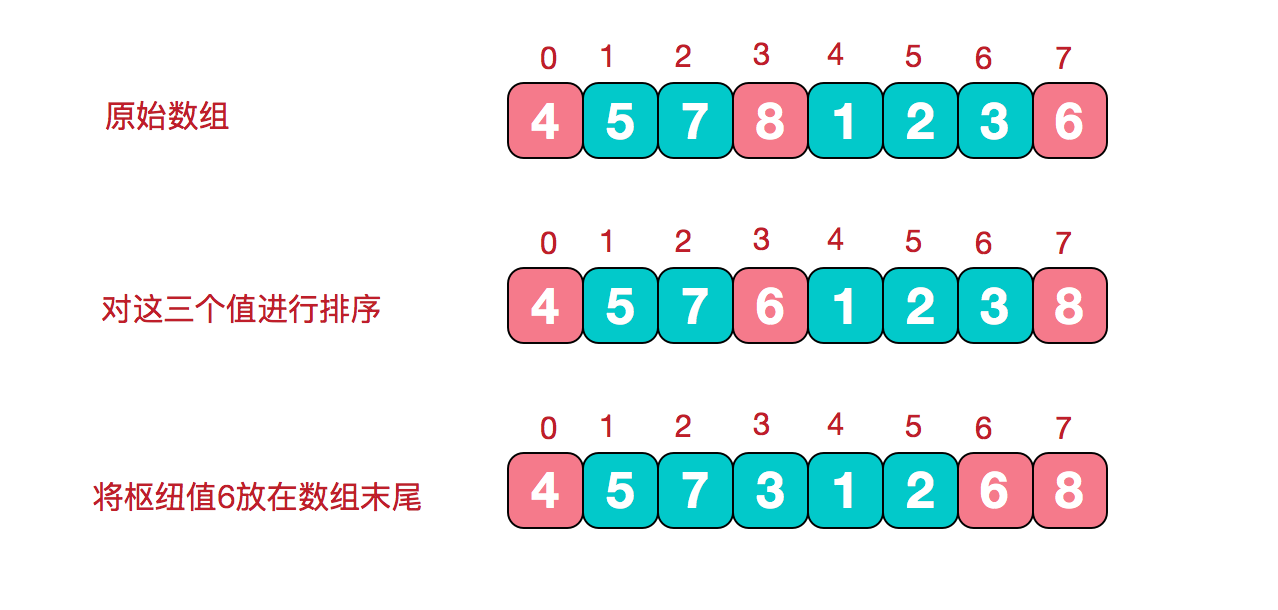
三数取中选key法
🎉我们只需要在首,中,尾这三个数据中,选择一个排在中间的数据作为基准值,进行快速排序,即可进一步提高快速排序的效率
那么为什么要取中间呢?
因为可以有效避免有序状态下快排的致命缺陷,也可以避免无序状态下因为取key的随机性所导致的不可控的时间效率问题
三数取中的步骤 其中枢纽值就是 key
void Swap(int* n, int* m) { int tmp = *n; *n = *m; *m = tmp; } int GetMidi(int* a, int left, int right) { int mid = (left + right) / 2; if (a[left] < a[mid]) { if (a[mid] < a[right]) { return mid; } else if (a[left] > a[right]) { return left; } else { return right; } } else { if (a[mid] > a[right]) { return mid; } else if (a[left] < a[right]) { return left; } else { return right; } } } void QuickSort(int* a, int left, int right) { if (left >= right) return; int begin = left, end = right; //三数取中 int midi = GetMidi(a, left, right); Swap(&a[left], &a[midi]); int key = left; while (left < right) { while (left < right && a[right] >= a[key]) { right--; } while (left < right && a[left] <= a[key]) { left++; } Swap(&a[left], &a[right]); } Swap(&a[left], &a[key]); key = left; QuickSort(a, 0, key - 1); QuickSort(a, key + 1, end); }

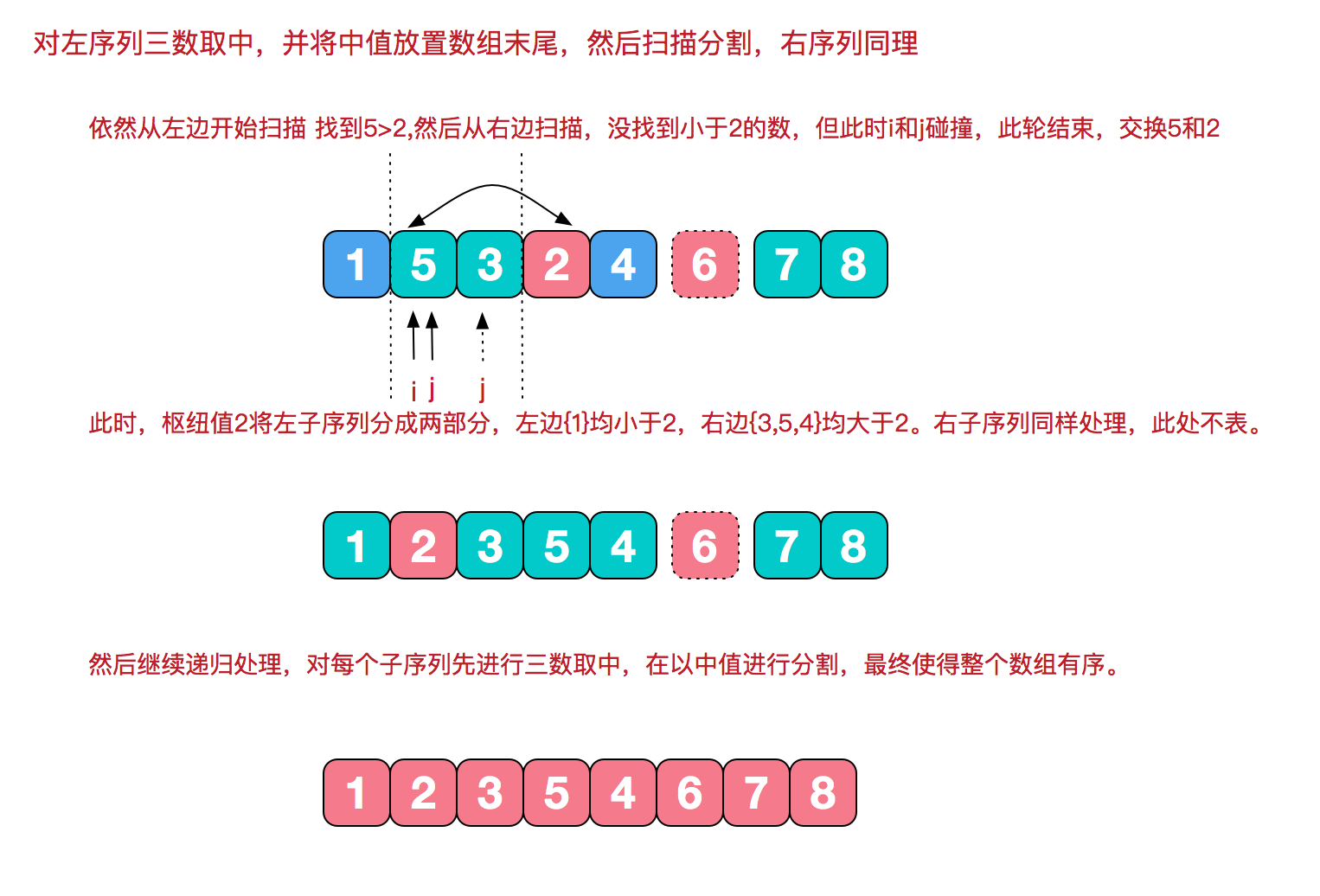
小区间优化递归问题
🎉我们知道快速排序实际上是递归分治这么进行下去的,每调用一次函数,就会调用两次函数,左区间和右区间。所以函数调用次数是呈等比数列的形式增长的,所以说当基数越大(即调用层数越深)时,函数调用的增长量越大,也就是说整个函数递归调用的次数很大一部分取决于最后几次调用(相当于满二叉树)
例如:最后一次调用就会使总的递归调用层数翻倍
所以有人就想能不能想个办法把最后几次的递归调用给消除掉呢?
于是就发明了小区间优化
✨以下是优化效率比较高的代码模板
void Swap(int* n, int* m) { int tmp = *n; *n = *m; *m = tmp; } int GetMidi(int* a, int left, int right) { int mid = (left + right) / 2; if (a[left] < a[mid]) { if (a[mid] < a[right]) { return mid; } else if (a[left] > a[right]) { return left; } else { return right; } } else { if (a[mid] > a[right]) { return mid; } else if (a[left] < a[right]) { return left; } else { return right; } } } void InserSort(int* a, int n) { for (int i = 0; i < n - 1; i++) { int end = i; int tmp = a[end + 1]; while (end >= 0) { if (a[end] > tmp) { a[end + 1] = a[end]; --end; } else { break; } } a[end + 1] = tmp; } } void QuickSort(int* a, int left, int right) { if (left >= right) return; //如果只有10个数,我们就直接插入 if (right - left + 1 < 10) { InserSort(a + left, right - left+1); } else { int begin = left, end = right; int midi = GetMidi(a, left, right); Swap(&a[left], &a[midi]); int key = left; while (left < right) { while (left < right && a[right] >= a[key]) { right--; } while (left < right && a[left] <= a[key]) { left++; } Swap(&a[left], &a[right]); } Swap(&a[left], &a[key]); key = left; QuickSort(a, 0, key - 1); QuickSort(a, key + 1, end); } }利用直接插入排序优化的原因:
因为小区间优化的目的 就是消除掉函数调用最后几层时所递归调用的巨大的次数 给个10,大概小区间优化的目的就完成了 这里为什么要用插入排序呢? 因为我们只需要排序10个数字,所以直接用直接插入排序即可 再去用快排会形成巨多栈帧不值得,用堆和希尔去做这么小的数据量的排序也很大材小用 上面的三个排序都是数据量越多相比于直接插入排序而言越有优势,而现在数据量很小,优势显不出来 而且本来进行了很多次快速排序的单趟排序后这个小区间内的数据有很多都已经是部分或整体有序的了 而直接插入排序对部分有序或整体有序的数组的排序有奇效(甚至时间复杂度有可能能达到O(N)) 所以我们用直接插入排序来进行小区间优化
快速排序前后指针写法
前后指针步骤
首先先在数组中找到一位基准数也可以称做 key ,通常是数组的首位或者末位
我们先以第一位设为基准数(key)
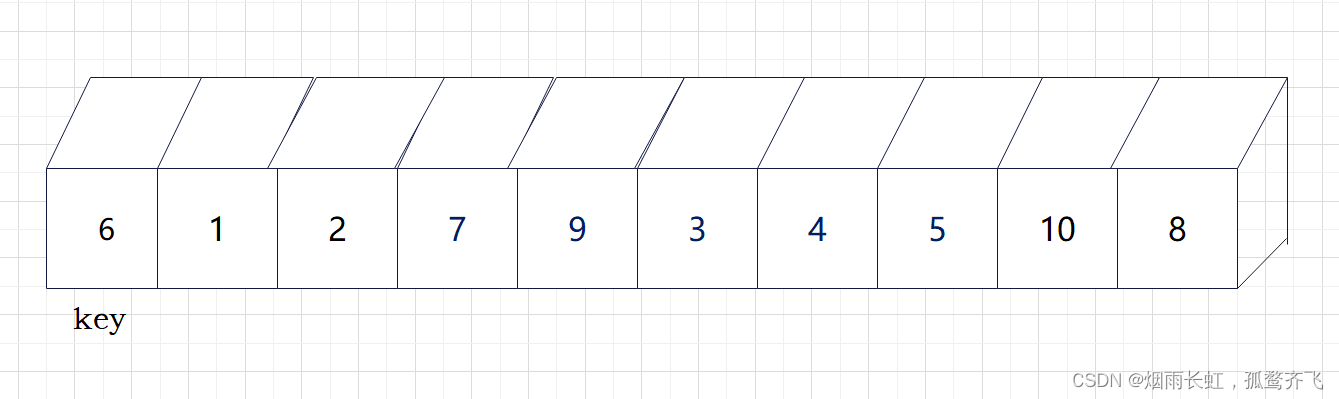
| ✨<1>我们将 left (公生) 定义在序列开头,right (熏)定义在 公生 的后一个 |
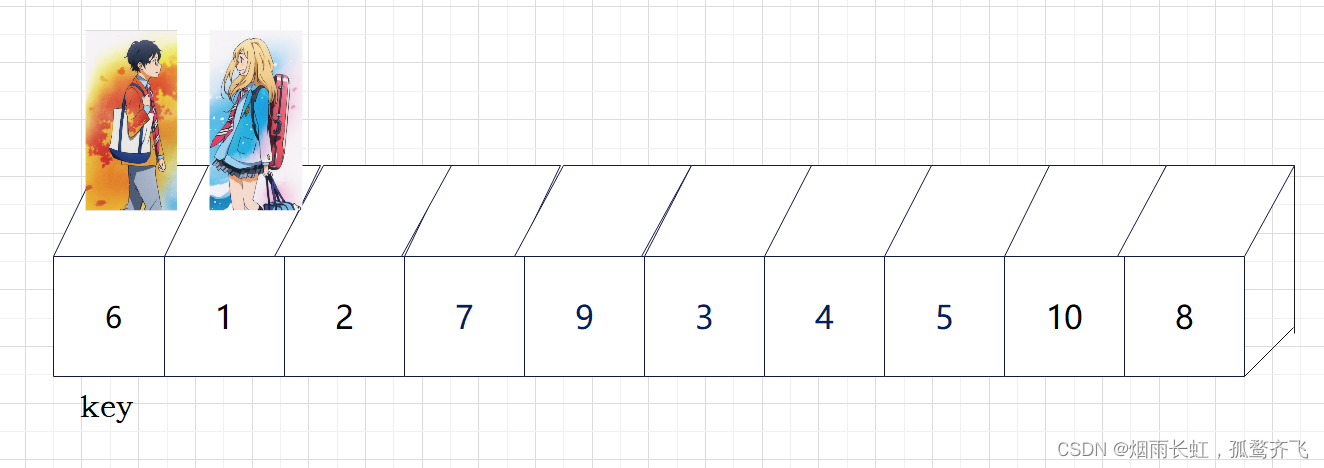
| ✨<2>然后公生往后走找大判断指向的数据是否小于key,若小于则公生后移一位否则等待;熏往后走找小判断指向的数据是否大于key,若大于则熏后移一位否则等待,直到两个人到达指定位置才进行数据交换 |
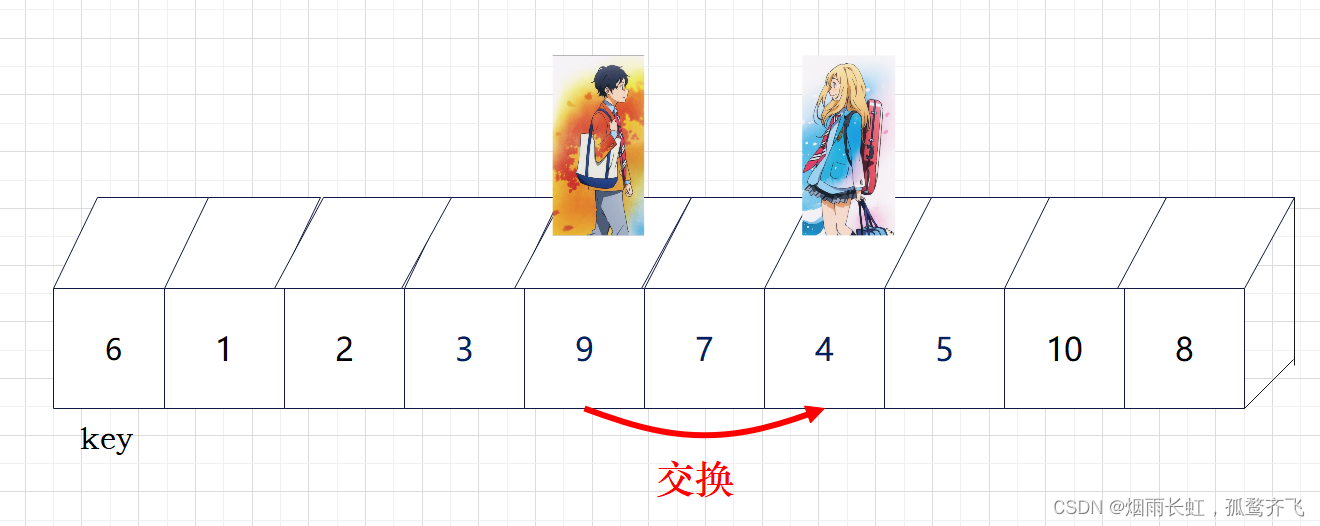
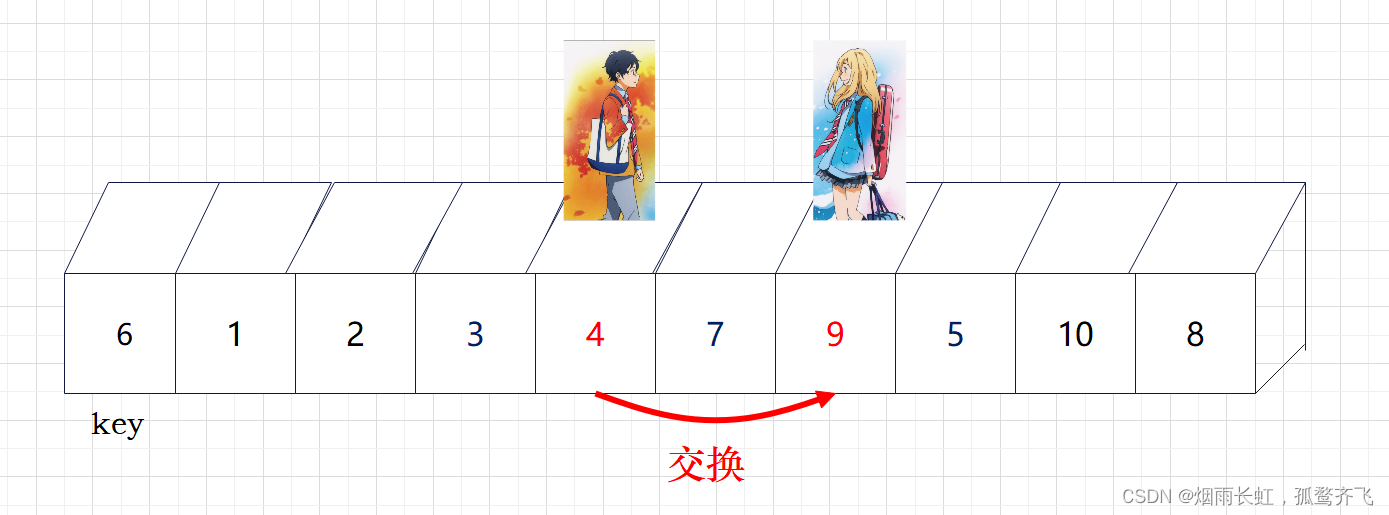
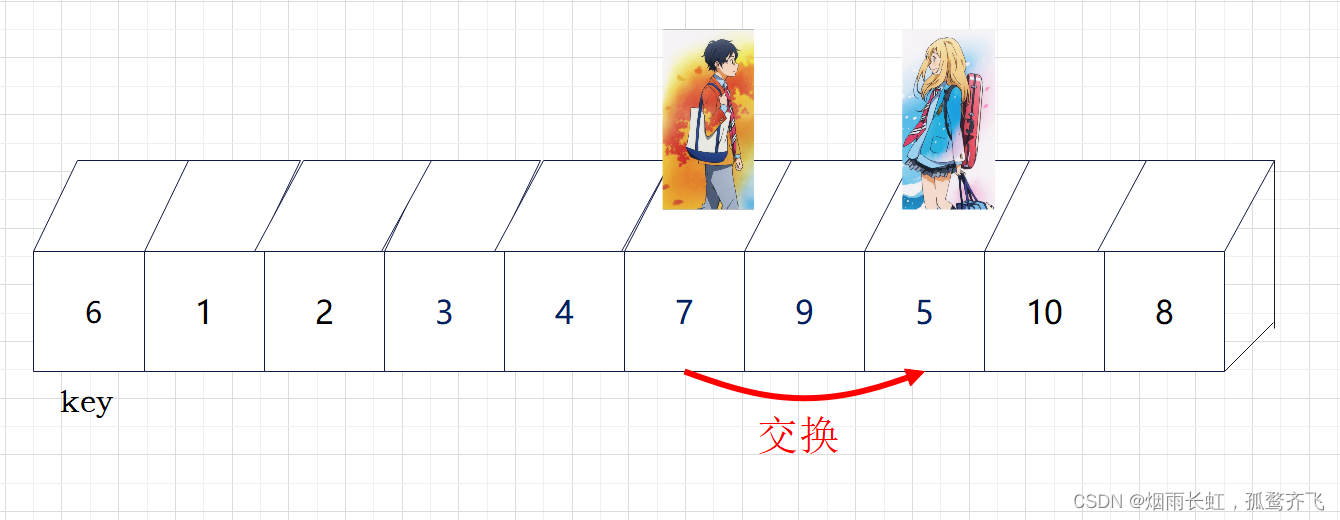
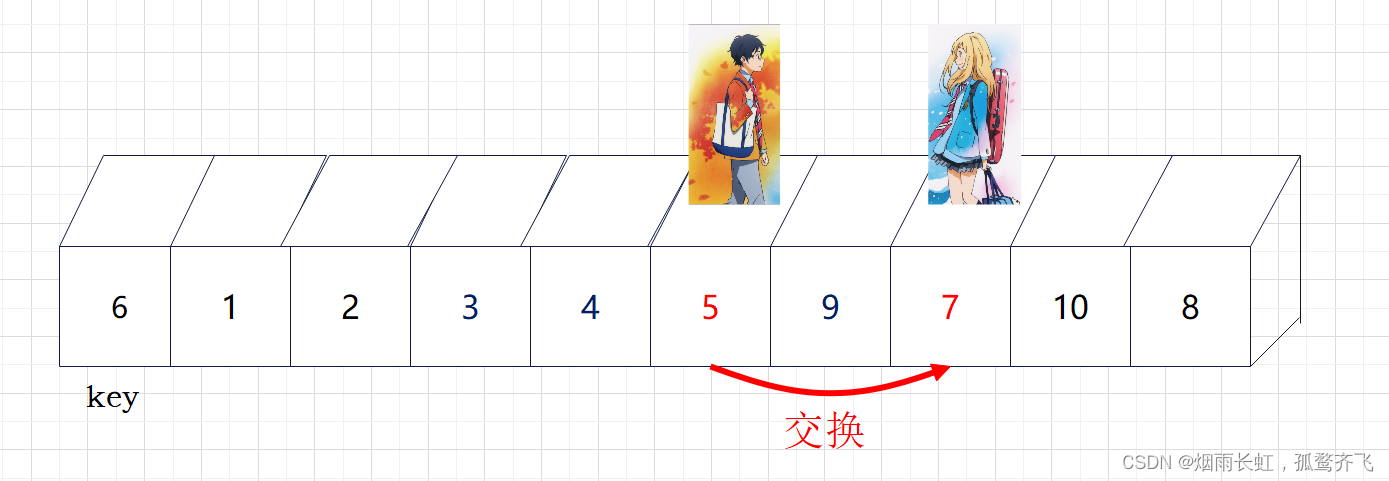
| ✨<3>直到熏消失在公生视野(越界),我们就将公生所在的位置与key进行交换 |
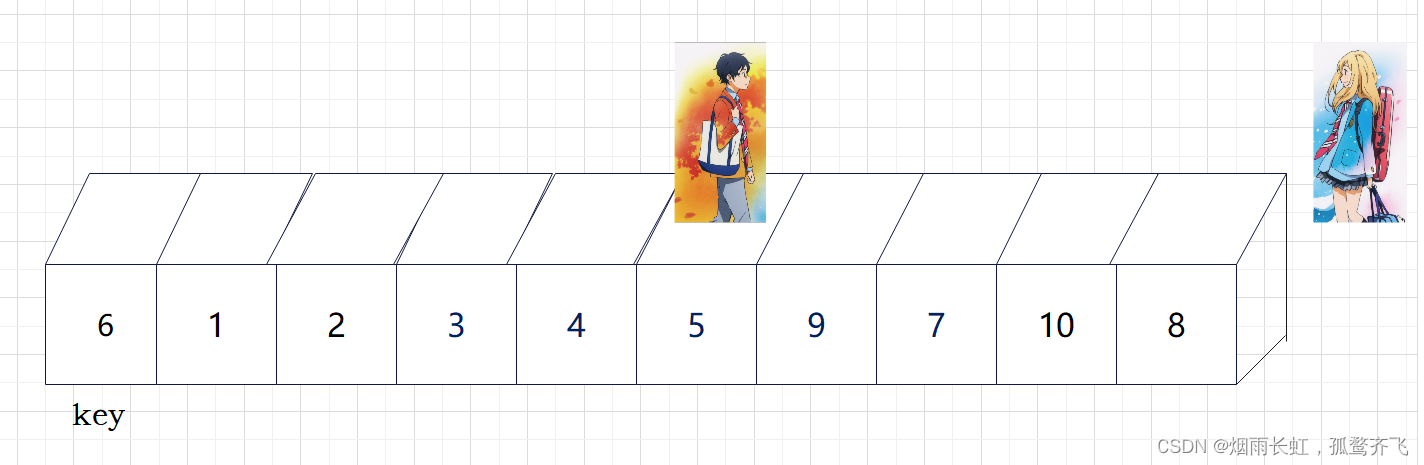
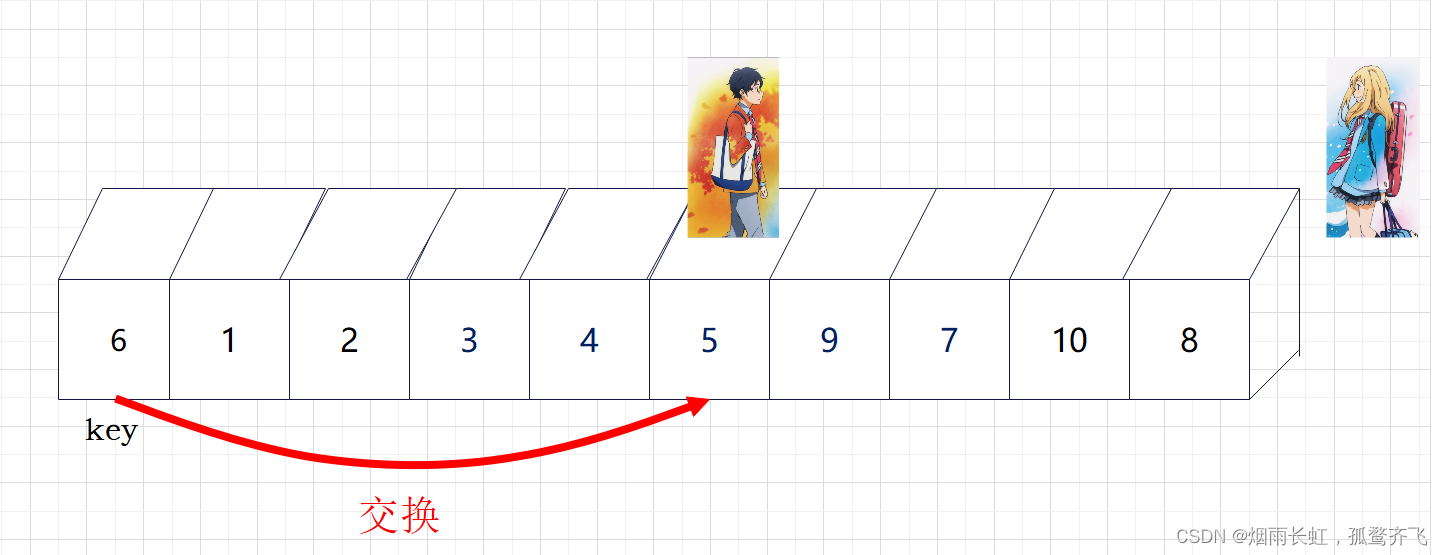
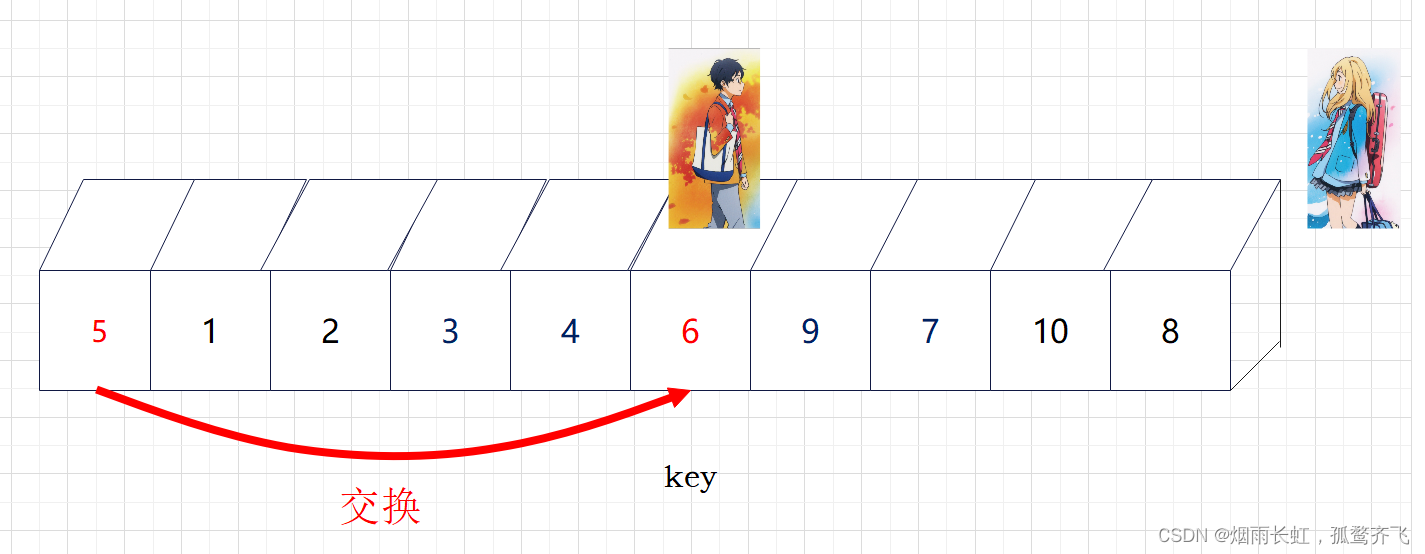
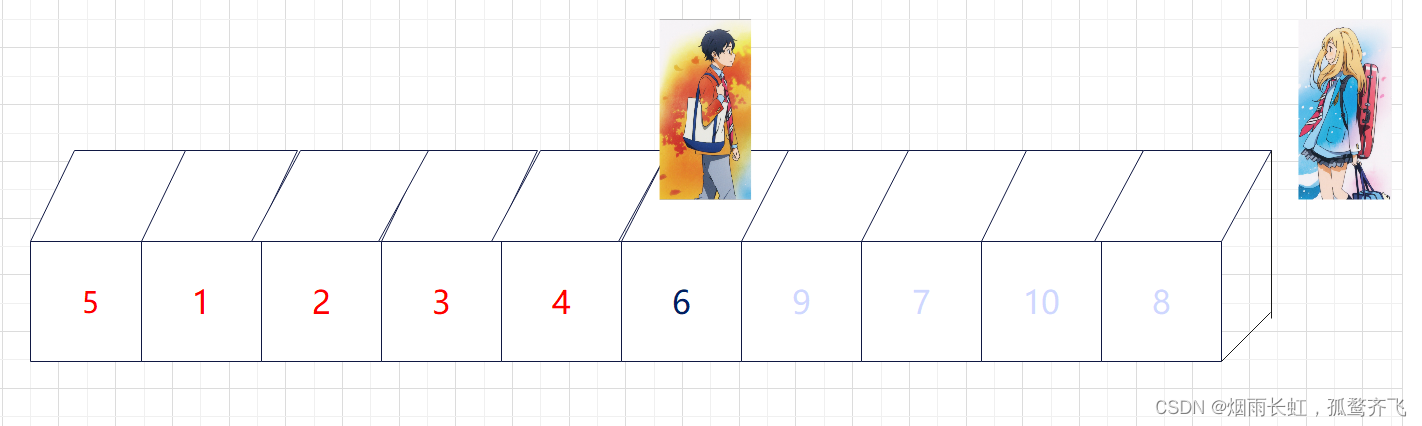
| ✨<4>这样以 key 为分界点拆分成了两个序列,左边小于 key,右边大于 key,接下来分治递归即可 |
代码展示
void Swap(int* n, int* m) { int tmp = *n; *n = *m; *m = tmp; } void QuickSort(int* a, int left, int right) { if (left >= right) return; int key = left; int prev = left; int cur = left + 1; while (cur <= right) { if (a[cur] < a[key] && ++prev != cur) Swap(&a[prev], &a[cur]); ++cur; } Swap(&a[key], &a[prev]); key = prev; QuickSort(a, left, key - 1); QuickSort(a, key + 1, right); }代码测试

非递归写法的简单介绍
在VS中Release版本下可以优化绝大部分递归调用
因为递归是一种压栈的操作,而系统提供的栈中的空间并不是很多,所以在数据量庞大项目中我们往往会选择非递归的方法
#include<stdio.h>
#include<stdbool.h>
#include<stdlib.h>
#include<assert.h>
typedef int STDateType;
typedef struct Stack
{
STDateType* a;
STDateType top;
int capacity;
}ST;
void StackInit(ST* ps)
{
ps->a = (STDateType*)malloc(sizeof(STDateType) * 4);
ps->top = 0;
ps->capacity = 4;
}
void StackDestory(ST* ps)
{
assert(ps);
free(ps->a);
ps->a = NULL;
ps->top = 0;
ps->capacity = 0;
}
void StackPush(ST* ps, STDateType x)
{
assert(ps);
if (ps->top == ps->capacity)
{
STDateType* tmp = (STDateType*)realloc(ps->a, ps->capacity * 2 * sizeof(STDateType));
if (tmp == NULL)
{
printf("realloc fail\n");
exit(-1);
}
else
{
ps->a = tmp;
ps->capacity *= 2;
}
}
ps->a[ps->top] = x;
ps->top++;
}
void StackPop(ST* ps)
{
assert(ps);
assert(ps->top > 0);
ps->top--;
}
STDateType StackTop(ST* ps)
{
assert(ps);
assert(ps->top > 0);
return ps->a[ps->top - 1];
}
int StackSize(ST* ps)
{
assert(ps);
return ps->top;
}
bool StackEmpty(ST* ps)
{
assert(ps);
return ps->top == 0;
}
void Swap(int* n, int* m)
{
int tmp = *n;
*n = *m;
*m = tmp;
}
int GetMinIndex(int* arr, int left, int right)
{
int mid = (left + right) >> 1;
if (arr[left] < arr[mid])
{
if (arr[mid] < arr[right])
{
return mid;
}
if (arr[left] < arr[right] && arr[right] < arr[mid])
{
return right;
}
return left;
}
else
{
if (arr[left] < arr[right])
{
return left;
}
if (arr[mid] < arr[right] && arr[right] < arr[left])
{
return right;
}
return mid;
}
}
void QuickSort(int* arr, int n)
{
ST st;
StackInit(&st);
StackPush(&st, n - 1);
StackPush(&st, 0);
while (!StackEmpty(&st))
{
int left = StackTop(&st);
StackPop(&st);
int right = StackTop(&st);
StackPop(&st);
int index = GetMinIndex(arr, left, right);
Swap(&arr[left], &arr[index]);
int begin = left;
int end = right;
int pivot = begin;
int key = arr[begin];
while (begin < end)
{
while (begin < end && arr[end] >= key)
{
end--;
}
arr[pivot] = arr[end];
pivot = end;
while (begin < end && arr[begin] <= key)
{
begin++;
}
arr[pivot] = arr[begin];
pivot = begin;
}
pivot = begin;
arr[pivot] = key;
if (pivot + 1 < right)
{
StackPush(&st, right);
StackPush(&st, pivot + 1);
}
if (left < pivot - 1)
{
StackPush(&st, pivot - 1);
StackPush(&st, left);
}
}
StackDestory(&st);
}
总结🔥
快速排序整体的综合性能和使用场景都是比较好的
时间复杂度:O(NlogN) 优化后就不会到最坏的情况
空间复杂度:O(logN)
稳定性:不稳定
虽然C++中提供了 sort 库函数,但是在面试中快排的底层代码以及优化往往都被要求手撕
由此可见 快排的重要
















 537
537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











