






参考视频:https://www.bilibili.com/video/BV1zgXGYuESx
4.1 无监督学习
机器学习的一种方法,没有给定事先标记过的训练示例,自动对输入的数据进行分类或分群。
优点:
- 算法不受监督信息(偏见)的约束,可能考虑到新的信息
- 不需要标签信息,极大程度扩大数据样本
主要应用: 聚类分析、关联规则、维度缩减
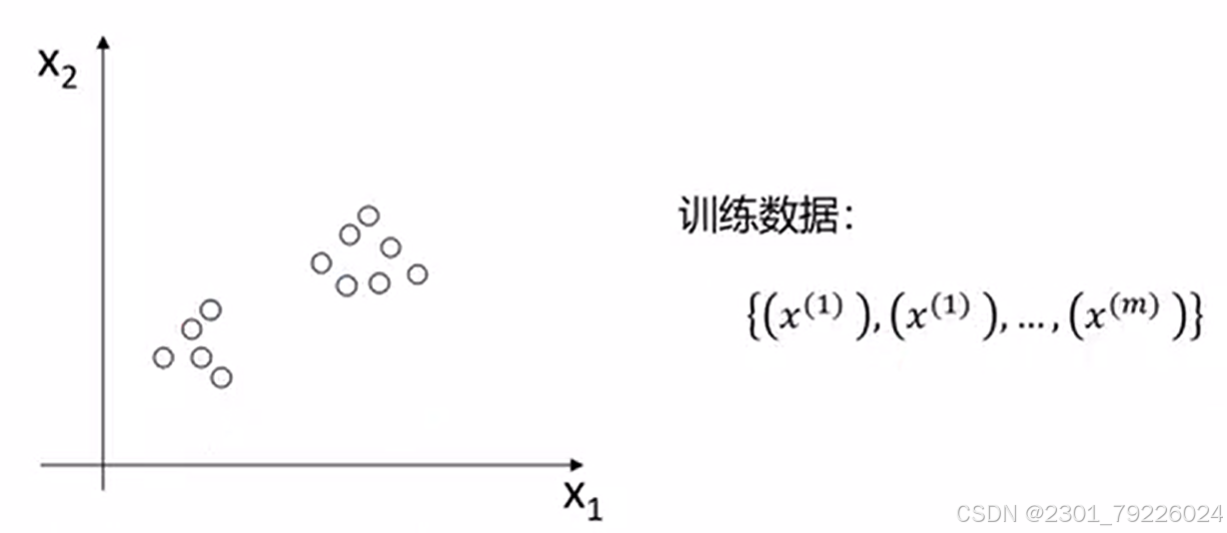
聚类分析
根据对象某些属性的相似度,将其自动划分为不同的类别
常用的聚类算法
- KMeans聚类
- 根据数据与中心点距离划分类别
- 基于类别数据更新中心点
- 重复过程直到收敛
特点:
- 实现简单,收敛快
- 需要指定类别数量
- 均值漂移聚类(Meanshift)
- 在中心点一定区域检索数据点
- 更新中心
- 重复流程到中心点稳定
特点:
- 自动发现类别数量,不需要人工选择
- 需要选择区域半径
- DBScan算法(基于密度的空间聚类算法)
- 基于区域点密度筛选有效数据
- 基于有效数据向周边扩张,直到没有新点加入
特点:
- 过滤噪音数据
- 不需要人为选择类别数量
- 数据密度不同时影响结果
4.2 KMeans、KNN、Mean-shift
KMeans
以空间中的K个点为中心进行聚类,对最靠近它们的对象归类,是聚类算法中最为基础也是最为重要的算法

算法流程:
- 选择聚类的个数K
- 确定聚类中心
- 根据点到聚类中心聚类确定各个点所属的类别
- 根据各个类别数据更新聚类中心
- 重复上述步骤直至收敛(中心点不再变化)
优点 1.原理简单,实现容易,收敛速度快 2.参数少,方便使用
缺点 1.必须设置簇的数量 2.随机选择初始聚类中心,结果缺乏一致性
KMeans VS KNN
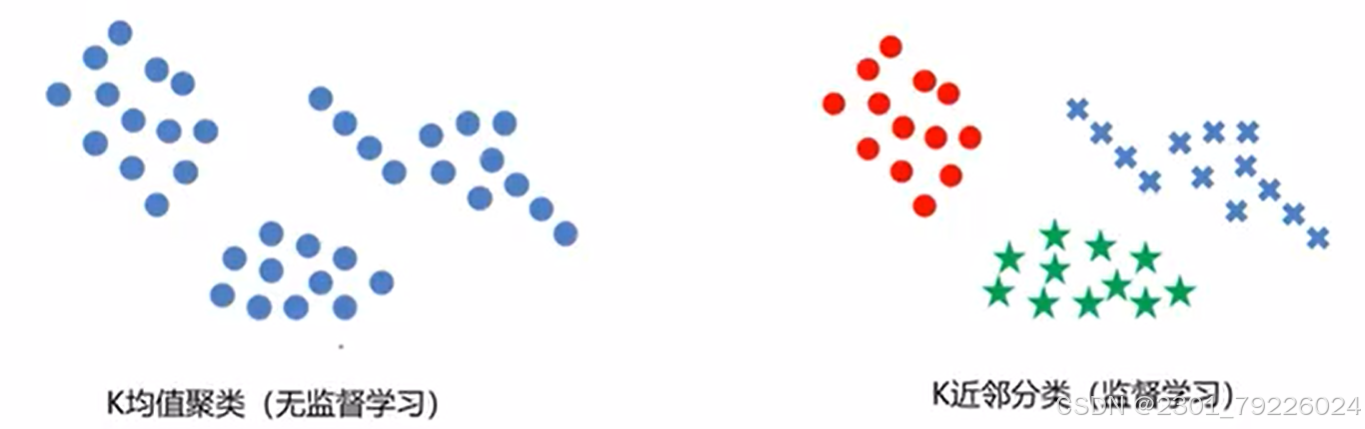
K近邻分类模型(KNN)
给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实例分类到这个类中。
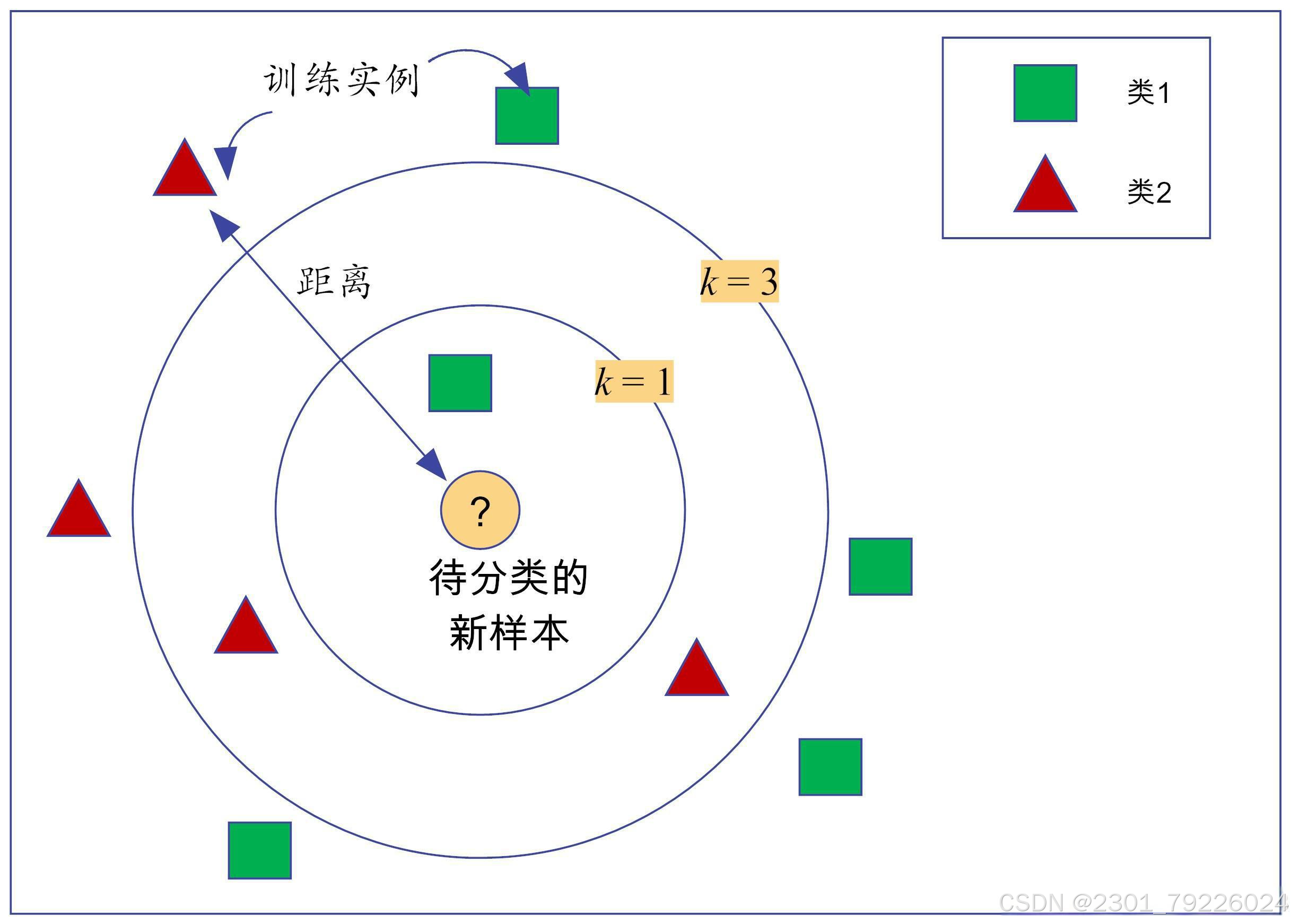
如果,该样本被划分为类1,因为在
距离中,类1的样本最多。
如果,该样本被划分为类2,因为在
距离中,类2的样本最多。
均值漂移聚类
一种基于密度梯度上升的聚类算法(沿着密度上升方向寻找聚类中心点)

算法流程:
- 随机寻找未分类点作为中心点
- 找出距离中心点在带宽之内的点,记作集合S
- 计算从中心点到集合S中每个元素的偏移向量M
- 中心点以向量M移动
- 重复2~4直至收敛
- 重复1~5直到所有点被归类
- 分类:根据每个类,对每个点的访问频率,取访问频率最大的那个类,作为当前点集的所属类。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









