






参考视频:https://www.bilibili.com/video/BV1op421C7wp
PPT:https://github.com/chenzomi12/AISystem
分布式并行意义
深度学习训练耗时:
训练耗时=训练数据规模*单步计算量/计算速率
计算速率(可变因素):
计算速率=单设备计算速率*设备数*多设备并行效率(加速比)
单设备计算速率提高:混合精度、算子融合、梯度累加
设备数增加:服务器架构、通信拓扑优化
多设备并行效率提高:数据并行、模型并行、流水并行
大模型遇到AI系统
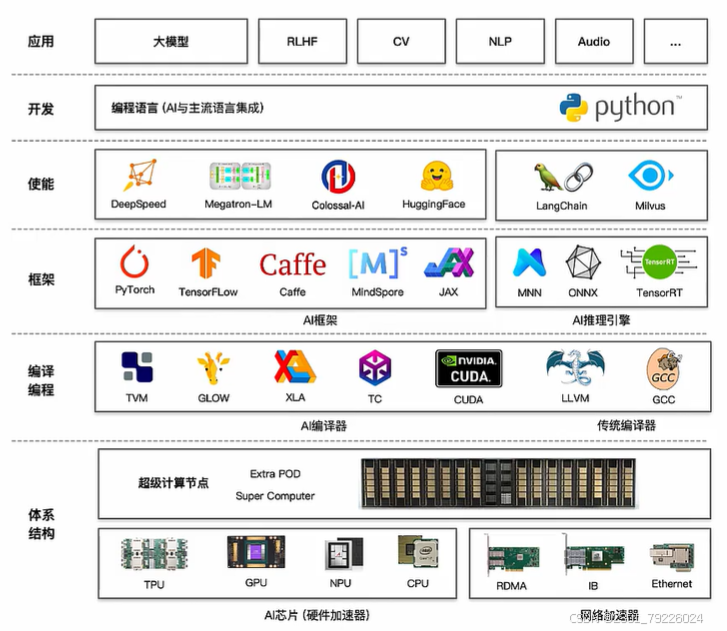
大模型使能层:分布式训练推理框架
解决大模型分布式训练:
- 部署和训练以Transformer类型结构的大模型
- 提供数据并行、模型并行和流水线并行等分布式并行模式
- 以集合通信和参数服务器方式进行资源整合
DeepSpeed
微软开发,提高大模型训练效率和可扩展性:
- 加速训练手段: 数据并行(ZeRO系列)、模型并行(PP)、梯度累积、动态缩放、混合精度等
- 辅助工具:分布式训练管理、内存优化和模型压缩等,帮助开发者更好管理和优化大模型训练任务
- 快速迁移:通过Python Wrap方式基于PyTorch构建,直接调用即完成简单迁移
Megatron-LM
NVIDIA开发,提高大模型分布式并行训练效率和线性度:
- 加速训练手段:综合数据并行(Data Parallelism),张量并行(Tensor Parallelism)和流水线并行(Pipeline Parallelism)来复现GPT-3
- 辅助工具:强大的数据处理& Tokenizer,支持LLM&VLM等基于Transformer结构。
Colossal-AI & BMTrain
Colossal-AI通过多种优化策略提高训练效率和降低显存需求:
- 加速训练手段: 更加丰富张量并行策略(ID/2D/2.5D/3D-TP)
- 丰富案例:提供20+大模型DEMO和配置文件,融入最新MOE技术和SORA
BMTrain用于训练数百亿规模参数大模型:
- 模型支持:智源研究院Aquila系列的模型分布式并行框架
- 加速训练手段:支持DeepSpeed中并行策略深度优化
Summary
分布式加速库/分布式加速框架
- 为大模型提供多维分布式并行能力,让大模型能够在AI集群上快速训练/推理
- 提升模型和算力利用率,提升AI集群的线性度


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









