







1. 下载和熟悉yolov7项目结构
1.1 下载YOLOv7项目
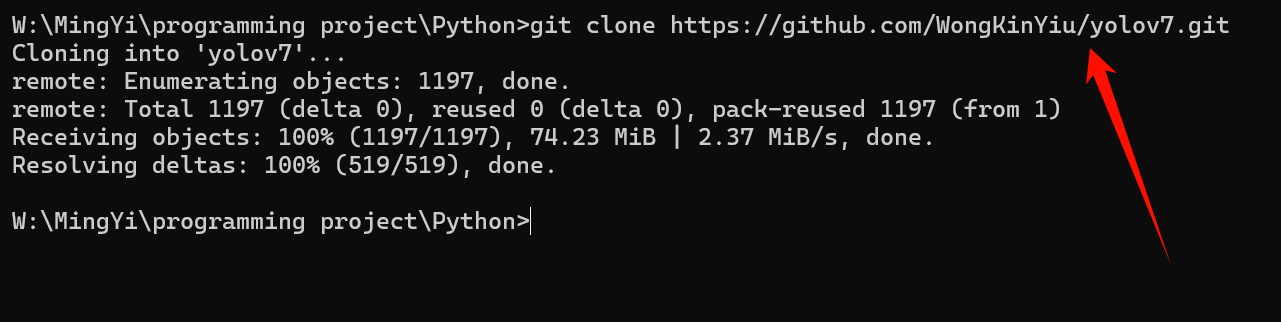
1.1.1 使用git拉取
在使用git拉取时,需要注意网络环境!
git clone https://github.com/WongKinYiu/yolov7.git
cd yolov71、在安装目录输入cmd,直接进入终端
2、使用git指令从GitHub拉取
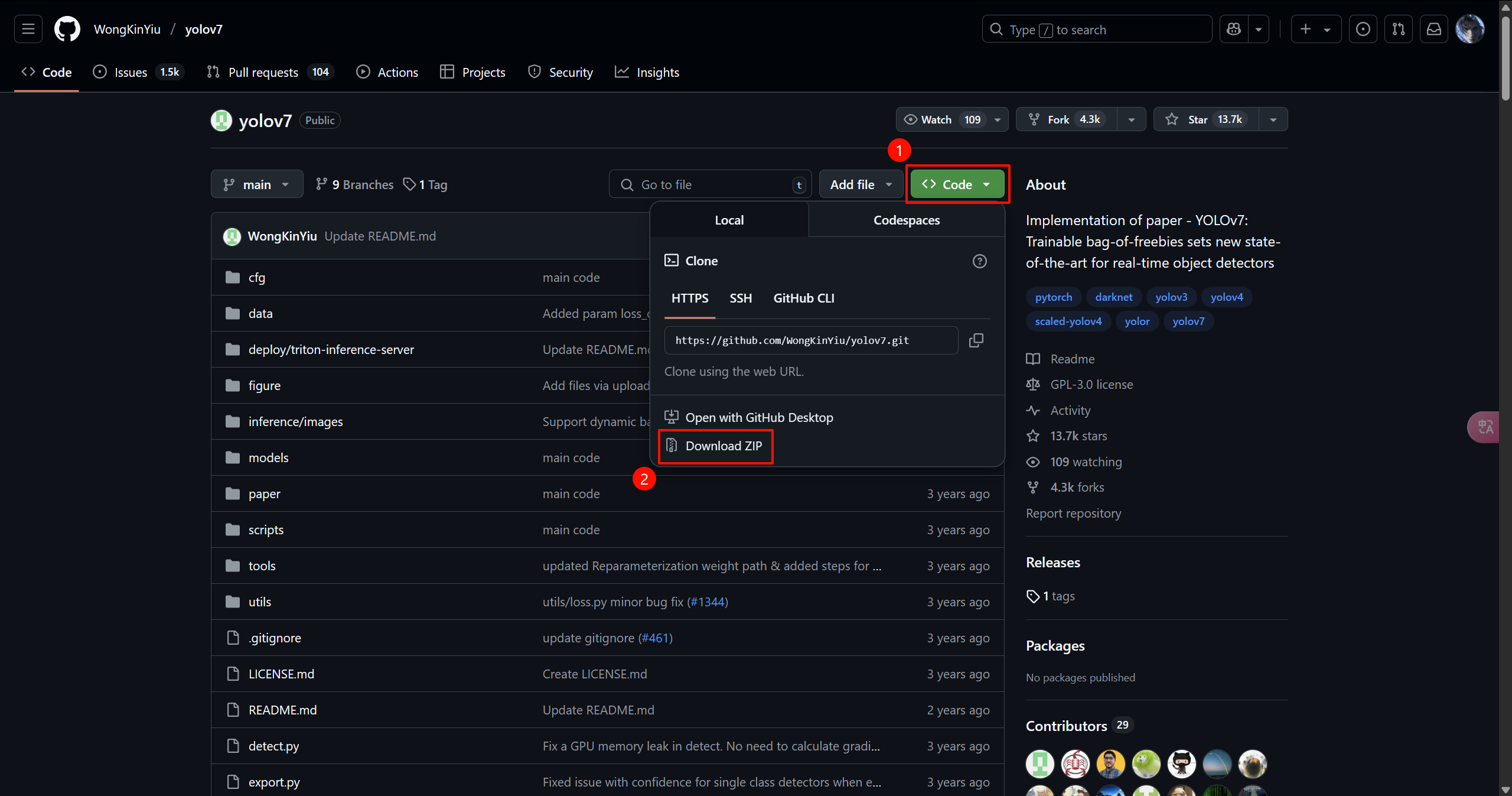
1.1.2 直接下载zip压缩包
下载链接,解压到指定目录即可
1.2 搭建自己的yolov7项目结构
1.2.1 原始项目结构
1.2.2 自定义项目结构和代码
1.2.2.1 整体项目文件
新手小白可能会疑惑,为什么下载下来还需要改项目结构?大佬的目标检测项目是通用的,可以用不同的方式来实现目标检测,但是万变不离其一!你需要根据自己的情况来自定义你的项目。比如,在此教程中是给大家一个我用yolov7算法来实现水果检测的项目,后期可以结合springboot+vue等技术栈搭建自己的web项目(后期可能会出一个教程)
首先,在整体的项目文件中:.engine和.pt文件先不用管,可以对照我的项目文件,把多余的删除!缺的补上!
1.2.2.2 局部目录文件
-
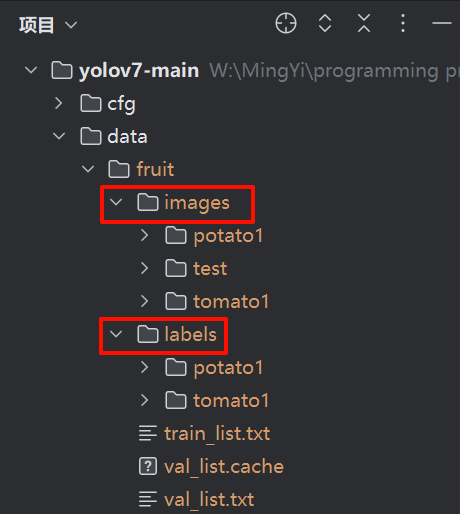
./data目录下创建/fruit目录,在此目录下分别创建/images和/labels目录
-
在yolov7目录下创建weights目录,用于存放模型文件(不知道什么是模型文件的可以不用管)
-
去此链接上下载yolov7模型文件:yolov7.pt
下载完成后放到上面创建的weights目录下。
1.3 修改代码
1.3.1 detect.py文件
此段代码是YOLOv7的推理(检测)核心实现,主要完成以下功能:
-
加载训练好的模型权重(weights/yolov7.pt)
-
处理输入源(图片/视频/摄像头)
-
执行目标检测推理
-
应用非极大值抑制(NMS)
-
可视化结果并保存
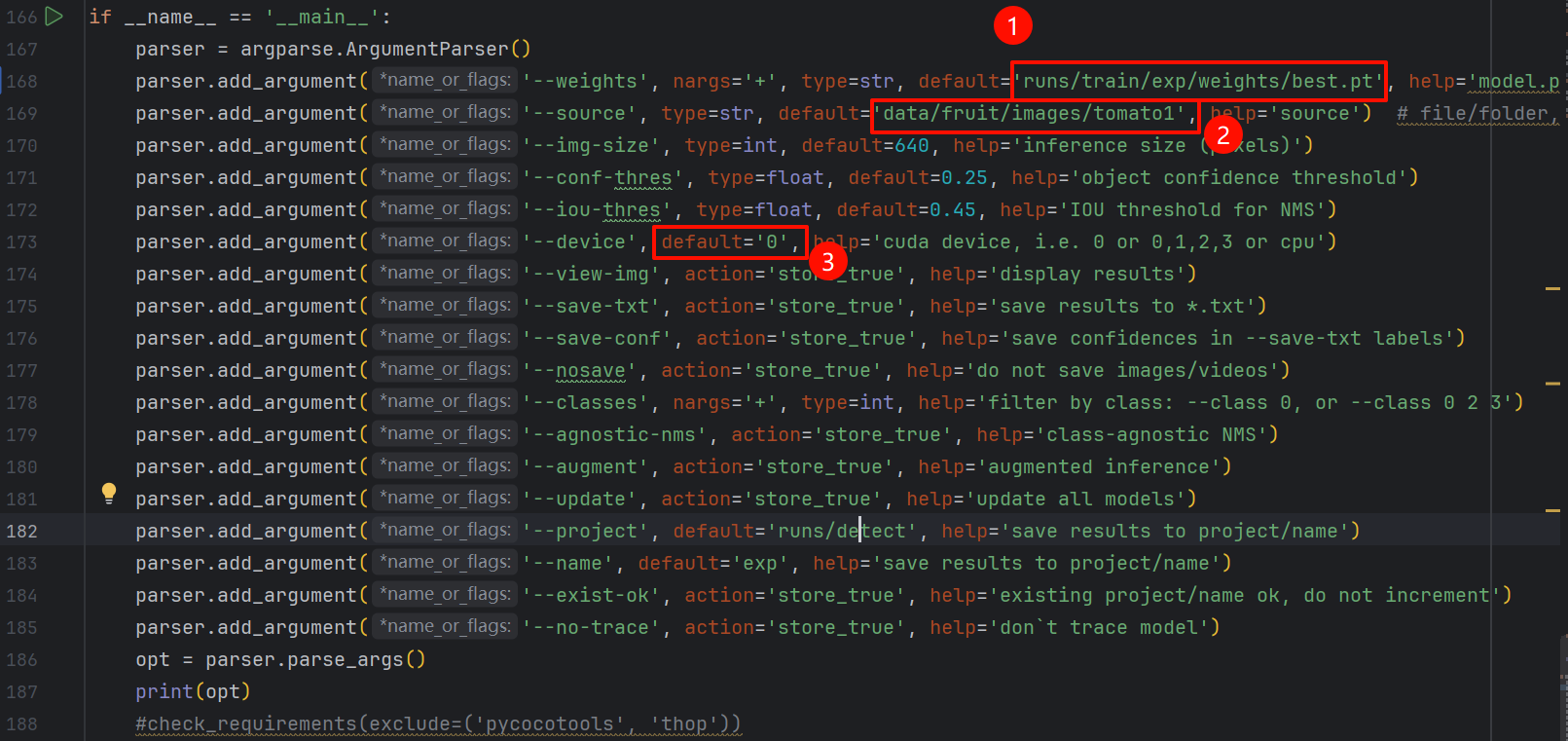
只需要修改如下几个地方的代码:没有对应的目录可以不用管,也不用去创建目录!后面运行train.py会自动创建的
1.3.2 partition_dataset.py文件
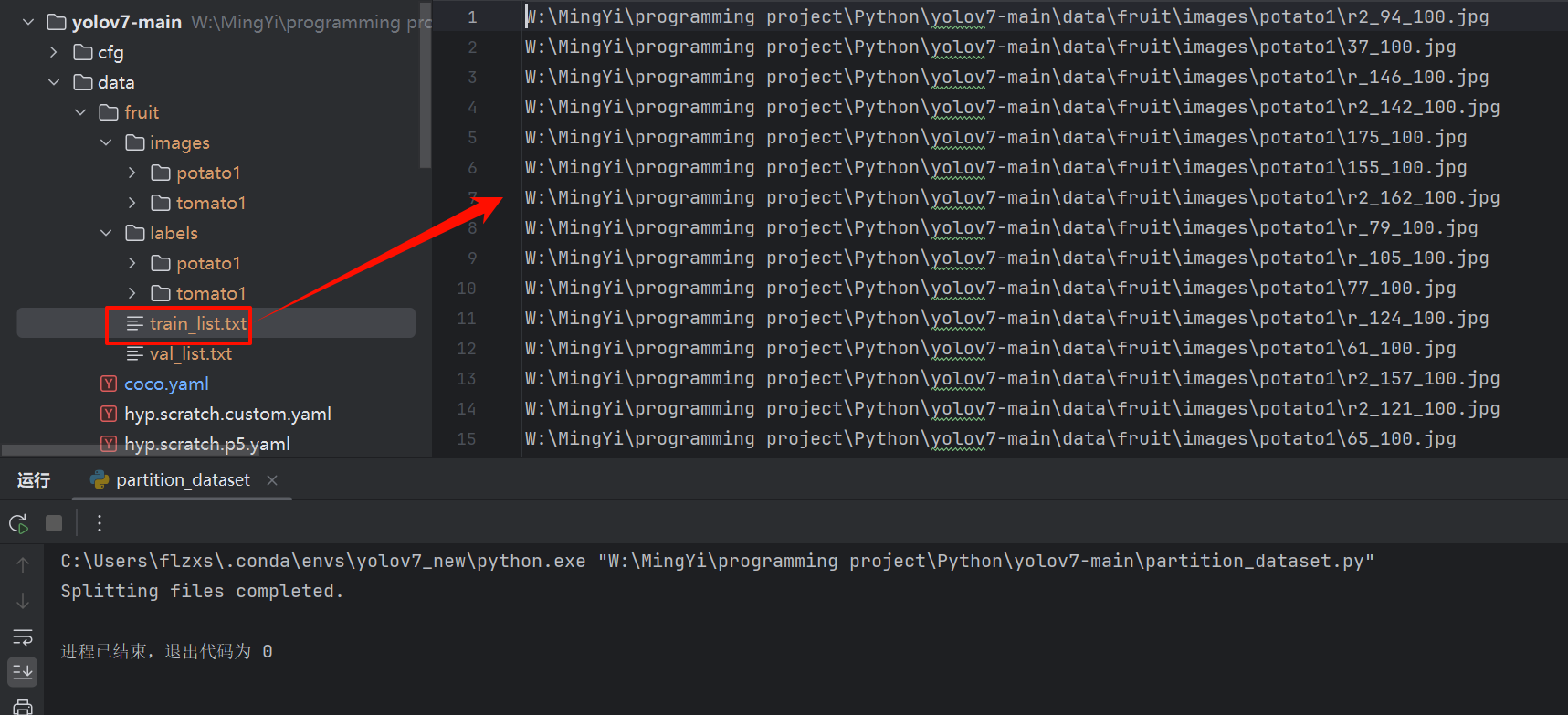
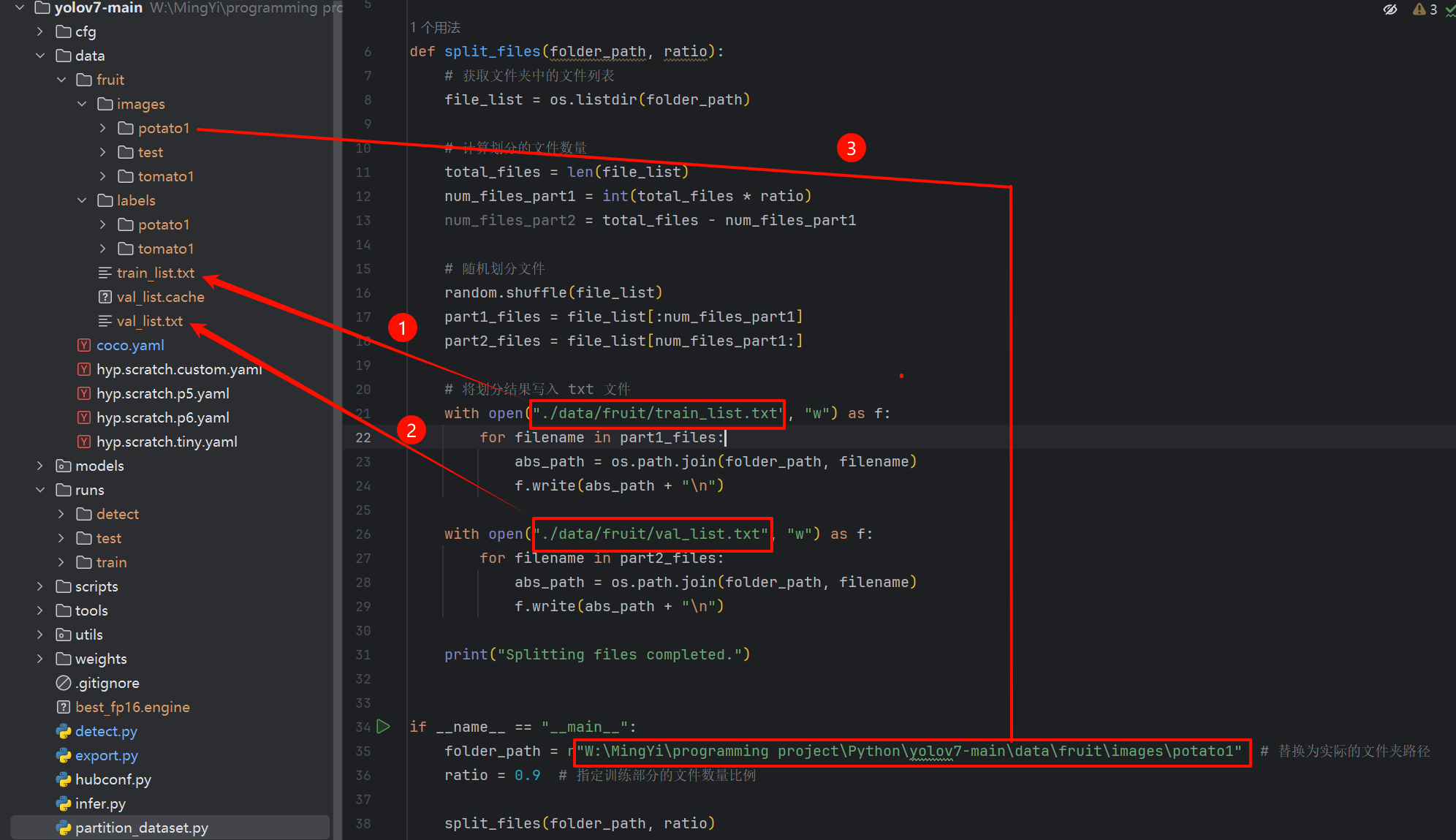
此文件是用来划分数据集的,可以直接使用该代码(注意21、26和35行的图片路径换成你自己的路径)
# 划分数据集
import os
import random
def split_files(folder_path, ratio):
# 获取文件夹中的文件列表
file_list = os.listdir(folder_path)
# 计算划分的文件数量
total_files = len(file_list)
num_files_part1 = int(total_files * ratio)
num_files_part2 = total_files - num_files_part1
# 随机划分文件
random.shuffle(file_list)
part1_files = file_list[:num_files_part1]
part2_files = file_list[num_files_part1:]
# 将划分结果写入 txt 文件
with open("./data/fruit/train_list.txt", "w") as f:
for filename in part1_files:
abs_path = os.path.join(folder_path, filename)
f.write(abs_path + "\n")
with open("./data/fruit/val_list.txt", "w") as f:
for filename in part2_files:
abs_path = os.path.join(folder_path, filename)
f.write(abs_path + "\n")
print("Splitting files completed.")
if __name__ == "__main__":
folder_path = r"W:\MingYi\programming project\Python\yolov7-main\data\fruit\images\potato1" # 替换为实际的文件夹路径
ratio = 0.9 # 指定训练部分的文件数量比例
split_files(folder_path, ratio)1.3.3 coco.yaml文件
train、val键的值分别是:划分训练数据集的文档和验证数据集的文档,指定./data/fruit下即可!运行partition_dataset.py,会在该目录下自动创建这两个文件
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: ./data/fruit/train_list.txt
val: ./data/fruit/val_list.txt
# number of classes
nc: 1
# class names
names: ['potato']如下图:
没有创建这两个文件先不用管,因为还没有配置python环境,代码跑不起来也正常!只需要照上述说的做即可。
1.3.4 infer.py文件
基于 TensorRT 加速的 YOLOv7 目标检测系统,主要功能是通过加载预训练好的 TensorRT 引擎文件(.engine),对图片或摄像头实时画面进行高效的目标检测。直接复制粘贴即可,不知道代码是干嘛的可以问AI来解答
import cv2
import tensorrt as trt
import torch
import numpy as np
from collections import OrderedDict, namedtuple
class TRT_engine():
def __init__(self, weight) -> None:
self.imgsz = [640, 640]
self.weight = weight
self.device = torch.device('cuda:0')
self.init_engine()
def init_engine(self):
# Infer TensorRT Engine
self.Binding = namedtuple('Binding', ('name', 'dtype', 'shape', 'data', 'ptr'))
self.logger = trt.Logger(trt.Logger.INFO)
trt.init_libnvinfer_plugins(self.logger, namespace="")
with open(self.weight, 'rb') as self.f, trt.Runtime(self.logger) as self.runtime:
self.model = self.runtime.deserialize_cuda_engine(self.f.read())
self.bindings = OrderedDict()
self.fp16 = False
print("Available TensorRT Bindings:")
for index in range(self.model.num_bindings):
self.name = self.model.get_tensor_name(index) # 使用新 API
self.dtype = trt.nptype(self.model.get_binding_dtype(index))
self.shape = tuple(self.model.get_binding_shape(index))
self.data = torch.from_numpy(np.empty(self.shape, dtype=np.dtype(self.dtype))).to(self.device)
self.bindings[self.name] = self.Binding(self.name, self.dtype, self.shape, self.data,
int(self.data.data_ptr()))
if self.model.binding_is_input(index) and self.dtype == np.float16:
self.fp16 = True
print(f" {index}: {self.name} -> shape={self.shape}, dtype={self.dtype}")
self.binding_addrs = OrderedDict((n, d.ptr) for n, d in self.bindings.items())
self.context = self.model.create_execution_context()
def preprocess(self, image):
# 检查图像是否为空
if image is None:
raise ValueError("图像加载失败,请检查路径是否正确。")
img = cv2.resize(image, (640, 640))
img = img.transpose((2, 0, 1))
img = np.expand_dims(img, 0)
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(self.device)
img = img.float()
return img
def predict(self, img, threshold):
img = self.preprocess(img)
self.binding_addrs['images'] = int(img.data_ptr())
self.context.execute_v2(list(self.binding_addrs.values()))
# 获取输出结果
output = self.bindings['output'].data.cpu().numpy() # 转为 NumPy 数组
# 解析 YOLOv7 输出
batch, num_anchors, grid_h, grid_w, num_attrs = output.shape # (1, 3, 80, 80, 6)
detections = output.reshape(-1, 6) # 转成 (N, 6) 形式
new_bboxes = []
for det in detections:
x, y, w, h, conf, cls = det
# 如果存在 NaN 或者置信度低于阈值,则跳过该框
if np.any(np.isnan(det)) or conf < threshold:
continue
# 转换 bbox 形式 (cx, cy, w, h) -> (xmin, ymin, xmax, ymax)
xmin = (x - w / 2)
ymin = (y - h / 2)
xmax = (x + w / 2)
ymax = (y + h / 2)
new_bboxes.append([cls, conf, xmin, ymin, xmax, ymax])
return new_bboxes
def visualize(img, bbox_array):
for temp in bbox_array:
xmin, ymin, xmax, ymax = map(int, temp[2:6])
# 检查坐标是否合法
if xmin < 0 or ymin < 0 or xmax < 0 or ymax < 0:
continue # 跳过无效的框
clas = int(temp[0])
score = temp[1]
cv2.rectangle(img, (xmin, ymin), (xmax, ymax), (105, 237, 249), 2)
img = cv2.putText(img, f"class:{clas} {round(score, 2)}", (xmin, ymin - 5),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (105, 237, 249), 1)
return img
def process_image(img_path, trt_engine):
img = cv2.imread(img_path)
if img is None:
print(f"无法读取图像文件: {img_path}")
return
results = trt_engine.predict(img, threshold=0.5)
img = visualize(img, results)
cv2.imshow("img", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 用户输入选择
print("选择模式:输入 1 预测单张图片,输入 2 进行摄像头实时检测: ")
mode = input()
trt_engine = TRT_engine("./best_fp16.engine")
if mode == "1":
img_path = input("请输入图片路径: ")
process_image(img_path, trt_engine)
elif mode == "2":
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
if not ret:
break
results = trt_engine.predict(frame, threshold=0.5)
frame = visualize(frame, results)
cv2.imshow("Camera", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()1.3.5 test.py文件
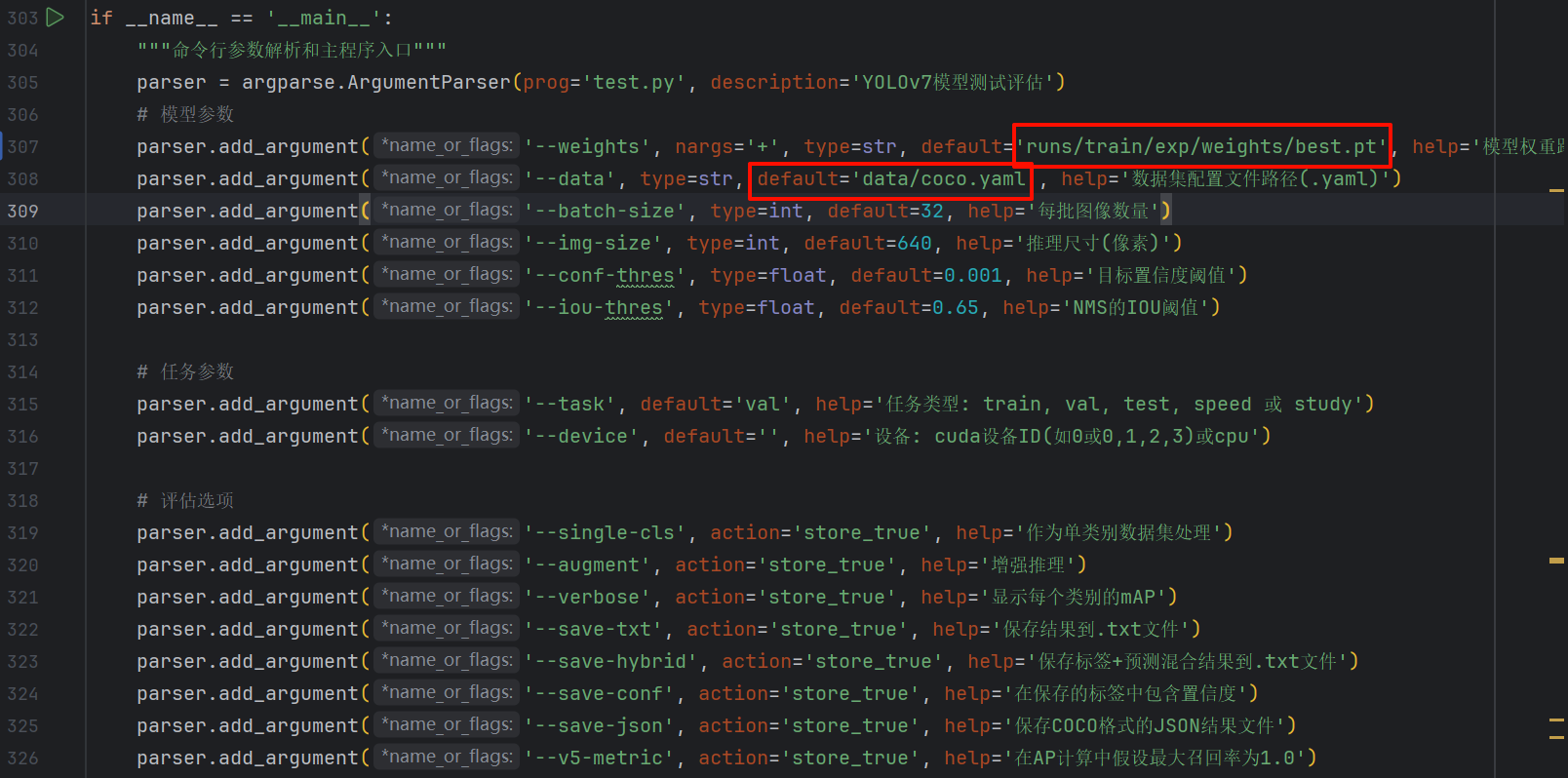
.pt权重文件的路径先不用管,运行train.py会自动创建改目录结构的!
1.3.6 train.py文件
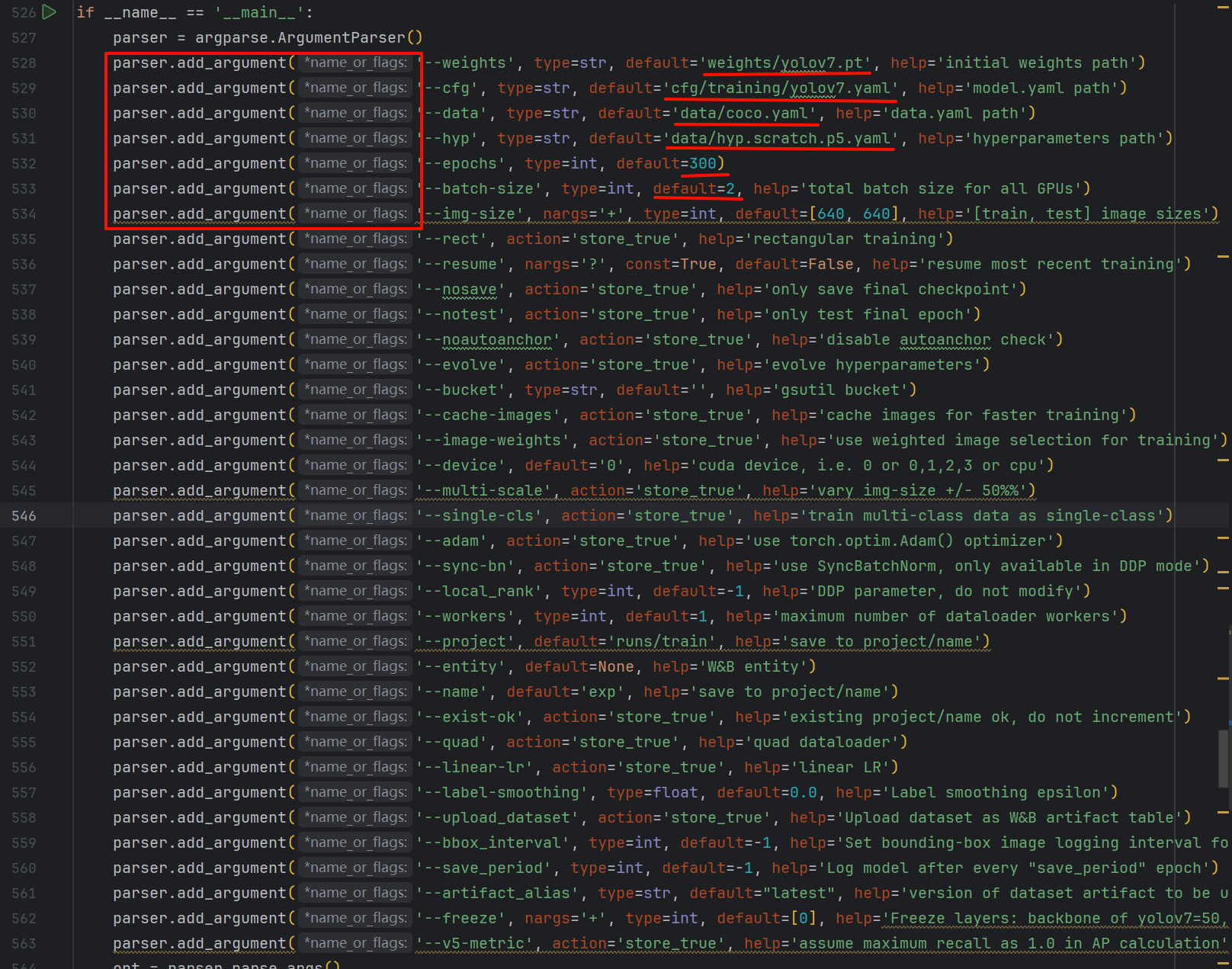
参数做参考,batch-size参数是指GPU显存大小(我的是4G的,指定为2)代码有不懂的地方直接问AI。
2. 项目结构分析
2.1 核心目录
cfg/目录
包含了各种模型配置文件:
-
deploy/:部署相关的配置文件
-
yolov7.yaml:标准YOLOv7模型配置
-
yolov7-tiny.yaml:轻量级模型配置
-
yolov7x.yaml:更大规模的模型配置
-
-
training/:训练相关的配置文件
models/目录
-
common.py:基础网络模块
-
experimental.py:实验性网络模块
-
yolo.py:YOLO模型的核心实现
utils/目录
-
datasets.py:数据集加载和预处理
-
general.py:通用工具函数
-
torch_utils.py:PyTorch相关工具函数
-
plots.py:可视化工具
-
metrics.py:评估指标计算
2.2 核心文件
train.py
训练脚本,主要功能:
-
加载数据集和模型配置
-
初始化模型和优化器
-
训练循环和验证
-
保存检查点
主要参数:
python train.py --data data/coco.yaml --cfg cfg/training/yolov7.yaml --weights '' --batch-size 32detect.py
目标检测脚本,主要功能:
-
加载预训练模型
-
图像预处理
-
目标检测和后处理
-
结果可视化
主要参数:
python detect.py --weights weights/yolov7.pt --source images/test.py
测试脚本,用于评估模型性能:
-
加载测试数据集
-
运行推理
-
计算评估指标
export.py
3. 核心代码解析
3.1 detect.py解析
-
参数配置
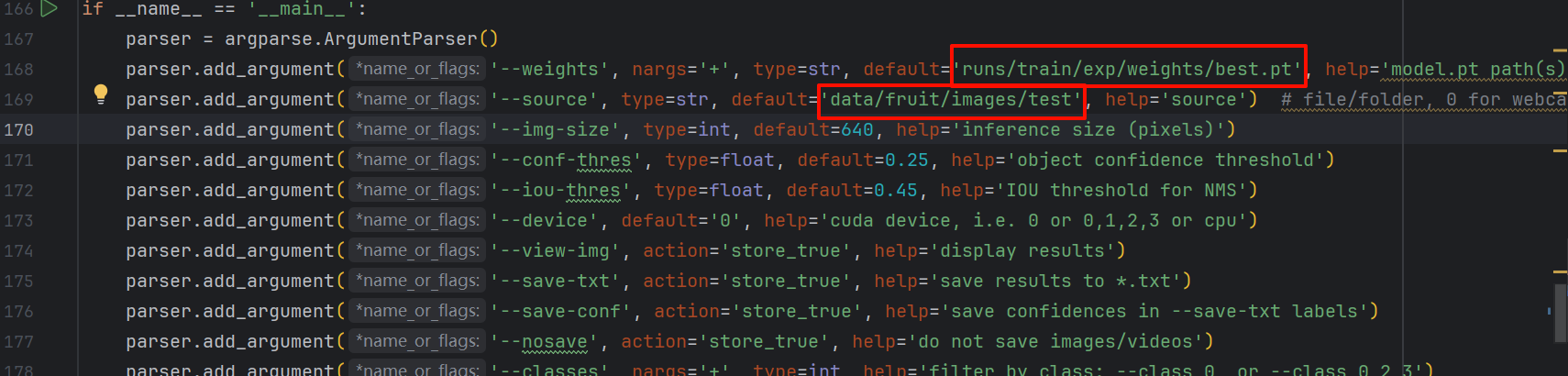
parser.add_argument('--weights', type=str, default='runs/train/exp/weights/best.pt', help='模型权重路径')
parser.add_argument('--source', type=str, default='data/fruit/images/test', help='图像/视频源')
parser.add_argument('--img-size', type=int, default=640, help='推理尺寸')
parser.add_argument('--conf-thres', type=float, default=0.25, help='置信度阈值')
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IOU阈值')-
模型加载
model = attempt_load(weights, map_location=device) # 加载FP32模型
stride = int(model.stride.max()) # 获取模型步长
imgsz = check_img_size(imgsz, s=stride) # 检查图像尺寸-
数据加载
if webcam:
dataset = LoadStreams(source, img_size=imgsz, stride=stride)
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride)-
推理过程
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float()
img /= 255.0
pred = model(img, augment=opt.augment)[0]
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres)以下是针对 train.py 的详细解析,结合代码结构和实际训练流程进行模块化说明:
3.2 train.py 解析
1. 参数配置与初始化
# 关键参数示例(简化版)
parser.add_argument('--weights', type=str, default='weights/yolov7.pt', help='预训练权重路径')
parser.add_argument('--cfg', type=str, default='models/yolov7.yaml', help='模型配置文件')
parser.add_argument('--data', type=str, default='data/coco.yaml', help='数据集配置文件')
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.p5.yaml', help='超参数文件')
parser.add_argument('--epochs', type=int, default=300, help='训练总轮次')
parser.add_argument('--batch-size', type=int, default=32, help='批量大小')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[训练, 测试] 图像尺寸')
parser.add_argument('--device', default='0', help='GPU设备编号')2. 数据准备
2.1 数据配置加载
with open(opt.data) as f:
data_dict = yaml.safe_load(f) # 从YAML加载数据集配置
train_path = data_dict['train'] # 训练集路径
val_path = data_dict['val'] # 验证集路径
nc = int(data_dict['nc']) # 类别数
names = data_dict['names'] # 类别名称2.2 数据增强设置
通过 hyp.yaml 文件配置增强参数:
# hyp.yaml 示例
hsv_h: 0.015 # 色调增强幅度
hsv_s: 0.7 # 饱和度增强幅度
flipud: 0.5 # 上下翻转概率
mosaic: 1.0 # Mosaic增强概率2.3 数据加载器
train_loader = create_dataloader(
train_path,
imgsz=opt.img_size[0],
batch_size=opt.batch_size,
augment=True, # 启用增强
hyp=hyp, # 超参数
rect=opt.rect, # 矩形训练
cache=opt.cache_images # 缓存图像
)[0]3. 模型构建
3.1 模型初始化
model = Model(opt.cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device)
if opt.weights.endswith('.pt'):
ckpt = torch.load(opt.weights, map_location=device)
model.load_state_dict(ckpt['model'].float().state_dict()) # 加载预训练权重3.2 冻结层(可选)
freeze = [f'model.{x}.' for x in range(5)] # 冻结前5层
for k, v in model.named_parameters():
if any(x in k for x in freeze):
v.requires_grad = False # 冻结梯度4. 训练配置
4.1 优化器设置
# 参数分组(权重、偏置、BN层)
pg0 = [p for n, p in model.named_parameters() if 'bias' in n]
pg1 = [p for n, p in model.named_parameters() if 'weight' in n and 'bn' not in n]
optimizer = optim.SGD(pg0, lr=hyp['lr0'], momentum=hyp['momentum'])
optimizer.add_param_group({'params': pg1, 'weight_decay': hyp['weight_decay']})4.2 学习率调度
lf = lambda x: (1 - x / epochs) * (1.0 - hyp['lrf']) + hyp['lrf'] # 线性衰减
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)4.3 损失函数
compute_loss = ComputeLoss(model, hyp) # 包含分类/回归/目标损失5. 训练循环
5.1 单批次训练流程
for epoch in range(epochs):
for i, (imgs, targets, _, _) in enumerate(train_loader):
imgs = imgs.to(device).float() / 255.0
# 前向传播
pred = model(imgs)
loss, loss_items = compute_loss(pred, targets.to(device))
# 反向传播
scaler.scale(loss).backward()
if ni % accumulate == 0:
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
# 日志记录
mloss = (mloss * i + loss_items) / (i + 1)5.2 验证与保存
if epoch % opt.eval_interval == 0:
results = test.test(opt.data, model=ema.ema, dataloader=val_loader)
fitness = results[2] # mAP@0.5
# 保存最佳模型
if fitness > best_fitness:
torch.save(ckpt, 'best.pt')6. 关键技术与优化
-
EMA (指数移动平均)
ema = ModelEMA(model) # 平滑模型参数,提升泛化性 -
混合精度训练
scaler = amp.GradScaler(enabled=cuda) # 加速训练,减少显存占用 -
多尺度训练
if opt.multi_scale: img_size = random.randrange(imgsz * 0.5, imgsz * 1.5 + gs) // gs * gs -
自动锚框调整
if not opt.noautoanchor: check_anchors(dataset, model=model, thr=hyp['anchor_t'])
7. 输出与日志
-
训练日志示例
Epoch GPU_mem box_loss obj_loss cls_loss total targets 0/299 3.2G 0.123 0.456 0.078 0.657 32 -
结果保存
-
runs/train/exp/weights/best.pt:最佳模型 -
runs/train/exp/results.txt:训练指标记录
-
3.3 test.py解析
-
参数配置
parser.add_argument('--weights', type=str, default='', help='模型权重路径')
parser.add_argument('--data', type=str, default='data/coco.yaml', help='数据集配置文件路径')
parser.add_argument('--batch-size', type=int,default=32, help='批量大小')
parser.add_argument('--img-size', type=int, default=640, help='推理尺寸')
parser.add_argument('--conf-thres', type=float, default=0.001, help='置信度阈值')
parser.add_argument('--iou-thres', type=float, default=0.65, help='NMS IOU阈值')
parser.add_argument('--task', default='val', help='val, test或speed')
parser.add_argument('--device', default='', help='cuda设备,如0或0,1,2,3')-
模型加载与准备
model = attempt_load(weights, map_location=device) # 加载FP32模型
imgsz = check_img_size(imgsz, s=model.stride.max()) # 检查图像尺寸
if half:
model.half() # 转为FP16推理-
数据加载器初始化
dataloader = create_dataloader(data[task],
imgsz,
batch_size,
model.stride.max(),
opt,
pad=0.5,
rect=True)[0]-
测试流程
for batch_i, (img, targets, paths, shapes) in enumerate(tqdm(dataloader)):
img = img.to(device, non_blocking=True)
img = img.half() if half else img.float()
img /= 255.0
# 推理
out, train_out = model(img, augment=augment)
# NMS处理
out = non_max_suppression(out, conf_thres, iou_thres)
# 统计指标
stats = process_batch(out, targets, iouv)-
结果计算与输出
# 计算mAP
mp, mr, map50, map = ap_per_class(*stats)
# 打印结果
print_results(mp, mr, map50, map, names)3.4 export.py解析
-
参数配置
parser.add_argument('--weights', type=str, default='./runs/train/best.pt', help='模型权重路径')
parser.add_argument('--img-size', nargs='+', type=int, default=[640,640], help='输入图像尺寸')
parser.add_argument('--batch-size', type=int, default=1, help='批量大小')
parser.add_argument('--device', default='0', help='导出设备')
parser.add_argument('--format', type=str, default='onnx', help='导出格式: onnx, torchscript')
parser.add_argument('--simplify', action='store_true', help='简化ONNX模型')
parser.add_argument('--dynamic', action='store_true', help='动态输入/输出维度')-
模型加载与检查
model = attempt_load(weights, map_location=device) # 加载FP32模型
model.eval()
for k, m in model.named_modules():
if hasattr(m, 'convert'):
m.convert = convert # 转换自定义层-
输入示例准备
img = torch.zeros(batch_size, 3, *img_size).to(device) # 创建虚拟输入-
模型导出
if format == 'onnx':
torch.onnx.export(
model, # 模型
img, # 输入示例
f, # 输出文件
verbose=False,
opset_version=12,
input_names=['images'],
output_names=['output'],
dynamic_axes=dynamic_axes if dynamic else None
)
# 简化ONNX模型
if simplify:
simplify_onnx(f)
elif format == 'torchscript':
model_ts = torch.jit.trace(model, img, strict=False)
model_ts.save(f)-
导出后验证
# 验证导出模型
if format == 'onnx':
check_onnx(f) # 检查ONNX模型有效性
print(f'Export complete. Results saved to {f}')3.5 各模块核心功能对比
| 模块 | 核心功能 | 关键参数 |
|---|---|---|
| detect.py | 单张图像/视频流的目标检测 | weights, source, conf-thres, iou-thres |
| train.py | 模型训练,包括数据准备、模型优化、训练循环和验证 | weights, cfg, data, epochs, batch-size, hyp |
| test.py | 模型性能评估,计算mAP等指标 | weights, data, batch-size, task, conf-thres, iou-thres |
| export.py | 模型格式转换,支持ONNX/TorchScript等格式导出 | weights, img-size, batch-size, format, dynamic |
3.6 总结-流程图
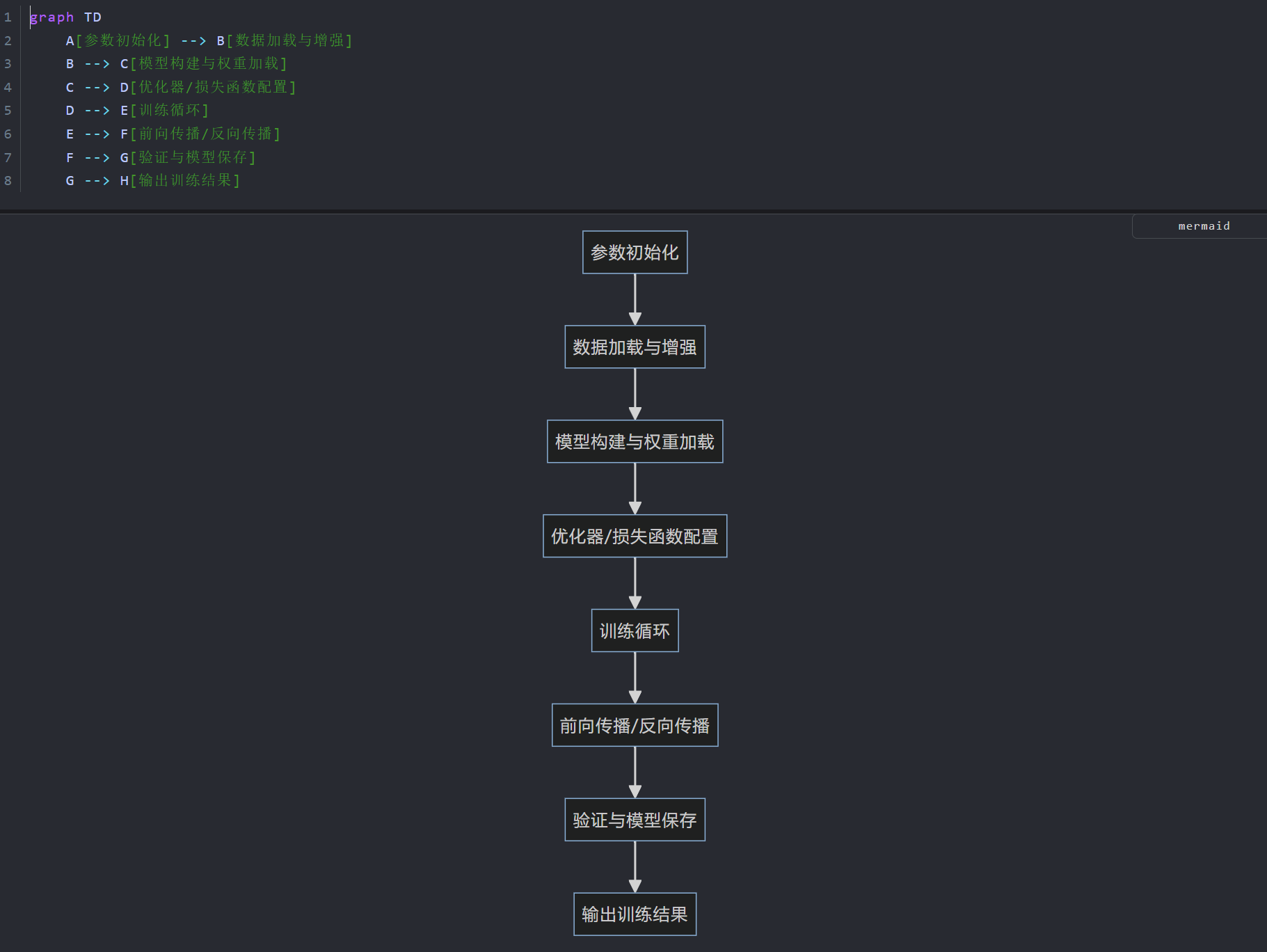
4. 环境搭建
4.1 安装python环境
安装完成后,配置系统环境变量:
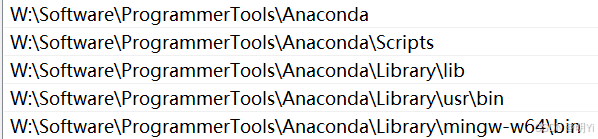
conda -V # 查看是否成功4.2 使用GPU还是CPU训练?
-
Nvidia显卡支持使用GPU训练,但是需要安装cuda和cudnn
-
AMD和intel显卡目前只能用CPU训练
4.3 GPU训练模型
4.3.1 安装配置cuda和cudnn
下载完成后,直接运行.exe默认安装,配置系统环境变量:

nvcc -V # 检查NVIDIA CUDA编译器(nvcc)的版本
nvidia-smi # 监控和管理NVIDIA GPU设备的工具包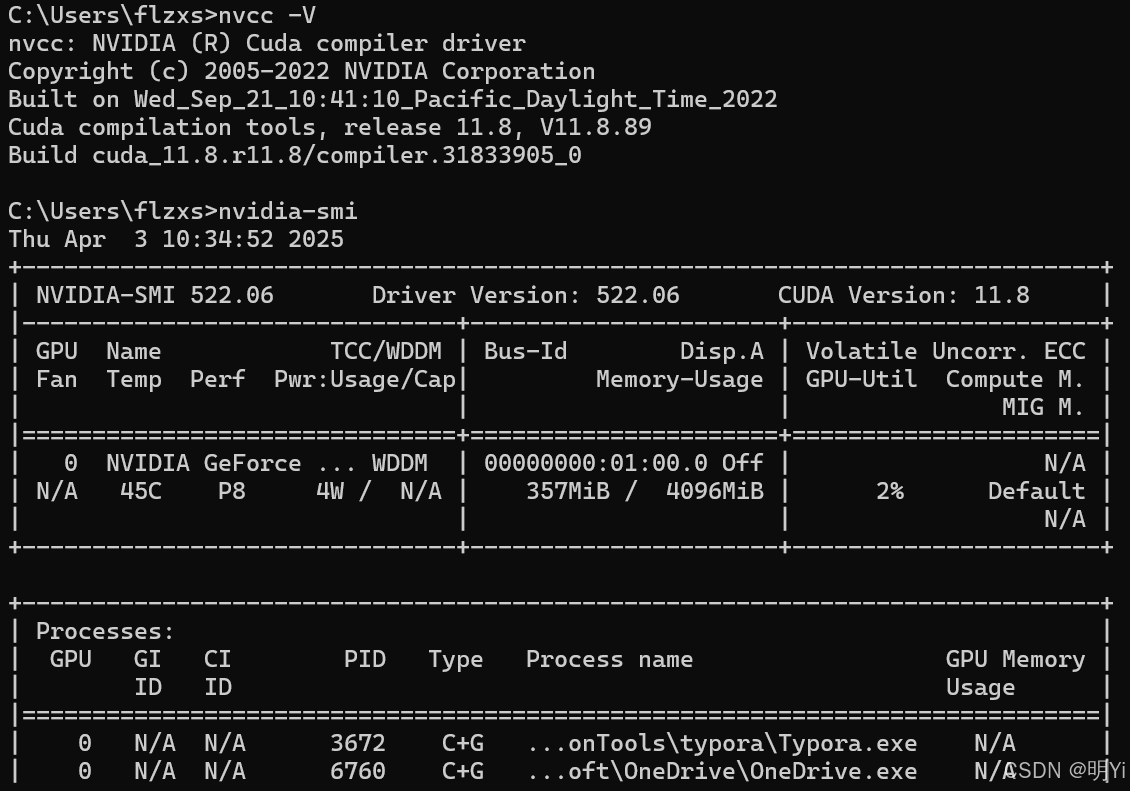
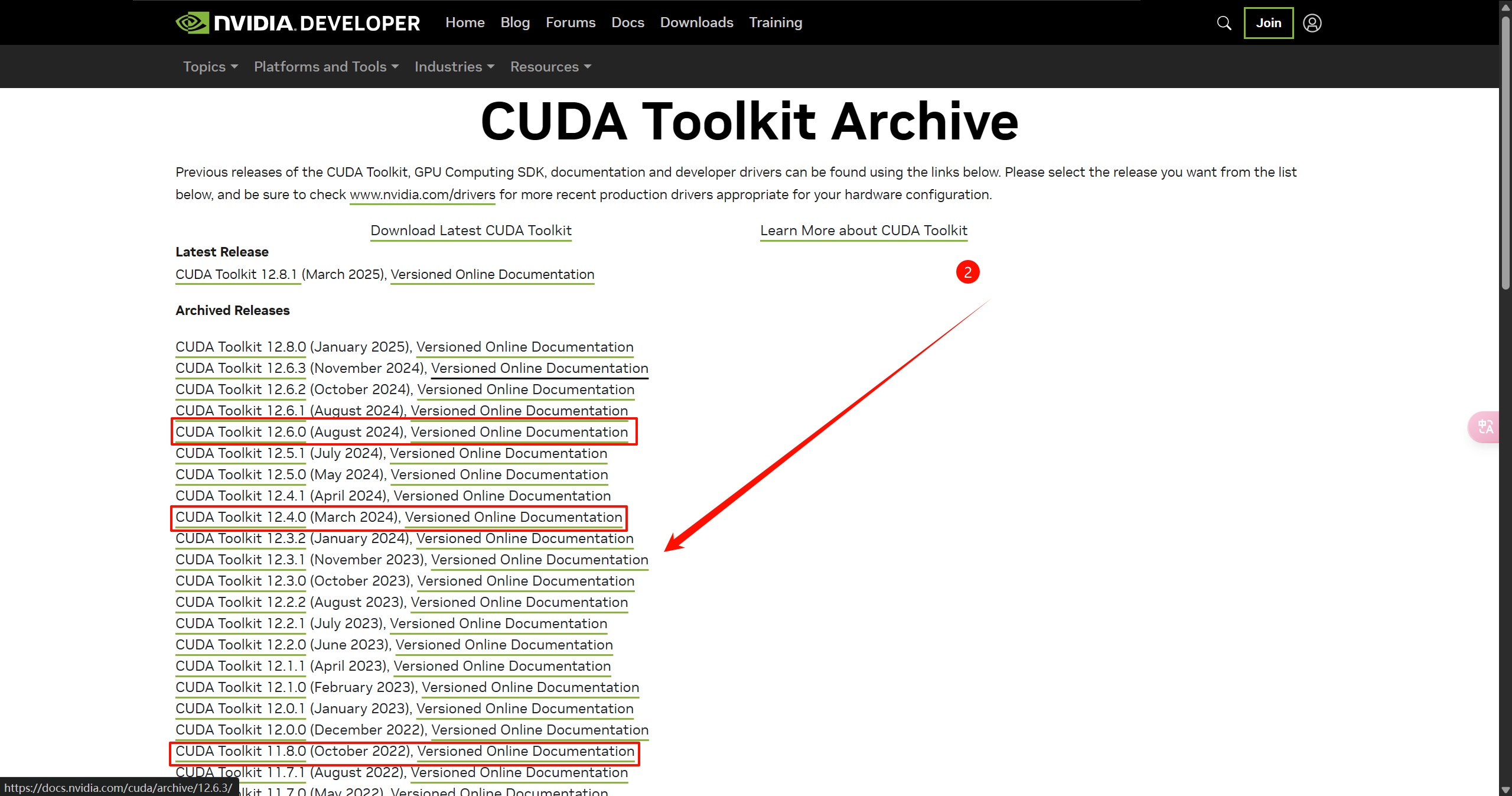
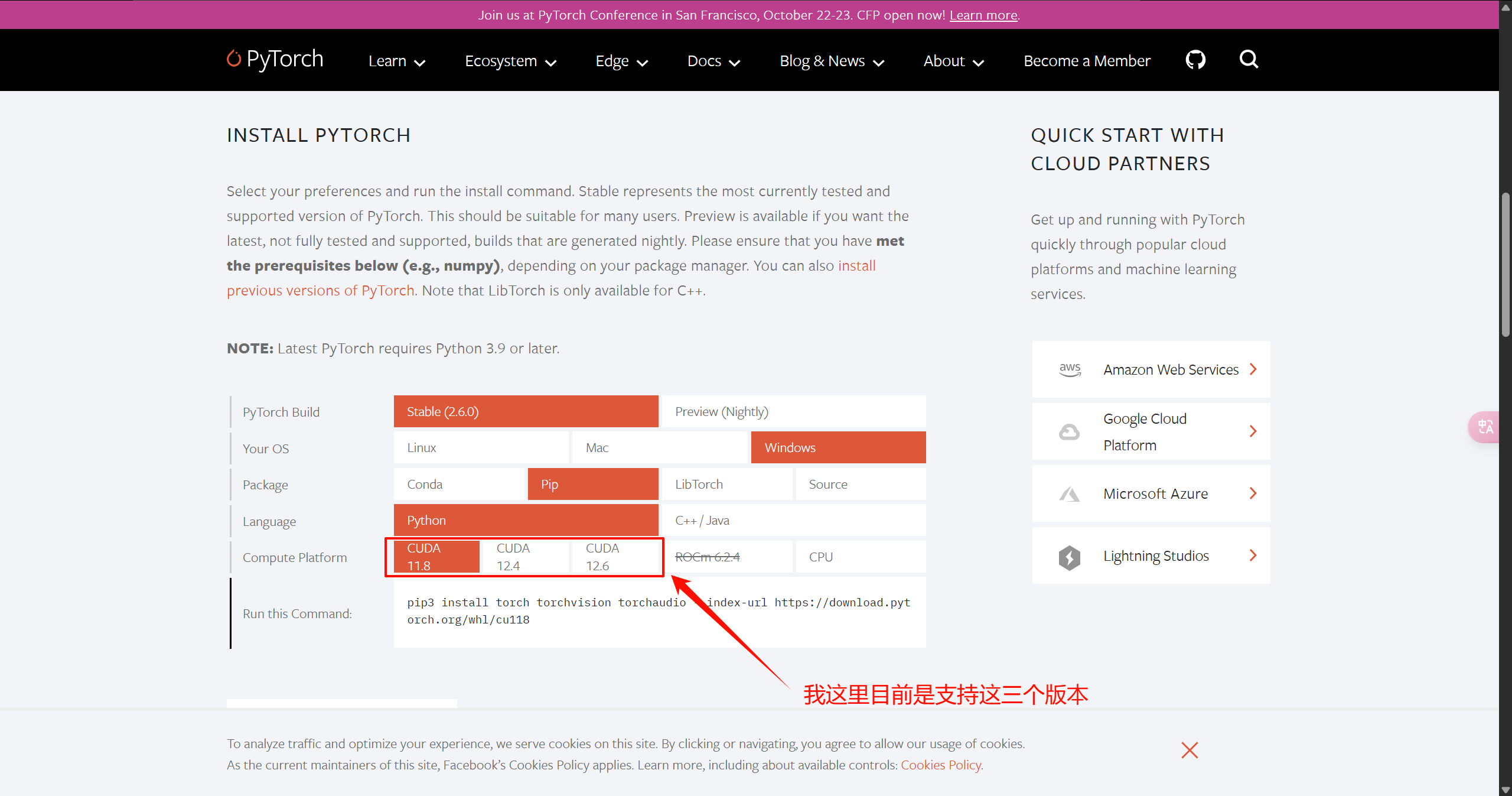
注意这里的cuda版本选择:先去pytorch官网查看支持哪几个版本的cuda,如下:
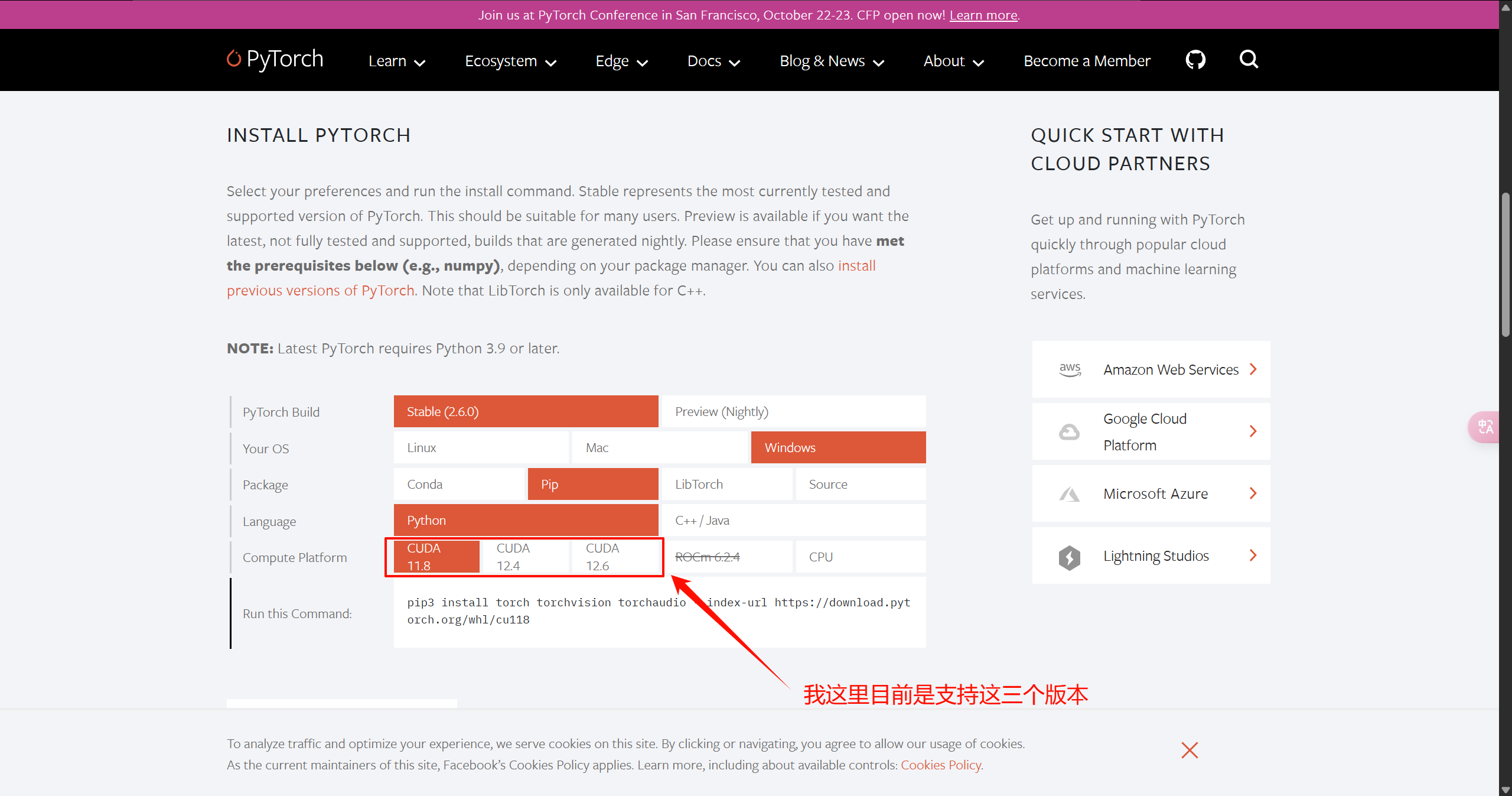
选择和pytorch对应的cuda版本下载即可
注意:cudnn的版本要和cuda一致!
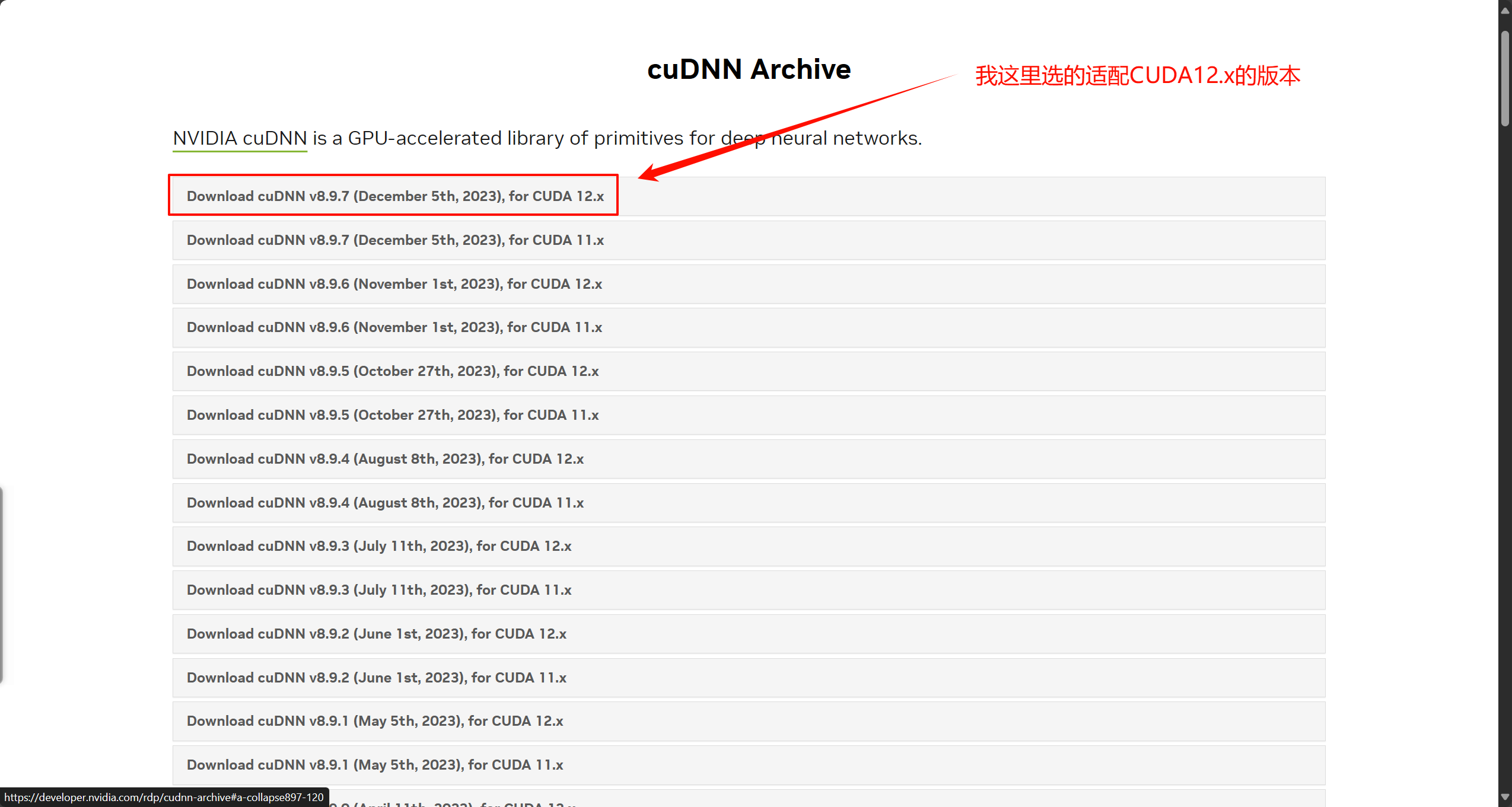
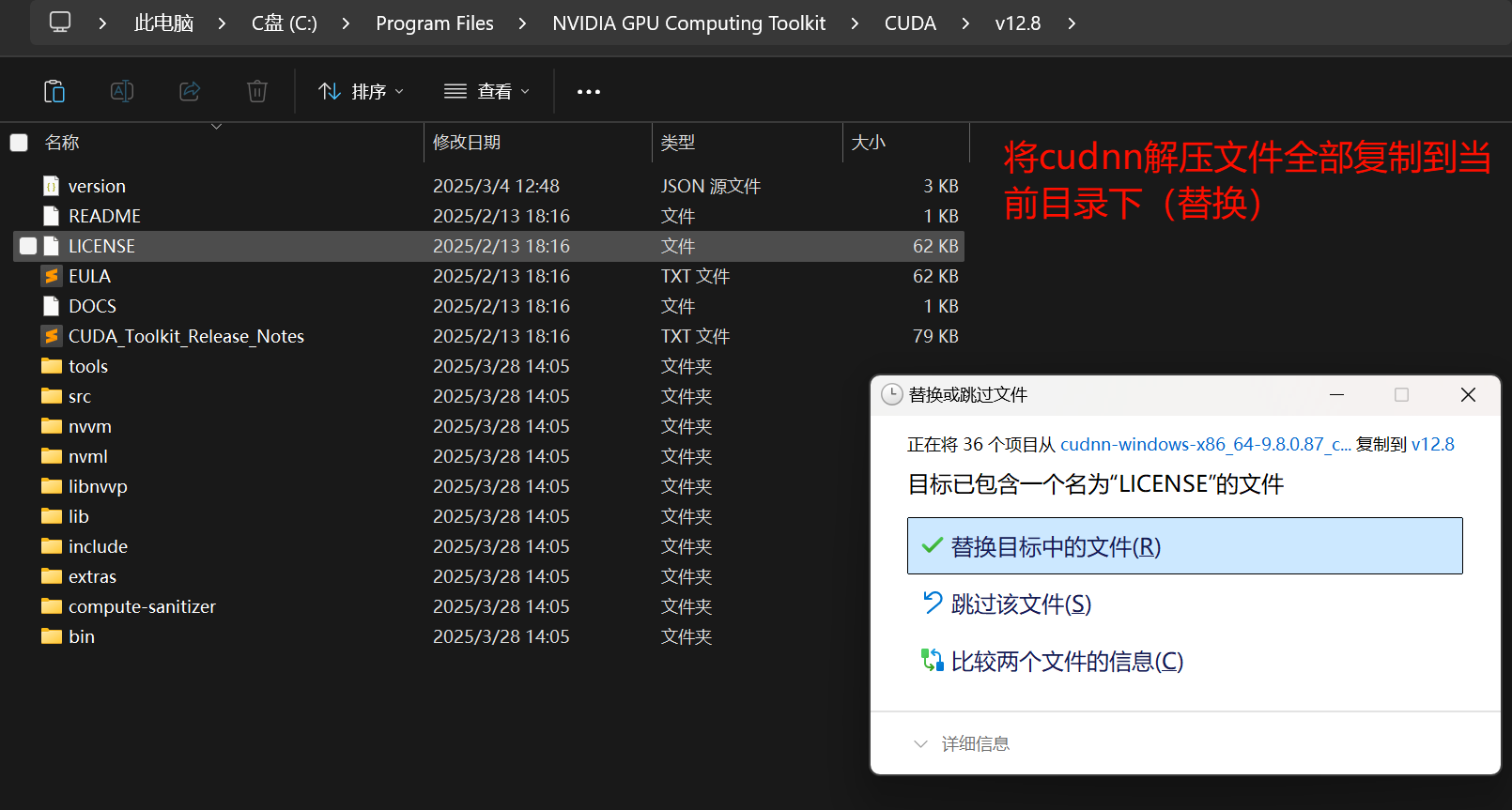
将下载的cudnn文件解压到cuda的安装目录:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8,选择替换
4.3.2 创建conda环境
-
Win+R打开Windows终端创建名为yolov7的conda环境,指定python版本3.10:
conda create -n yolov7 python=3.10-
激活创建的环境:
conda activate yolov7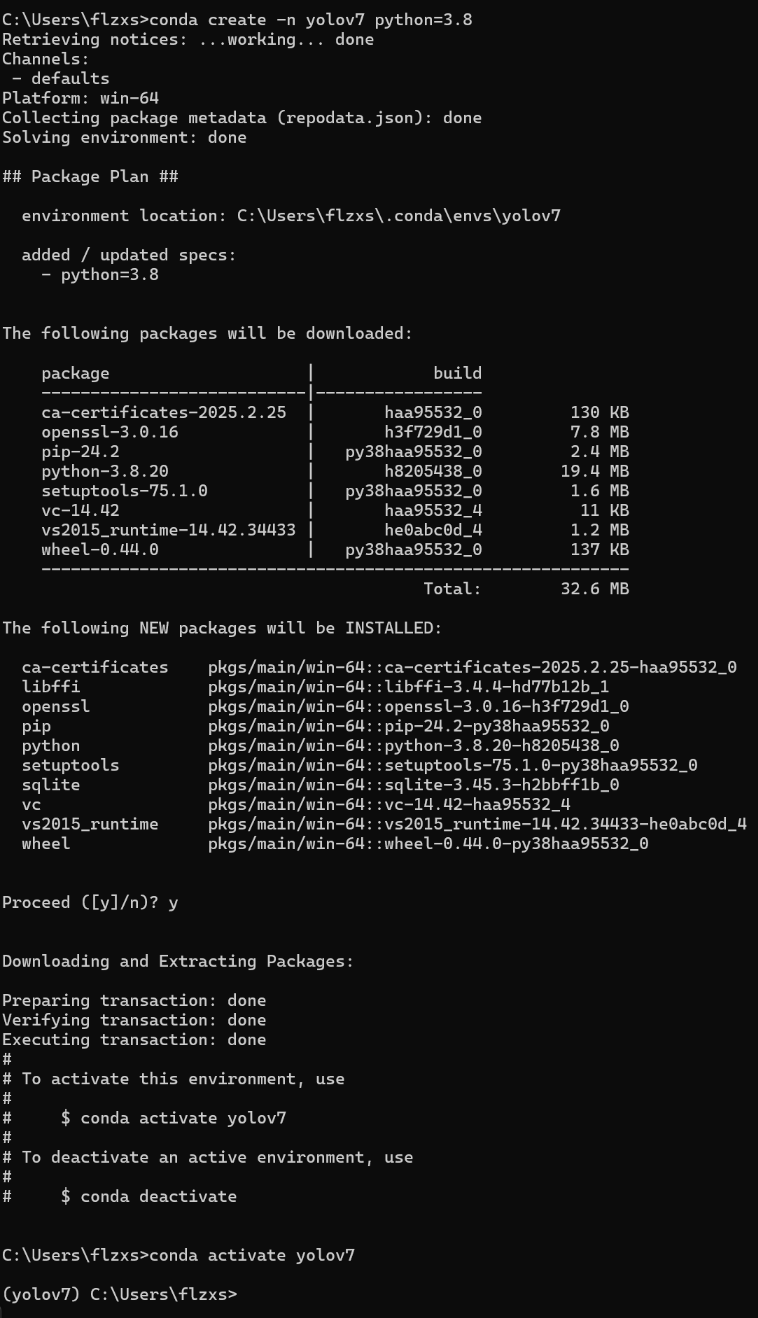
-
首先进入终端,路径为yolov7的项目路径,然后激活创建环境,安装requirements.txt文档中的依赖:因为requirements.txt在yolov7目录下,将文档中的依赖安装到已创建的conda环境中。
pip install -i Verifying - USTC Mirrors -r requirements.txt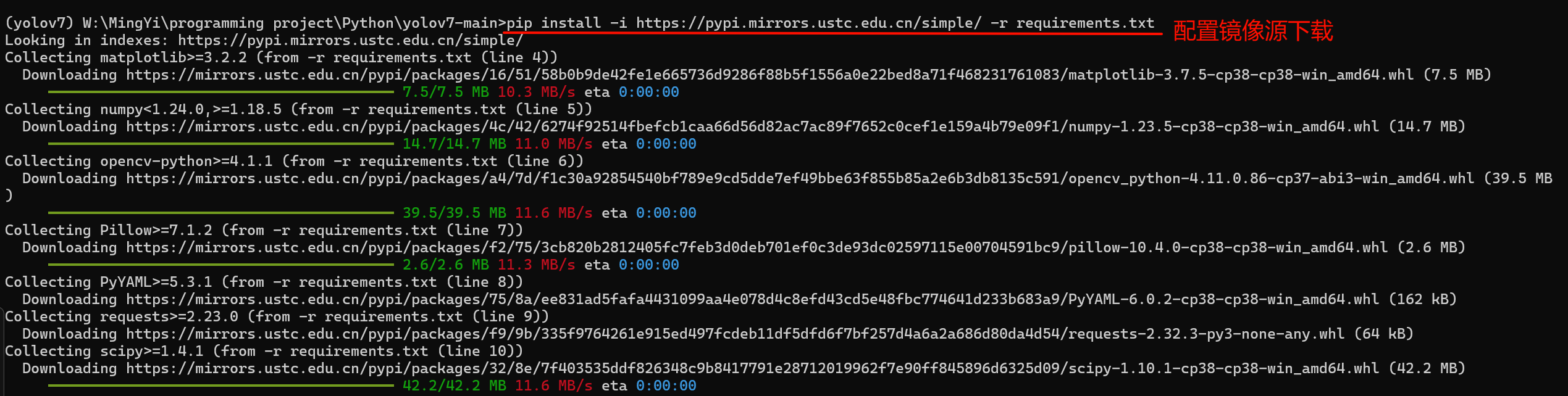
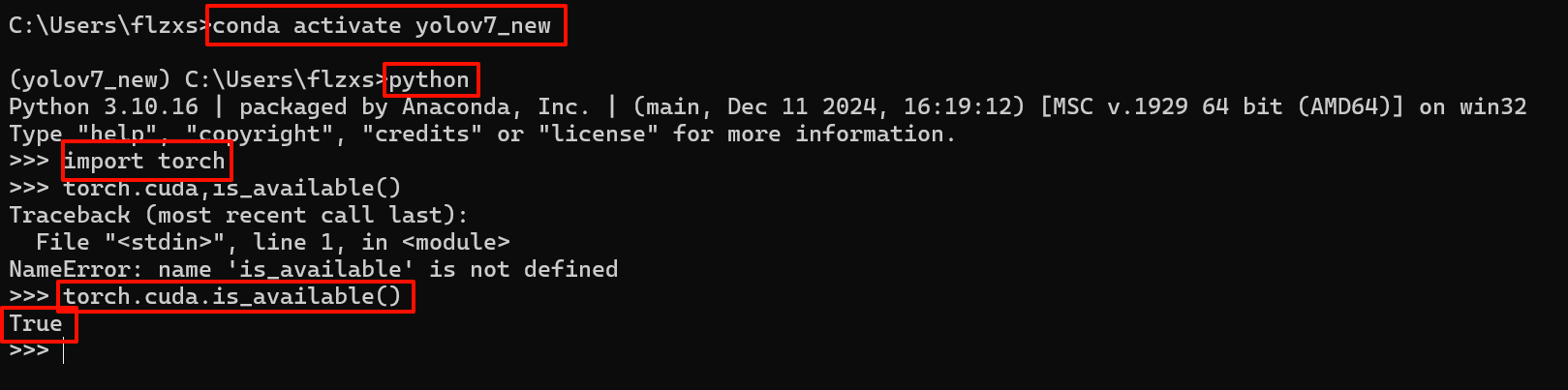
检测torch能否调用cuda:
如果是像如下显示False,说明:cuda版本和torch版本不匹配导致的!你需要回到上面的cuda安装:详细阅读要求(cuda版本和pytorch版本一致!)
注:使用exit()来退出当前的python环境

import torch
torch.cuda.is_available()首先删除原先的pytorch:
pip uninstall pytorch torch torchvision torchaudio -y然后在你的conda环境中重新安装:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
再次检查:返回True即可
4.4 CPU训练模型
除了不用下载cuda和cudnn意外,步骤2:创建conda环境,都是一样的。
4.5 数据标注工具labelimg
先退出当前环境:
conda deactivate
重新创建labelimg环境:我试了一下这里的python版本3.6最稳定(如果是3.10使用该工具时会出现闪退!)
conda create -n yolov7 python=3.6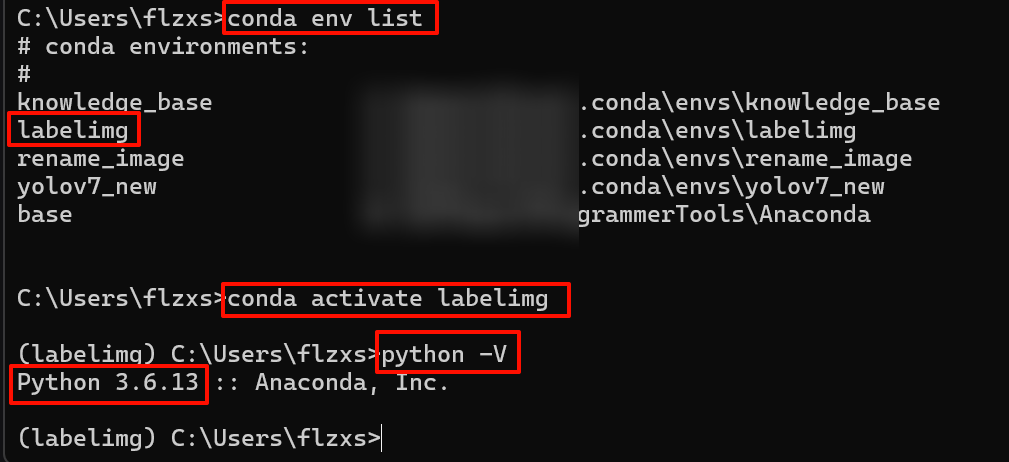
在当前labelimg环境中开启labelimg:会进入labelimg的UI界面
labelimg
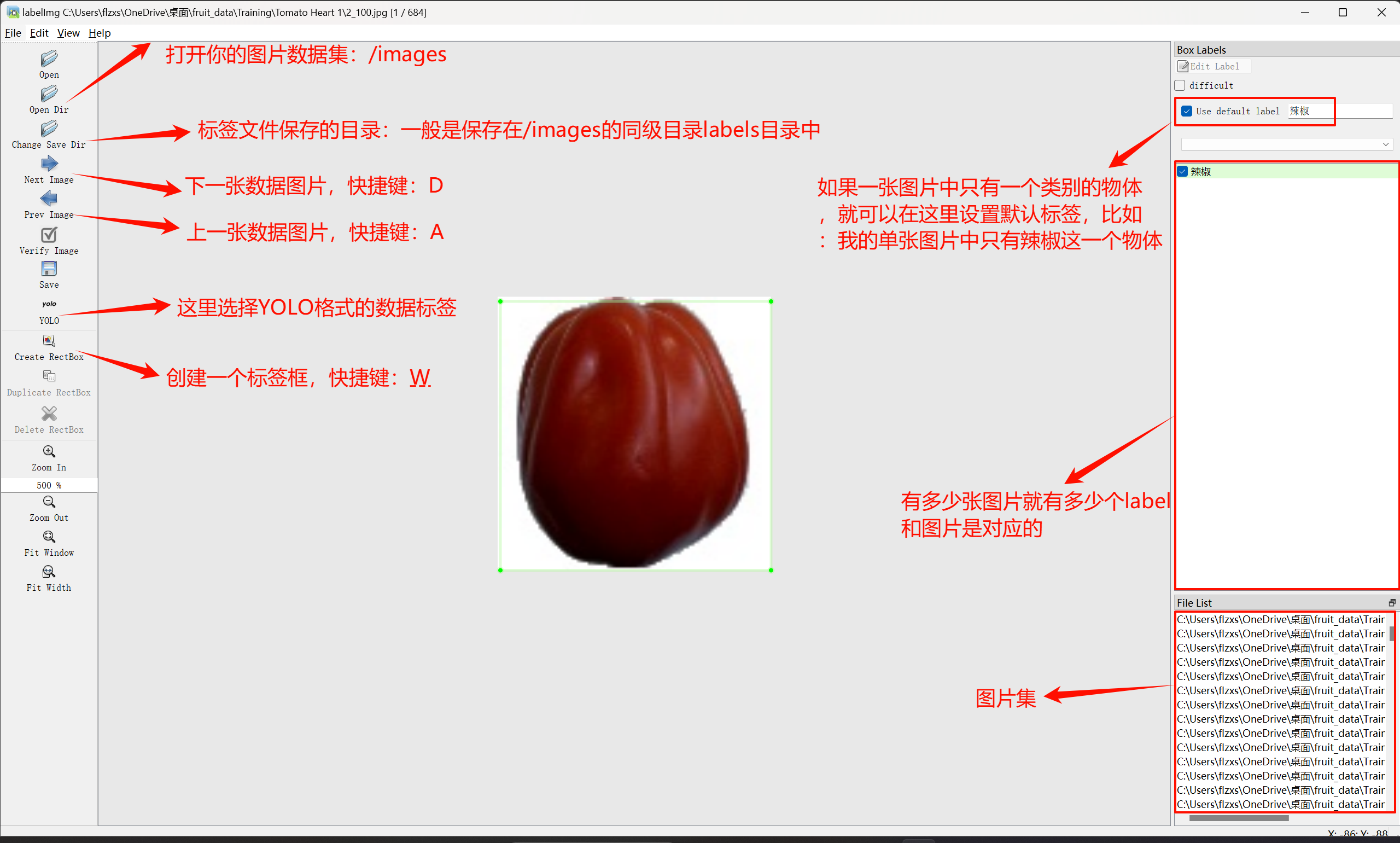
在View处打开Auto Save Mode,这样每标完一张图片就自动保存该图片的label标签!每一张图片对应一个label标签,TXT文件保存的是图片的物体类别和对应的坐标。
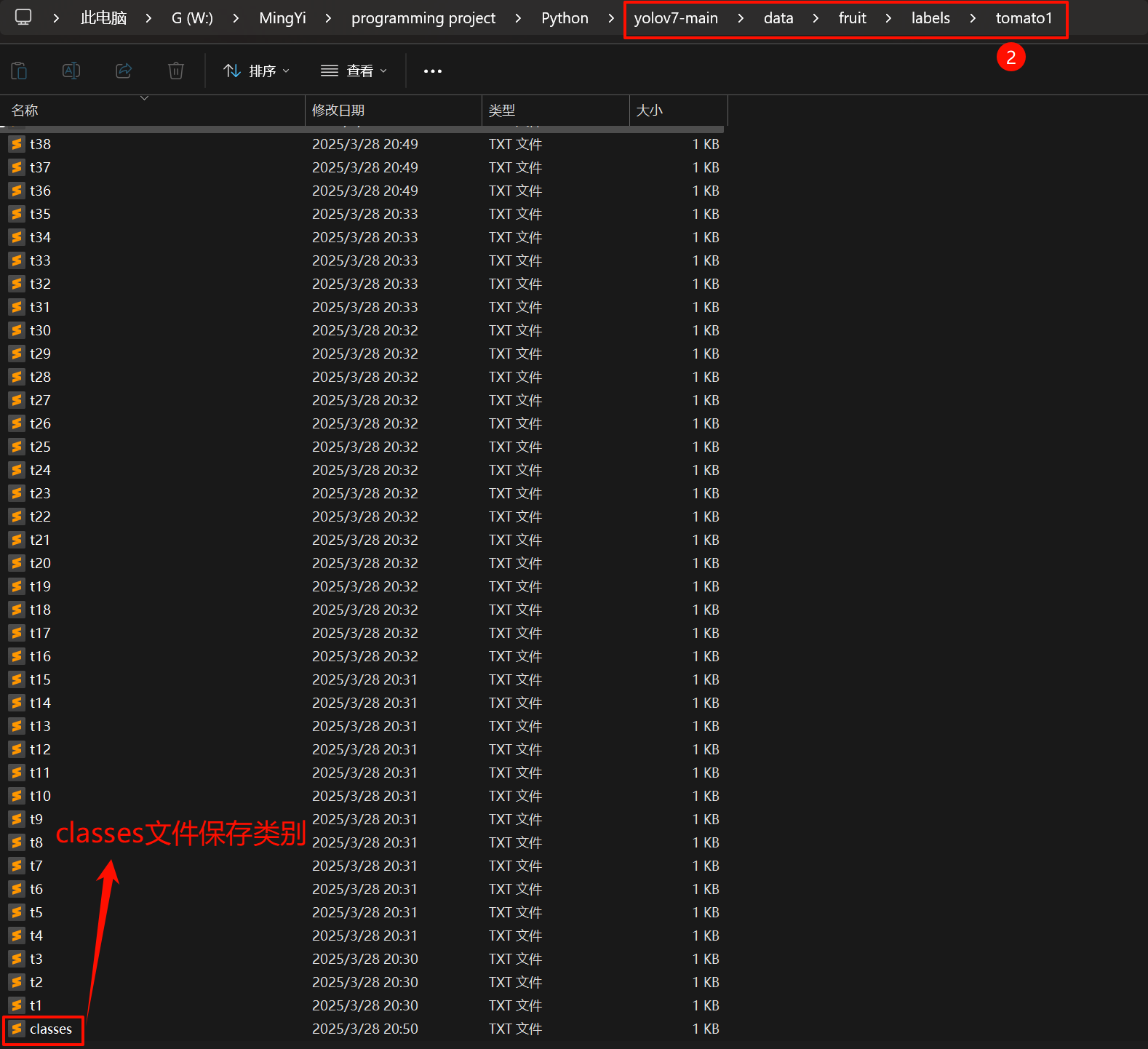
TXT的文件信息:

classes.txt:
最后将/images和/labels放到yolov7/data/fruit目录下!
分别指定partition_dataset.py和coco.yaml中的图片路径参数、类别信息:
coco.yaml:

看到这里!你是不是已经懂前面的:1.下载和熟悉yolov7项目结构。如果还是很懵,再回去多看几遍。
train_list.txt:其实就是数据图片的路径信息
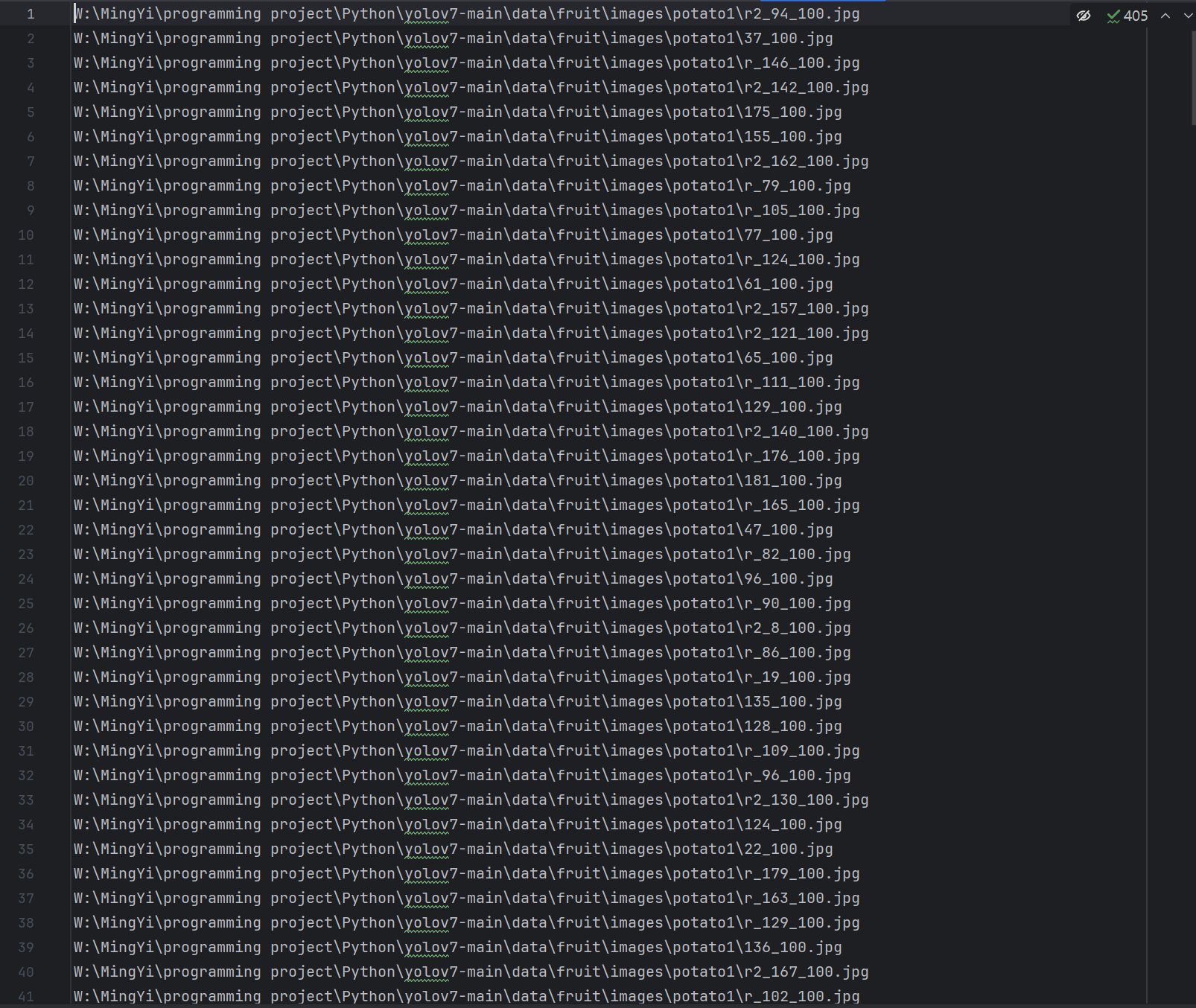
4.6 IDE中使用conda环境
在PyCharm中打开yolov7项目:
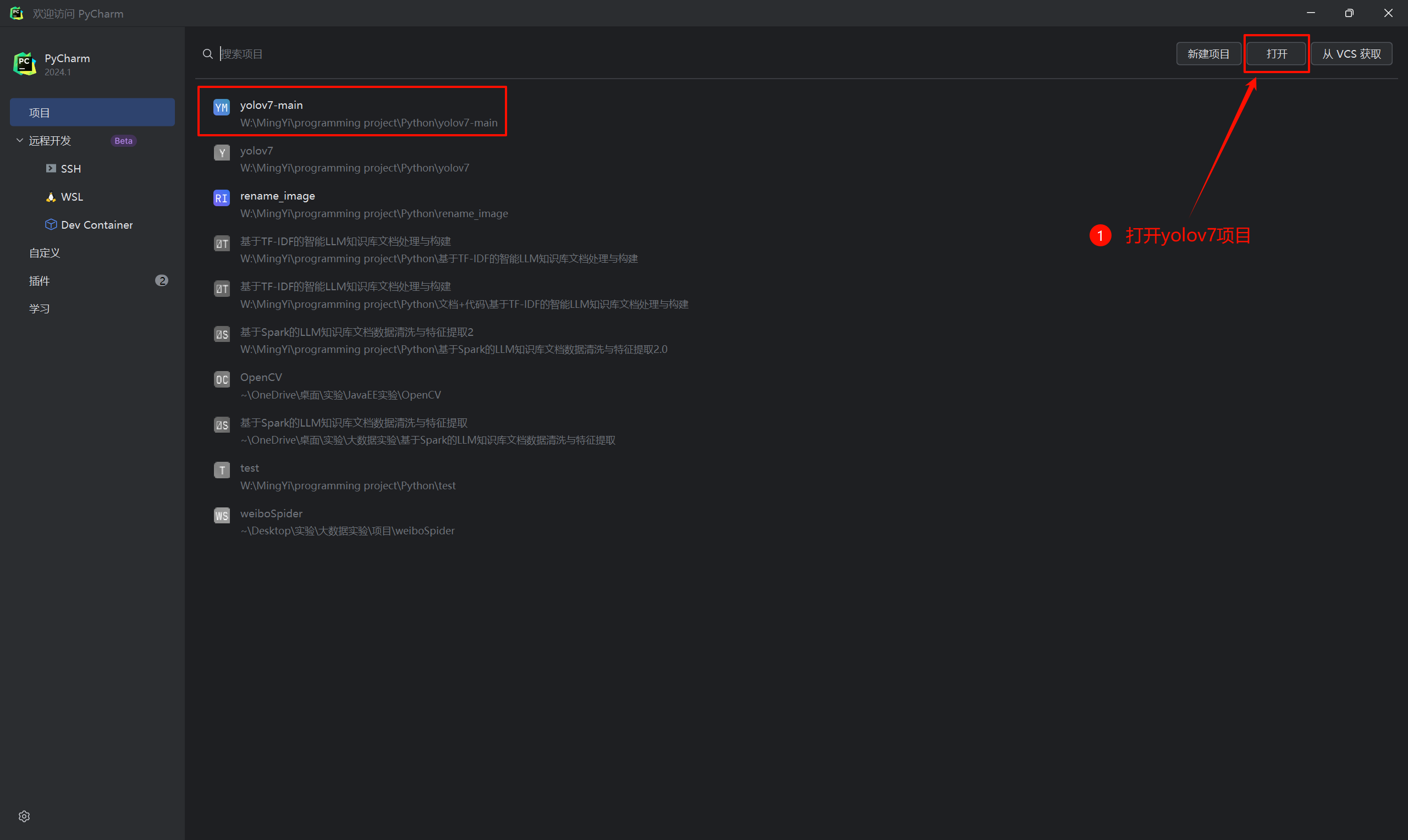
在IDE右下角选择"添加本地解释器",选择yolov7环境:
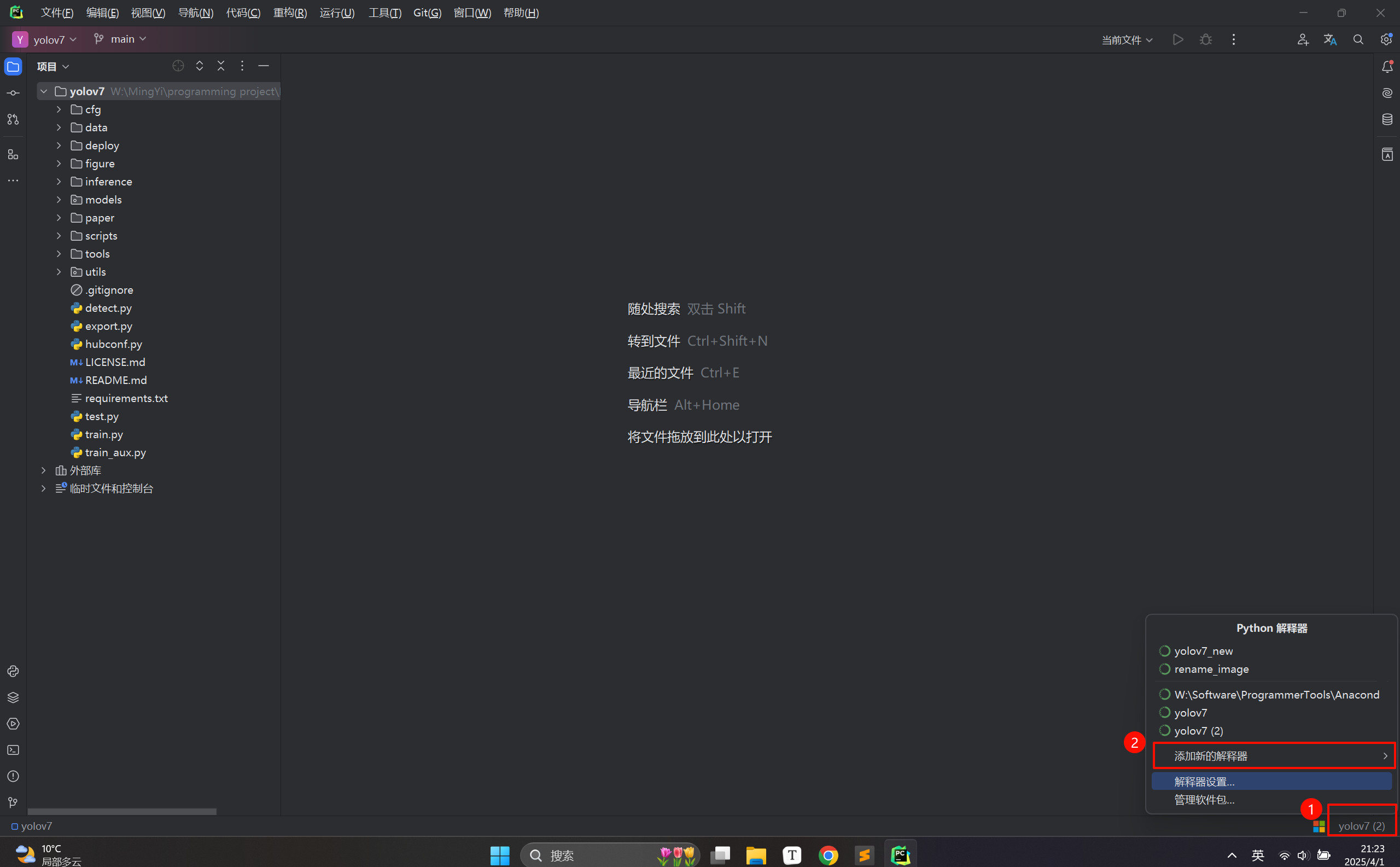
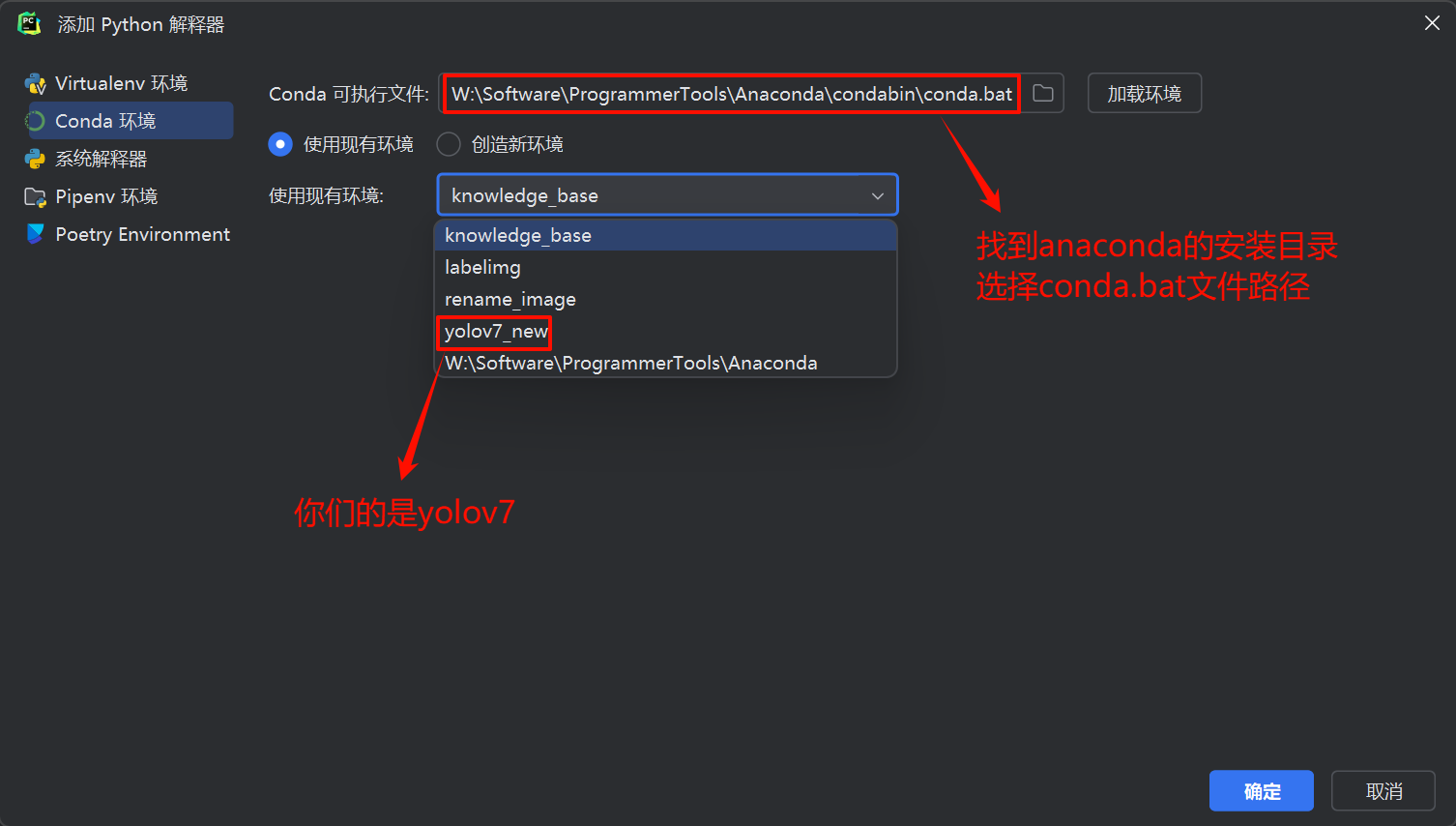
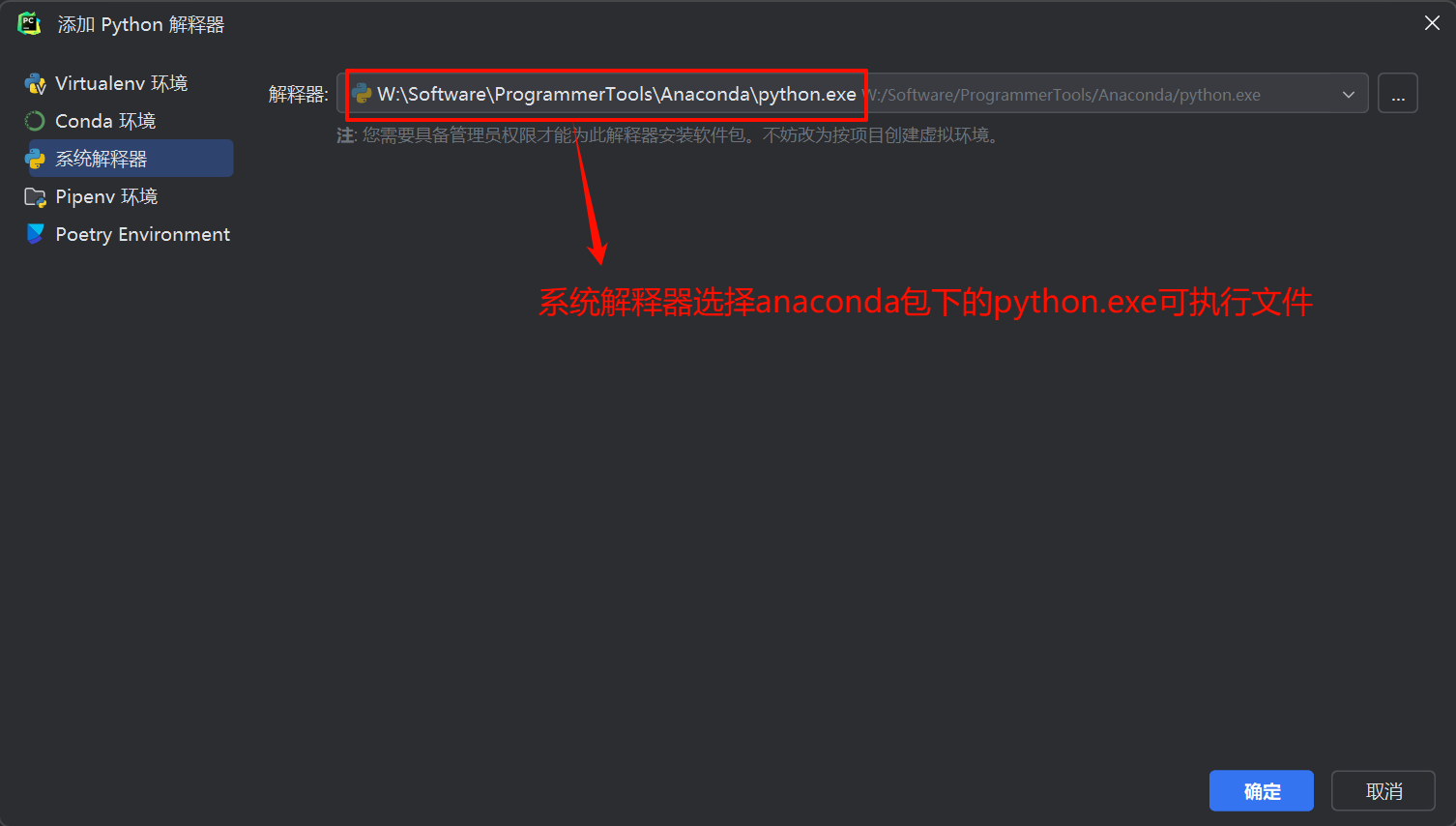
上述操作完成后,等待IDE加载环境!
5. 运行train.py训练模型
在完成上述所有步骤后,直接运行train.py
报错:
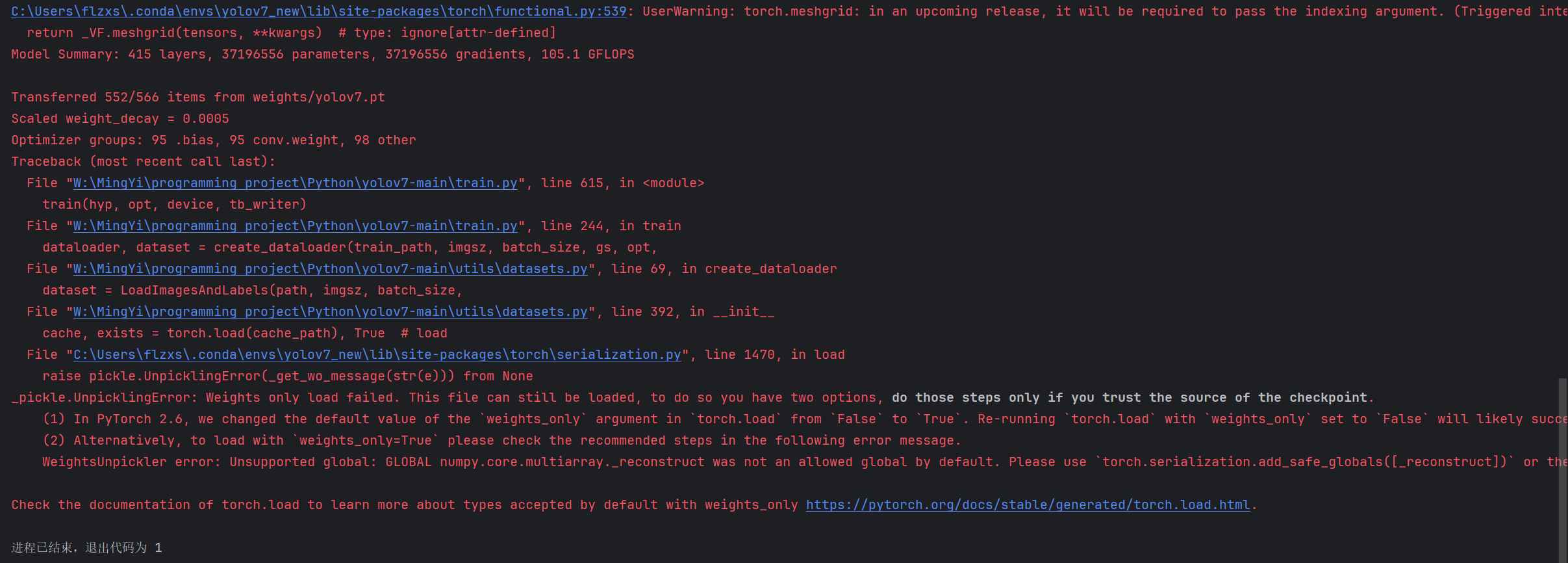
说明上次的数据划分文件还存在,你需要先删除:
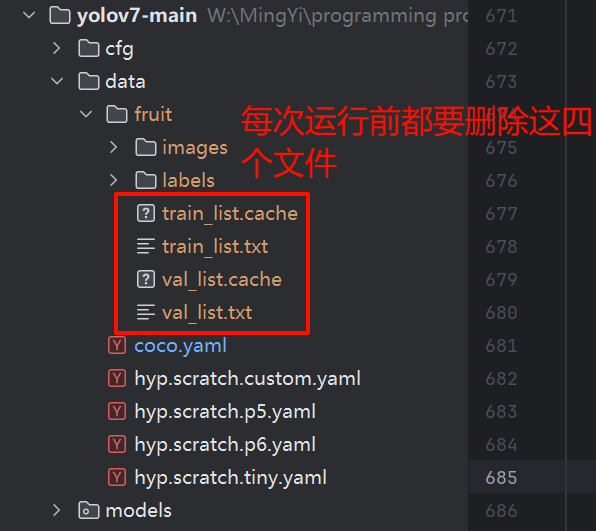
先运行partition_dataset.py,再运行train.py

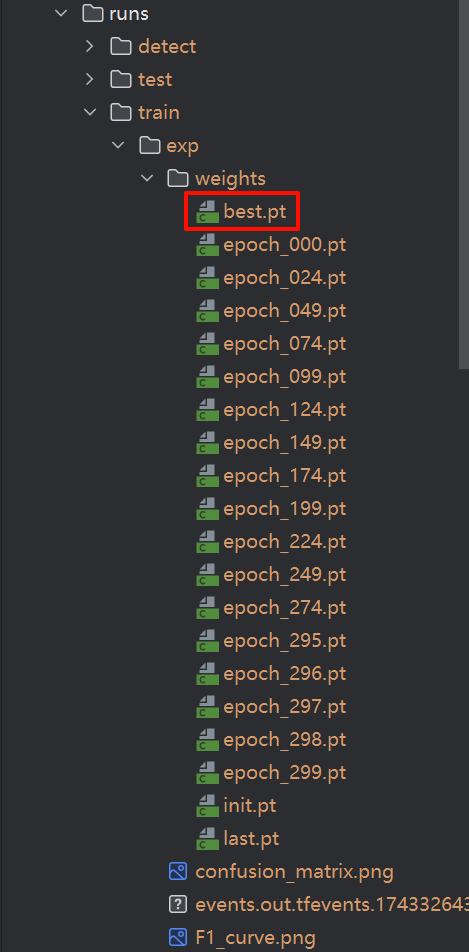
训练完成会在/runs/train/exp/weights目录下生成best.pt权重文件!
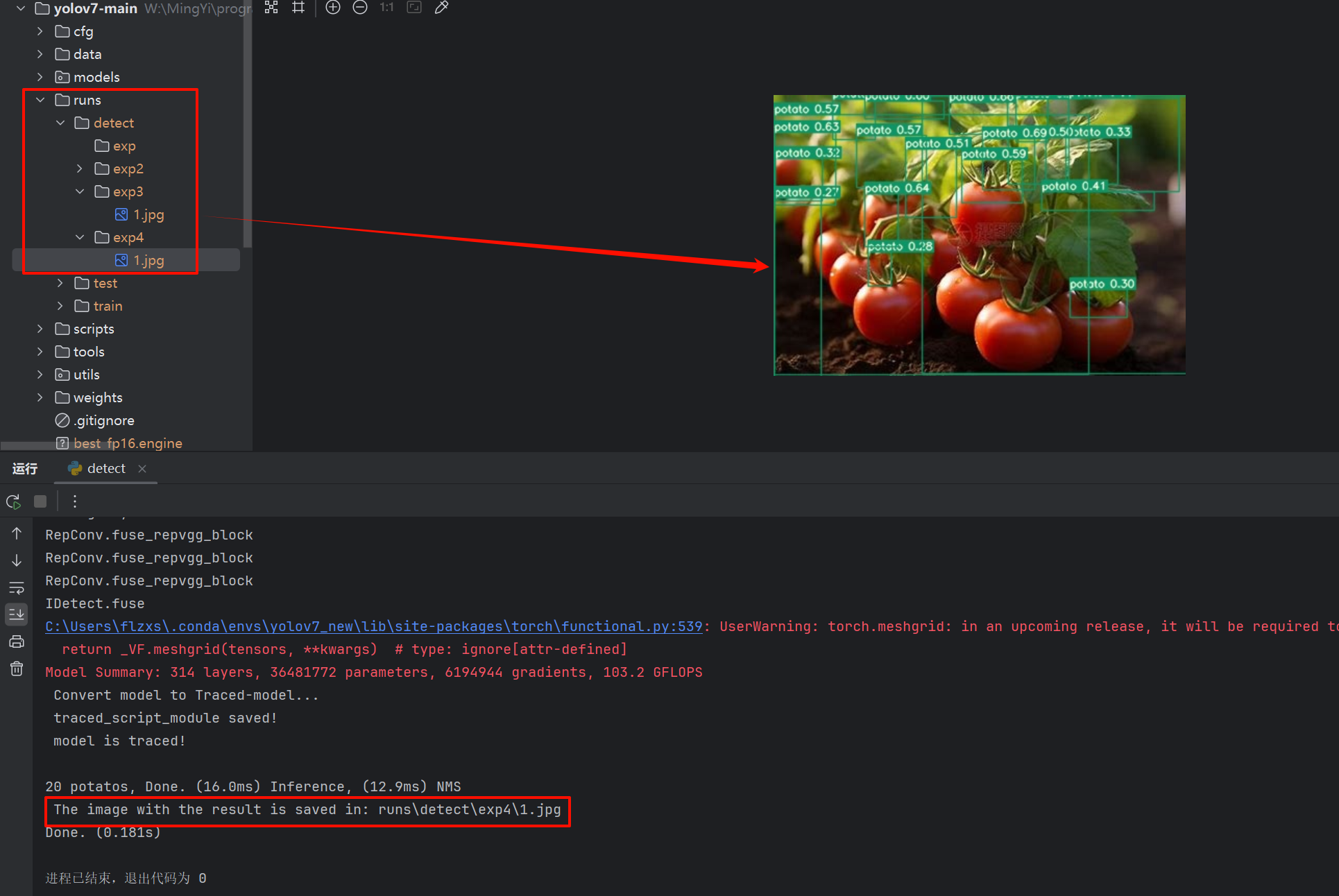
6. 运行detect.py识别
在detect.py中指定识别图片的路径和已经训练完成的权重文件!
结果
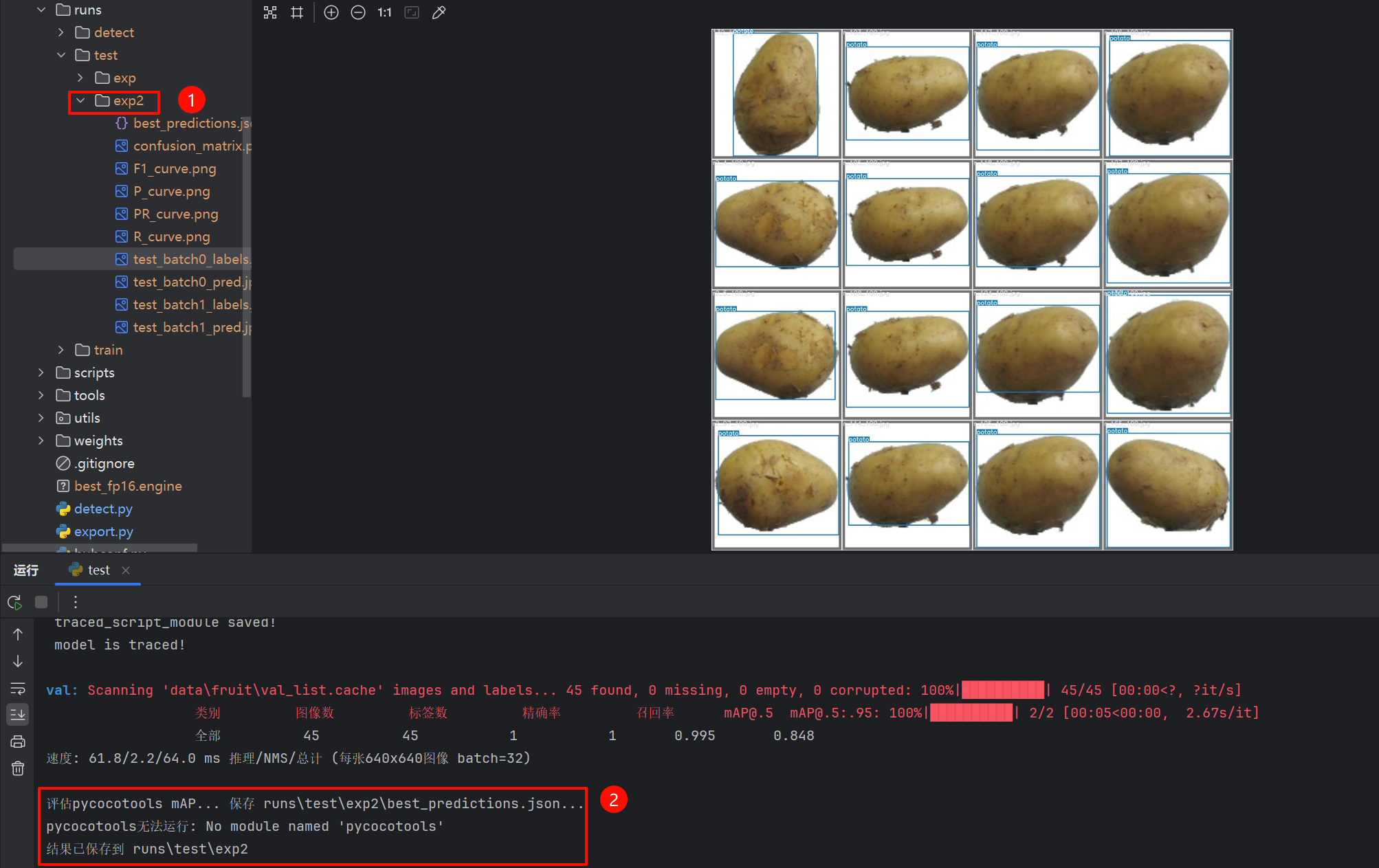
7. 运行test.py测试
指定权重文件路径即可!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









