







文章预告:
导入数据后,我该如何用Python进行处理?今天开始我们就聊聊数据结构!
首先,我会为大家讲解Python最基本的数据结构——序列,什么是序列,如何操作序列,还有一些什么好玩的内置函数?手把手教你玩转序列!
然后,我会为大家讲解四大数据类型之一的列表,它和C语言中的数组差别在哪?如何对它进行创建、删除、修改?又如何对它的各个元素进行操作?不着急,今天就为你揭秘!
你说具体讲什么?正好是谁家博主这么贴心,还为大家准备了详细的思维导图!快点击目录查看吧👇👇👇!
文章目录
🧠思维导图
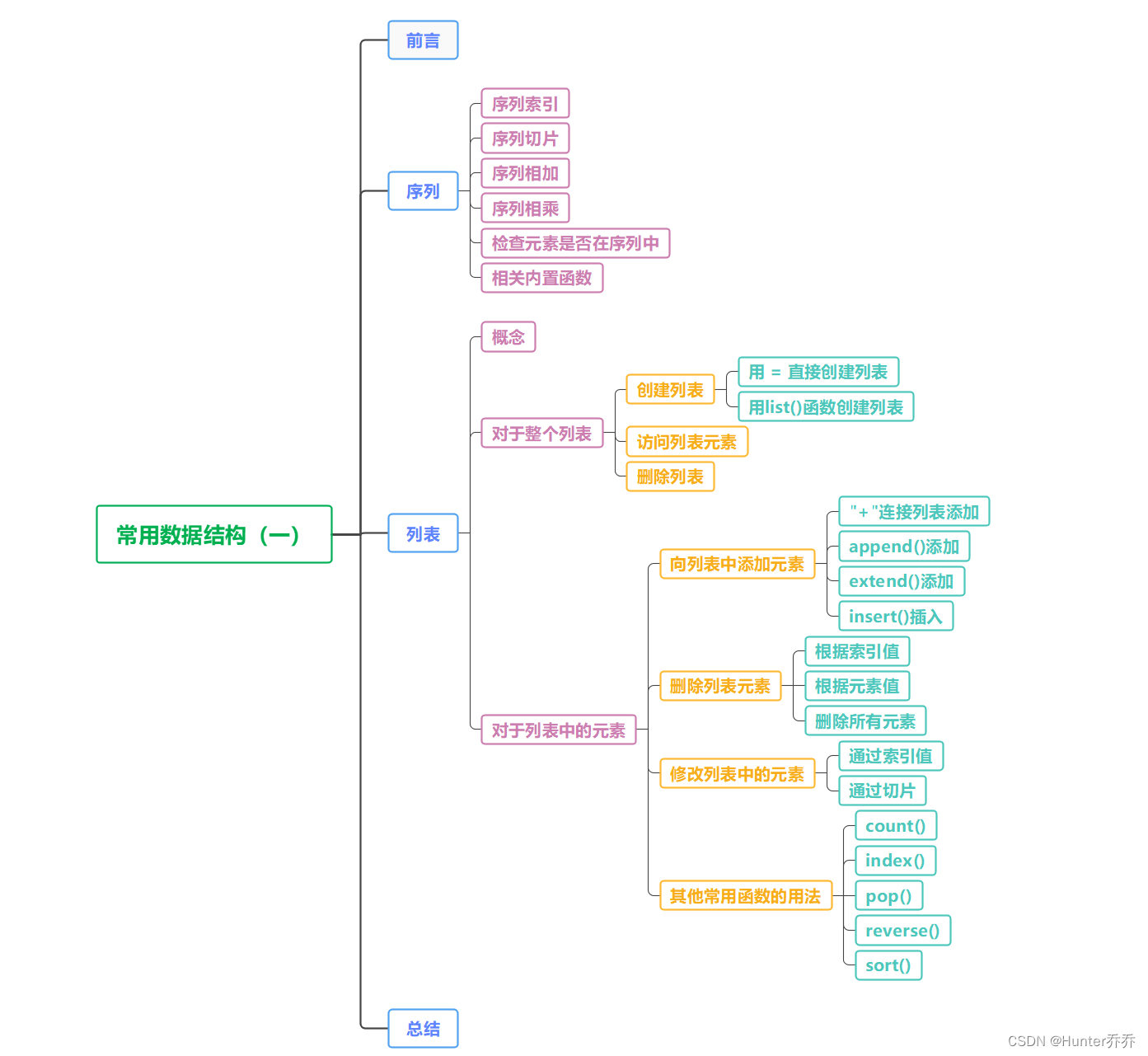
📒前言
上一篇文章为大家讲解了常用函数及运算符,我们先回顾一下上一节内容吧!
上一节首先我们讲了len(), input(), print()三大基本函数,len()函数负责获取字符串长度,input()函数负责输入,print()函数负责输出
接着我们讲了格式化字符串,用%占位符的方式和format函数的方式将数据格式化地填入字符串。然而,当数据不能和字符串通过“+”直接合并时,我们讲了类型转换。
最后,我们讲了运算符,包括算术运算符、赋值运算符、位运算符、比较运算符、逻辑运算符、三目运算符,还包括运算符的优先级
还没有学习的老铁们可以点击此链接简单回顾一下:http://t.csdnimg.cn/C5oIH
在机器学习中我们通常需要向Python中导入数据集,数据集的数据量可是相当大的,那么Python又是通过什么方式才能容纳得了这么多的数据?
这是因为Python可以使用多种数据结构来保存大量数据,而Python有内置的四种常用数据结构:列表、元组、字典以及集合。它们到底是何方神圣?今天我们就来会会四大金刚之一的列表!
别看本篇内容看起来比较多,实际上读起来也不少😭但每一小块内容不多,麻烦大家耐心阅读!
一、🔍序列
列表和元组都按顺序保存元素,每个元素都有自己的索引。所以理解序列是啥非常重要!
序列是指的是一块可存放多个值的连续内存空间,这些值按一定顺序排列,可通过每个值所在位置的编号(也称索引)访问它们。
就像店铺门口的门牌号(索引),我们通过不同的门牌号,可以在每条街道(序列)上找到不同的店铺(内存空间)。
序列类型包括字符串、列表、元组、集合和字典,但比较特殊的是,集合和字典不支持索引、切片、相加和相乘操作。
1、序列索引
就像店铺门口的门牌号一样,序列中的每一个元素都有自己的索引。起始元素的索引值为0,向后依次递增,第n个元素的索引值为n-1。
当然除了正着向后数,还可以倒着向前数。末尾元素索引值为-1,先前依次递减,第1个元素索引值为-n.
无论是采用正索引值,还是负索引值,都可以访问序列中的任何元素,并且两者可以同时使用。
str = "Hunter乔乔是一位CSDN博主"
print(str[3], str[-2])
#输出结果为:t 博2、序列切片
切片操作是访问序列中元素的另一种方法,它可以将序列中一定范围内的元素通过切片操作, 生成一个新的序列。可以理解为切菜时将一些好的部分留下,并组成要吃的部分。
序列切片格式如下:
strname[start : end : step]
strname表示序列名称
start表示切片开始索引位置(包括该位置),也可以不指定,默认为0。start对应元素在新序列中作为第一个元素。
end切片的结束索引位置(不包括该位置),也可以不指定,默认为字符串长度,即n。end对应元素在新序列中不出现,它的前一个元素在新序列中作为最后一个元素。
step:表示在切片过程中,隔几个存储位置(包含当前位置)取一次元素。如果 step 的值大于 1,则在进行切片去序列元素时,会“跳跃式”的取元素。如果未设置 step 的值,则最后一个冒号就可以省略。
举一个形象的例子帮助大家记忆,高中生物中mRNA进行翻译时,起始密码子在生成肽链中有对应氨基酸,而终止密码子不会在生成的肽链中有对应氨基酸。序列切片的过程与之相似。
我们再来用代码实践一下:
str = "Hunter乔乔是一位CSDN博主"
print(str[3], str[-2])
print(str[3:-2:])
print(str[3:-2:2])
print(str[3::])
print(str[3::2])
print(str[::])
print(str[::2])
#t 博
#ter乔乔是一位CSDN
#tr乔一CD
#ter乔乔是一位CSDN博主
#tr乔一CD博
#Hunter乔乔是一位CSDN博主
#Hne乔是位SN主序列切片在机器学习中也很重要,我们有时导入的数据集都是一维的,要将其还原为表格,就会使用序列切片将其分割。
3、序列相加
在Python 中,支持两种类型相同的序列使用“+”运算符做相加操作,它会简单粗暴地将两个序列进行连接。运用上我们前面讲过的类型转换,可以举个栗子:
str_1 = "Hunter乔乔"
str_2 = "是一位"
age = 18
str_3 = "岁的CSDN博主"
print(str_1[:-2]+str_2+str(age)+str_3[:2]+str_3[6:])
#运行结果:Hunter是一位18岁的博主4、序列相乘
序列相乘表示序列进行简单的数乘,当一个序列乘以n时,代表这个序列被重复n遍,并生成一个新的数列。
str = "学习Python使我快乐!"
print(str*3)
#运行结果:学习Python使我快乐!学习Python使我快乐!学习Python使我快乐!
5、检查元素是否在序列中
可以使用 in 关键字检查某元素是否为序列的元素,并返回布尔值,语法格式为
value in sequencevalue 表示要检查的元素,sequence 表示序列
举个栗子:
str = "学习Python使我快乐!"
print("Python" in str)
print("python" in str)
#True
#False
6、相关内置函数
在上一节内容中提到过的len()函数其实也是序列的内置函数,用于获取序列的长度。
| 函数 | 功能 |
|---|---|
| len() | 计算序列的长度,即返回序列中包含多少个元素。 |
| max() | 找出序列中最大的元素。 |
| min() | 找出序列中最小的元素。 |
| list() | 将序列转换为列表。 |
| str() | 将序列转换为字符串。 |
| sum() | 计算元素和。对序列使用 sum() 函数时,做加和操作的必须都是数字,不能是字符或字符串! |
| sorted() | 对元素进行排序。 |
| reversed() | 反向序列中的元素。 |
| enumerate() | 将序列组合为一个索引序列,多用在 for 循环中 |
str = "学习Python使我快乐!"
print(len(str))#13
print(max(str))#!
print(min(str))#P
print(sum(str))#报错其中字符串最小的字符表示在字符串中对应Unicode编码值最小的字符。
我们可以通过类型转换中讲过的ord()函数获取Unicode编码值。
for char in str:
print(ord(char), end=" ")
#输出结果为:23398 20064 80 121 116 104 111 110 20351 25105 24555 20048 65281 可以看出,尽管汉字在Unicode编码中的编码值可能比 "!" 更大,但在给定的字符串中,"!" 的编码值确实比任何汉字的编码值都大,而 "P" 的编码值比任何汉字的编码值都小,因此它们分别被认为是最大和最小的字符。
二、🔍列表
1、概念
在C语言中,我们学习过有关数组的知识,它就可以把多个数据挨个存储到一起,通过数组下标来访问数组中的各个元素,并且还要求所有元素的类型必须一致。
不过需要特别注意的是,Python中并没有数组的概念,不过它有功能更加强大的列表!
在C语言的数组中,我们通常在[ ]中表示数组的长度,在{ }中填充元素。但是在Python中,我们通常在[ ]中放进列表的所有元素,并将相邻的两个元素用", "间隔开。
[element1, element2, …, elementn]Python列表中的元素没有个数和类型限制,同一个列表中的元素数据类型甚至可以各不相同。但为了方便阅读,我们通常在同一列表中放入同种类型的数据。
在Python中,列表的数据类型是list。
2、如何创建列表
在Python中创建列表的方法有两种,我们一一介绍:
2.1 用 = 直接创建列表
listname=[element1, element2, …, elementn]在=左边的列表名称须符合变量的命名规范,等号右边向[ ]内填充元素。但是也可以什么元素也不写,此时创建一个空列表。
2.2 用list()函数创建列表
除使用前面介绍的方括号语法创建列表之外,Python 还提供了一个内置的 list() 函数来创建列表,它可用于将元组、区间(range)等对象转换为列表。
例如将元组和区间转换为列表:
tuple1 = ("Hunter乔乔", "是一位", 18, "岁的CSDN博主")
list1 = list(tuple1)
print(list1)
range2 = range(5, 10)
list2 = list(range2)
print(list2)
#['Hunter乔乔', '是一位', 18, '岁的CSDN博主']
#[5, 6, 7, 8, 9]range()函数表示一个左闭右开[ , )区间内所有的整数。在后面区间的内容会讲到。
3、访问列表元素
列表是序列的一种类型,所以访问列表元素和前面讲过的序列索引和切片的用法完全一模一样!
list1 = ["Hunter乔乔", "是一位", 18, "岁的CSDN博主"]
print(list1[1])
print(list1[1:4])
#输出结果:是一位
# ['是一位', 18, '岁的CSDN博主']我们还可以注意到:如果输出的是单个元素,没有[ ]。如果输出单个元素且是字符串时,连双引号也得去掉!
4、如何删除列表
对于已经创建的列表,如果不再使用,可以使用 del 语句将其删除。就像我们把一个文件扔进垃圾桶,会回收其所占有的内存空间。
但是由于Python自带的垃圾回收机制会自动销毁不用的列表,所以这种方法并不常用。
del 语句的语法结构:
list_1 = []
del list_1举个栗子:
list1 = ["Hunter乔乔", "是一位", 18, "岁的CSDN博主"]
print(list1)#['Hunter乔乔', '是一位', 18, '岁的CSDN博主']
del list1
print(list1)#报错:未定义list1
5、如何向列表中添加元素
通过前面的学习我们知道,通过使用“+”运算符可以将多个序列进行连接,列表也是如此,我们可以通过"+"将两个列表连起来形成一个新列表,从而简单粗暴地向列表中添加元素。
5.1 "+"连接列表添加元素
list1 = ["Hunter乔乔", "是一位"]
list2 = [18, "岁的CSDN博主"]
print(list1 + list2)
#输出结果:['Hunter乔乔', '是一位', 18, '岁的CSDN博主']5.2 append() 方法添加元素
但是当列表元素超级多时,“+连接的方法就不好使了,这时我们通常会使用append() 方法,append() 方法用于在列表的末尾追加元素。
append()语法格式:
listname.append(new_element)element表示到添加到列表末尾的数据,它可以是单个元素,也可以是列表、元组等。
list1 = ["Hunter乔乔", "是一位"]
list2 = [18, "岁的CSDN博主"]
list1.append(list2)
print(list1)
print(list1.append(list2))
#输出结果:['Hunter乔乔', '是一位', [18, '岁的CSDN博主']]
# None但特别需要注意的有两点:1、append()需要单独一行列出来,因为它本身没有返回值(None)2、追加的元组,列表等类型是被整体当作一个元素添加在原列表末尾。
5.3 extend()方法添加元素
如果希望不将被追加的列表或元组当成一个整体元素,而是只是逐个追加列表中的元素,那么我们就可以尝试一下extend()方法。
和append()一样,extend()只不过是换了一个单词而已:
listname.extend(new_element)再用extend()方法尝试一下连接上一个例子中俩列表:
list1 = ["Hunter乔乔", "是一位"]
list2 = [18, "岁的CSDN博主"]
list1.extend(list2)
print(list1)
#输出结果:['Hunter乔乔', '是一位', 18, '岁的CSDN博主']5.4 insert()方法插入元素
当然有时候我们不只是在列表末尾添加元素,我们还需要在列表中间添加元素,此时我们使用insert()方法。
insert()语法结构如下:
listname.insert(index , new_element)index是将元素插入到列表中指定位置处的索引值(或者说是插入位置后一个元素在原字符串中的索引值),这里添加的元素一样可以是列表,元组等。
不过需要特别注意的是,使用 insert() 方法向列表中插入元素,和 append() 方法一样,就算插入的对象是列表或者元组,也只会将其整体视为一个元素。
list1 = ["Hunter乔乔", 18, "岁的CSDN博主"]
list2 = ["是一位"]
list1.insert(1, list2)
print(list1)
#输出结果:['Hunter乔乔', ['是一位'], 18, '岁的CSDN博主']6、如何删除列表中的元素
前面我们讲过如何删除整个列表,当然有的铁子会问:如果我想保留列表怎么办呢?
今天为大家介绍三条妙计!
6.1 根据索引值删除元素
与前面讲到过的访问列表元素相似,我们添加上del语句就可以删除列表元素。
但是神奇的是,del 语句是 Python 中专门用于执行删除操作的语句,不仅可用于删除列表的元素,也可用于删除变量等等!
结合上前面的insert()插入元素用法,我们可以达到类似于替换元素的目的:
list1 = ["Hunter乔乔", 18, "岁的CSDN博主"]
list2 = ["是一位"]
del list1[0]
list1.insert(0,list2)
print(list1)
#[['是一位'], 18, '岁的CSDN博主']不仅可以将元素一个个删去,我们还可以一段段删去。这就要用上我们前面讲过的序列切片。
list_1 = [1, 2, 3, 4, 5, 6, 7, 8]
print(list_1[0:6:2])
del list_1[0:6:2]
print(list_1)
#[1, 3, 5]
#[2, 4, 6, 7, 8]6.2 根据元素值删除元素
除使用 del 语句之外,还可以用 remove() 方法来删除列表元素,但不同的是,这种方法是根据元素本身的值来执行删除操作的。
remove() 方法会删除第一个和指定值相同的元素,如果找不到该元素,该方法将会报错。并且这种方法一次只能删除一个元素!
list_1 = [1, 2, 3, 4, 5, 6, 7, 8, 3]
list_1.remove(3)
print(list_1)#[1, 2, 4, 5, 6, 7, 8, 3]
list_1.remove(9)
print(list_1)#ValueError: list.remove(x): x not in list
list_1.remove(1,2)
print(list_1)#TypeError: list.remove() takes exactly one argument (2 given)
6.3 删除列表中所有元素
不同于前面讲过的删除整个列表,我们现在讨论的是删除列表中所有元素。此时我们使用clear()来进行删除。
clear()语法结构如下
listname.clear()list_1 = [1, 2, 3, 4, 5, 6, 7, 8, 3]
list_1.clear()
print(list_1)
#输出结果:[]可以看出列表还在,但是元素被全部清空了!
7、如何修改列表中的元素
7.1 通过索引值进行修改
列表的元素相当于变量,当我们直接根据索引值对列表中的元素直接赋值时,就可以实现替换。
list_1 = ["今年是", 2023, "年"]
list_1[1] = 2024
print(list_1)
#输出结果:['今年是', 2024, '年']这里的索引值既可以是正数索引,当然也可以是负数索引。
7.2 通过切片进行修改
除了可以通过索引值进行修改以外,通过切片的方法对一小部分进行修改也可以。
需要注意的是,新的元素个数不必与旧的元素个数相同,而是可以理解为将旧的元素删去,直接将新的元素填充进来。不仅如此,和前面一样,由于切片默认左开右闭区间,所以注意第一个:后是被替换的最后一个元素索引值后+1。
list_1 = ["今年是", 2023, "年"]
list_1[1:3:1] = [2024, "年", "是闰年"]
print(list_1)
#输出结果:['今年是', 2024, '年', '是闰年']还需要注意的是,使用切片方法进行修改时的值必须为序列,不能使用单个值。如果使用字符串赋值,Python 会自动把字符串当成序列处理,其中每个字符都是一个元素。
list_1 = ["今年是", 2023, "年"]
list_1[0:3] = "去年是2023年"
print(list_1)
#['去', '年', '是', '2', '0', '2', '3', '年']8、其他常用函数的用法
除了前面介绍过的增加元素、删除元素、修改元素方法之外,列表还包含了一些常用的方法。
8.1 count()用法
count()方法用于统计某个元素在字符串中出现的次数。
count()语法格式如下:
listname.count(element)list_1 = [1, 2, 2, 2, 2, 2, 3]
print(list_1.count(2))
#输出结果:58.2 index()用法
index() 方法用于定位某个元素在列表中出现的位置,并且返回找到的第一个元素的索引。这种方法甚至还可以规定搜索范围。
index()语法结构:
listname.index(element, start, stop)start表示开始查找元素索引值,end表示结束查找元素后一个元素索引值。
list_1 = [1, 2, 3, 4, 3, 5, 6, 7]
print(list_1.index(3,0,7))#2
print(list_1.index(3,0,2))#ValueError: 3 is not in list8.3 pop()用法
pop() 方法会移除列表中指定索引处的元素,如果不指定,会默认移除列表中最后一个元素。
listname.pop(index)index表示移除元素的索引值
需要注意的是,pop()函数是有返回值的,返回值为移除的元素,而不是删除后的列表。
list1 = ["Hunter乔乔", "是一位", 18, "岁的CSDN博主"]
print(list1.pop(0))
print(list1)
#输出结果:Hunter乔乔
# ['是一位', 18, '岁的CSDN博主']
与del语句的比较:
- pop: 用于从列表中删去指定索引处的元素,并返回该元素的值
- del:用于从列表中删去指定索引处的元素,不返回该元素的值
8.4 reverse()用法
reverse()用于将列表中所有元素反向存放。
reverse语法结构如下:
listname.reverse()特别注意的是,reverse无返回值
list_1 = [1, 2, 3, 4, 5, 6, 7, 8, 9]
print(list_1.reverse())
print(list_1)
#输出结果:None
# [9, 8, 7, 6, 5, 4, 3, 2, 1]
8.5 sort()用法
sort() 方法用于对列表元素进行排序,排序后原列表中的元素顺序会发生改变。
sort()语法格式如下:
listname.sort(key=None, reserse=False)key 参数用于指定从每个元素中提取一个用于比较的关键字。例如,使用此方法时设置 key=str.lower 表示在排序时不区分字母大小写。
reverse 参数用于设置是否需要反转排序,默认 False 表示从小到大排序;如果改为True,将会改为从大到小排序。
如果对全是数的列表进行比较,则默认比较数的大小;如果对全是字符的列表进行比较,则默认比较字符串包含的字符的编码大小。
list_1 = [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
list_1.sort()
print(list_1)
list_1.sort(reverse=True)
print(list_1)
#输出结果:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]将字符串按照字符长度从大到小排列:
list1 = ["Hunter乔乔", "是一位", "18", "岁的CSDN博主"]
list1.sort(key=len, reverse=True)
print(list1)
#输出结果:['Hunter乔乔', '岁的CSDN博主', '是一位', '18']📝总结
本篇内容长度刷新了个人纪录,能够耐心看到这里的小伙伴估计前面都忘得差不多了,我带大家梳理一下!
首先我们讲了四大数据类型都必备的特性:序列!有关序列的内容无论是在本篇内容中讲过的列表还是后续会讲的元组、字典和集合中都非常重要。我们讲过的它的方法几乎是通用的。其中我们讲了索引、切片(这俩最重要,打上五个五角星)、相加、相乘、查找元素和相关内置函数。
然后就是我们第一大数据类型:列表!首先是对整个列表,如何创建,访问、删除列表?其次是对某一些元素,如何添加、删除、修改元素?最后我们还补充了一些常用的函数用法。这些函数不仅会频繁使用,还可以简化代码,非常实用!所以这一块内容也请大家务必理解!
本篇内容作者真的花了超多时间翻阅书籍、查找资料和撰写文稿(从篇幅上就可以看出来),因为这篇文章的内容的重要性不亚于上一篇文章内容。从上一篇文章只是对数的简单运算到这一篇直接引入数据类型的概念,代表着我们的数据量开始有数量级的提升。怎么样,有没有被吓着?
所以拜托看到这里的各位务必熟练掌握,如果可以就给作者一个赞😍,感谢大家的支持!
由于作者有一丢丢懒,春节想给自己结结实实地放个小长假,而且每篇内容也需要花费较多时间查找资料和撰写,后续内容将随机更新,记得关注,千万不要错过哦~
如果发现文章中表述存在错误或有疑问,欢迎私信作者或者在评论区留言~
愿在归途上的小伙伴出入平安,一路顺风!
同时预祝大家新年阖家团圆、年年有余、财源广进、学业有成、福星高照、万事如意、新年快乐、龙年吉祥🤩🎆🎉!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











