






线程不安全
由于线程是随即调度,抢占式执行,=>这样的随机性就会使程序的执行顺序产生变数,=>不同的结果,有的时候对于这个不同的结果我们是可以接受的,但是有的时候是不可以接受的,我们认为这是bug(只要与需求不符合的就算是bug,)多线程代码,引起的bug,这样的问题就是线程安全问题,存在线程安全问题的代码,称为线程不安全
经典线程不安全的例子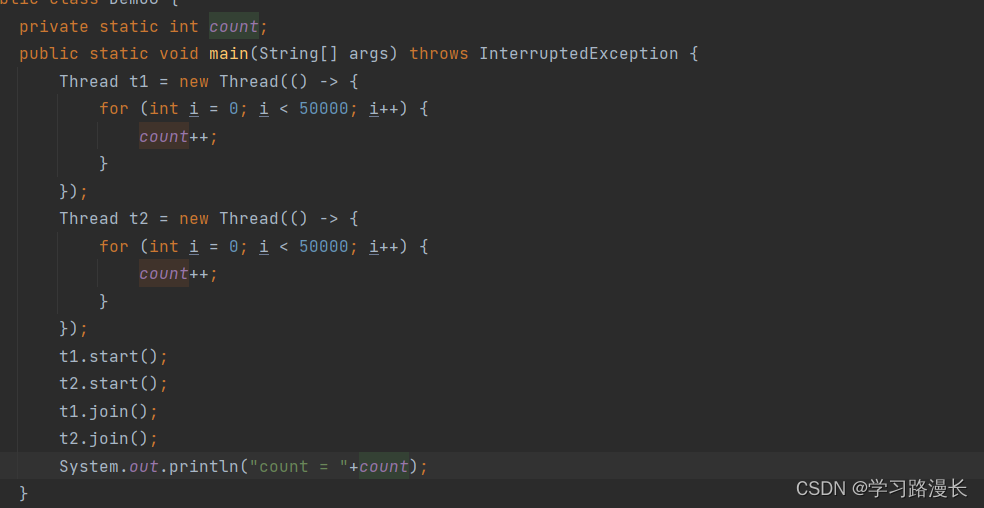
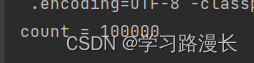
上述代码,我们期望结果是100000,但是结果差强人意,并不是我们所预期的结果,我们就认为这是线程不安全,

为什么会造成这个问题呢?
引起线程不安全的典型原因
1.线程在系统中是随机调度的,抢占式执行(线程不安全的罪魁祸首)
2.当前代码中,多个线程同时修改一个变量
如果一个线程修改同一个变量 => 没事
多个线程读取同一个变量=>没事 每次读到的结果都是固定的
多个线程修改多个变量=>没事
3.线程针对变量的修改操作,不是"原子"的,何为原子(不可拆分的最小单位,代码对应一个CPU指令)
例如count++这种,不是原子操作=>3个指令
但是有的操作虽然是修改,但也是原子操作,对int/float变量直接赋值操作(在cpu中就是一个move指令),关于那些代码变成什么指令需要参考芯片手册(CPU指令集)
4.内存可见性问题,引起的线程不安全

上面两个线程一个线程读,一个线程写,都是站在指令角度来理解的,
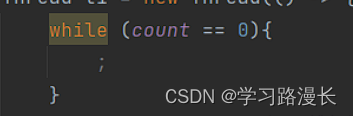
这个while的指令操作
1.load:从内存中读取数据到cpu寄存器当中
2.cmp(比较,同时会发生跳转,条件成立继续执行,不成立跳转到另一个地址)
循环体是空着的没有后续代码所以指令就只有这两个
由于当前循环旋转速度非常块,短时间内出现大量的load和cmp反复执行的效果,load执行消耗的时间会比cmp多个几千万倍,因为内存的访问速度大于硬盘好几个数量级,而寄存器的访问速度大于内存好几个数量级
上述load操作非常消耗时间,执行一次load操作就相当于执行了几万次cmp操作,而且每次load的值都是相同的,所以JVM优化代码,提高效率值执行了一次load的操作,就全部执行cmp操作,每次load的值都是第一次的值,所以当t2线程进行scanner的时候就会出现bug,JVM自动优化代码,将count每次的值都是默认为0,导致BUG
JVM/编译器在单线程中优化是比较靠谱的,但是引入多线程,就不那么靠谱,判断也不那么准确了
当我们在循环中加入一句代码就不会出现上述问题了
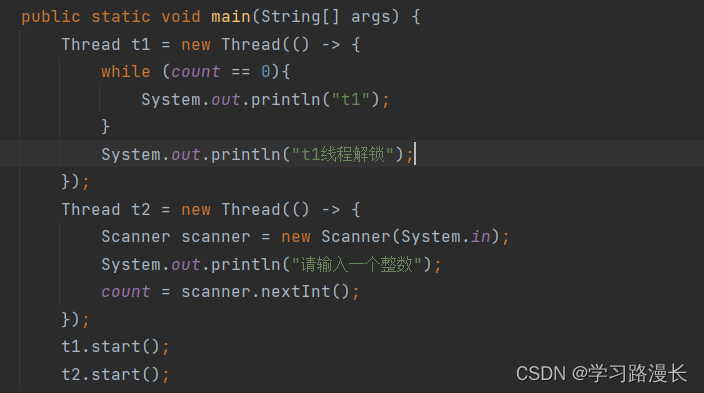
因为此时除了load 和 cmp 指令操作还有IO操作,而IO操作又比load指令操作慢特别多,所以此时瓶颈就是IO操作,能不能优化IO操作呢?显然是不可以的,因为我们可以优化load操作是因为在上述循环中每次都load操作的值都是相同的,而这每次的IO操作的值都是不一样的,
小结:内存可见性问题:问题本质上编译器优化引起的,优化掉load操作之后,t2线程的修改无法被t1线程感知到
关于volatile相关知识
volatile不仅能解决内存可见化的问题,也能禁止针对这个变量读写操作的指令重排序(很多地方都能重排序)问题,针对某个对象读写操作的过程中不会出现重排序.
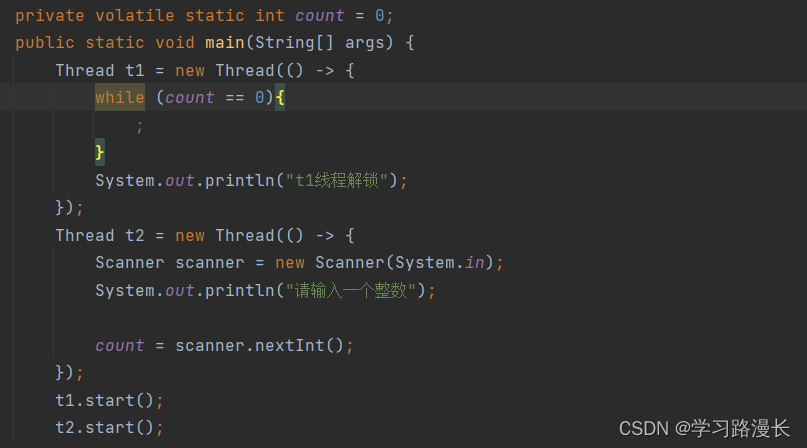

在上述代码中,while中没有加入打印语句,但是结果跟我们预想的一样,那是因为加入关键字volatile修饰count变量,如果不加这个volatile,那么编译器会自动优化程序,使每一次count的值都默认是0,从而造成死循环,当加入这个volatile修饰count之后,它就不会被编译器优化,从而解决了我们内存可见性的问题
编译器优化:是javac(编译器)和Java配合完成的工作,JVM是运行环境
上述问题我们还可以通过JMM(Java内存模型去解释)角度去进行理解
当t1执行的时候,去工作内存中读取count的值,而不是主内存中去,
后续t2修改的时候,也是会先修改工作内存(工作储存区,CPU寄存器+缓存),同步拷贝到主内存中,但是由于t1没有重新读取主内存,最终导致t1没有感知到t2的修改
关于Java文档为什么要搞出工作内存术语
Java讲究的是跨平台,作为Java程序员不需要理解硬件/系统里面的细节.而谈到的CPU寄存器/缓存都是硬件的细节,然后Java的大佬不希望我们了解这些细节,就有工作内存一言蔽之了
5.指令重排序,引起的线程不安全
解决线程安全的方法(从原因入手)
原因1,无法干预
原因2,是一个切入点,但是在Java中,这个方法并不常用,针对特定场景可以使用
原因3,这是解决线程安全问题,最普适的例子,可以通过一些操作,使上述非"原子"的操作打包变成"原子"操作
原因4:我们可以通过引入关键字volatile,来告诉编译器不要触发上述优化代码(具体在Java中,是让Javac生成的字节码的时候产生的"内存屏障",相关指令),但是这个操作和之前synchronized保证的原子性没有任何关系,volatile是专门针对内存可见性的场景来解决问题的,并不能解决之前count++的问题
锁
我们可以通过加锁,来起到互斥的作用,锁本质上是也是操作系统提供的功能,内核提供的功能=>通过api给应用程序,Java(JVM)有对这些api进行封装
关于锁的操作主要是:加锁和解锁
加锁:t1线程加上锁之后,t2也尝试进行加锁,就会阻塞等待(都是系统内核控制),在Java中能看到BLOCKED状态,加锁t1线程之后,t1也是可以被调度走的,即使其他线程调度上来,也是无法继续执行的(在lock这里锁住了)
解锁:直到t1解锁之后,t2才有可能拿到锁(加锁成功),t2只是有可能拿到锁,因为并不是只有一个线程在等待,还有其他线程等待,所以会抢占式执行
互斥:一个线程获取到锁之后,另一个线程尝试获取这个锁,就会阻塞等待(锁竞争/锁冲突)
在代码中,可以创建出多个锁,只有多个线程竞争同一把锁,才会互斥,针对不同的锁则不会.
Java中随便拿一个对象,都可以作为加锁对象(这个是Java中特立独行的规定)
锁的注意事项
这是一个例子
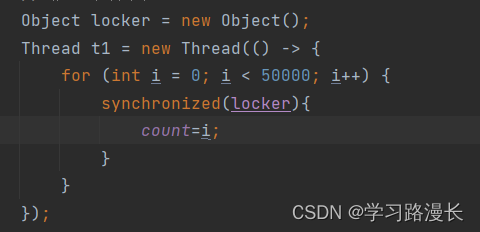
1.synchronized是关键字不是方法,里面的功能是JVM内部实现的
2.synchronized()这个()里面写的是锁对象
注意!锁对象的用途,有且只有一个,就是用来区分,两个线程是否对同一个对象进行加锁
如果是就会出现锁竞争/锁冲突/互斥,就会引起阻塞等待
如果不是,就不会出现锁竞争,也就不是阻塞等待
和对象具体是什么类型,和它里面有什么方法,属性,接下来是否操作对象无关
3.synchronized(){}这个{}是一个代码块当进入代码块中就是给()上述锁对象加锁操作,出来代码块就是解锁操作
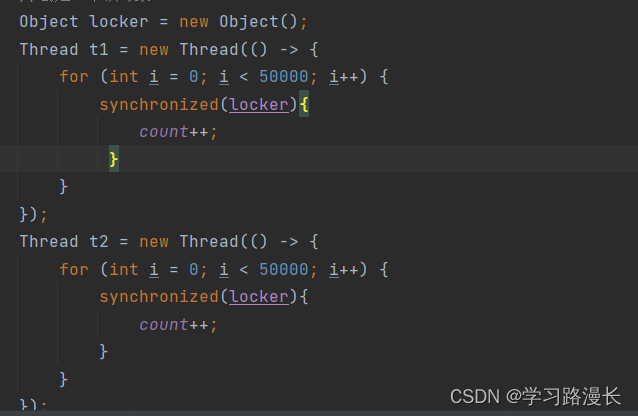
两个线程对同一个对象加锁就会产生互斥,此时的代码运行结果就是理想值
加锁操作,与join的区别:
在这两个线程中,只有每次执行count++的时候存在锁竞争,t1执行完++以后才会轮到t2执行count++,但是t1和t2的for循环和判断条件已经i++都是并发执行的,而join操作是等t1线程完全执行完以后才会执行t2线程


两种写法等价,加锁的生命周期和方法的生命周期一样的时候,可以把synchronized写到方法上
synchronized修饰普通方法相当于针对this加锁了,还有一个特殊的是static方法,没有this

syncronhized修饰static针对的是该类的对象加锁,类名.class这设计反射的知识点
关于反射知识点
反射:程序运行时能够拿到类的属性(不是自己代码所写的属性)包括:类的名字,继承自那个类,实现了那些interface,那些方法,每个方法叫啥,每个方法有啥参数,参数的类型,public/private,类提供了那些属性,每个属性的名字,类public/private
上述这些最初都是你写的.java源代码中提供的,经Javac编译之后.java=>.class字节码(上述信息依然存在,变成二进制),java运行,.class字节码,就会读取这里内容,并且加载到内存中给后续使用这个类提供基础,在java中可以通过类.class获得这个类对象,反射api就是从上述对象中获取信息的
在一个Java进程中某个类只能有唯一一个类对象,但是如果是this就不一样了,因为this指向的可能是不同的对象,new出来几个对象就有几个this.
死锁
死锁是一个非常可怕的事情,会使线程卡住,没法继续工作了,死锁这种bug都是概率性问题,由于不正确的加锁,导致线程卡住了死锁了
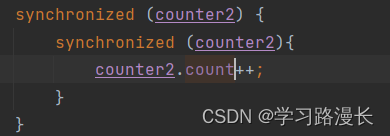
不可重入锁导致的死锁假设synchronized是一个不可重入锁
上述代码就是一个死锁,我们来分析一下这个代码,首先第一个synchronized对counter2加锁成功,执行代码块里的语句遇到第二个synchronized锁对象还是counter2对象,此时第二个synchronized就会阻塞等待,等到锁对象counter2被解锁成功以后,才能获取到counter2对象,而锁对象counter2要解锁成功就必须执行完 第二个}之后,就会形成矛盾,从而导致死锁的出现,这就是不可重入锁
注意
但是在实际情况中是不会出现死锁,因为自己在内部进行了特殊处理(JVM),在每个锁对象里,会记录当前是那个线程持有了这个锁,当针对这个对象加锁操作时,就会先判定一下,当前尝试加锁的线程是否持有锁的线程,如果不是就会阻塞等待,如果是,就直接放行,不会阻塞
如果加了多层锁的时候,代码需执行到最后一个}时才算解锁里面加的锁没有用,最外面加的锁才有用,之所以这样设置是因为避免粗心搞出死锁,这样的机制称为可重入锁synchronized特性
可重入特殊:同一个线程针对同一个对象多次加锁(嵌套锁),需要让锁对象记录那个线程持有锁,通过计数器的方式来决定什么时候解锁(定义count变量遇到 { count++ 遇到 } count-- 当count = 0 时解锁成功)
死锁的三个比较典型的场景
场景一:锁是不可重入锁,并且一个线程针对一个锁对象,连续加锁两次,引入可重入锁,问题迎刃而解
场景二:两个线程两把锁
假设在有线程t1和线程t2,锁A和锁B,线程t1获取到锁A但是不释放锁A继续占用,继续获取锁B此时就会发生死锁
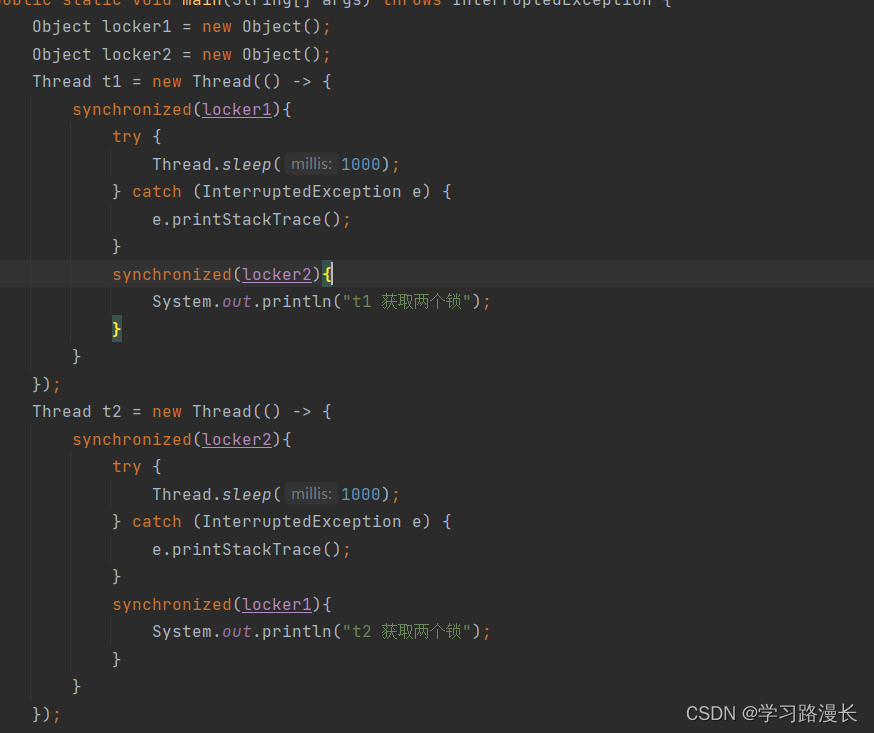
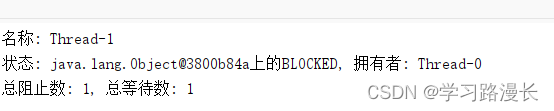
上述代码就写出了死锁,t1线程没有释放locker1尝试获取locker2,t2线程没有释放locker2尝试获取locker1,此时双方都不互相让,就算僵住了,我们可以通过j-console查看一下线程状态
场景三:N个线程,M把锁
死锁问题
死锁的四个必要条件(形成死锁缺一不可)
1.锁具有互斥性(基本特点,一个线程拿到一个锁之后,其他线程就得阻塞等待)
2.锁不可抢占(不可被剥夺),一个线程拿到一个锁之后,除非他自己主动释放锁,否则别人抢不走(也是锁的基本特性)
3.请求和保持,一个线程拿到一把锁之后,不释放这个锁的前提下,尝试获取另一把锁
4.循环等待,多个线程获取多个锁的过程中,出现了循环等待,A等待B,B等待A
死锁问题的解决方法
上述四个必要条件前两个是锁的基本特性我们无法干预,所以我们应该从第三个和第四个条件入手
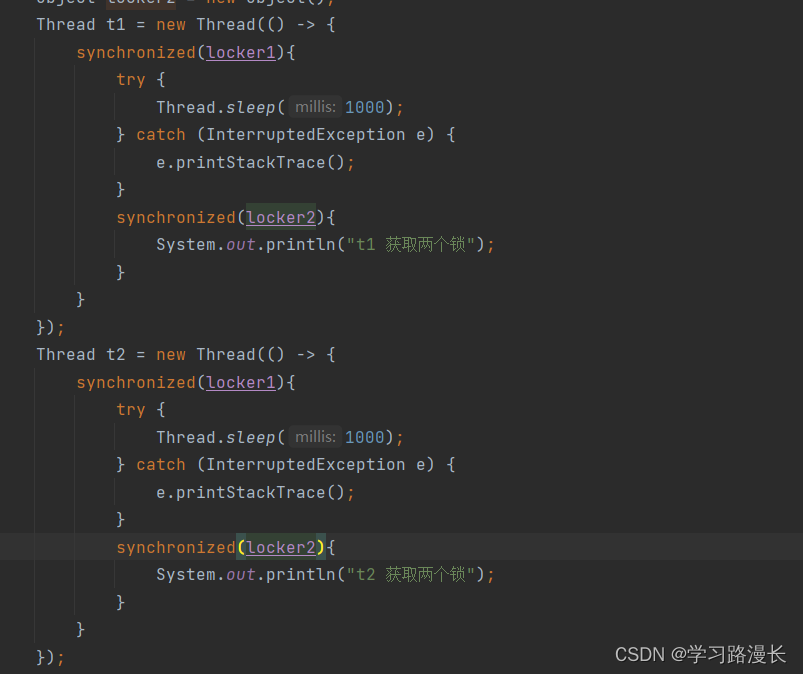
第三个条件的解决方法,避免让锁嵌套获取,如果非要锁嵌套获取,那么我们可以破除循环等待,即使出现嵌套也不会死锁,约定好线程获取顺序,例如在上述代码中先获取1在获取2















 5701
5701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









