






要在linux系统中用docker部署Elasticsearch
部署容器
执行命令创建容器
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
-v /root/es/config:/usr/share/elasticsearch/config\
--privileged \
--network hmall \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1注意,这里采用的是elasticsearch的7.12.1版本,由于8以上版本的JavaAPI变化很大,在企业中应用并不广泛,企业中应用较多的还是8以下的版本
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" //表示容器启动占用的内存512m
-e "discovery.type=single-node" //用于指定elasticsearch的集群类型,在这种模式下,Elasticsearch只会运行一个节点,这个节点不会与其他节点进行通信或数据同步
在elasticsearch有三种集群类型
-
单节点(Single Node):这种类型的集群只有一个节点,适用于开发和测试环境。
-
开发模式(Dev Mode):这种类型的集群可以有多个节点,但是它们之间不会进行数据同步,每个节点都是独立的。
-
生产模式(Production Mode):这种类型的集群是一个完整的、可以进行数据同步的集群,适用于生产环境
注意:
-v es-data:/usr/share/elasticsearch/data //es-data是数据卷,不是自定义的文件,在宿主机中,数据卷一般放在 /var/lib/docker/volumes 目录中
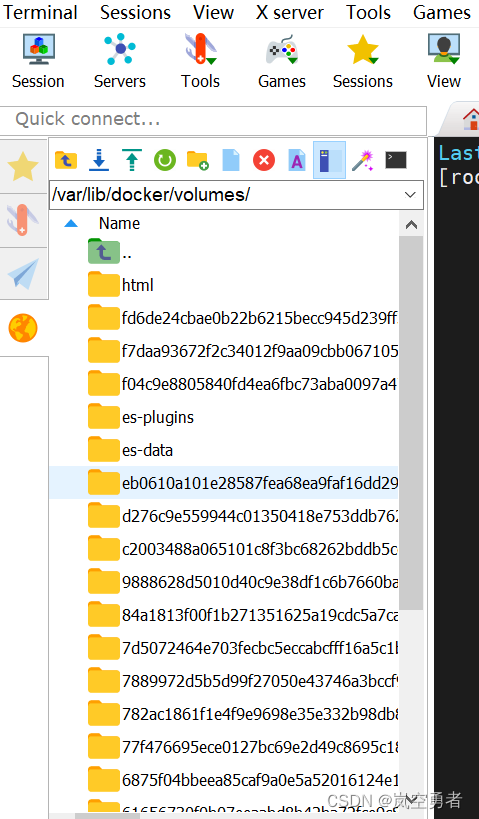
在目录中有es-data跟es-plugins 就是部署容器时指定的数据卷
-v /root/es/config:/usr/share/elasticsearch/config //这是安装elasticsearch的配置文件,是挂载的,/root/es/config是我自己创建的文件夹,你可在别的位置创建
安装完成后,访问9200端口,即可看到响应的Elasticsearch服务的基本信息
安装IK分词器
Elasticsearch的关键就是倒排索引,而倒排索引依赖于对文档内容的分词,而分词则需要高效、精准的分词算法,IK分词器就是这样一个中文分词算法
执行命令安装IK分词器
docker exec -it es ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip安装好后重新启动容器就好了
要是网速比较差,可以自己手动安装
IK分词器是一个插件,差看刚才的数据卷
docker volume inspect es-plugins内容如下
[
{
"CreatedAt": "2024-11-06T10:06:34+08:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data",
"Name": "es-plugins",
"Options": null,
"Scope": "local"
}
]可以看到elasticsearch的插件挂载到了/var/lib/docker/volumes/es-plugins/_data这个目录。要把IK分词器上传至这个目录,你可以在官网下载,
https://codeload.github.com/infinilabs/analysis-ik/zip/refs/tags/v7.12.1
你需要对其解压然后上传至虚拟机的/var/lib/docker/volumes/es-plugins/_data这个目录
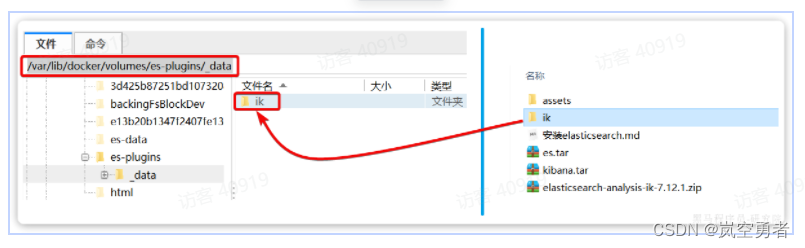
最后重启elasticsearch容器
至此就是docker部署ElasticSearch容器的内容,谢谢你的观看















 5126
5126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









