






本篇主要希望通过对C语言内存管理的复习来浅层理解C++中的内存管理
目录
3. operator new与operator delete函数
不建议malloc、free和new delete混用,否则可能崩溃:
1.C语言内存管理方式
int globalVar = 1;
static int staticGlobalVar = 1;
void Test()
{
static int staticVar = 1;
int localVar = 1;
int num1[10] = { 1, 2, 3, 4 };
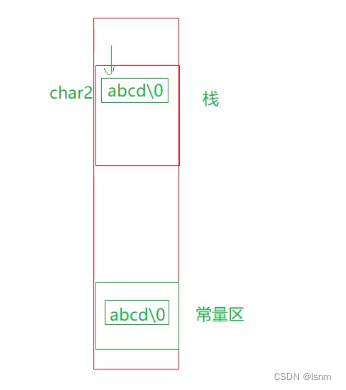
char char2[] = "abcd";
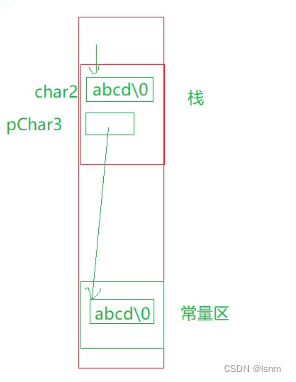
const char* pChar3 = "abcd";
int* ptr1 = (int*)malloc(sizeof(int) * 4);
int* ptr2 = (int*)calloc(4, sizeof(int));
int* ptr3 = (int*)realloc(ptr2, sizeof(int) * 4);
free(ptr1);
free(ptr3);
}
/*1. 选择题:
选项: A.栈 B.堆 C.数据段(静态区) D.代码段(常量区)
globalVar在哪里?____ staticGlobalVar在哪里?____
staticVar在哪里?____ localVar在哪里?____
num1 在哪里?____
char2在哪里?____ *char2在哪里?___
pChar3在哪里?____ *pChar3在哪里?____
ptr1在哪里?____ *ptr1在哪里?____
2. 填空题:
sizeof(num1) = ____;
sizeof(char2) = ____; strlen(char2) = ____;
sizeof(pChar3) = ____; strlen(pChar3) = ____;
sizeof(ptr1) = ____;
3. sizeof 和 strlen 区别?*/答案如下:

globalVar是全局变量,在数据段,4字节
staticGlobalVar是全局静态变量,在数据段,4字节
staticVar是静态变量,在数据段,4字节
localVar是局部变量,在栈上,4字节
num1是栈上开辟的数组名
char2是在栈上开辟的,其指向的内容是从常量区的常量字符串"abcd/0"拷贝到栈中的
作为一个指针,32位环境下是4字节
*char2在栈上,大小为5个字节(包括/0)
pChar3在栈上,*pChar3在常量区
ptr1在栈上,*ptr1在堆上
填空:
10*4 5 4 4(32位) 4 4

1. 栈 又叫堆栈 -- 非静态局部变量 / 函数参数 / 返回值等等,栈是向下增长的。2. 内存映射段 是高效的 I/O 映射方式,用于装载一个共享的动态内存库。用户可使用系统接口创建共享共享内存,做进程间通信。3. 堆 用于程序运行时动态内存分配,堆是可以上增长的。4. 数据段 -- 存储全局数据和静态数据。5. 代码段 -- 可执行的代码 / 只读常量
在之前的对内存的学习中,我们对内存有如下理解,现在我们进行回忆:1.对于栈来讲,是由编译器自动管理,无需我们手工控制;对于堆来说,释放工作由程序员控制。
2.对于栈来讲,生长方向是向下的,也就是向着内存地址减小的方向;对于堆来讲,它的生长方向是向上的,是向着内存地址增加的方向增长。
3.对于堆来讲,频繁的 new/delete 势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。对于栈来讲,则不会存在这个问题。
4.
栈大小与编译器有关,通常栈大小为1M。但在平时应用程序中,由于函数会使用栈结果,所以只能用略小于1M大小的栈
对于全局变量来说,与编译器有关。默认情况下全局变量数组大小是2G。由于程序本身的应用,所以只能使用小于2G的大小
对于Heap来说,与程序是32位还是64位,以及编译器都有关
32位程序可以申请的堆大小最大是2G。实际上只能小于2G,64位下也只能最多获得4G内存,实际上小于4G
“分区的目的是为了更高效的分类管理”
需要稍微强调一下的是代码段部分的“只读常量”。
被const修饰过的变量任然是 变量 :
const int a=0;中的a,任然在栈中,而不在代码段中,
const int* p="abcdefg"中的abcdefg才在常量区中。并且,如果像上文题目中的char2那样定义,还会将常量区的只读字符串拷贝一份到栈中char2对应的位置上。
如果像pchar3一样作为指针指向该常量区,那么该字符串不会拷贝。我们可以通过打印地址观察pchar3和char2对应的空间,差距还是比较大的。因为常量区字符串具有常性,所以必须用const修饰pchar3,避免权限放大的问题
回忆:如果此时再定义一个:
const char* pChar4 = "abcd";那么,pChar4和pChar3其实指向的是同一块常量区的空间。
2.new/delete
new和delete不是函数,而是两种操作符。
2.1针对内置类型

对于内置类型,new与malloc/calloc等区别不大,都是开辟空间然后初始化。
注意:申请和释放单个元素的空间,使用 new 和 delete 操作符,申请和释放连续的空间,使用 new[] 和 delete[] ,注意:匹配起来使用(尤其是leetcode,对这方面语法检查比较严格)。
其实,作为内置类型,new了一个数组之后用delete delete[] free都能成功清理,不会报错。
2.2针对自定义类型
如果按照C语言的方法,使用malloc开辟自定义类型的空间却有大问题:无法初始化。

(很多成员都被private修饰,初始化很困难)
因此new的本质是对malloc的一种升级和封装:
new会先开辟空间,再去调用他的默认构造或者传参构造
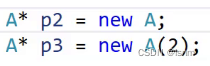
new除了开空间,还能调用构造函数。这样,一个自定义类就能在定义时被初始化,更符合使用规范的生成。
同理,delete除了会有free的封装,还会调用析构函数
class A
{
public:
A(int a = 0)
: _a(a)
{
cout << "A():" << this << endl;
}
~A()
{
cout << "~A():" << this << endl;
}
private:
int _a;
};也可以用自定义类型实现数组,但是语法规则稍有变化:
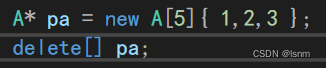
再申请5个空间后,可以直接通过花括号赋值,没有传参的部分会按照默认构造函数进行初始化。可以通过调试观察。
class A {
private:
int _a;
int _b;
public:
/*A(int a, int b)
:_a(a),
_b(b)
{
cout << "A(int a,int b)" << endl;
}*/
/*A(int a)
:_a(a),
_b(2)
{
cout << "A(int a)" << endl;
}*/
//为了避免调用歧义而注释掉
A(int a=1,int b=99)
:_a(a),
_b(b)
{
cout << "int a=1,int b=99" << endl;
}
A(const A& a)
:_a(a._a),
_b(a._b)
{
cout << "A(const A& a)" << endl;
}
};
int main() {
A* pa = new A[5]{ 1,2,3 };//给前三个A类都各自只传了一个参数
delete[] pa;
return 0;
}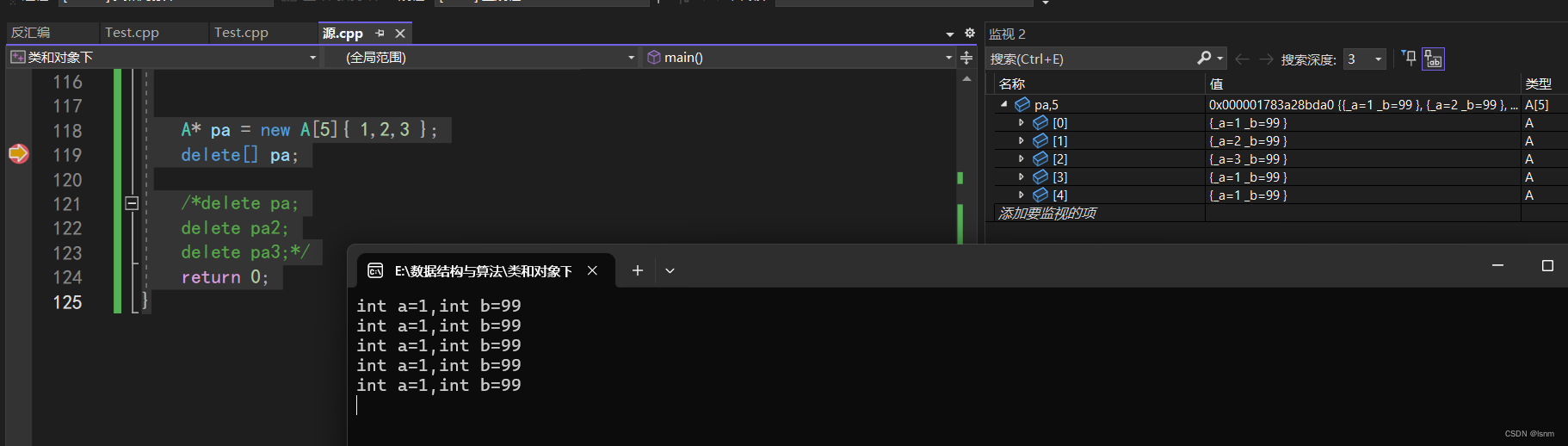 前三个我们只传了_a,所以_b使用默认值,后两个什么都没传,所以全使用默认值。
前三个我们只传了_a,所以_b使用默认值,后两个什么都没传,所以全使用默认值。
也可以使用拷贝构造、中括号多参数、隐式转换等方式赋值:
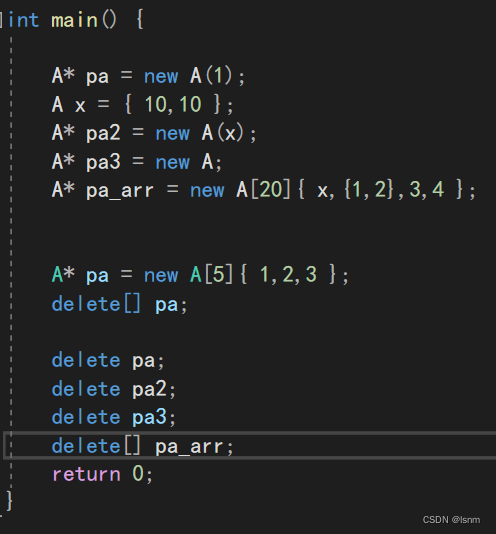
观察如下代码:
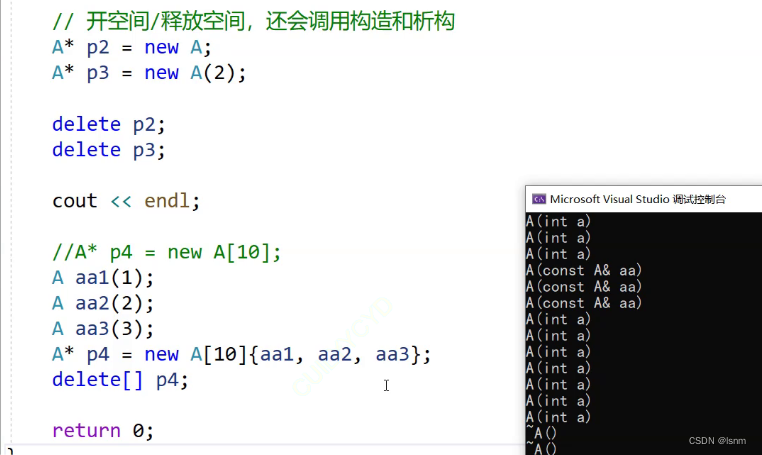
p4数组的十个对象中,三个调用拷贝构造,七个调用默认构造。
可以用匿名对象传参,也可以直接使用隐式类型转换:

多参数也支持:

new对自定义类型的操作是C语言无法比拟的。
不过C++在扩容上没有renew的概念,都需要手动扩容。
下面我们再进一步的学习new和delete的运行逻辑。
3. operator new与operator delete函数
这是库中写好的两个全局函数。
new 和 delete 是用户进行 动态内存申请和释放的操作符 , operator new 和 operator delete 是系统提供的 全局函数 , new 在底层调用 operator new 全局函数来申请空间, delete 在底层通过 operator delete 全局函数来释放空间。也就是说:new的底层是operator new+构造函数delete的底层是析构函数+operator delete
而目前为止,我们可以认为operator是对malloc的封装,operator delete是对free的封装
理清楚new和delete 与 构造函数和析构函数的区别
我们调用一个int类型的栈,该栈中有一个数组指针,指向堆区动态开辟的数组。
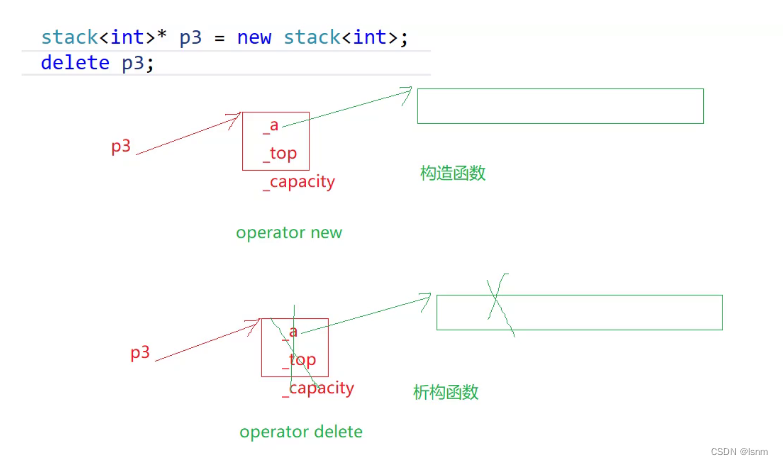
operator new开辟的是_a _top _capacity
而栈内部的构造函数就会去开辟数组空间。
析构函数释放的是我们申请出的、需要手动释放的资源,比如此处我们刚刚动态开辟的栈。
然后operator delete会释放 _a _top _capacity 。
(并不代表operator delete/new只能开辟内置类型,析构函数中同样使用的是delete和new)
delete相对free的优点:
以前需要检查开辟空间是否成功,现在不需要检查

new如果失败了就会抛异常,并且不会执行之后的new语句。
总结,operator new就是 malloc + 失败抛异常,new是operator new + 构造函数,new比malloc多做了很多事情,功能更加全面,是对malloc的高效封装;operator delete 就是对free的封装,delete就是operator delete + 析构函数
不建议malloc、free和new delete混用,否则可能崩溃:
除了有operator new/delete函数,语法规定,还有operator new[]和operator delete[]函数。
new 的原理1. 调用 operator new 函数申请空间2. 在申请的空间上执行构造函数,完成对象的构造delete 的原理1. 在空间上执行析构函数,完成对象中资源的清理工作2. 调用 operator delete 函数释放对象的空间new T[N] 的原理1. 调用 operator new[] 函数,在 operator new[] 中实际调用 operator new 函数完成 N 个对象空间的申请2. 在申请的空间上执行 N 次构造函数delete[] 的原理1. 在释放的对象空间上执行 N 次析构函数,完成 N 个对象中资源的清理2. 调用 operator delete[] 释放空间,实际在 operator delete[] 中调用N次 operator delete 来释放空间。3.至于如何得到N,会在后文中说明。
delete自定义类型数组的崩溃之谜
class A {
public:
A(int a = 1)
:_a(a)
{
cout << "A(int a = 1)" << endl;
}
~A() {
cout << "~A()" << endl;
}
private:
int _a = 0;
};


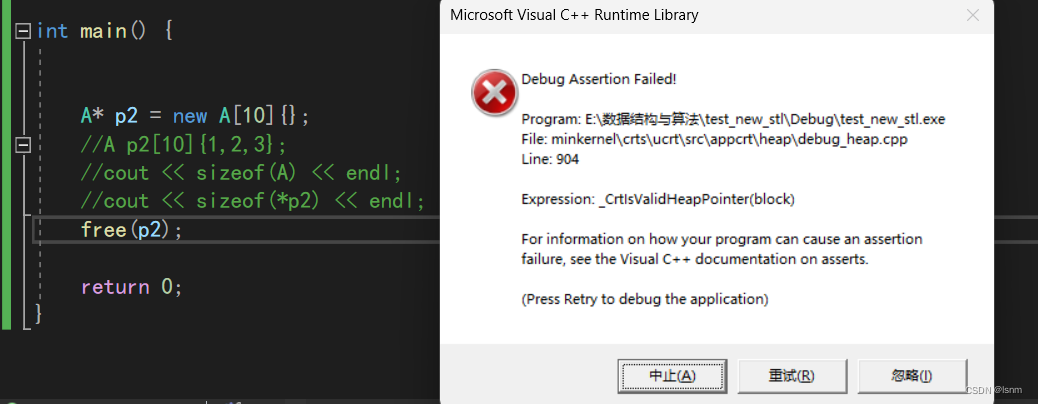
A* p2 = new A[10];
free(p2);
A* p2 = new A[10]{};
delete p2;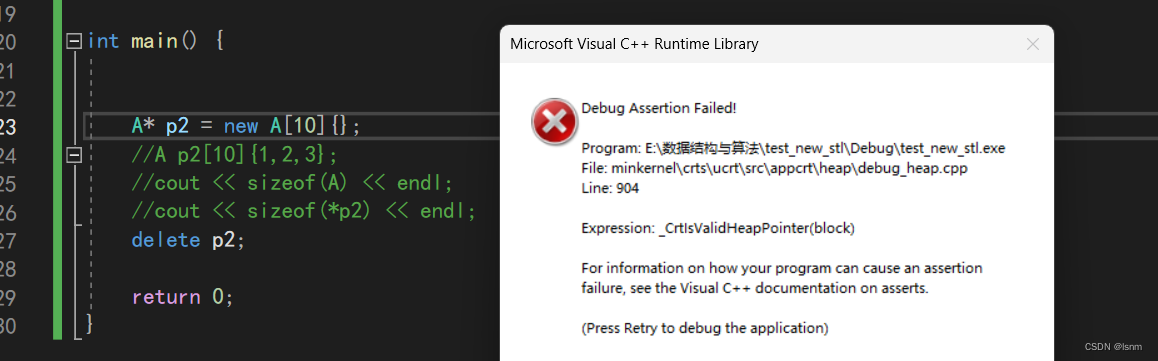
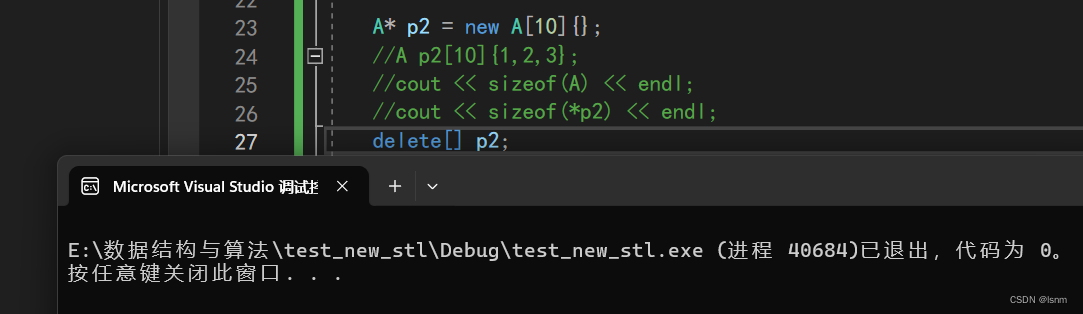

这个 个数 的目的是为了让编译器知道该调多少次析构函数。free/delete就不会去使用这个个数,但是 delete[ ] 就会从给的这个地址往前找四个字节拿到 个数再调用 个数 次所以此处不仅free会报错,delete也会报错,他们两个都不会向前移动四个字节去找个数,都会当作只有一个对象来操作。但是delete[ ]就不会报错,因此delete[ ]必须要和new [ ]搭配使用。但如果我们不显示的实现析构,编译器会认为此时没有必要 必须使用析构(除了此处的A是为了教学的目的,大部分时候确实有需要手动释放的资源才会显式实现析构函数)才能释放的资源,不会多在数组前面加 个数,使用free和delete也就不会报错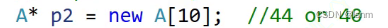 因此,有显式实现析构函数,p2对应的大小是44,没有显示实现析构,大小就是40。结论:不要错配使用,否则,可能会内存泄漏,也可能程序崩溃。
因此,有显式实现析构函数,p2对应的大小是44,没有显示实现析构,大小就是40。结论:不要错配使用,否则,可能会内存泄漏,也可能程序崩溃。
4.定位new的位置(placement-new)
如果我们希望显式手动调用析构、构造函数时,有如下场景:

或者在线程池(不了解可以略过)中:

或者使用operator new而非new中(operator new的用法和malloc是相似的):

不允许这样显式调用构造函数。
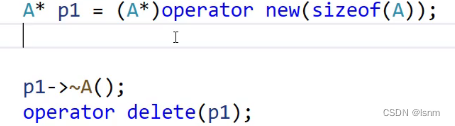


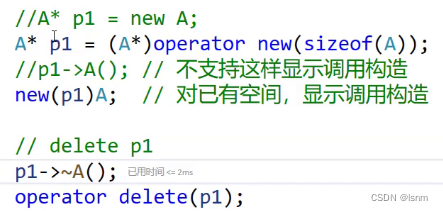
等价并且合规的做法是:
A* p3 = (A*)operator new (sizeof(A));
A* p4 = (A*)operator new (sizeof(A));
//p3->A();
new(p3)A;
new(p4)A(5);可以在类型名后面调用默认构造,也可以传参构造、拷贝构造等。
用循环就可以初始化很多个变量

定位new主要用于对先malloc或者直接operatoe new出的已有空间的对象进行构造,也就是对无法自动调用构造函数的开辟空间的方法进行构造。
本质上:
new和delete就是对以上功能的封装,当前阶段我们直接使用new/delete即可。
在内存池的使用中,定位new就有使用价值。
5.内存管理中的易错点
1. malloc和free是函数,new和delete是操作符2. malloc申请的空间不会初始化,new可以初始化3. malloc申请空间时,需要手动计算空间大小并传递,new只需在其后跟上空间的类型即可,如果是多个对象,[]中指定对象个数即可4. malloc的返回值为void*, 在使用时必须强转,new不需要,因为new后跟的是空间的类型5. malloc申请空间失败时,返回的是NULL,因此使用时必须判空,new不需要,但是new需要捕获异常6. 申请自定义类型对象时,malloc/free只会开辟空间,不会调用构造函数与析构函数,而new在申请空间后会调用构造函数完成对象的初始化,delete在释放空间前会调用析构函数完成空间中资源的清理7.栈可以动态、静态分配,但是 堆 只能动态分配。8.变量都遵循先使用后销毁,静态变量也是如此。















 1559
1559











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









