









在访问某些网站时,selenium webdriver 开启网页失败,被发现为爬虫,目前我碰到的有效解决方案是:
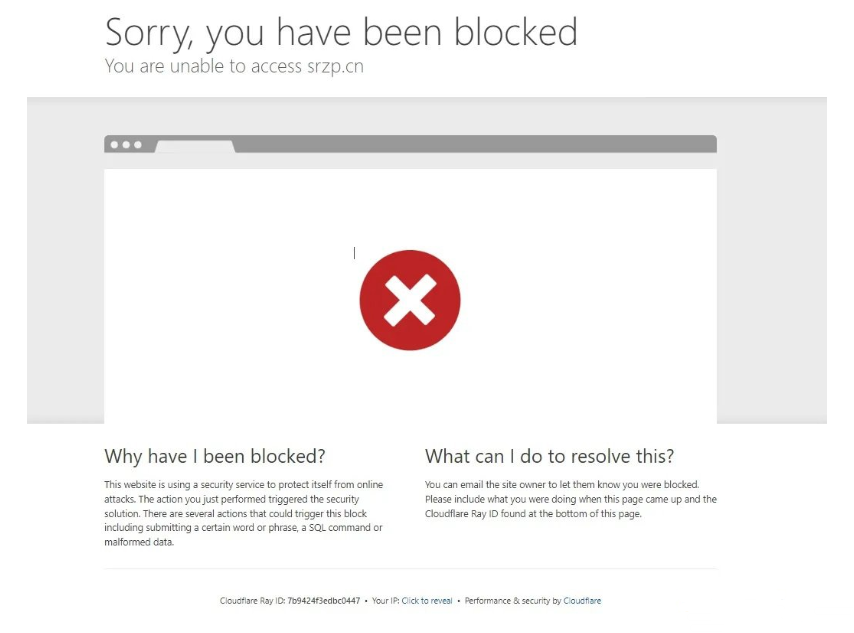
1、因为selenium在命令行手动开启后的谷歌浏览器加了一些变量值,比如window.navigator.webdriver,在正常的谷歌浏览器是undefined,在selenium打开的谷歌浏览器是True,然后对方服务器就会下发js代码,检测这个变量值给网站,网站判断这个值,为True就是爬虫程序就封锁你的访问,如下图。
实现代码是在请求之前改变一些参数,绕过检测,具体细节可以自己了解下网站检测selenium的原理,需要设置对应其它的值都可以加:
-
# 下面代码本人是基于命令行打开再接管浏览器窗口, -
from selenium import webdriver -
options = webdriver.ChromeOptions() -
-
# chrome在79版之前用下面两行代码 -
#options.add_experimental_option("excludeSwitches", ["enable-automation"]) -
#options.add_experimental_option('useAutomationExtension', False) -
-
# -我是最新谷歌浏览器版本,chrome在79和79版之后用这个, -
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", { -
"source": """ -
Object.defineProperty(navigator, 'webdriver', { -
get: () => undefined -
}) -
""" -
}) -
driver.get("这里填写你被反爬网站的链接")
总结:
感谢每一个认真阅读我文章的人!!!
作为一位过来人也是希望大家少走一些弯路,如果你不想再体验一次学习时找不到资料,没人解答问题,坚持几天便放弃的感受的话,在这里我给大家分享一些自动化测试的学习资源,希望能给你前进的路上带来帮助。

软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

视频文档获取方式:
这份文档和视频资料,对于想从事【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!以上均可以分享,点下方小卡片即可自行领取。















 403
403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









