







ES原理
Es核心概念
-
索引: 管理着下面的文档集合
-
文档:相当于一个类中的数据总和,相当于数据库的行
-
分片:相当于容器储存着索引数据
一个索引得数据可以分布在多个分片中
一个Lucene索引在ES中为分片,在查询的时候会将请求发送到属于索引的分片,为分割分片的结果到一个全局的结果集:由于节点间的通信问题问题。使得每个节点都认为自己是主节点
-
分配
将分片分配给某个节点的过程,包括主分片或者副本,还包含主从复制过程。
-
副本
为分片提供备份,提高高可用,并且不要和主分片不在一个节点上。要不然注解点崩溃了副本数据也没有了。但是多节点要注意脑裂问题:ES规范
-
字段设计类型规范:
要确定该字段的扩展性和用来搜索的功能性
好,我们一步一步来,既**帮你梳理你这个索引的字段适合什么类型**,也**详细解释一下 boolean、long 和 keyword 等字段类型是否建立倒排索引**。
---
## ✅ 一、你的索引字段梳理与建议
你提供的字段如下:
| 字段名 | 类型 | 建议类型 | 原因 |
|----------------|-----------|------------|------|
| `id` | keyword | ✅ `keyword` | 主键唯一标识,精确匹配,不需要分词 |
| `deleted` | boolean | ✅ `boolean` 或 `keyword` | 如果值仅为 true/false,`boolean` 可更省存储;如果有脏数据可能是 `"true"`,用 `keyword` 更保险 |
| `enabled` | boolean | ✅ 同上 |
| `root` | boolean | ✅ 同上 |
| `mgt_org_id` | long | ✅ `long` | 数值型 ID,可用于范围查找、排序、聚合 |
| `name` | keyword | ✅ `keyword` 或 `text+keyword` | 如果仅用于精确匹配可用 `keyword`,若支持搜索建议 `text+keyword` |
| `phone` | keyword | ✅ `keyword` | 电话号码必须精确匹配,不分词 |
| `password` | keyword | ✅ `keyword` | 密码字段必须精确匹配 |
| `roles` | keyword[] | ✅ `keyword` | 角色 ID 列表,只做过滤和精确匹配 |
| `create_id` | long | ✅ `long` | 创建人 ID,做过滤排序 |
| `push_except` | boolean | ✅ `boolean` | 是否推送排除,true/false |
| `create_time` | date | ✅ `date` | 日期字段,排序、范围过滤 |
| `offline_time` | date | ✅ `date` | 同上 |
结论:你的字段定义已经非常合理了。大部分使用了 `boolean` / `long` / `keyword`,根据字段含义和使用场景没有明显问题 ✅。
---
## ✅ 二、这些类型是否建立倒排索引?
这是个关键问题,下面是重点讲解:
### 1. 🔤 `keyword` 类型会建立倒排索引
- ✅ **默认会建立倒排索引**(用于 `term`、`terms` 查询、聚合、排序);
- ❌ 不建立 `全文索引`,即不分词。
### 2. 🔢 `long` / `integer` 等数值类型也建立索引,但不是倒排索引
- ✅ **Elasticsearch 为数值类型构建的是 BKD 树(Block KD-Tree)索引结构**;
- ❌ 不使用 Lucene 倒排索引(Inverted Index);
- 🔍 这种索引非常适合做范围查询(如 `range`)、排序、聚合等;
- 📊 这些类型是 columnar 存储(列式),不参与 full-text 搜索。
### 3. ✅ `boolean` 类型和 `keyword` 类似,会建立倒排索引
- ✅ Lucene 中的 `boolean` 是通过一个非常紧凑的数据结构处理的;
- ✅ 适合用 `term` 过滤;
- ❌ 不能做 range 查询(因为不是数值);
- 🚨 注意:如果只取某个布尔字段为 true 的文档,其效率非常高,哪怕文档量很大。
---
## ✅ 三、其他几个小知识点扩展(建议收藏)
| 类型 | 是否建立索引 | 是否倒排索引 | 适合查询 |
|----------|----------------|------------------|------------|
| `keyword` | ✅ 默认是 | ✅ 是(term 索引) | 精确匹配、聚合、排序 |
| `text` | ✅ 默认是 | ✅ 是(分词后) | 全文搜索 |
| `boolean` | ✅ 默认是 | ✅ 是(term 索引) | 过滤 |
| `long` / `int` | ✅ 默认是 | ❌ 不是倒排索引(BKD树) | 范围查询、排序、聚合 |
| `date` | ✅ 默认是 | ❌ BKD 树 | 时间过滤、排序 |
---
## 📌 总结一句话:
> - `keyword` 和 `boolean` 是构建倒排索引的;
> - `long` / `int` / `date` 是构建 BKD 树(非倒排索引);
> - **是否倒排 ≠ 是否索引**,数值型和日期型同样支持高效过滤,只是结构不同。
---
如果你还有哪些字段打算添加进 mapping,我也可以帮你提前判断类型和用途,避免以后踩坑。你觉得要不要我给你来一个可复用的 mapping 模板结构?😎
关于 **Elasticsearch 规范**,可以从以下几个方面来系统地整理,包括索引、文档、字段命名、映射、查询、性能、安全等规范。以下是较为通用、实际可用的一套 **Elasticsearch 使用规范文档**,适用于开发、运维和数据建模阶段:
---
## 🗂 1. 索引规范(Index Naming)
- 使用 **小写字母 + 下划线或中划线**,不支持大写字母。
- 推荐命名格式:`业务_模块_环境` 或 `业务-时间`
例如:`order_log_prod`,`user-profile-2025-04`
- 避免使用时间戳作为索引名(推荐做索引别名指向时间索引)。
---
## 📄 2. 文档规范(Document)
- 文档 `_id` 可使用业务主键(如订单号、用户ID)或使用系统生成的 UUID。
- 每条文档大小应控制在 **1MB 以内**(过大影响性能)。
- 避免频繁更新文档中的嵌套字段(nested 会带来性能问题)。
---
## 🔤 3. 字段命名规范(Field Naming)
- 使用 **小写 + 下划线**,避免使用中文或特殊字符。
- 命名应有语义,例如:
- `user_id`, `order_time`, `total_price`
- 避免与 Elasticsearch 保留字段冲突,如 `_id`, `_index`, `_type`。
---
## 📐 4. 映射规范(Mapping)
- 尽量使用 **显式映射**(`PUT mapping`),避免动态映射造成字段膨胀。
- 控制字段类型数量:例如 `text`, `keyword`, `integer`, `date` 等。
- 文本字段规则:
- 短文本(如状态码、分类等):使用 `keyword`
- 可搜索文本:使用 `text` 并指定 `analyzer`
- 如需聚合、排序:`text` + `keyword` 组合字段
示例:
```json
"user_name": {
"type": "text",
"fields": {
"keyword": { "type": "keyword" }
}
}
```
---
## 🔍 5. 查询规范(Query DSL)
- 查询优先使用 **bool + must/must_not/should** 组合。
- 避免 wildcard、regexp 查询在高频数据字段中使用(性能消耗大)。
- 使用分页查询时,from+size 不宜太大,推荐 scroll 或 search_after。
- 使用 filter 替代 must 做无评分查询,提高性能。
---
## 🚀 6. 性能规范
- 控制索引分片数量:
- 小索引(<10GB)建议单分片。
- 大索引按数据量划分(推荐 30~50GB/分片)。
- 合理设置副本(replica)数量,一般为 1。
- 使用压缩:`"codec": "best_compression"`。
- 开启 refresh_interval 合理延迟,避免写入频繁触发刷新。
---
## 🔐 7. 安全与权限规范
- 使用 X-Pack 或 OpenSearch 安全模块做认证与权限控制。
- 禁止公网直接暴露 9200 端口,使用代理或网关访问。
- 限制操作权限(写、删)至必要角色。
---
## 📊 8. 日志与监控规范
- 配置 slowlog,监控慢查询:
- `index.search.slowlog.threshold.query.warn: 1s`
- 使用 Elastic Stack(Kibana、Beats、Logstash)进行指标收集与告警。
- 使用 ILM(Index Lifecycle Management)管理老旧索引。
---
## 🔄 9. 索引生命周期管理(ILM)
- 写入活跃期:热节点(Hot)
- 存档期:温节点(Warm)
- 归档期:冷节点(Cold)
- 过期删除:Delete Phase
---
如果你想我根据你实际项目来定制一套更符合你团队的 Elasticsearch 使用规范(比如中文搜索、日志收集、大数据分析等场景),可以告诉我更多细节。需要我补充吗?KDB树:存储地理位置信息和基本数据类型如integer,double、bool等数据。利于范围查询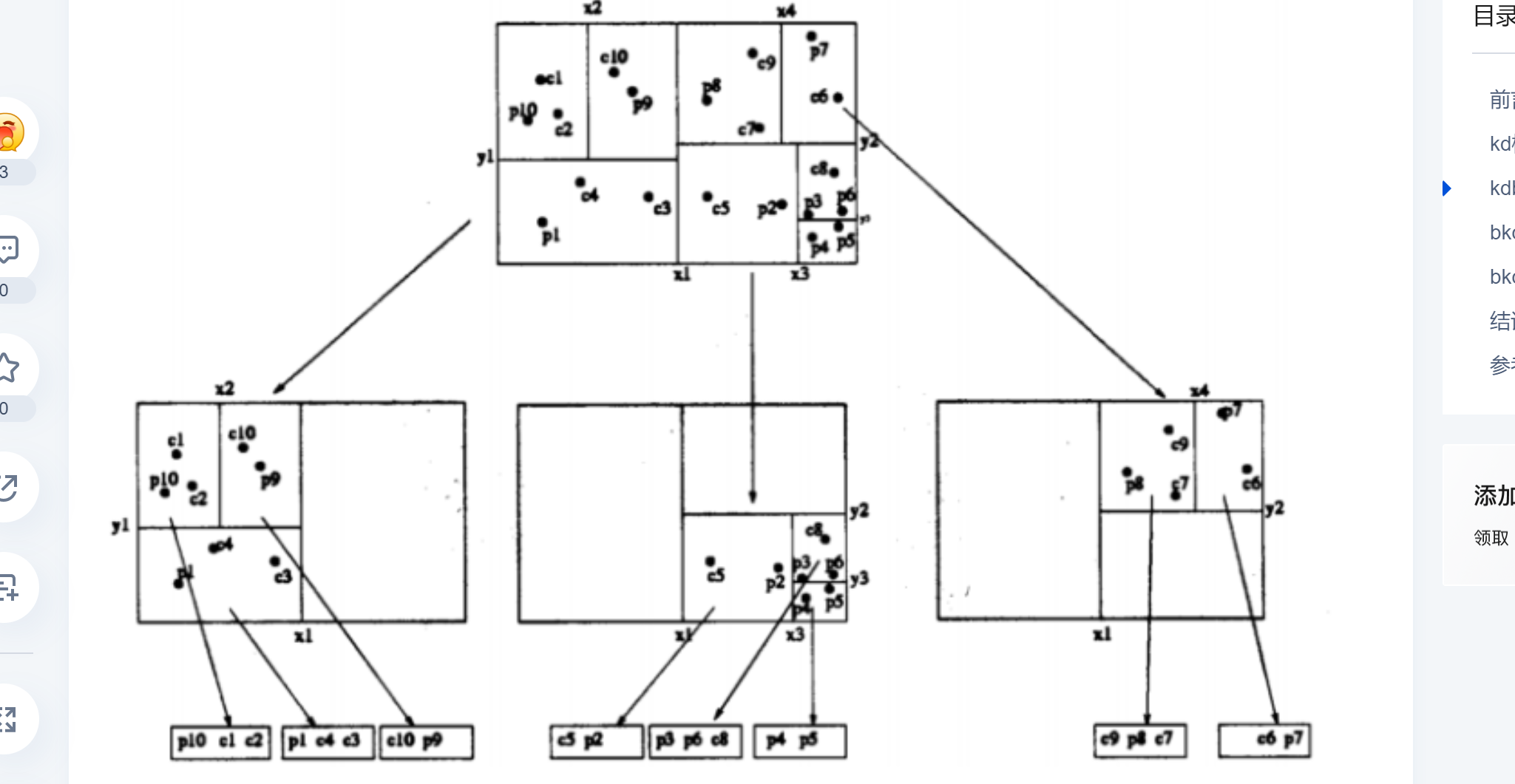
ES加快查询效率
查询方法:
@Query
NativeSearchQuryBuilder构建
QueryBuilder ES原生DSL查询
在 Spring Boot 中使用 Elasticsearch(通常通过 Spring Data Elasticsearch),你可以通过多种方式执行查询操作,包括:
- **Repository 接口方法查询(基于方法命名规则)**
- **`@Query` 注解查询**
- **`NativeSearchQueryBuilder` 构建原生查询**
- **`QueryBuilders`(Elasticsearch 原生 DSL 查询)**
下面我会根据 **字段类型分类**,列举出 Elasticsearch 中常见的查询操作在 Spring 中的写法,涵盖:
---
## 🧩 一、`keyword` 类型(不分词,精确匹配)
### ✅ 精确匹配
```java
QueryBuilders.termQuery("name", "Tom")
```
### ✅ 多个值匹配
```java
QueryBuilders.termsQuery("status", "ACTIVE", "INACTIVE")
```
### ✅ 前缀匹配
```java
QueryBuilders.prefixQuery("username", "adm")
```
### ✅ 通配符匹配
```java
QueryBuilders.wildcardQuery("username", "adm*")
```
---
## 📃 二、`text` 类型(分词,全文搜索)
### ✅ 匹配查询(自动分词)
```java
QueryBuilders.matchQuery("description", "spring boot elasticsearch")
```
### ✅ 多字段匹配
```java
QueryBuilders.multiMatchQuery("elasticsearch", "title", "description")
```
### ✅ 短语匹配
```java
QueryBuilders.matchPhraseQuery("description", "spring boot")
```
---
## 🔢 三、`long` / `integer` / `float` / `double` 类型
### ✅ 精确匹配
```java
QueryBuilders.termQuery("age", 30)
```
### ✅ 范围查询
```java
QueryBuilders.rangeQuery("price").gte(100).lte(500)
```
---
## 📅 四、`date` 类型
### ✅ 时间范围查询
```java
QueryBuilders.rangeQuery("create_time")
.gte("2024-01-01 00:00:00")
.lte("2024-12-31 23:59:59")
.format("yyyy-MM-dd HH:mm:ss")
```
---
## 🎯 五、`boolean` 类型
### ✅ 布尔字段匹配
```java
QueryBuilders.termQuery("enabled", true)
```
---
## 🧠 六、组合查询(复合查询)
### ✅ `bool` 查询:组合多个条件
```java
QueryBuilders.boolQuery()
.must(QueryBuilders.termQuery("status", "ACTIVE"))
.must(QueryBuilders.rangeQuery("score").gte(80))
.mustNot(QueryBuilders.termQuery("deleted", true))
```
---
## 🔍 七、模糊查询(fuzzy)
### ✅ 用于拼写容错(适合短文本,如人名)
```java
QueryBuilders.fuzzyQuery("name", "Jon") // 会匹配 "John"、"Jonh" 等
```
---
## 🧾 八、通用 Spring Data 查询构建方式
### ✅ 使用 `NativeSearchQueryBuilder`
```java
SearchQuery query = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.matchQuery("title", "elasticsearch"))
.withPageable(PageRequest.of(0, 10))
.build();
List<Article> result = elasticsearchRestTemplate.search(query, Article.class);
```
---
## 🧪 九、Repository 接口方法派生查询(适用于 `keyword`)
```java
interface UserRepository extends ElasticsearchRepository<User, String> {
List<User> findByName(String name);
List<User> findByEnabled(boolean enabled);
List<User> findByAgeBetween(int min, int max);
List<User> findByCreateTimeAfter(Date startTime);
}
```
---
## 🧾 十、聚合(Aggregations)
```java
AggregationBuilders.terms("by_status").field("status.keyword")
```
```java
AggregationBuilders.avg("avg_price").field("price")
```
---
## ✨ 总结表格:字段类型 vs 查询方式
| 字段类型 | 支持的查询类型 |
|---------------|---------------------------------------------------------------|
| `keyword` | term, terms, wildcard, prefix, exact match |
| `text` | match, match_phrase, multi_match, full-text search |
| `long/int` | term, range, gt/gte/lt/lte, sort |
| `date` | term, range, before/after, format |
| `boolean` | term (true / false) |
| 所有类型 | bool (组合查询), must, must_not, should, filter |
| 数值类/日期类 | 排序、聚合、范围过滤 |
| `text` 类型 | 不可用于排序,聚合前需要 `.keyword` 子字段 |
---
如果你正在使用 `ElasticsearchRestTemplate` 或 `Spring Data Elasticsearch Repository`,也可以贴下你的使用方式,我可以帮你进一步封装常用的查询模板 🔧。要不要我也给你整理一个 Java 封装查询方法的工具类?
-
配置优化:
- 增大分片分配时间使得可以使得节点有益于恢复数据
- 文档写入速度优化:
- 加大transaction FLush 降低logs,writeLock次数
- 增加IndexRefresh间隔,减少segment Merge次数
调整Bulk线程池和队列
优化节点的任务分布
最终我们都会采用31 G 设置-Xms 31g-Xmx 31g
堆内存过大,Lucene 可用的内存将会减少,就会严重影响降低Lucene 的全文本查询性能。ES集群
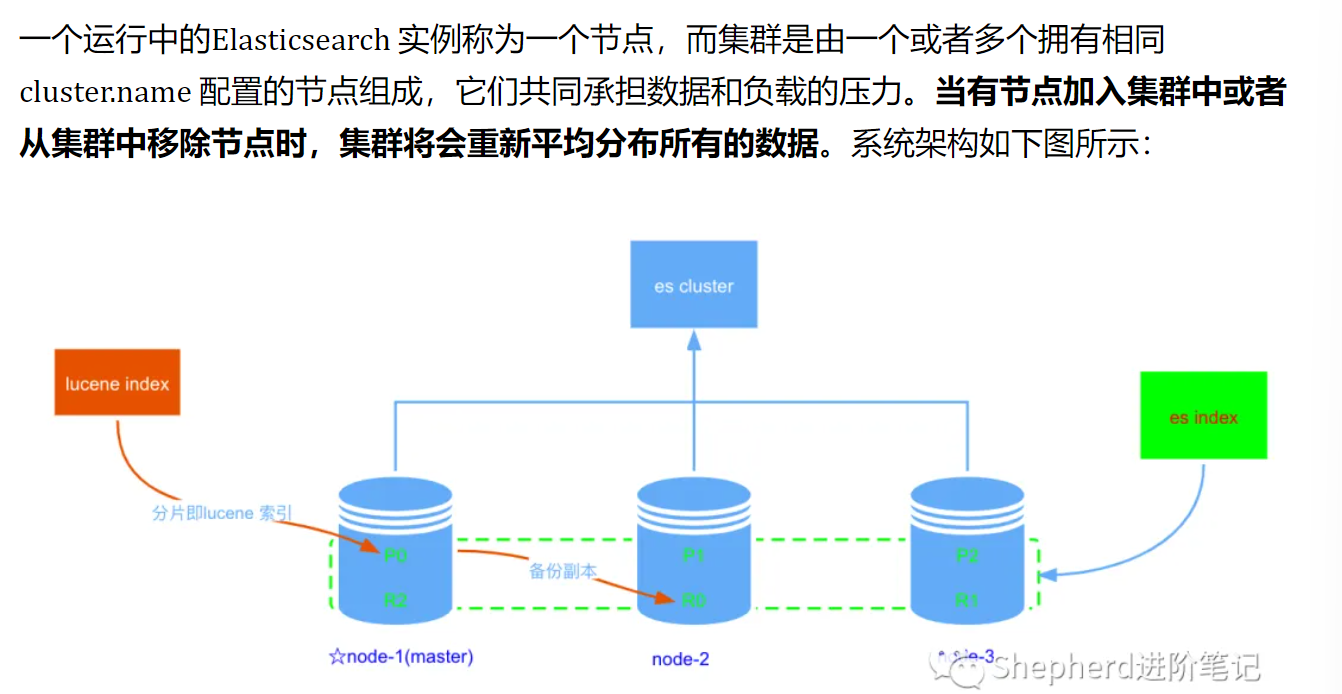
-
主节点只用进行索引的增删改查主节点不需要文档级别的变更和搜索
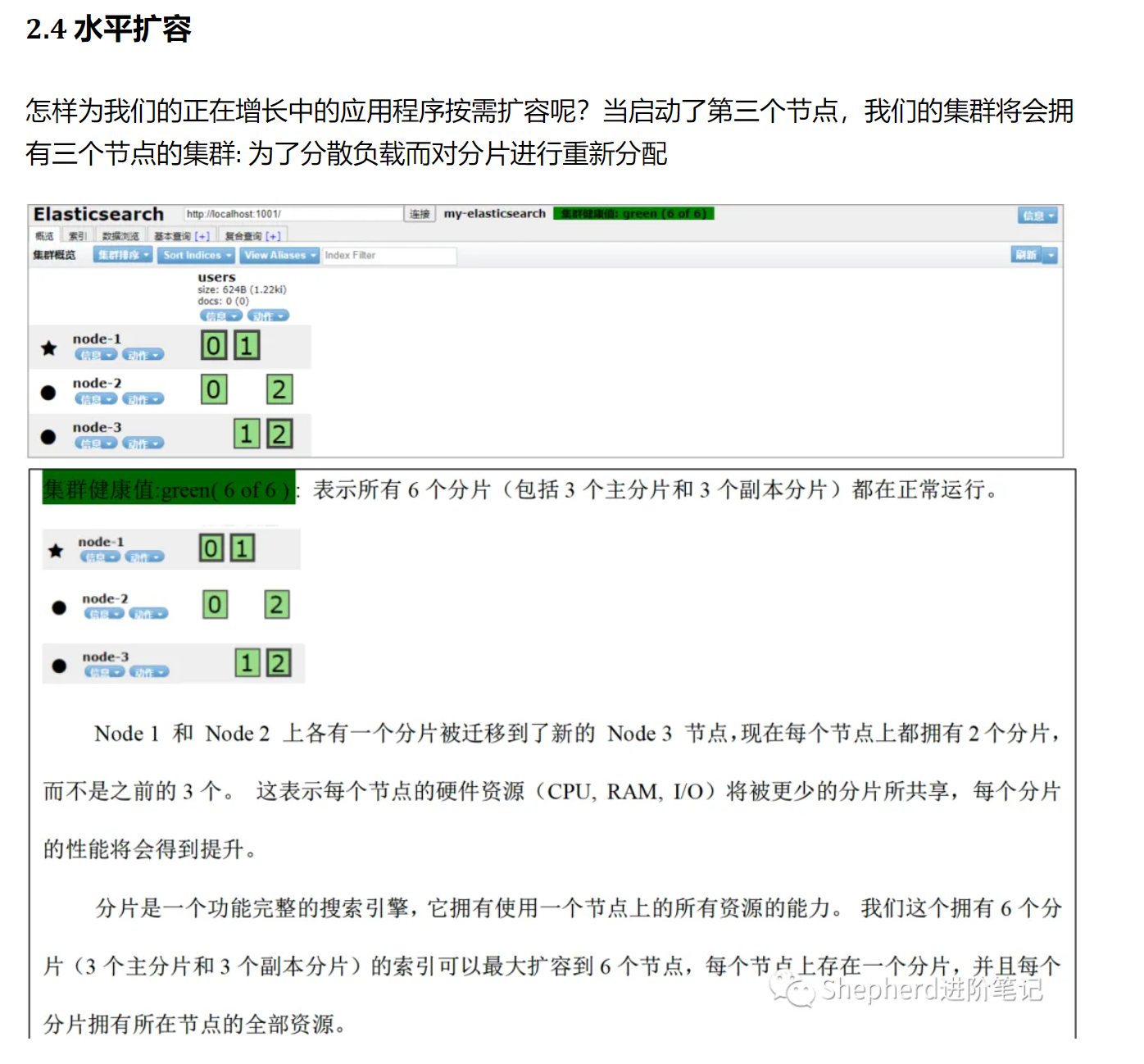
-
路由配置:
当索引一个文档会被存储到主分片。ES如何知道一个文档应该存放分片。创建文档时,会被路由到对应的节点
shard = hash (route) % number_of_primary_shards:
route默认是文档的_id,routing通过hash函数生成一个数字,所以在创建索引就确认了主分片的数量。
文档API(get 、index 、delete 、bulk 、update 以及mget )都接受一个叫做routing 的路由参数,通过这个参数我们可以自定义文档到分片的映射
-
具体流程:
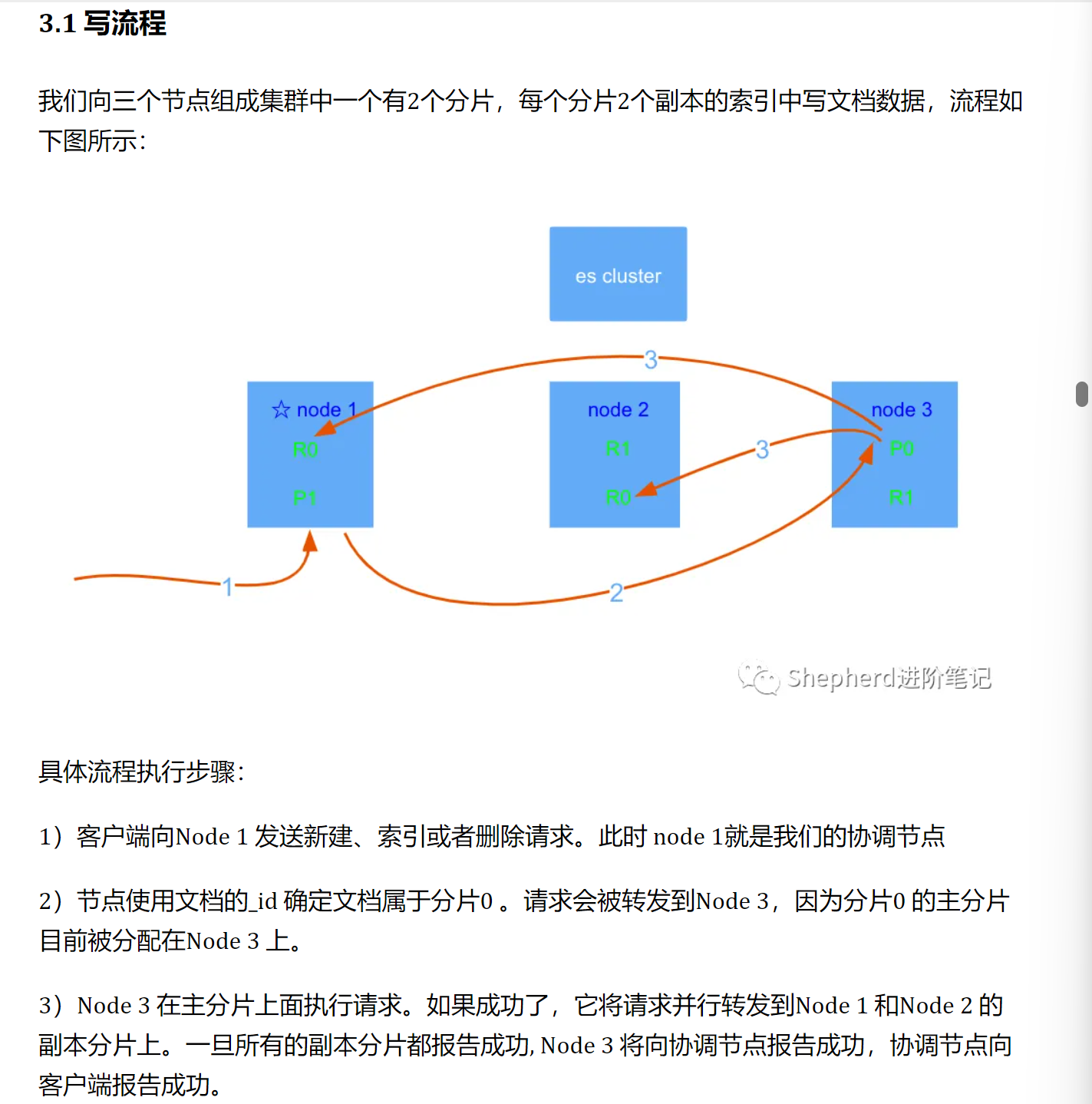
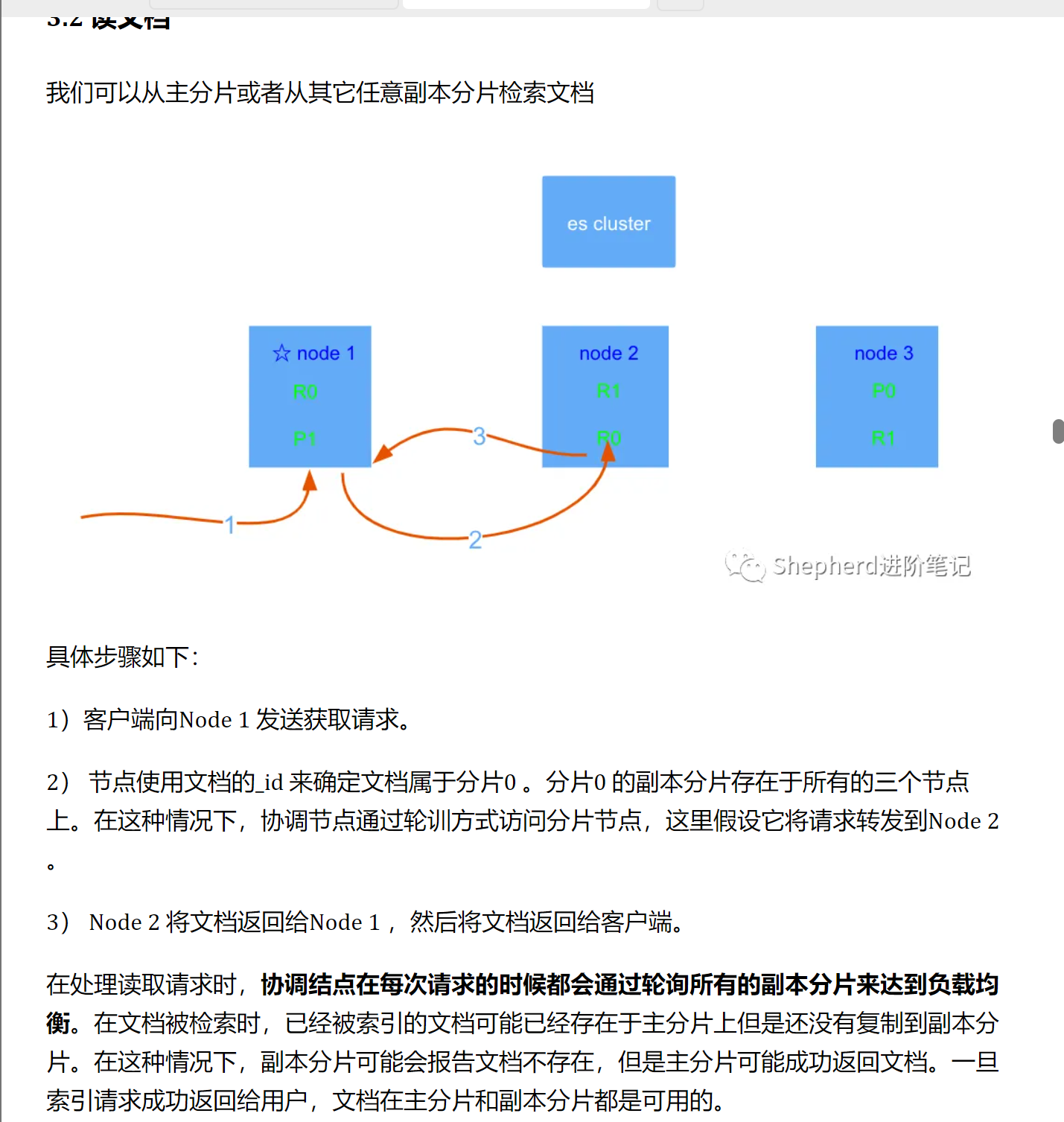
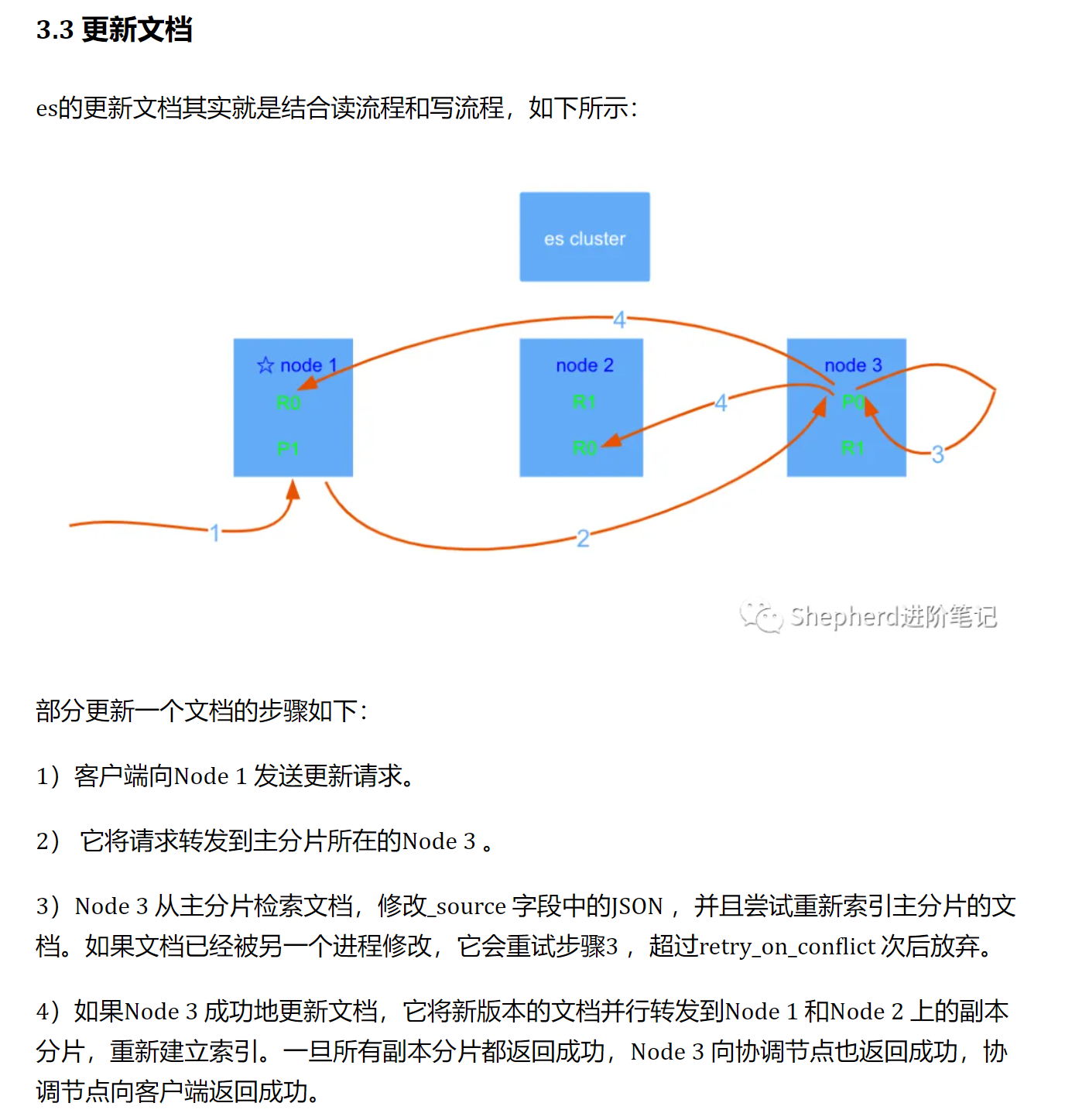
-
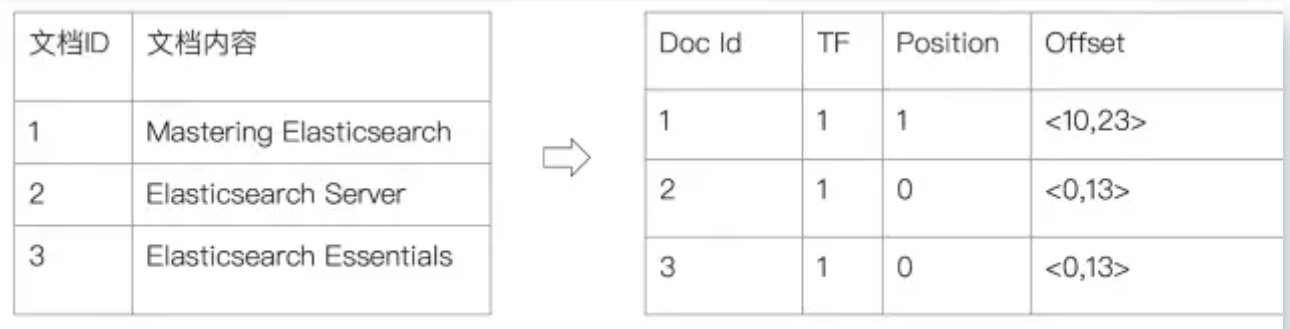
倒排索引:
4.3 动态更新索引
用更多的索引。通过增加新的补充索引来反映新近的修改,而不是直接重写整个倒排索引。每一个倒排索引都会被轮流查询到,从最早的开始查询完后再对结果进行合并。
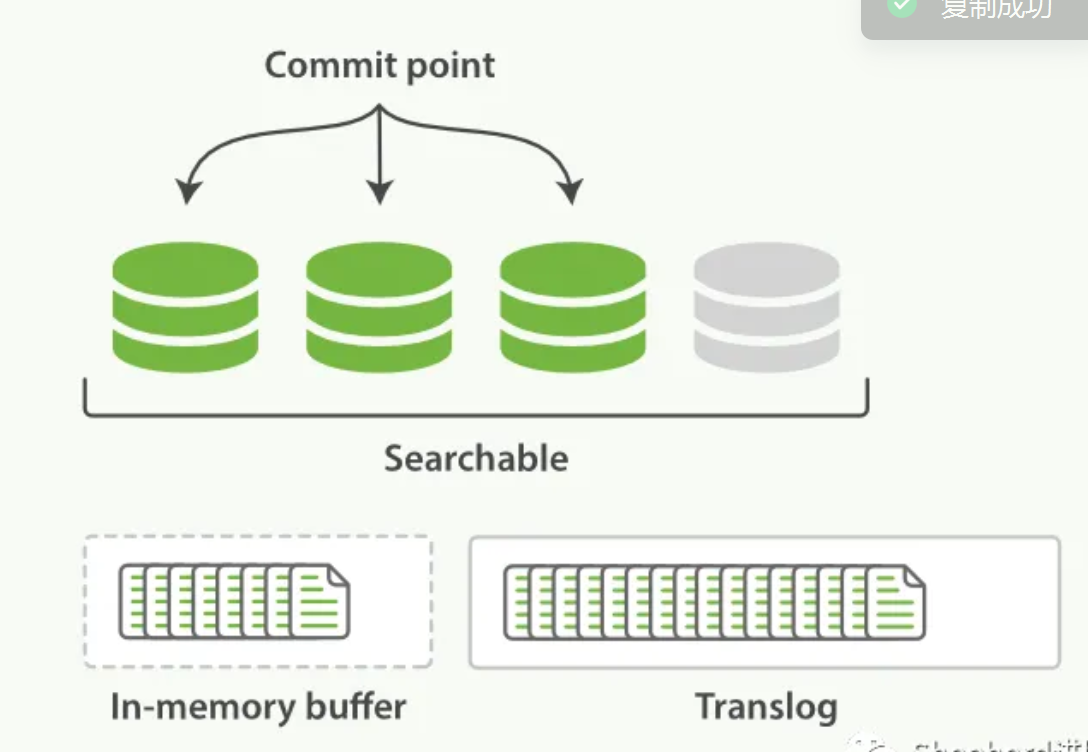
段是不可改变的,所以既不能把文档从旧的段中移除,也不能修改旧的段来进行反映文档的更新。取而代之的是,每个提交点会包含一个 .del 文件,文件中会列出这些被删除文档的段信息。当一个文档被 “删除” 时,它实际上只是在 .del 文件中被 标记 删除。一个被标记删除的文档仍然可以被查询匹配到, 但它会在最终结果被返回前从结果集中移除
Lucene 允许新段被写入和打开,从而使其包含的文档在未进行一次完整提交时便对搜索可见。这种方式比进行一次完整提交代价要小得多,并且在不影响性能的前提下可以被频繁地执行。
倒排索引具有文档(这里的文档包含分词后各个位置的部分的分词,会对应对应的文档_id和TF(词频),位置:单词在文档分词的位置,和偏移量:实现高亮显示)
倒排索引的底层数据结构:Lucene
是由 Lucene 构建和维护的,其底层使用词典树(如 FST)+ 倒排表结构,并进行了大量压缩和优化
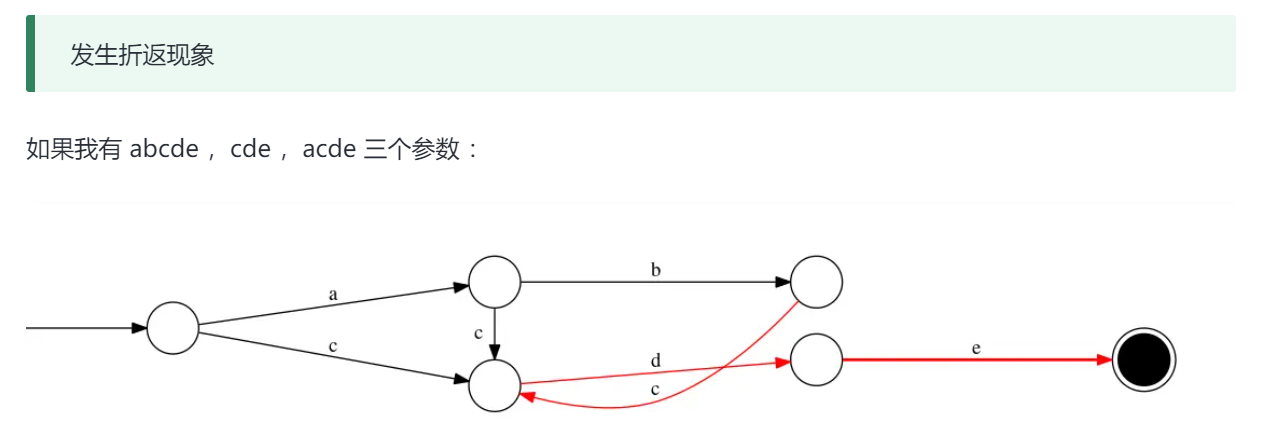
FST 全名 : (Finite State Transducer)有限状态自动机,是一种基于有限状态机的数据结构。
FST 是一个有向图 ,每个节点表示一个状态,每个节点(状态)可以有多个出边 ,每个出边都有对应的标签和权重。
在 FST 中,从根节点到任何其他节点的路径都代表一个键,并且权重表示该键的相关度或分值。
```流程
// S1 : 构建 FST 结构
当数据开始逐渐生成后,通过分词器按照不同的方式进行分词,在把所有的词项构建成 FST
// S2 : 查询的转换
当用户进行查询时,会将查询词按照分词器的逻辑进行分词,然后按照分词结果转换为查询状态序列
// S3 : 查找匹配的状态转换序列
使用深度优先搜索或广度优先搜索算法在有限状态自动机中查询匹配的状态序列,匹配上则可以找到一个对应的词项
// S4 : 通过词项获取
在 FST 中找到了一个匹配的词项,就可以返回该词项的相关信息,比如文档 ID、权重等
Elasticsearch 还可以通过自定义 FST 来实现特定的分词器和词库,在不同的场景中加快了查询的速度,提高效率。
- 优化
数据压缩 :FST 的特性决定了他的数据结构是紧凑的,按照之前看到的一篇文章的数据 :10TB 磁盘数据量,其对应的 FST 内存占用量在 10GB ~ 15GB 左右
可定制规则 : FST 的分词和自动化处理的算法都是可以定制和精简的,可以根据情况和优化对处理效率进行提高
可用复杂的算法 :深度优先搜索、广度优先搜索、剪枝等都可用提高了处理速度
并行处理 :可以通过并行计算和分布式处理等技术,将大规模的数据处理分成多个任务,提高处理效率和并发性
-
优化分片的刷新:
持久化:fsync:一次完整的提交会将段刷到磁盘,并希尔所有段列表的提交点
增加transation_logL事物日志:
段满了就会合并
-
新文档写入:词条分析->建立倒排索引-> 过滤格式 ->分词器分词 -> Token过滤 ->建立倒排索引
ES提高查询精度
-
routing查询
不带routing 查询在查询的时候因为不知道要查询的数据具体在哪个分片上,所以整个过程分为2 个步骤1)分发:请求到达协调节点后,协调节点将查询请求分发到每个分片上。2)聚合: 协调节点搜集到每个分片上查询结果,在将查询的结果进行排序,之后给用户返回结果。带routing 查询查询的时候,可以直接根据routing 信息定位到某个分配查询,不需要查询所有的分配,经过协调节点排序。向上面自定义的用户查询,如果routing 设置为userid 的话,就可以直接查询出数据来,效率提升很多。-
ES的四大查询方式:
- term和terms精确查询
- math_phrase查询,短语查询,按顺序,且有偏移量的配置
- bool查询,组合must和should和mostnot等多个查询条件
- match:
"match": {
"content": {
"query": "架构师尼恩",
"operator": "and"
}
operator为and时是:要求文档必须包含查询词分词后的所有词
boost权重值:boost只能在都和多个math字段查询中可使得有权重的
{
"query": {
"match": {
"title": {
"query": "架构师尼恩",
"boost": 2
},
"content": "人工智能应用"
}
}
}
效率 terms>match>match_phrase 因为短语匹配要考虑顺序
查询时的小tips:
提高在多字段查询的权重值,
"multi_match": {
"query": "手机",
"fields": [
"product_title^3",
"brand^2",
"description"
]
}
MultiMatchQueryBuilder multiMatchQuery = QueryBuilders.multiMatchQuery("手机")
.field("product_title", 3.0f)
.field("brand", 2.0f)
.field("description");
fuzziness:运行输入的拼写出错
// 构建 fuzzy 查询:允许 "aplle" 匹配 "apple"
FuzzyQueryBuilder fuzzyQuery = QueryBuilders
.fuzzyQuery("product_name", "aplle")
.fuzziness("1"); // 1表示最多允许1个字符错误
-
索引层面:
分词器的选择:Ik_smart(ik_max_word:尽量拆分成精细范围,覆盖多种组合)和whitespace和standard和结巴分词
实际使用时使用ik_smart因为粗粒度过滤的内容多,
-
自定义词库
编辑 IK 的自定义词库文件(默认路径)
在 config/analysis-ik 目录下:
IKAnalyzer.cfg.xml ➜ 加入自定义词库文件名
custom.dic ➜ 添加你自己的词汇
例如,在 custom.dic 里添加:
txt
复制
编辑
华为P60
荣耀Magic6
王者荣耀
ChatGPT
然后在 IKAnalyzer.cfg.xml 中添加:
xml
复制
编辑
<entry key="ext_dict">custom.dic</entry>
-
自定义停用词
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<entry key="ext_stopwords">my_stopwords.dic</entry>
</properties>
这里 my_stopwords.dic 是一个自定义的停用词文件。-
数据格式规范:日期和keyword的选择,text和keyword支持
-
explain分析查询和查询得分率
-
funtion_socre:对热门文章调整得分
-
comfortbleFuture的使用
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import java.io.IOException;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ElasticsearchQueryExample {
public static void main(String[] args) {
// 创建一个 Elasticsearch 客户端,这里假设你已经正确配置了 RestHighLevelClient
RestHighLevelClient esClient = createEsClient();
// 创建一个线程池,用于 CompletableFuture 的异步执行
ExecutorService executorService = Executors.newFixedThreadPool(2);
try {
// 构建 term 查询
SearchRequest termSearchRequest = new SearchRequest("your_index_name");
SearchSourceBuilder termSearchSourceBuilder = new SearchSourceBuilder();
termSearchSourceBuilder.query(QueryBuilders.termQuery("product_id", "P001"));
termSearchRequest.source(termSearchSourceBuilder);
// 构建 match 查询
SearchRequest matchSearchRequest = new SearchRequest("your_index_name");
SearchSourceBuilder matchSearchSourceBuilder = new SearchSourceBuilder();
matchSearchSourceBuilder.query(QueryBuilders.matchQuery("product_name", "手机"));
matchSearchRequest.source(matchSearchSourceBuilder);
// 使用 CompletableFuture 并行执行两个查询
CompletableFuture<SearchResponse> termFuture = CompletableFuture.supplyAsync(() -> {
try {
return esClient.search(termSearchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}, executorService);
CompletableFuture<SearchResponse> matchFuture = CompletableFuture.supplyAsync(() -> {
try {
return esClient.search(matchSearchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}, executorService);
// 合并两个查询的结果
CompletableFuture.allOf(termFuture, matchFuture).thenRun(() -> {
try {
SearchResponse termResponse = termFuture.get();
SearchResponse matchResponse = matchFuture.get();
// 在这里可以处理和合并两个查询的结果
// 例如,将两个响应中的 hits 合并
// 以下是简单的打印结果示例,实际应用中可以进行更复杂的处理
System.out.println("Term Query Results:");
System.out.println(termResponse);
System.out.println("Match Query Results:");
System.out.println(matchResponse);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}).join();
} finally {
try {
esClient.close();
} catch (IOException e) {
e.printStackTrace();
}
executorService.shutdown();
}
}
private static RestHighLevelClient createEsClient() {
// 这里应该根据你的 Elasticsearch 集群配置来创建 RestHighLevelClient
// 以下是一个简单的示例,实际使用时请根据实际情况修改
// return new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));
return null; // 你需要根据实际情况完成这个方法
}
}ES集群数据的同步方案
-
数据会同步到副本中
-
最新新增的数据通过段来存储,且逻辑标记删除使得可以实时访问数据
-
Flush和fsync会磁盘写保证数据的持久化和高可用


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









