






六大设计原则
第一剑、单一职责原则
面向对象三大特性之一的 封装 指的就是将单一事物抽象出来组合成一个类,所以我们在设计类的时候每个类中处理的是单一事物而不是某些事物的集合。
设计模式中所谓的 单一职责原则(Single Responsibility Principle - SRP),就是对一个类而言,应该仅有一个引起它变化的原因,其实就是将这个类所承担的职责单一化。如果一个类承担的职责过多,就等于把这些职责耦合到了一起,一个职责的变化可能会削弱或者抑制这个类完成其他职责的能力。这种耦合会导致设计变得脆弱,当变化发生时,设计会遭受到意想不到的破坏。
应该有且仅有一个原因引起类的变更,一个类或者模块只负责完成一个职责
解释:不要设计大而全的类,要设计粒度更小,单一功能的类。即假设一个类中既包含了用户的一些操作,又包含了设置的一些操作,那么就需要将这个类拆分成几个更小,功能更单一、粒度更细的类。
单一职责原则的好处:
- 类的复杂性降低,实现什么职责都有清晰明确的定义
- 可读性提高,复杂性降低
- 可维护性提高,可读性提高
- 变更引起的风险降低
在软件设计中,要如何用好单一职责原则也是一个难题,因为遵循这一原则最关键的地方在于职责的划分,而职责的划分是根据需求定的,需要设计人员发现类的不同职责并将其分离,再封装到不同的类或模块中。同一个类(接口)的设计,在不同的需求里面,可能职责的划分并不一样。而发现类的多重职责需要设计人员具有较强的分析设计能力和相关重构经验。
示例:
在一个社交媒体产品中,我们使用UserInfo去记录用户的信息,包括如下的属性

Q:UserInfo类有没有遵守单一职责原则?
A1:遵守了单一职责原则,因为其中包括都是跟用户相关的个人信息的内容。
A2:没遵守单一职责原则,因为没有把地址相关的信息单独拿出来。
正确答案:
根据实际业务选择是否应该拆分。
- 该社交产品的用户信息只是用来展示的,那么这个类这样设计就没有问题
- 假设后面这个社交产品又添加了电商模块, 那就需要将地址信息提取出来,单独设计一个类

注意:单一职责同样也适用于方法。一个方法应该尽可能做好一件事情。如果一个方法处理的事情太多,其颗粒度会变得很粗,不利于重用
不同的应用场景、不同阶段的需求背景下,对同一个类的职责是否单一的判定,可能都是不一样的,最好的方式就是我们可以先写一个粗粒度的类,满足业务需求。随着业务的发展,如果粗粒度的类越来越庞大,代码越来越多,这个时候,我们就可以将这个粗粒度的类,拆分成几个更细粒度的类。这就是所谓的持续重构
软件设计真正要做的事情就是,发现根据需求发现职责,并把这些职责进行分离,添加新的类,给当前类减负,越是这样项目才越容易维护。杜绝万能类或万能函数!!!
第二剑、开放封闭原则
开放 – 封闭原则 (Open/Closed Principle - OCP) 说的是软件实体(类、模块、函数等)可以扩展,但是不可以修改。也就是说对于扩展是开放的,对于修改是封闭的。开闭原则是面向对象程序设计的终极目标,它使软件实体拥有一定的适应性和灵活性的同时具备稳定性和延续性具体来说,其作用如下。
1. 对软件测试的影响:软件遵守开闭原则的话,软件测试时只需要对扩展的代码进行测试就可以了,因为原有的测试代码仍然能够正常运行。
2. 可以提高代码的可复用性:粒度越小,被复用的可能性就越大;在面向对象的程序设计中,根据原子和抽象编程可以提高代码的可复用性。
3. 可以提高软件的可维护性:遵守开闭原则的软件,其稳定性高和延续性强,从而易于扩展和维护。
解释:
对拓展开放和对修改关闭表示当一个类或一个方法有新需求发生改变时应该采用拓展的方式而不应该采用修改原有逻辑的方式来实现。因为拓展了新的逻辑如果有问题只会影响新的业务,不会影响老业务;而如果采用修改的方式,很有可能就会使老业务受影响。
开闭原则是所有设计模式的最核心目标,也是最难实现的目标,但是所有的软件设计模式都应该以开闭原则当作标准,才能使软件更加的稳定和健壮。
优点:
1. 新老逻辑解耦,需求发生改变不会影响老业务的逻辑
2. 改动成本最小,只需要追加新逻辑,不需要改动老逻辑
3. 提供代码的稳定性和可扩展性
//1.定义一个形状接口,它声明了所有形状共有的方法:
interface Shape {
draw(): void;
}
//2.创建几个具体的形状类,它们实现了Shape接口:
class Circle implements Shape {
draw() {
console.log('Drawing a circle.');
}
}
class Square implements Shape {
draw() {
console.log('Drawing a square.');
}
}
//3.定义一个Canvas类,它接受一个Shape数组并遍历它们来绘制:
class Canvas {
constructor(private shapes: Shape[]) {}
drawAll() {
this.shapes.forEach(shape => shape.draw());
}
}
//4.客户端代码可以创建Canvas实例,并向其中添加任意数量的形状:
const canvas = new Canvas([new Circle(), new Square()]);
canvas.drawAll();
如果我们想要添加新的形状类型,只需创建一个新的类,实现Shape接口即可,而无需修改Canvas类或现有的形状类。这样,我们的系统就遵循了开闭原则。
依赖注入
为了进一步增强系统的灵活性,我们可以使用依赖注入来提供Shape实例给Canvas。这样,Canvas不需要关心形状的具体实现,只需要知道如何使用它们:
class Canvas {
constructor(private shapeFactory: () => Shape) {}
add(shape: Shape) {
// 使用工厂方法来创建形状
this.shapes.push(this.shapeFactory());
}
drawAll() {
this.shapes.forEach(shape => shape.draw());
}
}
// 使用工厂函数来创建形状
const canvas = new Canvas(() => new Circle());
canvas.add(new Square());
canvas.drawAll();
通过这种方式,我们可以在不修改Canvas类的情况下,通过更改工厂函数来提供不同类型的形状。
-
顶层设计思维
- 抽象意识
- 封装意识
- 扩展意识
-
总结
在写代码的时候后,我们要多花点时间往前多思考一下,这段代码未来可能有哪些需求变更、如何设计代码结构,事先留好扩展点,以便在未来需求变更的时候,不需要改动代码整 体结构、做到最小代码改动的情况下,新的代码能够很灵活地插入到扩展点上,做到“对扩展开放、对修改关闭”。
第三剑、里氏替换原则
所谓的里氏替换原则就是子类类型必须能够替换掉它们的父类类型。
-
定义
- 如果对每一个类型为S的对象o1,都有类型为T的对象o2,使得以T定义的所有程序P在所有的对象o1都代换成o2时,程序P的行为没有发生变化,那么类型S是类型T的子类型。
- 只要父类能出现的地方子类就可以出现,而且替换为子类也不会产生任何错误或异常,使用者可能根本就不需要知道是父类还是子类。反过来,有子类出现的地方,父类未必就能适合。
里氏替换原则为良好的继承定义了一个规范:
1. 子类必须完全实现父类的方法(在类中调用其他类时务必要使用父类或接口,如不能,则违背LSP原则)。
2. 子类可以有自己的个性。
3. 覆盖或实现父类的方法时输入参数可以被放大(子类中方法的前置条件必须与超类中被覆写的方法的前置条件相同或者更宽松)。
4. 重写或实现父类的方法时输出结果可以被缩小。
解释:
想要理解里氏替换,首先需要理解以下两个问题:
- 什么是替换?
- 替换的前提是面向对象语言所支持的多态特性,同一个行为具有多个不同表现形式或形态的能力。
- 什么是与期望行为一致的替换?
- 在不了解派生类的情况下,仅通过接口或基类的方法,即可清楚的知道方法的行为,而不管哪种派生类的实现,都与接口或基类方法的期望行为一致。
- 不需要关心是哪个类对接口进行了实现,因为不管底层如何实现,最终的结果都会符合接口中关于方法的描述(也就是与接口中方法的期望行为一致).或者说接口或基类的方法是一种契约,使用方按照这个契约来使用,派生类也按照这个契约来实现。这就是与期望行为一致的替换。
里氏替换原则要满足的第一个条件就是继承,其次还要求子类继承的所有父类的属性和方法对于子类来说都是合理的。关于是否合理这个关键词下面将要举一个例子:
比如,对于哺乳动物来说都是胎生,但是有一种特殊的存在就是鸭嘴兽,它虽然是哺乳动物,但是是卵生。
如果我们设计了两个类:哺乳动物类 和 鸭嘴兽类,此时能够让鸭嘴兽类继承哺乳动物类吗?
- 答案肯定是否定的,因为如果我们这么做了,鸭嘴兽就继承了胎生的属性,这与它自身的情况是不匹配的。
- 如果想要遵循里氏替换原则,就不应该让这两个类有继承关系。
如果我们创建了其它的胎生的哺乳动物类,那么它们是可以继承哺乳动物这个类的,在实际应用中就可以使用子类替换掉父类,同时功能也不会受到影响,父类实现了复用,子类也能在父类的基础上增加新的行为,这个就是
里氏替换原则。
假设我们有一个图形库,其中包括一个Shape基类和两个具体的形状类:Circle和Square。Shape基类定义了一个draw方法,而Circle和Square类都提供了自己的draw实现。此外,我们还定义了一个AreaCalculator类,它可以计算任何Shape对象的面积。
//创建一个Shape基类
abstract class Shape {
abstract draw(): void;
}
//创建两个具体的形状类:Circle和Square
class Circle extends Shape {
constructor(public radius: number) {
super();
}
draw() {
console.log("Drawing a circle...");
}
calculateArea() {
return Math.PI * this.radius ** 2;
}
}
class Square extends Shape {
constructor(public sideLength: number) {
super();
}
draw() {
console.log("Drawing a square...");
}
calculateArea() {
return this.sideLength ** 2;
}
}
//定义一个AreaCalculator类,计算任何Shape对象的面积
class AreaCalculator {
calculate(shapes: Shape[]) {
shapes.forEach(shape => {
console.log(`Area of ${shape.constructor.name}: ${shape.calculateArea()}`);
});
}
}
在这个例子中,AreaCalculator类的calculate方法接受一个Shape数组作为参数。由于Circle和Square都是Shape的子类,它们可以被传递给calculate方法,而不会影响程序的正确性。这正是里氏替换原则的体现。
const shapes: Shape[] = [new Circle(5), new Square(4)];
const calculator = new AreaCalculator();
calculator.calculate(shapes);
/*
*执行代码输出为
*Area of Circle: 78.53981633974483
*Area of Square: 16
*/

里氏替换原则是为了弥补继承的缺点,总体来看是利大于弊的。里氏替换原则告诉我们,在软件中将一个基类对象替换成它的子类对象,程序将不会产生任何错误和异常,反过来则不成立,如果一个软件实体使用的是一个子类对象的话,那么它不一定能够使用基类对象。例如:我喜欢动物,那我一定喜欢狗,因为狗是动物的子类;但是我喜欢狗,不能据此断定我喜欢动物,因为我并不喜欢老鼠,虽然它也是动物。
使用里氏替换原则时需要注意如下几个问题:
- 子类的所有方法必须在父类中声明,或子类必须实现父类中声明的所有方法。根据里氏代换原则,为了保证系统的扩展性,在程序中通常使用父类来进行定义,如果一个方法只存在子类中,在父类中不提供相应的声明,则无法在以父类定义的对象中使用该方法。
- 我们在运用里氏替换原则时,尽量把父类设计为抽象类或者接口,让子类继承父类或实现父接口,并实现在父类中声明的方法,运行时,子类实例替换父类实例,我们可以很方便地扩展系统的功能,同时无须修改原有子类的代码,增加新的功能可以通过增加一个新的子类来实现。里氏替换原则是开闭原则的具体实现手段之一。
第四剑、依赖倒置原则
依赖倒置原则(Dependence Inversion Principle,DIP)是指在设计代码架构时,高层模块不应该依赖于底层模块,二者都应该依赖于抽象。抽象不应该依赖于细节,细节应该依赖于抽象。
解释:
依赖倒置原则是实现开闭原则的重要途径之一,它降低了客户与实现模块之间的耦合。
- 高层级的模块应该依赖的是低层级的模块的行为的抽象,取决于具体编程语言,可以是抽象类或者接口等技术
- 第2句话其实很简单,只有一个意思:只要依赖了实现,就是耦合了代码,所以我们需要始终依赖的是抽象,而不是实现。
关于依赖倒转原则,对应的是两条非常抽象的描述:
- 高层模块不应该依赖低层模块,两个都应该依赖抽象。
- 抽象不应该依赖细节,细节应该依赖抽象。
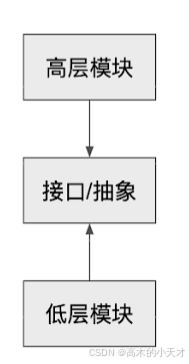
先用人话解释一下这两句话中的一些抽象概念:
- 高层模块:可以理解为上层应用,就是业务层的实现;
- 低层模块:可以理解为底层接口,比如封装好的API、动态库等;
- 抽象:指的就是抽象类或者接口
依赖倒置原则的好处:
- 减少类间的耦合性。
- 提高系统的稳定性 。 (根据类与类之间的耦合度从弱到强排列:依赖关系、关联关系、聚合关系、组合关系、泛化关系和实现关系 )
- 减少并行开发引起的风险 (两个类之间有依赖关系,只要制定出两者之间的接口(或抽象类)就可以独立开发了)
- 提高代码的可读性和可维护性
依赖倒置原则的实现方法
依赖倒置原则的目的是通过要面向接口的编程来降低类间的耦合性,所以我们在实际编程中只要遵循以下4点,就能在项目中满足这个规则。
- 每个类尽量提供接口或抽象类,或者两者都具备。
- 变量的声明类型尽量是接口或者是抽象类。
- 任何类都不应该从具体类派生。
- 使用继承时尽量遵循里氏替换原则
假设我们正在构建一个博客系统,其中需要处理文章的存储与检索。这里我们将采用依赖倒置原则设计一个简单的内容管理系统(CMS)
class DatabaseArticleRepository {
saveArticle(article: Article): void {
// 保存文章到数据库的逻辑
}
getArticleById(id: string): Article | null {
// 从数据库获取文章的逻辑
}
}
class FileArticleRepository {
saveArticle(article: Article): void {
// 保存文章到文件的逻辑
}
getArticleById(id: string): Article | null {
// 从文件系统获取文章的逻辑
}
}
class CMS {
private articleRepository: DatabaseArticleRepository; // 直接依赖于具体实现
constructor() {
this.articleRepository = new DatabaseArticleRepository(); // 创建具体实现
}
publishArticle(article: Article): void {
this.articleRepository.saveArticle(article);
}
showArticle(id: string): Article | null {
return this.articleRepository.getArticleById(id);
}
}
const cms = new CMS();
cms.publishArticle({ id: '123', title: 'My first post', content: 'Content of my first post...' });
const article = cms.showArticle('123');
console.log(article);
我们可以看到这种设计存在以下问题:
- 紧耦合:
CMS类直接依赖于DatabaseArticleRepository,如果将来需要更改存储方式(例如使用文件系统存储),则必须修改CMS类的代码,破坏了开闭原则(Open-Closed Principle,OCP)。 - 不易测试:由于
CMS类与具体实现硬绑定,很难进行单元测试,因为每次测试都需要运行完整的数据库环境。 - 难以复用:
CMS类与具体的数据库存储方式紧密耦合,限制了其在不同场景下的复用能力,比如在一个仅使用文件存储的项目中。 - 扩展困难:如果要添加新的存储方式,必须在
CMS类中添加条件判断或策略模式来区分使用哪种存储方式,这增加了复杂性和耦合度。
那么根据依赖倒置原则,可以进行如下更改:
- 抽象层:数据访问接口
首先,定义一个数据访问接口,它描述了如何保存和检索文章的基本操作:
interface ArticleRepository {
saveArticle(article: Article): void;getArticleById(id: string): Article | null;
}
- 实现层:具体的数据存储
然后,我们可以创建具体的实现,比如使用数据库存储或文件系统存储:
- 数据库存储实现
class DatabaseArticleRepository implements ArticleRepository {
saveArticle(article: Article): void {// 逻辑:将文章保存到数据库中console.log(`Saved article to database: ${article.title}`);
}
getArticleById(id: string): Article | null {// 逻辑:从数据库中读取文章return { id, title: 'Sample article', content: 'This is a sample article.' };
}
}
- 文件系统存储实现
class FileArticleRepository implements ArticleRepository {
saveArticle(article: Article): void {// 逻辑:将文章保存到文件中console.log(`Saved article to file system: ${article.title}`);
}
getArticleById(id: string): Article | null {// 逻辑:从文件系统中读取文章return { id, title: 'Sample article', content: 'This is a sample article.' };
}
}
- 应用层:CMS服务
CMS服务依赖于ArticleRepository接口,而不是具体的实现:
class CMS {
private articleRepository: ArticleRepository;
constructor(repository: ArticleRepository) {
this.articleRepository = repository;
}
publishArticle(article: Article): void {
this.articleRepository.saveArticle(article);
}
showArticle(id: string): Article | null {
return this.articleRepository.getArticleById(id);
}
}
- 客户端代码
客户端可以根据当前的需求选择使用数据库还是文件系统的存储方式:
const dbRepo = new DatabaseArticleRepository();
const cmsWithDB = new CMS(dbRepo);
cmsWithDB.publishArticle({ id: '123', title: 'Hello World', content: 'First Article' });
console.log(cmsWithDB.showArticle('123'));
const fsRepo = new FileArticleRepository();
const cmsWithFS = new CMS(fsRepo);
cmsWithFS.publishArticle({ id: '124', title: 'File System', content: 'Second Article' });
console.log(cmsWithFS.showArticle('124'));
对于开闭原则、里氏替换原则以及依赖倒置原则,三者是无法分离的,下面举一个例子:
现需要将存储在TXT或Excel文件中的客户信息转存到数据库中,因此需要进行数据格式转换。在客户数据操作类中将调用数据格式转换类的方法实现格式转换和数据库插入操作,初始设计方案结构如图所示:
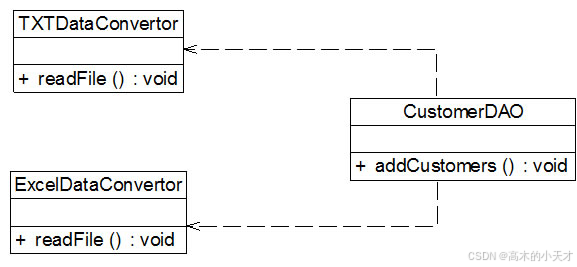
在编码实现图所示结构时,Sunny软件公司开发人员发现该设计方案存在一个非常严重的问题,由于每次转换数据时数据来源不一定相同,因此需要更换数据转换类,如有时候需要将TXTDataConvertor改为ExcelDataConvertor,此时,需要修改CustomerDAO的源代码,而且在引入并使用新的数据转换类时也不得不修改CustomerDAO的源代码,系统扩展性较差,违反了开闭原则,现需要对该方案进行重构。
在本实例中,由于CustomerDAO针对具体数据转换类编程,因此在增加新的数据转换类或者更换数据转换类时都不得不修改CustomerDAO的源代码。我们可以通过引入抽象数据转换类解决该问题,在引入抽象数据转换类DataConvertor之后,CustomerDAO针对抽象类DataConvertor编程,而将具体数据转换类名存储在配置文件中,符合依赖倒转原则。根据里氏代换原则,程序运行时,具体数据转换类对象将替换DataConvertor类型的对象,程序不会出现任何问题。更换具体数据转换类时无须修改源代码,只需要修改配置文件;如果需要增加新的具体数据转换类,只要将新增数据转换类作为DataConvertor的子类并修改配置文件即可,原有代码无须做任何修改,满足开闭原则。重构后的结构如图所示:
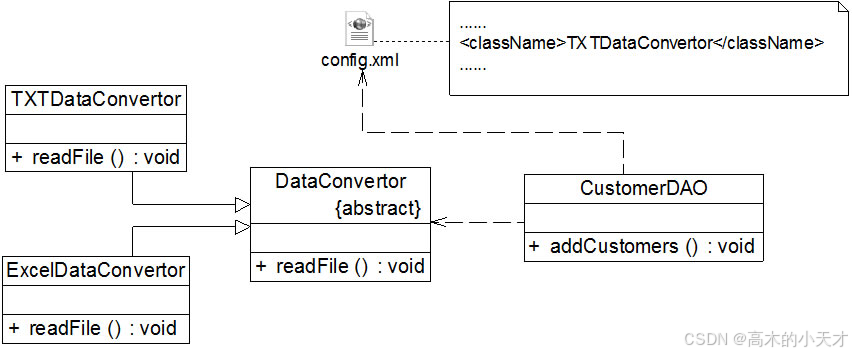
在大多数情况下,这三个设计原则会同时出现,开闭原则是目标,里氏替换原则是基础,依赖倒转原则是手段,它们相辅相成,相互补充,目标一致,只是分析问题时所站角度不同而已。
第五剑、接口隔离原则
使用多个专门的接口,而不使用单一的总接口,即客户端不应该依赖那些它不需要的接口。
该原则还有另外一个定义:一个类对另一个类的依赖应该建立在最小的接口上
解释:
要为各个类建立它们需要的专用接口,而不要试图去建立一个很庞大的接口供所有依赖它的类去调用。它还有另外一个意思是:降低类之间的耦合度。由此可见,其实设计模式就是从大型软件架构出发、便于升级和维护的软件设计思想,它强调降低依赖,降低耦合。
接口隔离原则与单一职责原则的区别
接口隔离原则和单一职责都是为了提高类的内聚性、降低它们之间的耦合性,体现了封装的思想,但两者是不同的:
- 单一职责原则注重的是职责,而接口隔离原则注重的是对接口依赖的隔离。
- 单一职责原则主要是约束类,它针对的是程序中的实现和细节;接口隔离原则主要约束接口,主要针对抽象和程序整体框架的构建。
接口隔离原则的实现方法
在具体应用接口隔离原则时,应该根据以下几个规则来衡量。
- 接口尽量小,但是要有限度。一个接口只服务于一个子模块或业务逻辑。
- 为依赖接口的类定制服务。只提供调用者需要的方法,屏蔽不需要的方法。
- 了解环境,拒绝盲从。每个项目或产品都有选定的环境因素,环境不同,接口拆分的标准就不同深入了解业务逻辑。
- 提高内聚,减少对外交互。使接口用最少的方法去完成最多的事情。
接下来举个实例来加深对接口隔离原则的印象:
假设有这样一个场景:一个系统中需要处理不同类型的设备,如打印机、扫描仪和多动能一体机(同时具备打印、扫描功能)。在最初的设计中,我们可能会创建一个大型接口来管理所有设备的通用操作。
原始设计(未隔离)
interface Device {
print(document: string): void;
scan(document: string): void;
turnOn(): void;
turnOff(): void;
}
在这种情况下,无论设备是否支持所有的功能,都需要实现这些方法。例如,一个只用于打印的设备也需要实现scan方法,尽管它实际上无法执行扫描功能。
应用接口隔离原则
为了改进这个设计,我们可以将Device接口分解为更具体的接口,每个接口只包含一组相关的方法:
interface Printer {
print(document: string): void;
turnOn(): void;
turnOff(): void;
}
interface Scanner {
scan(document: string): void;
turnOn(): void;
turnOff(): void;
}
// 用于多功能设备interface MultiFunctionDevice extends Printer, Scanner {}
如此一来,Printer接口只关心打印相关的操作,而Scanner接口则专注于扫描任务。MultiFunctionDevice则通过组合Printer和Scanner接口,拥有了所有必要的功能,无需实现任何额外的、无关的方法。
类的实现
接下来,我们可以很容易地为每种设备类型创建对应的类:
class PrinterOnly implements Printer {
print(document: string) { /* 实现打印逻辑 */
}
turnOn() { /* 实现开启逻辑 */
}
turnOff() { /* 实现关闭逻辑 */
}
}
class ScannerOnly implements Scanner {
scan(document: string) { /* 实现扫描逻辑 */
}
turnOn() { /* 实现开启逻辑 */
}
turnOff() { /* 实现关闭逻辑 */
}
}
class MultiFunctionDevice implements MultiFunctionDevice {// 实现所有来自Printer和Scanner的方法
}
通过这样的设计,每个类都只实现了它真正需要的方法,不仅减少了代码冗余,也使得系统更加灵活和易维护。这就是接口隔离原则带来的好处。
接口隔离原则的优点:
- 将臃肿庞大的接口分解为多个粒度小的接口,可以预防外来变更的扩散,提高系统的灵活性和可维护性。
- 接口隔离提高了系统的内聚性,减少了对外交互,降低了系统的耦合性。
- 如果接口的粒度大小定义合理,能够保证系统的稳定性;但是,如果定义过小,则会造成接口数量过多,使设计复杂化;如果定义太大,灵活性降低,无法提供定制服务,给整体项目带来无法预料的风险。
- 使用多个专门的接口还能够体现对象的层次,因为可以通过接口的继承,实现对总接口的定义。
- 能减少项目工程中的代码冗余。过大的大接口里面通常放置许多不用的方法,当实现这个接口的时候,被迫设计冗余的代码。
在使用接口隔离原则时,我们需要注意控制接口的粒度,接口不能太小,如果太小会导致系统中接口泛滥,不利于维护;接口也不能太大,太大的接口将违背接口隔离原则,灵活性较差,使用起来很不方便。一般而言,接口中仅包含为某一类用户定制的方法即可,不应该强迫客户依赖于那些它们不用的方法。
第六剑、迪米特法则
迪米特法则(LoD:Law of Demeter)又叫最少知识原则(LKP:Least Knowledge Principle ),指的是一个类/模块对其他的类/模块有越少的了解越好。
解释:
简单来说迪米特法则想要表达的思想就是: 不该有直接依赖关系的类之间,不要有依赖;有依赖关系的类之间,尽量只依赖必要的接口。
如果两个软件实体无须直接通信,那么就不应当发生直接的相互调用,可以通过第三方转发该调用。其目的是降低类之间的耦合度,提高模块的相对独立性。
迪米特法则还有个更简单的定义:只与直接的朋友通信。
直接的朋友:每个对象都会与其他对象有耦合关系,只要两个对象之间有耦合关系, 我们就说这两个对象之间是朋友关系。耦合的方式很多,依赖,关联,组合,聚合 等。其中,我们称出现成员变量,方法参数,方法返回值中的类为直接的朋友,而 出现在局部变量中的类不是直接的朋友。也就是说,陌生的类最好不要以局部变量 的形式出现在类的内部。
迪米特法则的实现方法
从迪米特法则的定义和特点可知,它强调以下两点:
- 从依赖者的角度来说,只依赖应该依赖的对象。
- 从被依赖者的角度说,只暴露应该暴露的方法。
所以,在运用迪米特法则时要注意以下 6 点:
- 在类的划分上,应该创建弱耦合的类。类与类之间的耦合越弱,就越有利于实现可复用的目标。
- 在类结构设计上,尽量降低类成员的访问权限。
- 在类的设计上,优先考虑将一个类设置成不变类
- 在对其他类的引用上,将引用其他对象的次数降到最低。
- 不暴露类的属性成员,而应该提供相应的访问器(set 和 get 方法)。
- 谨慎使用序列化(Serializable)功能。
实例
假设有一个简单的图书管理系统,包含Library(图书馆)、Book(书籍)和Patron(读者)三个类。
使用迪米特法则前
class Book {
checkAvailability() {
return true;
}
}
class Patron {
borrow(book: Book): boolean {
if (book.checkAvailability()) {
console.log('Book borrowed');
return true;
}return false;
}
}
class Library {
books: Book[];
constructor() {
this.books = [new Book()];
}
findBook(title: string): Book | undefined {
return this.books.find(book => book.title === title);
}
}
// 使用const library = new Library();
const patron = new Patron();
const book = library.findBook('The Great Gatsby');
patron.borrow(book!); // 这里!是断言操作符,保证类型正确
在这个例子中,Patron直接调用了Book的checkAvailability方法。同时,Patron通过Library获取Book实例。
使用迪米特法则后
class Book {
constructor(public available: boolean) {}
}
class Patron {
borrow(book: Book, library: Library): boolean {
const availableCopy = library.checkOutBook(book);
if (availableCopy) {
console.log('Book borrowed');
return true;
}return false;
}
}
class Library {
books: Book= [];
constructor() {
this.books.push(new Book(true));
}
checkOutBook(book: Book): Book | undefined {
for (let i = 0; i < this.books.length; i++) {
if (this.books[i] === book && this.books[i].available) {
this.books[i].available = false;
return this.books[i];
}
}return undefined;
}
}
// 使用const library = new Library();
const patron = new Patron();
const book = new Book(true);
patron.borrow(book, library);
在这个修改后的版本中,Patron不再直接与Book通信,而是通过Library这个“朋友”来借书。Library检查书籍是否可用,并管理借阅流程。
使用迪米特法则的好处
- 降低耦合:Patron不再直接依赖Book,而是通过Library间接沟通。
- 提高模块独立性:Patron、Book和Library各自关注自己的职责,没有多余的交叉。
- 易于维护和扩展:若要改变借书流程,只需修改Library即可,不会影响到Patron和其他相关类。
迪米特法则的优点
迪米特法则要求限制软件实体之间通信的宽度和深度,正确使用迪米特法则将有以下两个优点。
- 降低了类之间的耦合度,提高了模块的相对独立性。
- 由于亲合度降低,从而提高了类的可复用率和系统的扩展性。
但是,过度使用迪米特法则会使系统产生大量的中介类,从而增加系统的复杂性,使模块之间的通信效率降低。所以,在釆用迪米特法则时需要反复权衡,确保高内聚和低耦合的同时,保证系统的结构清晰
七、总结
设计原则就是我们要使用到的更加具体的对于代码进行评判的标准,比如, 我们说这段代码的可扩展性比较差,主要原因是违背了开闭原则。
我们所学习的设计原则它包含了:
- 单一职责原则(SRP):实现类要职责单一
- 开闭原则(OCP):要对扩展开放,对修改关闭
- 里氏替换原则(LSP):不要破坏继承体系
- 接口隔离原则(ISP):在设计接口的时候要精简单一
- 依赖倒置原则(DIP):要面向接口编程
- 迪米特法则 (LKP):要降低耦合
这里我们需要重点关注三个常用的原则:
- 单一职责原则
单一职责原则是类职责划分的重要参考依据,是保证代码”高内聚“的有效手段,是我们在进行面向对象设计时的主要指导原则。
单一职责原则的难点在于,对代码职责是否足够单一的判定。这要根据具体的场景来具体分析。同一个类的设计,在不同的场景下,对职责是否单一的判定,可能是不同的。
- 开闭原则
开闭原则是保证代码可扩展性的重要指导原则,是对代码扩展性的具体解读。很多设计模式诞生的初衷都是为了提高代码的扩展性,都是以满足开闭原则为设计目的的。
开闭原则是所有设计模式的最核心目标,也是最难实现的目标,但是所有的软件设计模式都应该以开闭原则当作标准,才能使软件更加的稳定和健壮。
- 依赖倒置原则
依赖倒置原则主要用来指导框架层面的设计。高层模块不依赖低层模块,它们共同依赖同一个抽象。
要反复权衡,确保高内聚和低耦合的同时,保证系统的结构清晰


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









