






逻辑回归
逻辑回归
逻辑回归是机器学习中最基础的分类算法之一,它通过Sigmoid函数将线性回归结果映射为0-1之间的概率值,适用于二分类问题(如垃圾邮件识别、疾病预测等)。本文将先深入解析逻辑回归的核心原理,再结合实际数据集用Python代码演示完整实现流程,全程干货,新手也能轻松上手!
一、逻辑回归核心原理
逻辑回归虽名为“回归”,实则是基于线性回归的概率型分类算法,其核心思想可拆解为以下4步:
1. 线性组合:构建特征与标签的关联
假设我们有一个二分类问题(标签y∈{0,1}),样本有n个特征(x₁, x₂, …, xₙ)。逻辑回归首先通过线性组合建立特征与标签的关系:
z
=
θ
0
+
θ
1
x
1
+
θ
2
x
2
+
⋯
+
θ
n
x
n
=
θ
T
x
z = \theta_0 + \theta_1x_1 + \theta_2x_2 + \dots + \theta_nx_n = \boldsymbol{\theta}^T\mathbf{x}
z=θ0+θ1x1+θ2x2+⋯+θnxn=θTx
- θ:模型参数(包括截距θ₀和特征权重θ₁-θₙ),需通过训练学习得到。
- z:线性回归的结果,取值范围为(-∞, +∞),但分类问题需要概率值(0-1之间),因此需要进一步处理。
2. Sigmoid函数:将线性结果转换为概率
通过Sigmoid函数(又称逻辑函数)将线性组合z映射为概率值,公式为:
h
θ
(
x
)
=
1
1
+
e
−
z
=
1
1
+
e
−
θ
T
x
h_\theta(\mathbf{x}) = \frac{1}{1 + e^{-z}} = \frac{1}{1 + e^{-\boldsymbol{\theta}^T\mathbf{x}}}
hθ(x)=1+e−z1=1+e−θTx1
- 函数特性:
-
图像呈“S型”,当z→+∞时,hθ(x)→1;当z→-∞时,hθ(x)→0。
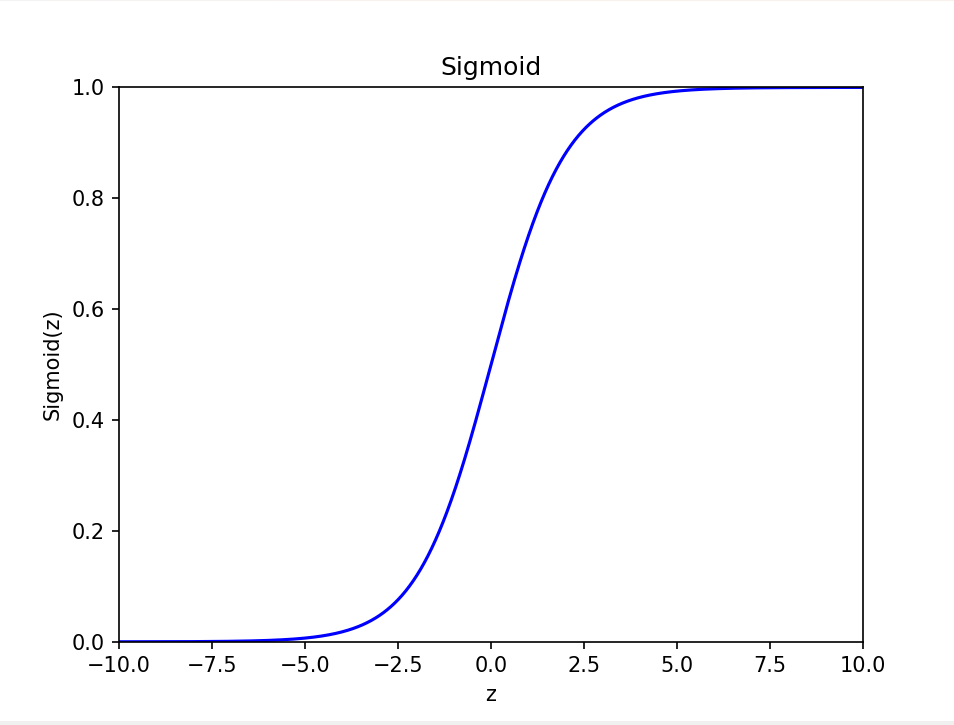
-
导数为:hθ(x)(1 - hθ(x)),后续梯度下降计算会用到。
-
- 概率意义:hθ(x)表示样本x属于正类(y=1)的概率,即:
P ( y = 1 ∣ x ; θ ) = h θ ( x ) , P ( y = 0 ∣ x ; θ ) = 1 − h θ ( x ) P(y=1|\mathbf{x};\theta) = h_\theta(\mathbf{x}), \quad P(y=0|\mathbf{x};\theta) = 1 - h_\theta(\mathbf{x}) P(y=1∣x;θ)=hθ(x),P(y=0∣x;θ)=1−hθ(x)
3. 决策边界:用概率划分类别
通过设定阈值(通常为0.5)将概率转化为类别预测:
- 若hθ(x) ≥ 0.5,预测y=1(正类);
- 若hθ(x) < 0.5,预测y=0(负类)。
此时,决策边界由线性方程θᵀx = 0决定:
- 二维数据中,决策边界是一条直线;
- 高维数据中,决策边界是一个超平面。
4. 损失函数与优化:让模型学会“纠错”
训练模型的目标是让预测概率与真实标签尽可能接近,因此需要定义损失函数衡量预测误差。逻辑回归采用交叉熵损失函数(对数损失),公式为:
单个样本损失:
L ( y , y ^ ) = { − log ( y ^ ) 当 y = 1 − log ( 1 − y ^ ) 当 y = 0 = − y log ( y ^ ) − ( 1 − y ) log ( 1 − y ^ ) L(y, \hat{y}) = \begin{cases} -\log(\hat{y}) & \text{当 } y=1 \\ -\log(1-\hat{y}) & \text{当 } y=0 \end{cases} = -y\log(\hat{y}) - (1-y)\log(1-\hat{y}) L(y,y^)={−log(y^)−log(1−y^)当 y=1当 y=0=−ylog(y^)−(1−y)log(1−y^)
- 直观理解:若真实标签y=1,预测概率ˆy越接近1,损失越小;若y=0,ˆy越接近0,损失越小。
整体损失(成本函数):
J ( θ ) = 1 m ∑ i = 1 m [ − y ( i ) log ( h θ ( x ( i ) ) ) − ( 1 − y ( i ) ) log ( 1 − h θ ( x ( i ) ) ) ] J(\theta) = \frac{1}{m}\sum_{i=1}^m \left[ -y^{(i)}\log(h_\theta(\mathbf{x}^{(i)})) - (1-y^{(i)})\log(1-h_\theta(\mathbf{x}^{(i)})) \right] J(θ)=m1i=1∑m[−y(i)log(hθ(x(i)))−(1−y(i))log(1−hθ(x(i)))]
- 优化目标:最小化J(θ),常用算法为梯度下降法,通过迭代更新参数:
θ j : = θ j − α ∂ J ( θ ) ∂ θ j \theta_j := \theta_j - \alpha \frac{\partial J(\theta)}{\partial \theta_j} θj:=θj−α∂θj∂J(θ)
其中α为学习率,梯度的计算可通过链式法则推导得到简洁形式(此处省略推导,感兴趣可查阅机器学习教材)。
二、数据集介绍
我们使用的数据集为testSet.txt,包含100条样本,每条样本有2个特征(x1、x2)和1个二分类标签(y,0或1)。数据格式如下:
-0.017612 14.053064 0
-1.395634 4.662541 1
...
任务目标:通过特征x1和x2训练模型,预测样本标签y。
三、代码实现步骤(基于原理的实践)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
data = np.loadtxt('testSet.txt', delimiter='\t')
X = data[:, :-1]
y = data[:, -1].astype(int)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
model = LogisticRegression()
model.fit(X_train, y_train)
print("模型参数θ:")
print(f"截距项 θ0: {model.intercept_[0]:.4f}")
print(f"系数 θ1: {model.coef_[0][0]:.4f}, θ2: {model.coef_[0][1]:.4f}")
y_pred_train = model.predict(X_train)
y_pred_test = model.predict(X_test)
print("\n训练集准确率:", accuracy_score(y_train, y_pred_train))
print("测试集准确率:", accuracy_score(y_test, y_pred_test))
print("\n分类报告:\n", classification_report(y_test, y_pred_test))
plt.figure(figsize=(10, 6))
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 500),
np.linspace(y_min, y_max, 500))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3, cmap=plt.cm.Paired)
plt.scatter(X[y==0, 0], X[y==0, 1], color='red', marker='o', edgecolor='k', label='Class 0')
plt.scatter(X[y==1, 0], X[y==1, 1], color='blue', marker='x', linewidth=1, label='Class 1')
theta = np.append(model.intercept_, model.coef_).flatten()
equation = f"{theta[0]:.2f} + {theta[1]:.2f}x₁ + {theta[2]:.2f}x₂ = 0"
plt.text(0.05, 0.95, equation, transform=plt.gca().transAxes,
fontsize=12, verticalalignment='top')
plt.xlabel('Feature 1 (x₁)', fontsize=12)
plt.ylabel('Feature 2 (x₂)', fontsize=12)
plt.title('Logistic Regression Decision Boundary', fontsize=14)
plt.legend(loc='upper right')
plt.grid(alpha=0.3)
plt.tight_layout()
plt.show()
运行截图:
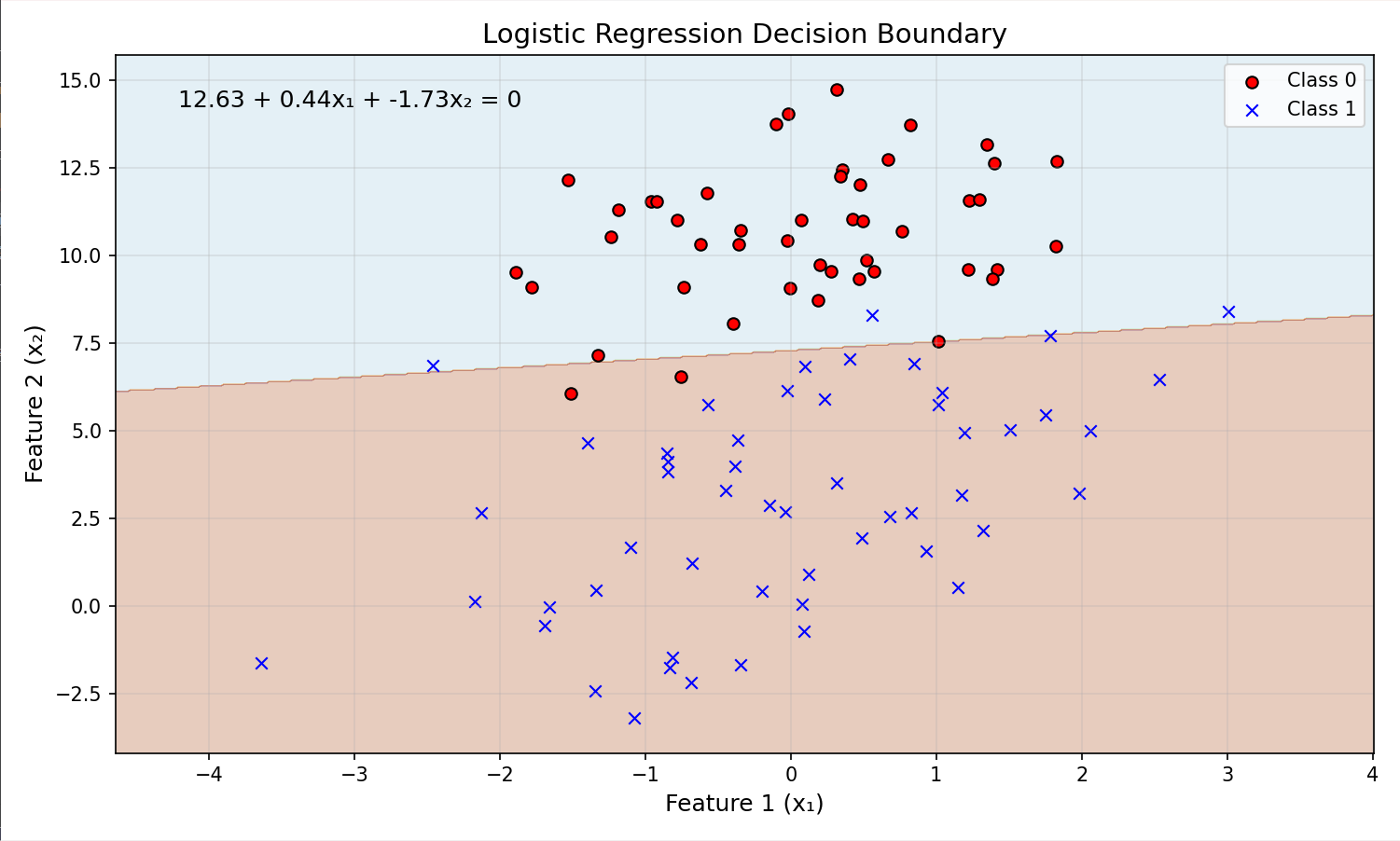
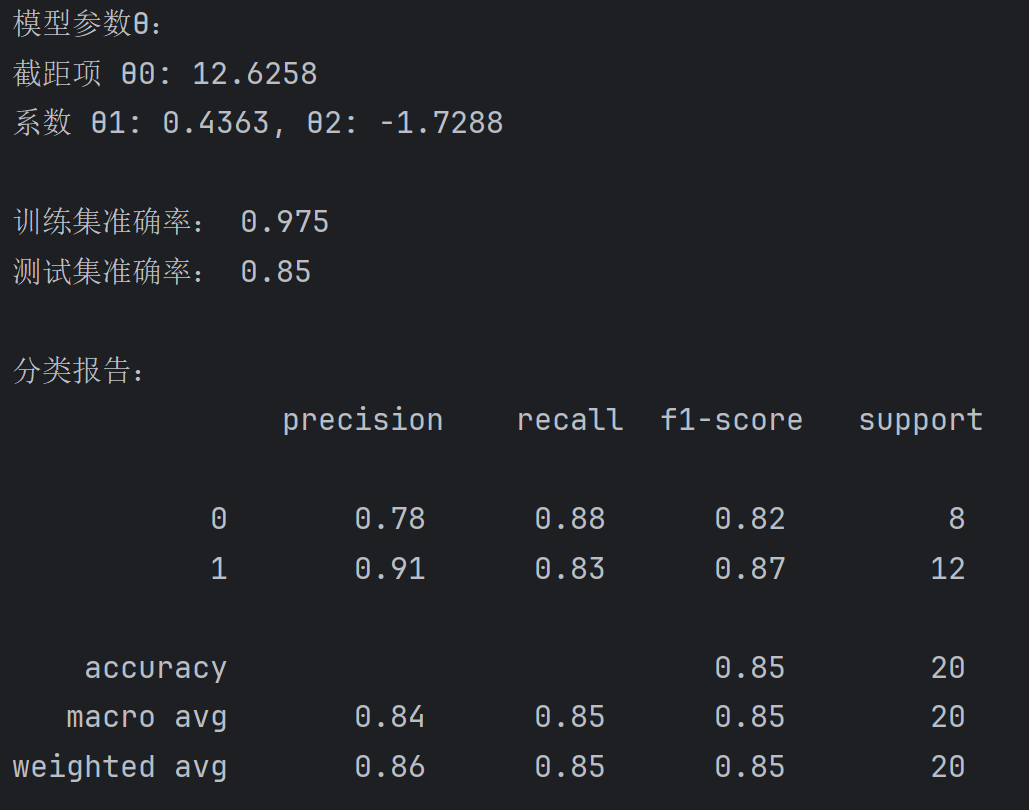
四、总结
逻辑回归通过线性组合 + Sigmoid 函数将线性回归转化为概率分类,结合交叉熵损失和梯度下降实现模型优化。其优势在于:
- 可解释性强:参数直接反映特征的影响方向和重要性;
- 效率高效:适合大规模数据,常作为分类任务的基线模型;
- 扩展性好:可通过特征工程(如多项式特征)处理非线性问题。
通过理论与实战结合,我们既能理解算法本质,又能快速应用于实际场景。后续可进一步探索逻辑回归在多分类、不平衡数据中的优化策略。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









