







会返回如下结果:
index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,subquery_materialization_cost_based=on,use_index_extensions=on
其中:index_condition_pushdown这个参数就是是否开启索引下推优化的,on表示开启,off表示关闭。
可以通过如下语句设置:
SET optimizer_switch='index\_condition\_pushdown=off';
Multi-Range Read(MRR)
Multi-Range Read和Index Condition Pushdown一样,也是在MySQL5.6版本之后引进的优化措施。MRR优化的目的是为了减少磁盘的随机IO访问,并且将随机访问转化为顺序的数据访问,所以MRR优化措施对IO-bound型的SQL查询语句可能带来极大的性能提升。
和ICP一样,也是通过【optimizer_switch】变量查询,找到返回结果中的下面两个参数:
mrr=on
mrr_cost_based=on
mrr=on表示启用,mrr_cost_based 表示是否通过基于开销的方式来启用MRR,如果mrr_cost_based=on,则即使满足了使用MRR的条件,优化器也会视当前查询的开销来决定是否使用MRR,如果我们想总是开启MRR,则可以将mrr设置为on,mrr_cost_based设置为off,如下:
SET optimizer_switch='mrr=off,mrr\_cost\_based=off';
MRR的工作方式
1、将查询得到的辅助索引键值存放于缓存之中,注意,这时候缓存中的数据是根据辅助索引的键值排序的。
2、将缓存中的数据根据row ID(主键)进行重排序。
3、然后再根据row ID(主键)的顺序去访问。
注意2,3中的row ID,《MySQL技术内幕 InnoDB存储引擎》一书中写的是RowID,我不太清楚作者当时想表达的是按照主键,还是MySQL隐藏列ROWID进行排序,但我个人认为如果写成主键会更容易理解,因为如果我们自己创表的时候显示的指定了主键,而且排序和ROWID不一致,那么就应该是按照我们的主键进行排序,否则就达不到实现顺序IO访问的结果,下面附上MySQL官网原文:
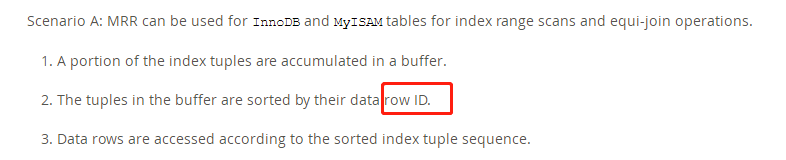
可以看到,官网用的是两个单词:row ID,也就是行id,个人认为是可以直接理解成主键的意思,而并不单单指的是MySQL隐藏列ROWID。这里如果我理解错了,欢迎给我留言或者私信。
我们想一想,如果我们通过辅助索引查找到了辅助索引的键值和主键的键值,这时候我们需要回表,假如辅助索引和主键索引顺序相差很大,那么回表查主键B+树的时候,就是随机访问磁盘,也就是随机IO操作,而如果使用了MRR,就会按照主键进行重排序,这时候再回表就是顺序IO,所以说MRR之所以能优化是因为顺序IO访问的效率是远远大于随机IO的。
INDEX MERGE
索引合并优化,MySQL在5.0及之后的版本引入了这种优化方案。这个意思就是我们在一个表中建立了很多单列索引,然后查询的时候同时用到了多列作为条件,MySQL能够识别并分别使用单列索引进行扫描,然后将结果合并。
这种算法一般用于以下三种情况:
- or条件的并集(union 或者 union all)
- and条件的交际
- 综合前面两种情况
注意:过多的单列索引大部分情况下并不能提高性能。《高性能MySQL》一书中的作者认为,索引合并虽然是MySQL的优化方案,但是出现了这种现象,更多是说明索引建的很糟糕。
索引的种类
创建索引语法为:
CREATE [UNIQUE | FULLTEXT | SPATIAL] INDEX index_name
[index_type]
ON tbl_name (key_part,...)
[index_option]
[algorithm_option | lock_option] ...
InnoDB引擎支持如下常见的三种索引:
B+树索引的类型及使用
B+树索引就是我们常见的主键索引,唯一索引等普通索引
普通索引
如:
CREATE INDEX name_index ON test2 (name);
唯一索引
如:
ALTER TABLE test2 DROP INDEX name_index; -- 先删掉上面创建的索引
CREATE UNIQUE INDEX name_index ON test2 (name);
前缀索引
前缀索引只能用在CHAR, VARCHAR, BINARY,VARBINARY及TEXT等字符类型的列上。如下:
ALTER TABLE test2 DROP INDEX name_index; -- 先删掉上面创建的索引
CREATE INDEX name_index ON test2 (name(10));
name(10)就表示只把name中前10位作为索引的列
多列联合索引
可以把多列作为共同索引,如下:
CREATE INDEX id_name_index ON test2 (id,name);
全文索引
每张表最多允许创建一个全文索引,目前只有InnoDB和MyISAM两种存储引擎支持全文索引。全文索引只能在字符类型的字段创建,比如 char、varchar、text等。如下:
ALTER TABLE test2 DROP INDEX name_index; -- 先删掉上面创建的索引
CREATE FULLTEXT INDEX name_index ON test2 (NAME);
请注意,全文索引的查询语法和其他索引不一样,全文索引使用如下语法进行查询:
MATCH (col1,col2,...) AGAINST (expr [search_modifier])
其中:search_modifier有如下选项:
search_modifier:
{
IN NATURAL LANGUAGE MODE
| IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION
| IN BOOLEAN MODE
| WITH QUERY EXPANSION
}
如下示例:
CREATE TABLE articles (
id INT UNSIGNED AUTO\_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT (title,body)
) ENGINE=InnoDB;
INSERT INTO articles (title,body) VALUES
('MySQL Tutorial','DBMS stands for DataBase ...'),
('How To Use MySQL Well','After you went through a ...'),
('Optimizing MySQL','In this tutorial we will show ...'),
('1001 MySQL Tricks','1. Never run mysqld as root. 2. ...'),
('MySQL vs. YourSQL','In the following database comparison ...'),
('MySQL Security','When configured properly, MySQL ...');
SELECT \* FROM articles WHERE MATCH (title,body) AGAINST ('database' IN NATURAL LANGUAGE MODE);
注意:NATURAL LANGUAGE MODE 表示的是自然语言模式,也是默认的全文索引的查询模式,所以上面示例中的查询也可以直接这么写:
SELECT \* FROM articles WHERE MATCH (title,body) AGAINST ('database');
全文索引不得不说的事
在MySQL 5.7.6之前,MySQL全文索引只支持英文全文索引,不支持中文全文索引(只能把整个中文当成一个词语搜索),如果需要支持中文则需要使用插件ngram来实现,MySQL从5.7.6开始才内置了ngram全文解析器,用来支持中文、日文、韩文分词。
全文索引还有很多细节需要注意的地方,本文篇幅有限,就不进一步阐述了!
哈希索引
InnoDB中的哈希索引是一种自适应哈希索引,也就是说我们不能直接创建哈希索引,目前MySQL引擎中只有Memory引擎支持创建哈希索引
索引信息分析
我们知道,有些查询语句是用不到索引的,那么一句查询语句到底在什么情况下用到索引,什么情况下用不到索引呢?MySQL是如何选择的呢?
新建一张表test:
CREATE TABLE `test` (
`id` int(5) NOT NULL AUTO\_INCREMENT,
`name` varchar(50) DEFAULT NULL,
`company` varchar(20) DEFAULT NULL,
`age` tinyint(2) DEFAULT NULL,
`create_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name_index` (`name`),
KEY `name_age_index` (`name`,`age`)
) ENGINE=InnoDB AUTO\_INCREMENT=120 DEFAULT CHARSET=utf8
初始化一些数据,然后先让我们执行一条语句:
SHOW INDEX FROM test
返回结果如下:

注意:第三行和第四行是一个多列索引,这里的查询时按照列显示的
查询结果的字段含义如下:
- Table:表名
- Non_unique:是否非唯一索引,0-否(主键是唯一索引,所以是0) 1-是
- Key_name:索引名称
- Seq_in_index:索引所在位置(组合索引的时候可以看出区别,单列索引都是1)
- Column_name:索引列的名称
- Collation:列是以什么方式存储的,值为A或者Null,对于B+树索引,总是为A,代表排序;而全文索引或者哈希索引则为Null
- Cardinality:索引中唯一值的估计值。这个数字越接近总数,则表示索引的选择性越高,如果这个数很小,那么可以考虑删除这个索引,因为重复值太多,选择性就不高,用到索引的概率也相对较低。
- Sub_part:是否是列的部分被索引。如果索引全部则为Null,如果是对字段的某一长度索引,则显示具体长度。
- Packed:索引值如何被压缩,没有压缩则为Null。
- Null:索引列是否允许Null值
- Index_type:索引的类型
- Comment:关于索引的信息没有在它自己的列中描述,例如,如果索引已禁用,则禁用索引
- Index_comment:创建索引时的comment属性值
关于Cardinality
Cardinality是通过采样来实现计算的,也就是说并不是一个精确值,而是一个统计值,而且这个值并不会实时更新(亲测如果你的表足够小,是会实时更新的),如果表够大,每次更新都会带来消耗,如果想要手动更新的话,可以使用以下步骤:
- 对InnoDB引擎,可以执行ANALYZE TABLE 表名来强制更新(),
- 对MyISAM引擎,则可以执行命令:myisamchk 表名,注意,这个命令是要到服务器中数据库存储的文件目录里面(通过:SHOW VARIABLES LIKE 'datadir’可以查询到数据存储路径)去执行的,而不是在sql语句里面执行,这一点网上有些博客并没有说清楚。官网介绍还有一种执行方式是myisamchk 表名.MYI也可以执行,亲测后发现是无法执行的,会报错提示无法打开表,据其他博主介绍这个是MySQL5.6之后出现的Bug,本人用的是MySQL5.7.26,有兴趣的可以自己用低版本MySQL尝试一下
Cardinality的更新策略
InnoDB存储引擎内部对更新Cardinality信息的策略有两种:
- 上一次统计Cardinality之后,表中1/M之一的数据发生过变化
- stat_modifier_counter>2,000,000,000:这种情况主要针对的是假如少数行频繁的更改,表中的数据发生变化数达不到1/M的情况,所以在InnoDB引擎内部有一个计数器stat_modifier_counter,用来统计表发生变化的次数(注意这不是某一行变化的次数,而是整体的变化次数)
Cardinality的计算方式
InnoDB默认对N个叶子节点进行抽样统计,所以如果一张表足够小的话,每次统计的值是一样的,采样统计过程如下:
1、获得叶子节点的总数A
2、随机获取叶子节点N个,并相加,获得总数total
3、(total / N) * A 得到采样的数据
在 MySQL 中,有两种存储索引统计的方式,可以通过设置参数 innodb_stats_persistent 的值来选择:
- 设置为 on 的时候,表示统计信息会持久化存储。这时,默认的N是20,M是10。
这时候N的值由变量innodb_stats_persistent_sample_pages控制 - 设置为 off 的时候,表示统计信息只存储在内存中。这时,默认的 N 是 8,M 是 16。
这时候N的值由变量innodb_stats_transient_sample_pages控制
另外,统计的时候对Null值也有特殊处理,由变量innodb_stats_method控制
| 值 | 描述 |
|---|---|
| nulls_equal | 默认值。所有Null都按等值处理 |
| nulls_unequal | 所有Null都按不等值处理 |
| nulls_ignored | 忽略Null值,Null值不统计 |
索引的使用原则
离散度
离散度=count(distinct(column_name)) /count(*),而count(distinct(column_name))实际上就是上文中介绍的Cardinality值。某一列的离散度越高,也就是说越接近1,则被MySQL优化器选择作为索引的概率就越大。
最左匹配原则
MySQL索引遵循最左匹配原则,这又可以分为两种情况
like和_的最左匹配方式
比如我们在表user中的列name中创建了索引,然后执行查询语句:
select \* from user where name like '%张三';
select \* from user where name like '\_张三';
这两种因为不是从开头开始匹配的,等于跳过了索引的开头部分,根据索引的最左匹配原则,这种情况就不会使用索引
Kafka实战笔记
关于这份笔记,为了不影响大家的阅读体验,我只能在文章中展示部分的章节内容和核心截图

- Kafka入门
- 为什么选择Kafka
- Karka的安装、管理和配置

- Kafka的集群
- 第一个Kafka程序

afka的生产者

- Kafka的消费者
- 深入理解Kafka
- 可靠的数据传递


- Spring和Kalka的整合
- Sprinboot和Kafka的整合
- Kafka实战之削峰填谷
- 数据管道和流式处理(了解即可)

- Kafka实战之削峰填谷

fka的生产者
[外链图片转存中…(img-j8n6zyq9-1714517291563)]
- Kafka的消费者
- 深入理解Kafka
- 可靠的数据传递
[外链图片转存中…(img-2IprVWJ8-1714517291563)]
[外链图片转存中…(img-mGTZofvH-1714517291563)]
- Spring和Kalka的整合
- Sprinboot和Kafka的整合
- Kafka实战之削峰填谷
- 数据管道和流式处理(了解即可)
[外链图片转存中…(img-luEE7tIe-1714517291563)]
- Kafka实战之削峰填谷
[外链图片转存中…(img-1EHfkkWo-1714517291564)]















 1224
1224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









