







目录
作为一棵二叉搜索树,其属性有其左子树小于根节点,右子树大于根节点。
在删除二叉搜索树的节点后,我们仍要保持这个属性。
思考:
具体情况分为三种:
-
- 删除叶子
- 删除只有一个孩子的结点
- 删除有两个孩子的结点
让我们来思考这几种情况:
删除叶子
当要删除的节点为叶子节点时,此时的删除操作会非常简单,我们可以直接delete并将其指针赋NULL
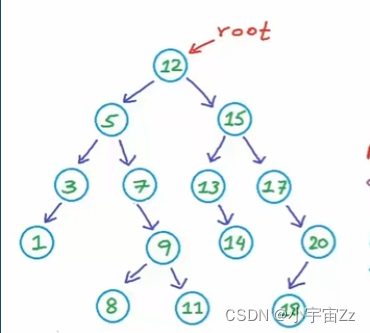
- 例如我们需要删除图中数据为1的节点,只需要delete并赋空
if (root->left == NULL && root->right == NULL)
{
delete root;
root = NULL;
}
删除只有一个孩子的结点
当要删除的节点只有一个孩子时,即左孩子为NULL或右孩子为NULL,此时的结构很想一条链表,我们只需要将要删除节点的父节点的子节点指向要删除节点的子节点即可
- 例如我们要删除图中数据为7的节点,只需要将5连向9即可
- 至于怎么连接,我们待会会在递归的返回值上实现
- 为什么直接将5与9相连就可以呢?作为一棵二叉搜索树,以5为根节点,其右子树均大于5,这时候将在右子树的9替换掉原本右节点的7也是没有问题的
else if (root->left == NULL)
{
treenode* temp = root;
delete root;
root = root->right;
}
else if (root->right == NULL)
{
treenode* temp = root;
delete root;
root = root->left;
}
删除有两个孩子的结点
这种情况较为复杂,当要删除的节点有两个孩子时
此时如果删除该节点,让父节点连其左子树或是右子树都会丢失一棵子树。
这时我们有一种思路:
例如删除图中数据为15的节点在15的右子树中找到最小值,将这个最小值覆盖掉15的数据,再将这个最小值删除。
这样做有什么好处呢?
让我们想一下:
1.在这棵以15为根节点的二叉搜索树中,右子树的最小值,即17,因为是二叉搜索树,17一定大于15左子树的所有节点,同时17又小于15右子树的所有节点,这样就保证了二叉搜索树的属性。
2.当我们回过头来删除17这个节点时,我们会发现,其一定是第一种情况(删除叶子)或第二种情况(删除只有一个孩子的结点),17作为右子树中最小的节点,其左节点一定为NULL,否则17就不是最小节点。
else
{
treenode* temp = findmin(root->right);
root->a = temp->a;
root->right=deletenode(root->right, temp->a);
}其中findmin函数用来查找子树中数据最小的节点。
通过以上操作,便可以将第三种情况下降至第一种/第二种情况进行删除操作。
递归
现在来分析一下其中的递归操作:
函数返回值为连接上的新节点。
if (date < root->a)
root->left = deletenode(root->left, date);
else if (date > root->a)
root->right = deletenode(root->right, date);在递归中,我们通过接受返回值来连接节点。
else
{
treenode* temp = findmin(root->right);
root->a = temp->a;
root->right=deletenode(root->right, temp->a);
}同时,在第三种情况中,我们将其下降为第一种/第二种情况时也使用了递归。
整体代码:
class DELETE
{
public:
treenode* deletenode(treenode* root, int date)
{
if (NULL == root)
return NULL;
if (date < root->a)
root->left = deletenode(root->left, date);
else if (date > root->a)
root->right = deletenode(root->right, date);
else//找到了
{
//1
if (root->left == NULL && root->right == NULL)
{
delete root;
root = NULL;
}
else if (root->left == NULL)
{
treenode* temp = root;
delete root;
root = root->right;
}
else if (root->right == NULL)
{
treenode* temp = root;
delete root;
root = root->left;
}
else
{
treenode* temp = findmin(root->right);
root->a = temp->a;
root->right=deletenode(root->right, temp->a);
}
}
return root;
}
public:
treenode* findmin(treenode* root)
{
if (NULL == root)
return NULL;
//
if (root->left == NULL)
return root;
return findmin(root->left);
}
};以上的第三种方法为在右子树中寻找最小值来删除,我们也可以在左子树中寻找最大值进行相同操作,原理是一样的,留给大家来思考。谢谢大家。















 310
310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









