







一、Linux中安装软件
1)源码安装
2)软件包安装---rpm
3)包管理器yum(centos) apt/aptget(ubuntu)
a.网络下载
b.安装(就是拷贝)必须使用root权限
安装到系统里,只安装一次,任何人都能使用。
包管理器会自动给我们解决包的依赖问题。
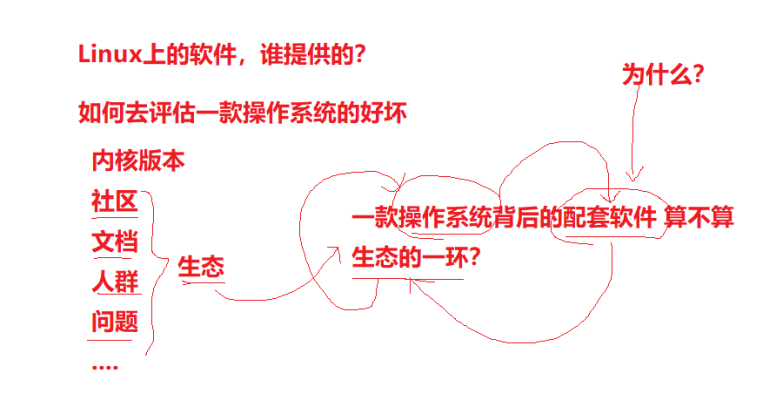
什么是包管理器?
类似手机上的应用商店。
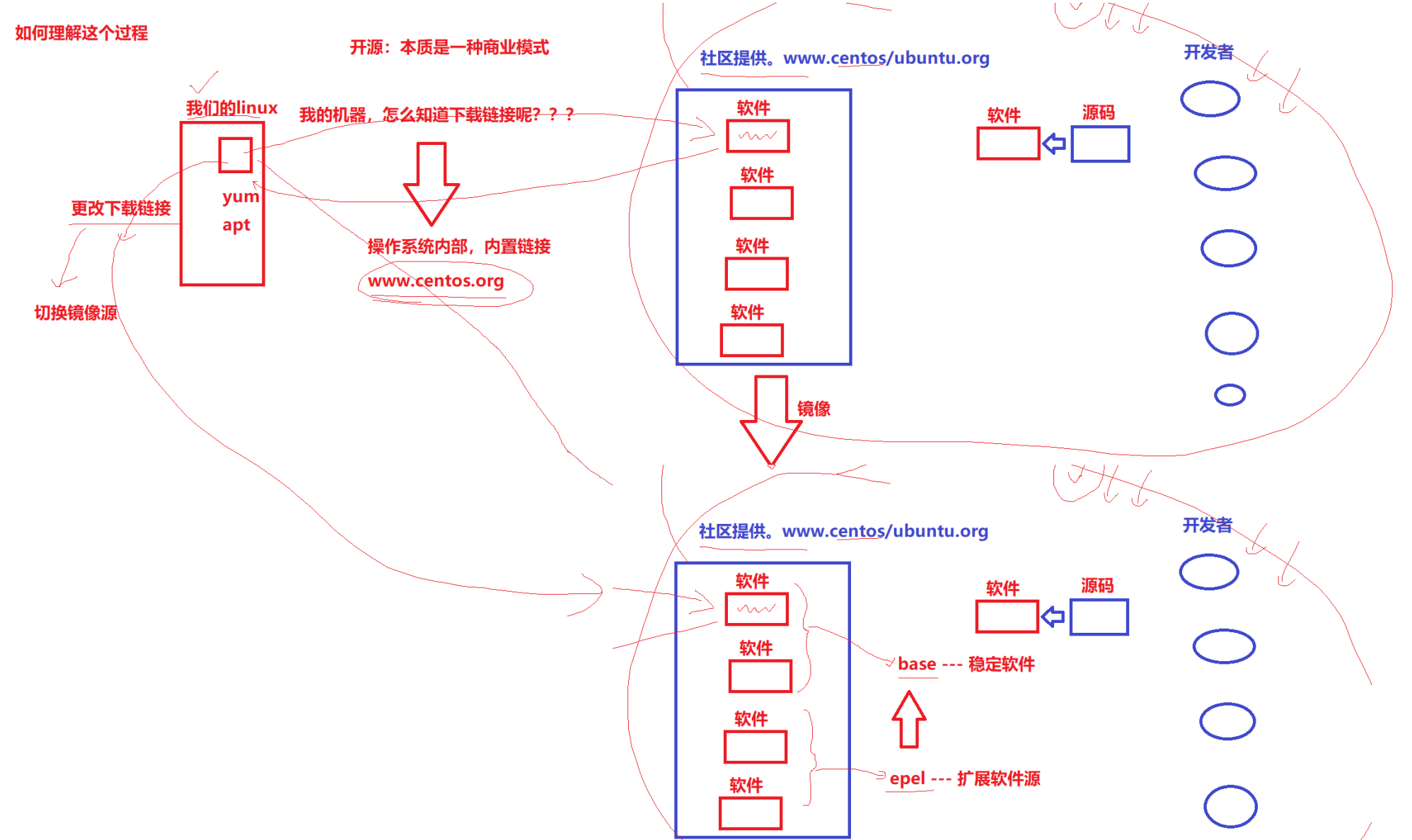
软件是由谁提供的?
理解过程:操作系统背后的配套软件,也是生态的一环。
我的机器怎么知道下载链接?
操作系统内部,内置链接,由于原因,国内有镜像源。
base---稳定软件
epel---扩展软件源
开源本质是一种商业模式。
修改yum源
/etc/yum.repos.d/*(yum源配置文件)
Cetnos 安装源路径:-rw-r--r-- 1 root root 676 Oct 8 20:47 CentOS-Base.repo # 标准源-rw-r--r-- 1 root root 230 Aug 27 10:31 epel.repo # 扩展源yum install -y epel-realse(安装epel扩展软件源)
查看软件包通过 yum list 命令可以罗列出当前⼀共有哪些软件包. 由于包的数目可能非常之多, 这里我们需要使用grep命令只筛选出我们关注的包。例如: yum list | grep lrzsz卸载软件yum remove [-y] lrzsz

易错点1:
死代码删除是编译最优化技术,指的是移除根本执行不到的代码,或者对程序运行结果没有影响的代码,而并不是删除被注释的代码。
内联函数,也叫编译时期展开函数, 指的是建议编译器将内联函数体插入并取代每一处调用函数的地方,从而节省函数调用带来的成本,使用方式类似于宏,但是与宏不同的是内联函数拥有参数类型的校验,以及调试信息,而宏只是文本替换而已。
for循环的循环控制变量,通常被cpu访问频繁,因此如果调度到寄存器中进行访问则不用每次从内存中取出数据,可以提高访问效率。
强度削弱是指执行时间较短的指令等价的替代执行时间较长的指令,比如 num % 128 与 num & 127 相较,则明显&127更加轻量。
易错点2:
编译过程为 扫描程序-->语法分析-->语义分析-->源代码优化-->代码生成器-->目标代码优化
扫描程序进行词法分析,从左向右,从上往下扫描源程序字符,识别出各个单词,确定单词类型。
语法分析是根据语法规则,将输入的语句构建出分析树,或者语法树,也就是我们答案中提到的分析树parse tree或者语法树syntax tree。
语义分析是根据上下文分析函数返回值类型是否对应这种语义检测,可以理解语法分析就是描述一个句子主宾谓是否符合规则,而语义用于检测句子的意思是否是正确的。
目标代码生成指的是,把中间代码变换成为特定机器上的低级语言代码。
易错点3:
Makefile里主要包含了五个东西:显式规则、隐晦规则、变量定义、文件指示和注释。
显式规则说明了,如何生成一个或多个目标文件。
make有自动推导的功能,所以隐晦的规则可以让我们比较粗糙地简略地书写makefile,比如源文件与目标文件之间的时间关系判断之类。
在makefile中可以定义变量,当makefile被执行时,其中的变量都会被扩展到相应的引用位置上,通常使用 $(var) 表示引用变量
文件指示。包含在一个makefile中引用另一个makefile,类似C语言中的include。
注释,makefile中可以使用 # 在行首表示行注释。
默认的情况下,make命令会在当前目录下按顺序找寻文件名为“GNUmakefile”、“makefile”、“Makefile”的文件。
伪对象.PHONY
makefile中的伪对象表示对象名称并不代表真正的文件名,与实际存在的同名文件没有相互关系,因此伪对象不管同名目标文件是否存在都会执行对应的生成指令。
伪对象的作用有两个:
1. 使目标对象无论如何都要重新生成。
2. 并不生成目标文件,而是为了执行一些指令。
make会自动根据依赖对象检测目标对象是否需要重新生成.
make在执行makefile规则中,根据语法规则,会分析目标对象与依赖对象的时间信息,判断是否在上一次生成后,源文件发生了修改,若发生了修改才需要重新生成。
二、编辑器vim
批量注释:首先从命令模式输入ctrl+v切换到V-BLOCK模式,使用hjkl进行选择,选择完后输入shitf+i=I进入插入模式,输入//,使用ESC切回V-BLOCK模式,可以看到选中行前面都加了//。
命令模式:快速编辑
快捷键:
定位
gg:快速回归光标
shift+g=G:快速把光标定位到结尾
n+shift+g = n+G:把光标定位到任意行
shift+$:定位到一行结尾
shift+^:定位到一行开头
n+hjkl:左下上右
w:以单词为单位向后移动
b:以单词为单位向前移动
编辑
n+yy:复制
n+p:粘贴
u:撤销历史操作(退出文件编辑无法进行撤销,但如果只是保存,没有退出还可以撤销)
ctrl+r:反撤销
n+dd:剪切当前行,或者删除
n+x:删除光标所在位置的字符
shift+x:光标右侧不动,左侧删除,也类似剪切。
r:替换光标所在字符,r->目标字符
nr:
shift+r=R:批量化替换
shift+~:大小写切换
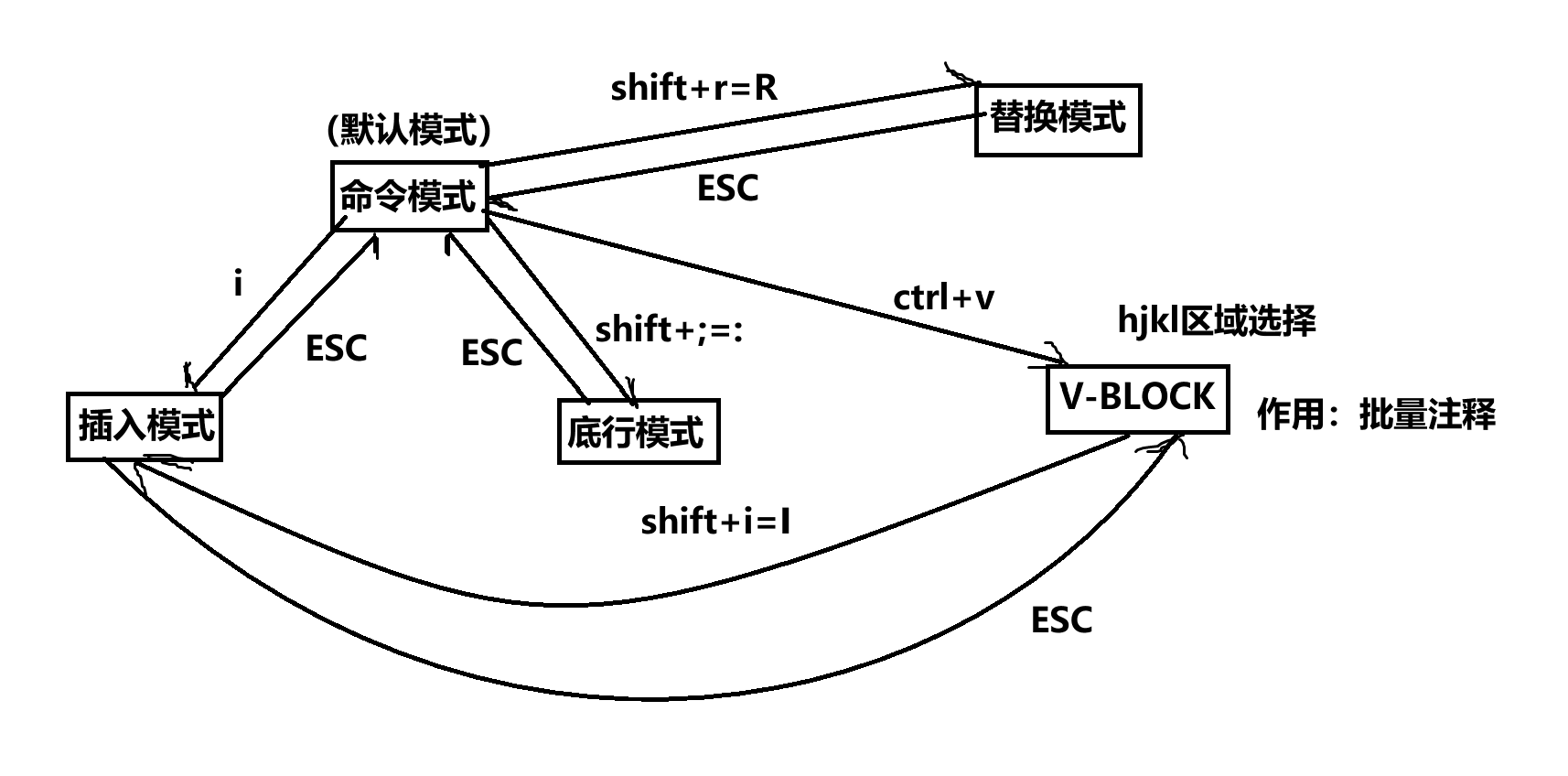
底行模式
w/q/!,ZZ set nu/nonu
:!command 不退出vim情况下输入命令
:%s/dst/src/ 批量化替换
分屏操作
:vs new_src
ctrl+ww:切换光标位置
vim技巧
vim src+n 打开时定位到第n行。
三、Linux编译器---gcc/g++使用
gcc xxx.c -o xxx
1.预处理(宏替换,条件编译,去注释,头文件展开等)
gcc -E code.c -o code.i
-E表示进行程序翻译,在预处理完时停止
2.编译(生成汇编)
gcc -S code.i -o code.s
-S表示开始翻译,编译做完了,就停下来
3.汇编(生成机器可识别代码)
gcc -c code.s -o code.o
-c表示开始翻译,汇编完成就停下来。
code.o是可重定位目标文件,vs2022,xxx.obj
已经是二进制文件了,但不能直接运行。
4.链接(生成可执行文件或库文件)
gcc code.c -o code
库:
1.动态库:Linux(.so) Windows(.dll)
2.静态库:Linux(.a) Windows(.lib)


理解预处理:
gcc code.c -o code -DM (命令行级的宏定义)
相当于#define M 100字符串插入到代码中。
预处理本质就是修改编辑我们的文本代码。
条件编译的用途:
1.社区版和专业版区分,使用条件编译进行代码动态裁剪。
2.内核源代码也是采用条件编译进行代码裁剪(例如嵌入式设备不需要联网就将网络部分裁剪)
3.多平台的开发工具、应用软件
为什么C/C++编译,要先变成汇编?
语言发展史:
开关
打孔编程(二进制编程)
汇编语言
C语言
C++/Java/Go/Python...
为什么要先变成汇编?
直接翻译成2进制,翻译代价太大了,C语言出来的时候,汇编语言已经发展得很成熟了,将C语言翻译成汇编(文本到文本),再由汇编翻译成2进制,翻译成本小。
编译器的自举过程:
第一个汇编语言编译器必须用2进制写,因为如果用汇编写没有对应汇编编译器编译汇编,产生了2进制的汇编语言编译器后,再用汇编语言写一个汇编编译器,用2进制的汇编编译器编译之后,就诞生了汇编语言写的汇编编译器,这个过程称为编译器的自举过程。
因此,先有语言,然后才有该语言写的编译器。
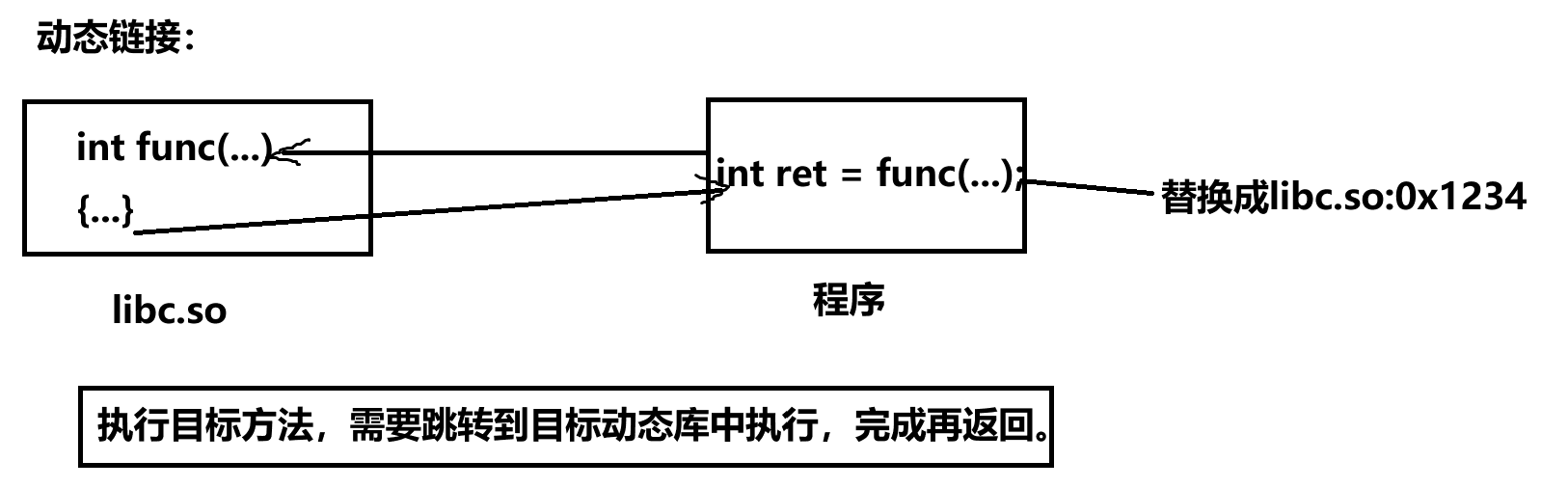
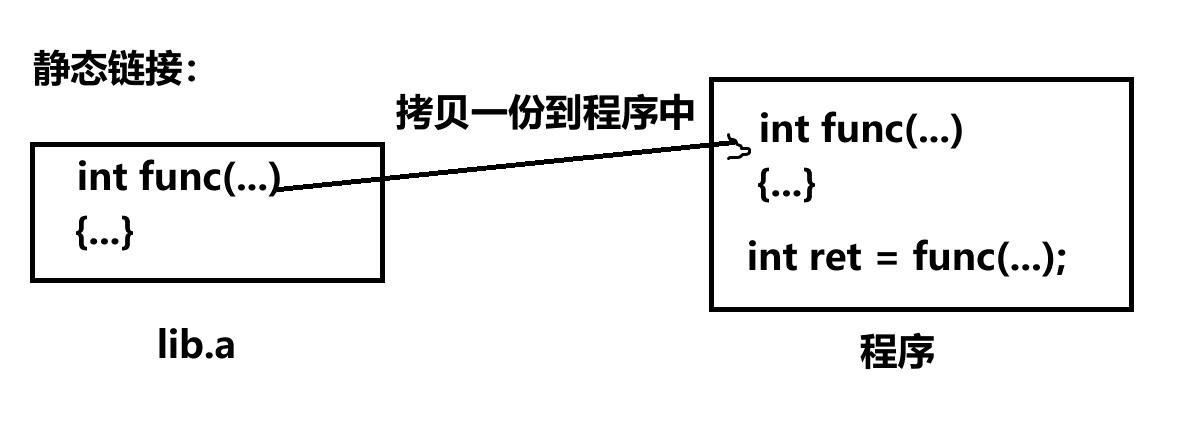
什么叫做动态库,什么叫做动静态链接,如何理解?
库:
1.动态库:Linux(.so) Windows(.dll)
2.静态库:Linux(.a) Windows(.lib)
库是一套方法或数据库,为我们开发提供最基本的保证(基本接口、功能,加速我们二次开发)。
libc.so 命名 lib+名称+.so*/.a*
libc.a
动态库:被多个程序共享,一旦缺失,会导致所以程序无法执行
静态库:只在链接时需要,运行时不需要。
动静态库对比:
1)动态库形成的可执行程序体积一定很小
2)可执行程序对静态库依赖小,动态库不能缺失
3)程序运行,需要加载到内存,静态链接的,会在内存中出现大量的重复代码
4)动态链接,比较节省内存和磁盘资源
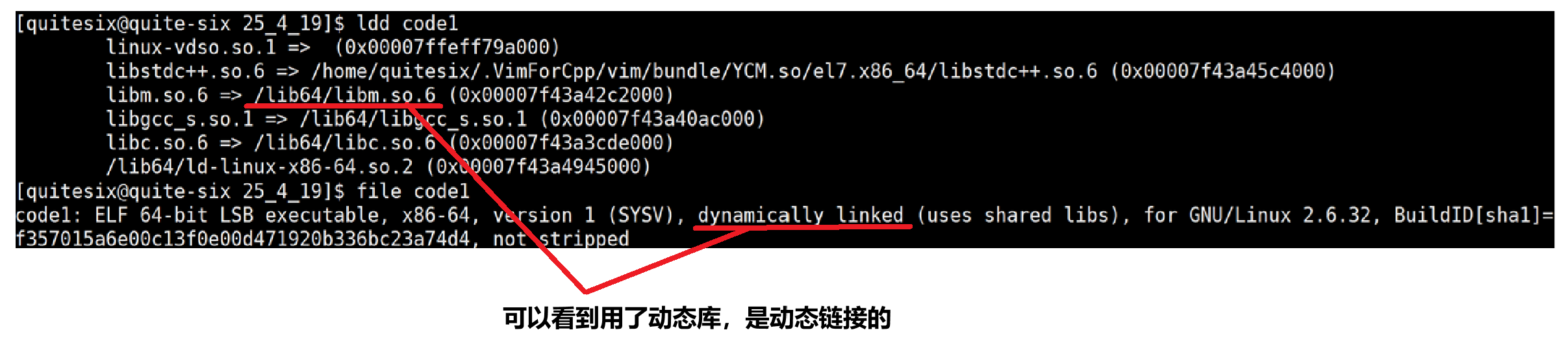
ldd和file指令:
gcc code.c -o code-static -static(-static强制静态链接)
默认是动态链接
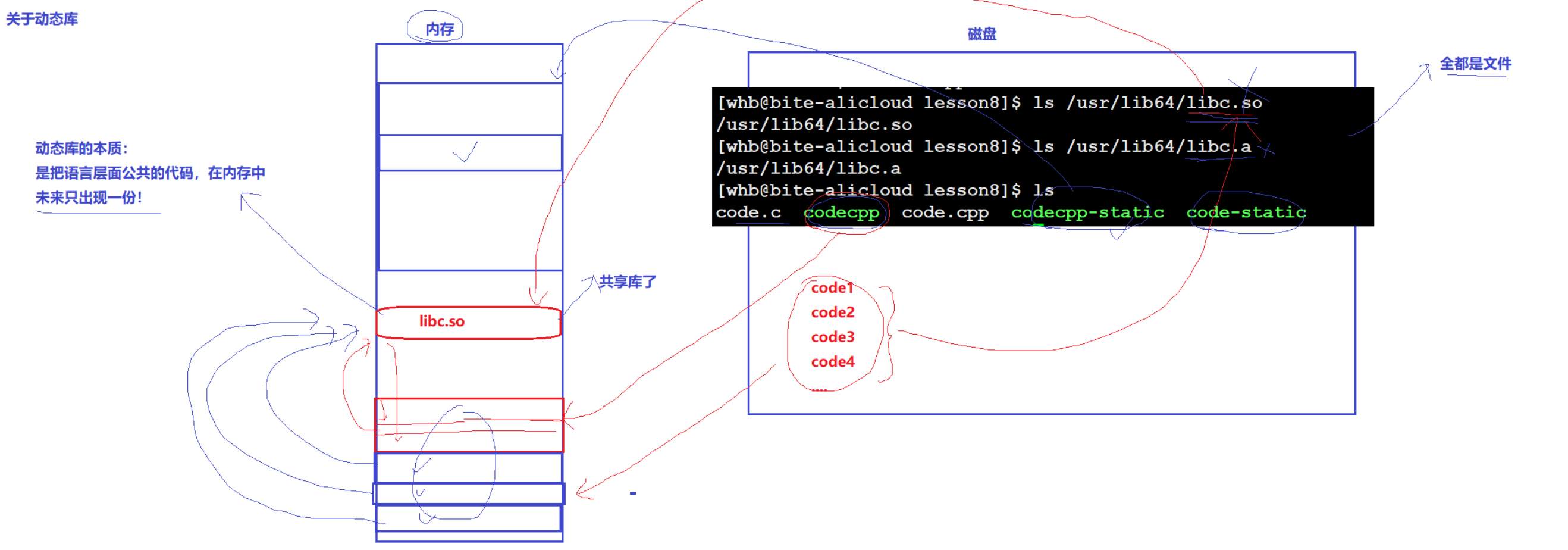
关于动态库:
重定向拷贝:cat srcfile > dstfile
动态库本质:把语言层面公共的代码,在内存中未来只出现一份。
加载程序到内存时,相应的动态库也会被加载到内存中。
技术上理解库:
1.c->1.o
2.c->2.o
3.c->3.o
再链接o->exe。
库的本质是.o,但是为了防止丢失,打包成.so或.a。
本质上是被打包的.o文件。
链接本质,将.o进行合并。

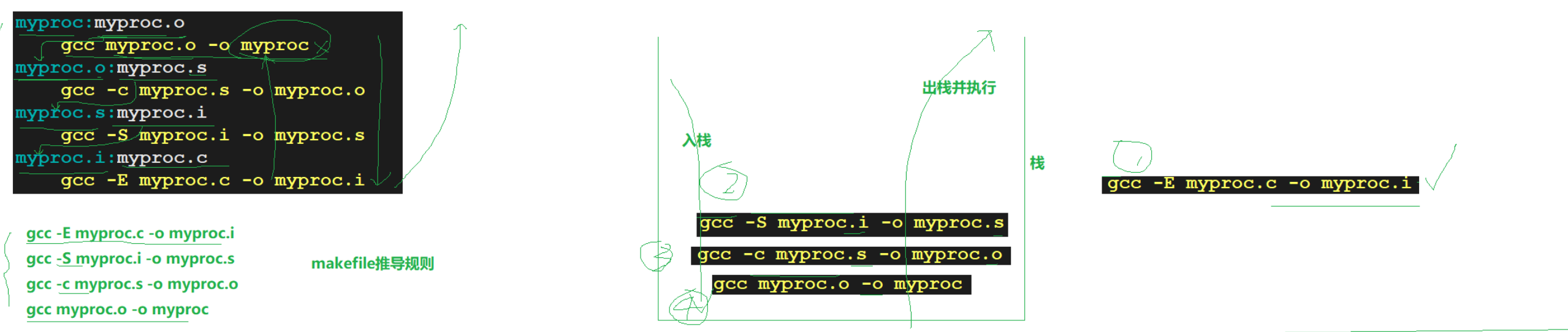
四、自动化构建-make/Makefile(重点)
make是一个命令,makefile是一个文件
写成makefile/Makefile都可以。
实例:
code:code.c (依赖关系)
gcc -o code code.c (依赖方法)
target: src1 src2 src3
command依赖关系中,target和src是一对多的关系。
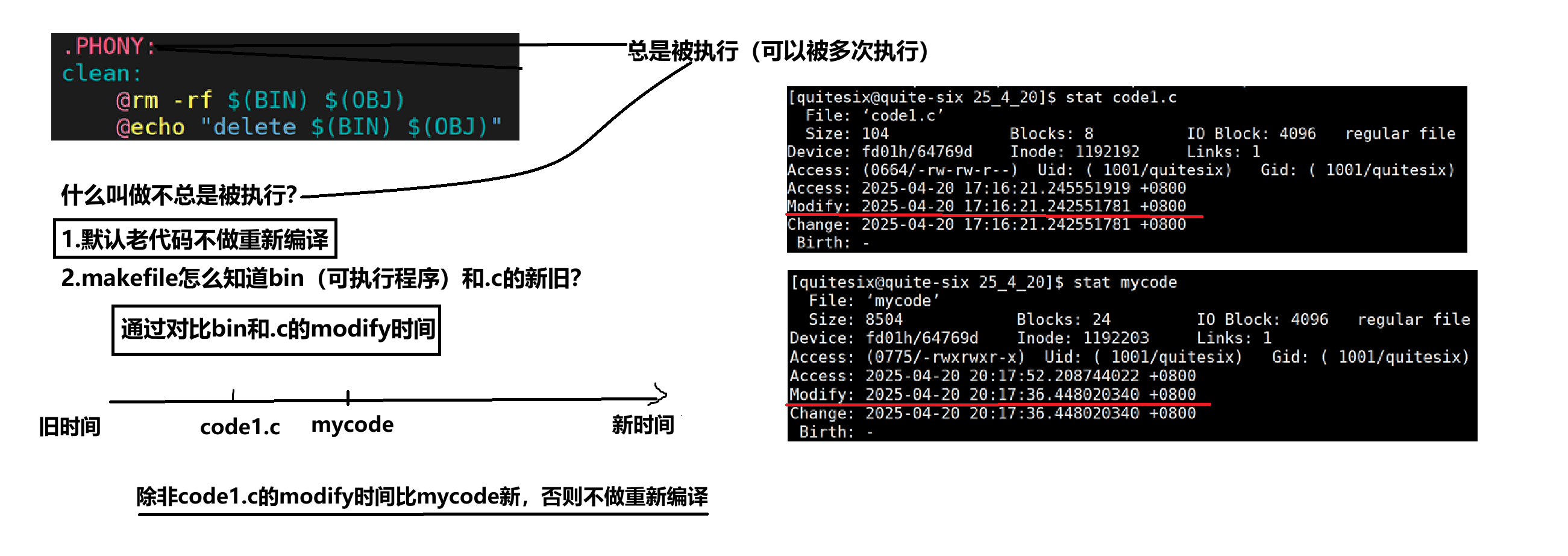
理解.PHONY以及不总被执行:
Access:最近访问时间,但由于查询是占文件操作的大部分,如果每一次查询都修改时间,那么就会导致每次都要修改访问时间,要进行一次IO操作,IO操作很消耗时间,要达到一定访问次数才更新时间,并非实时更新。
Modify:文件的内容变了,就要更新。
Change:文件属性变了,就更新。由于属性包括文件大小,时间。Modify了,即使文件大小不变,Modify时间变了,必然会影响文件属性,Change时间会更新。修改文件的权限也会更新Change时间。
文件=内容+属性
touch 已存在文件,更新三个时间
makefile的原理:
makefile技巧:
$() //引用
加@ 不打印makefile的内容
$@ 最终目标
$^ 最终目标依赖的众多文件列表
%.o:%.c
把当前路径下的所有.o/.c依次展开,如果有100份,展成100份对应的依赖关系。
$< 将方法一个一个展开
1)SRC=${shell ls *.c} 获取当前目录下的所有.c文件
2)SRC=${wildcard *.c}
OBJ=${SRC:.c=.o} SRC内部的文件名.c替换成同名.o
通用makefile:
#SRC=${shell ls *.c} SRC=${wildcard *.c} OBJ=${SRC:.c=.o} BIN=mycode $(BIN):$(OBJ) @gcc -o $@ $^ @echo "linking ... $^ to $@" %.o:%.c @gcc -c $< @echo "compling ... $< to $@" .PHONY: clean: @rm -rf $(BIN) $(OBJ) @echo "delete $(BIN) $(OBJ)" .PHONY: PRINT: @echo ${SRC} @echo ${OBJ}
进度条:
\r回车,回归光标
\n换行,换到下一行。
\r\n回车换行。
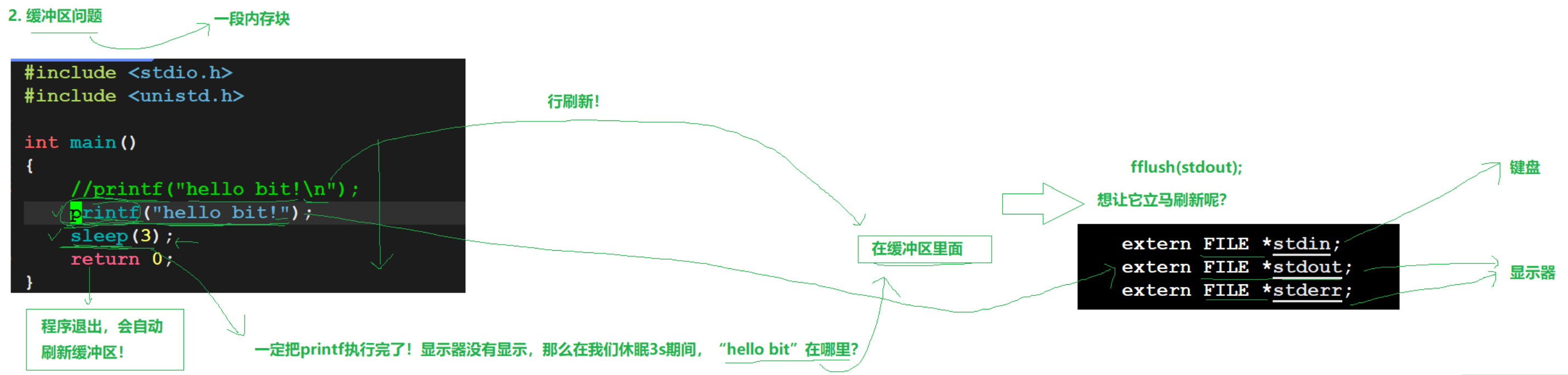
缓冲区理解:一段内存块。
所以要让不加\n的printf立即显示,要加fflush(stdout);刷新一下缓冲区。
进度条实现,版本1:
#include <stdio.h> #include <string.h> #include <unistd.h> #define flag '#' void progressBar1() { char buff[101]; memset(buff,0,101); static char s[] = "/-|\\"; int cnt = 0; static int tmp = 0; while(cnt<=100) { tmp %= 4; printf("[%-100s][%d%%][%c]\r",buff,cnt,s[tmp]); fflush(stdout); usleep(10000); ++tmp; buff[cnt] = flag; ++cnt; } printf("\n"); }版本2:
#include <stdio.h> #include <string.h> #define flag '#' void progressBar2(double current,double total) { char s[] = "/-|\\"; char buff[101]; memset(buff,0,101); int count = (int)((current/total)*100); for(int i = 0;i<count;++i) { buff[i] = flag; } static int k = 0; k%=4; printf("[%-100s][%d%%][%c]\r",buff,count,s[k++]); fflush(stdout); }#include <stdio.h> #include<unistd.h> #include "progressBar2.h" double speed = 1.0; double total = 1024.0; void Upload() { printf("Upload begin...\n"); double current = 0; while(current<=total) { progressBar2(current,total); current+=speed; usleep(10000); } printf("\nCompleted total:%.1lf\n",total); } int main() { Upload(); return 0; }
五、版本控制器Git
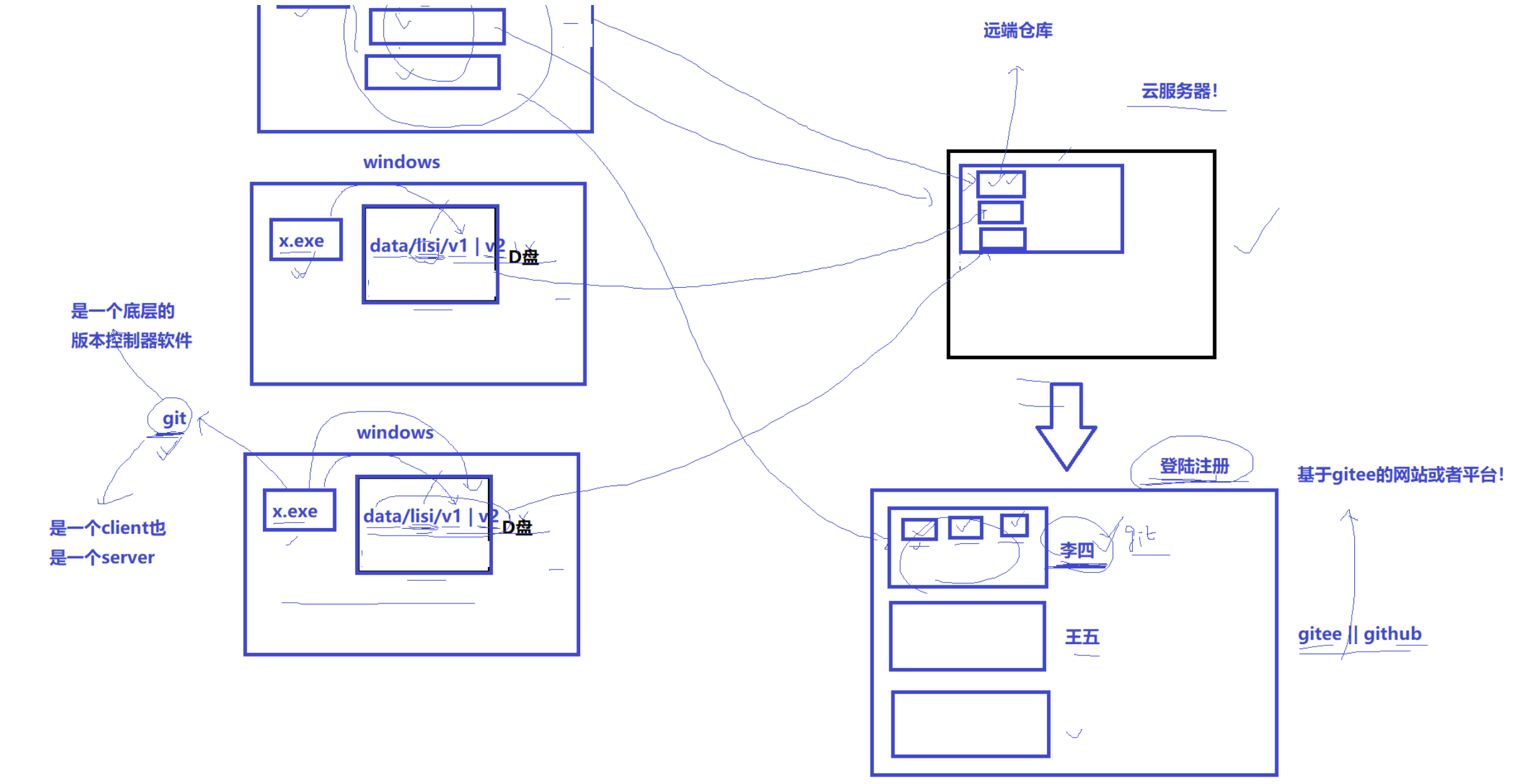
1.如何理解版本控制?->Git && gitee || github(基于git的网站或平台)
版本控制:将每个文件版本进行记录,管理起来。
git是一个客户端,也是一个服务器,底层的版本控制器软件。
目的:
1.数据安全
2.协作开发
git clone 克隆到本地仓库
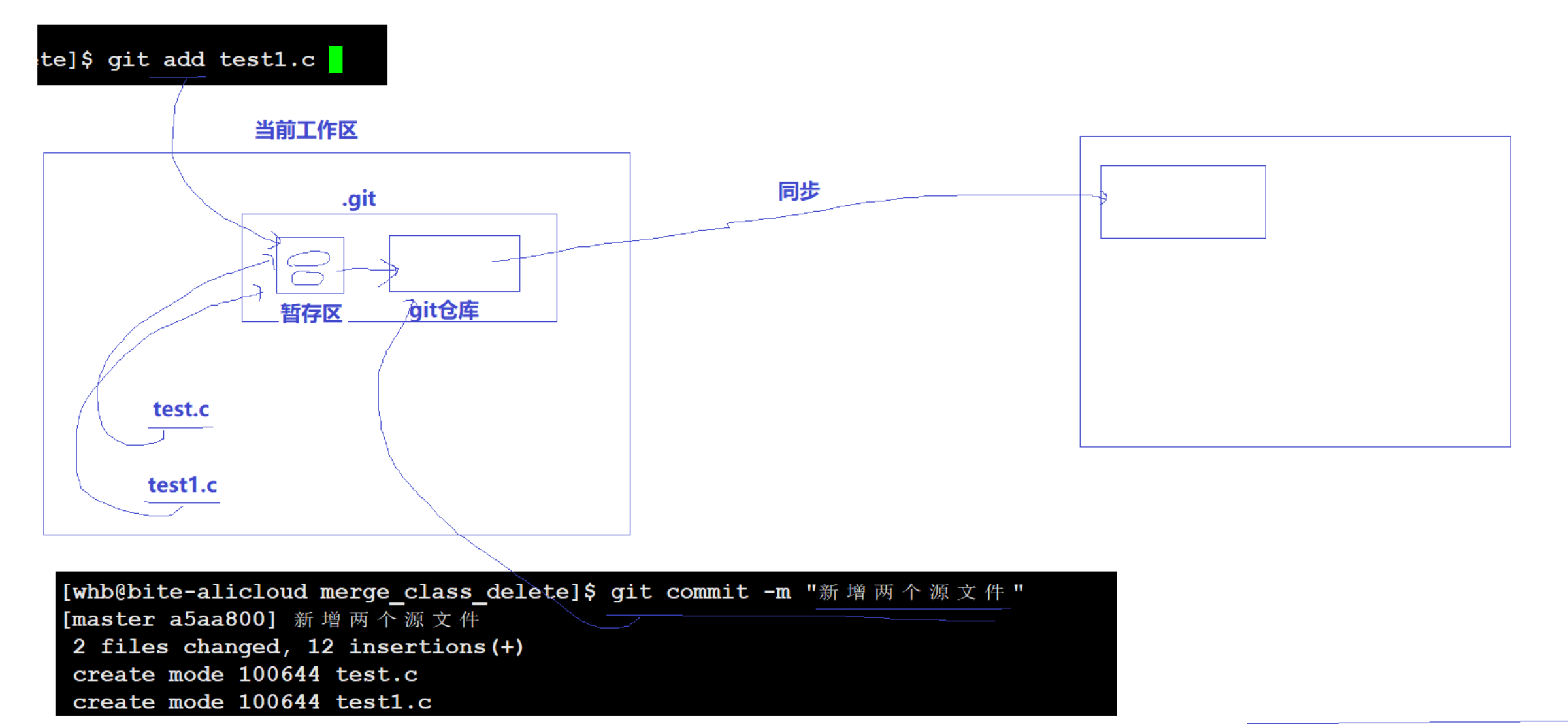
.git 隐藏的本地仓库,包含历史修改记录。
git数据提交的时候,只会提交变化的部分。
git add //添加文件到git暂存区
git comimit -m "xxx" //提交到本地git仓库,带上日志信息
git push //推送到远程仓库
git log //查看日志
git pull //拉取远程仓库,达到同步
注意:
1.首次使用设置登录名和主机名
2.git版本管理,只管理源文件.c/.cpp/.h
3.-gitignore:需要忽略的特定后缀的文件列表。
4.远程仓库,相比较于任何人,都是最新的。
为什么要冲突?
提醒本地用户,需要和远程仓库进行同步了。
六、调试器-gdb/cgdb使用
gcc/g++默认release模式
加上-g选项,让最后形成的可执行程序,加上调试信息。---debug模式
查看debug信息:readelf -S BIN | grep -i debug
gdb bin(可执行程序)
quit退出
list 简写l显示源代码
b+行号:打断点
b+文件名:行号
b+函数名
d+断点编号:删除断点
info b:查看断点信息
r:运行程序,从头开始
gdb不退出:断点编号依次递增。
next/n:逐过程
step/s:逐语句
bt:查看栈帧信息
finish:结束当前函数
p xxx:查看变量的值(表达式)
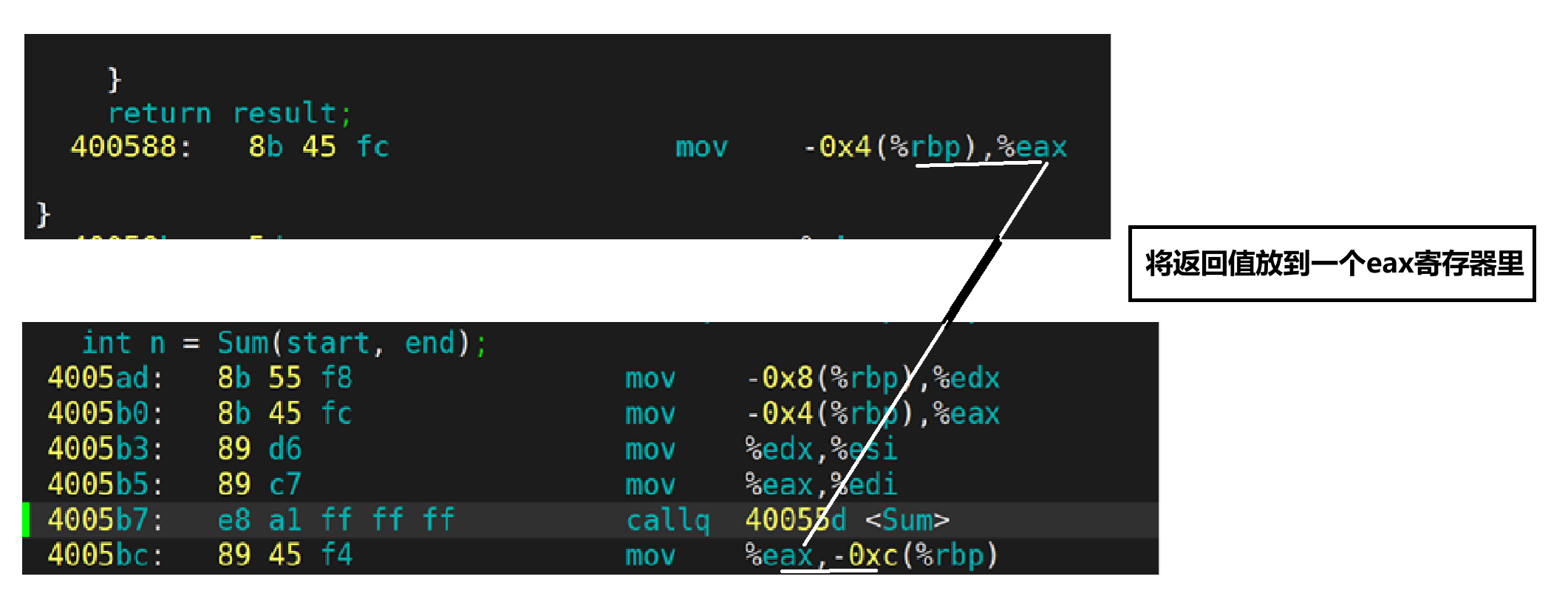
objdump -S mycode > mycode.s(反汇编)
断点可以被使能:
disable + 断点编号 禁用断点
enable + 断点编号 使用断点
调试的本质:
1.找到问题
2.查看代码上下文
断点的本质,把代码进行块级别的划分。
c:运行到下一个断点处
until+行号:将程序运行到指定行号(局部范围快速执行)
类似VS监视窗口:
display+变量 长期显示变量值
undisplay+显示编号 删除对应编号的长显示
注:变量生命周期结束,自动删除对应变量的长显示
info locals 查看当前函数的临时变量
调试技巧:
watch + 变量名 监视变量的变化,变化了就会打印提示信息(也是点信息,c也会跳转至对应改变这个变量的位置)
set vat + 变量名 = xxx 暂时更改变量名对应的值
条件断点:
b + 行号 if expression (常用于循环内部)
给已存在的断点设置条件:
condition + 断点编号 expression
ESC:进入代码屏,滚动代码
i:回到gdb屏




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











