







 本文详细介绍了堆排序的基本概念、堆的存储与建立(包括向上/向下调整算法)、堆排序的具体代码实现,以及其时间复杂度O(nlogn)。重点强调了升序排序时应使用大堆的策略。
本文详细介绍了堆排序的基本概念、堆的存储与建立(包括向上/向下调整算法)、堆排序的具体代码实现,以及其时间复杂度O(nlogn)。重点强调了升序排序时应使用大堆的策略。
堆排序
- 一.堆
- 1.什么是堆
- 2.堆的存储与建立
- 2.1 堆的存储
- 2.2 堆的建立
- a.向上调整算法建大堆
- b. 向下调整算法建大堆
- 二.堆排序代码及原理
- 三.堆排序的时间复杂度
一.堆
1.什么是堆
堆是一种数据结构,属于二叉树的特殊情况(完全二叉树)
堆总体可以分成两大类:大堆和小堆
大堆:要求任意一个父亲>=孩子
小堆:要求任意一个父亲<=孩子
我们可以看一下几张图判别一下:
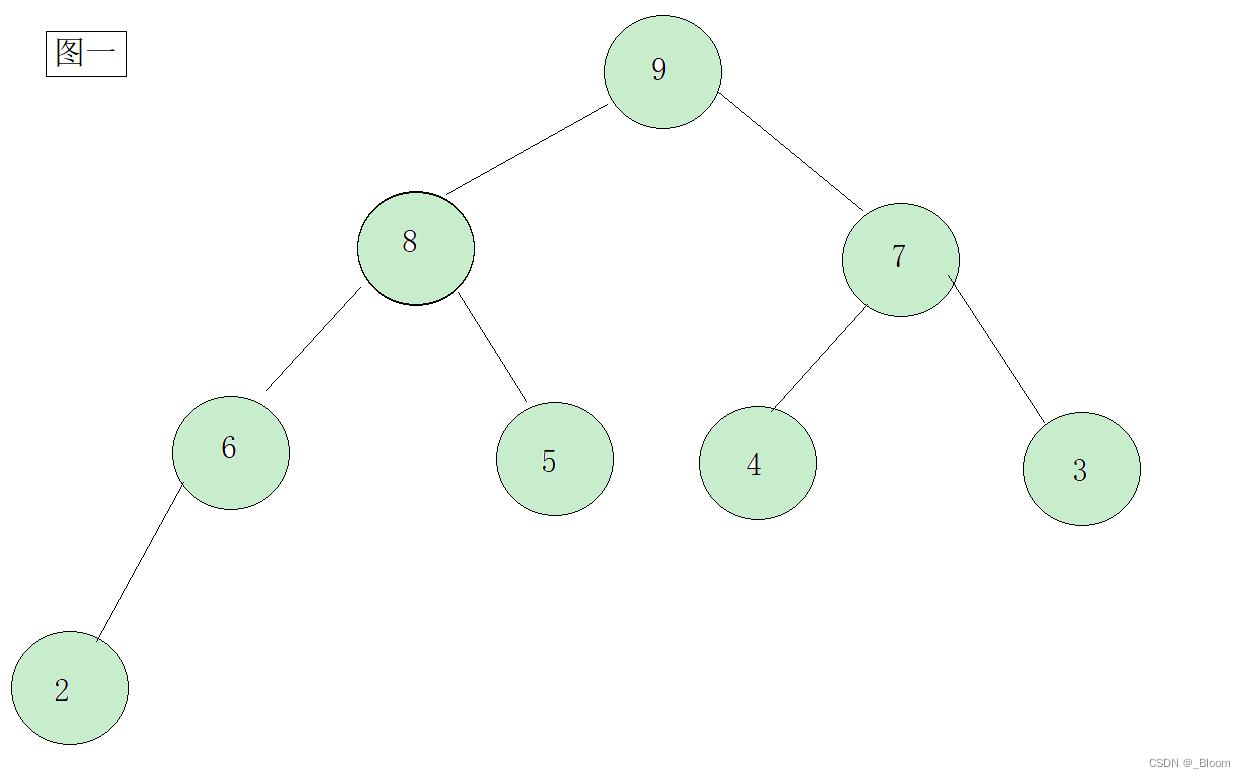
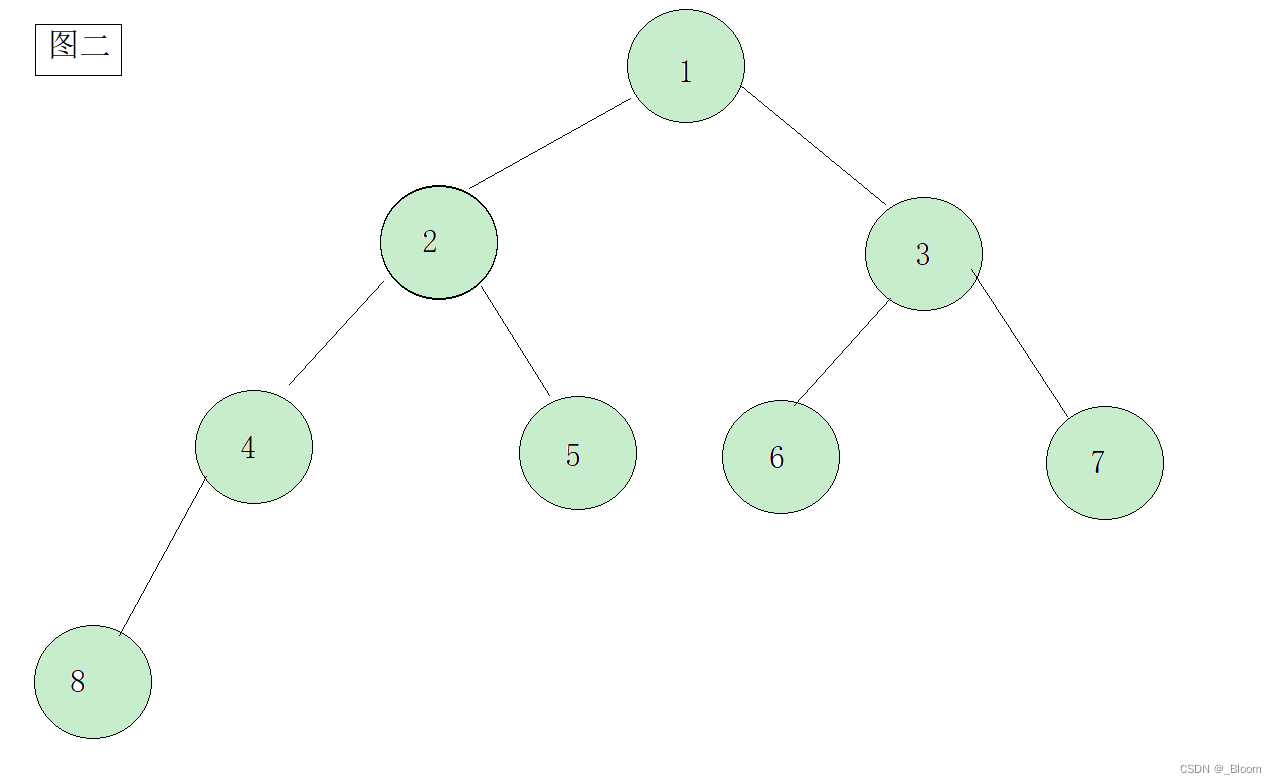
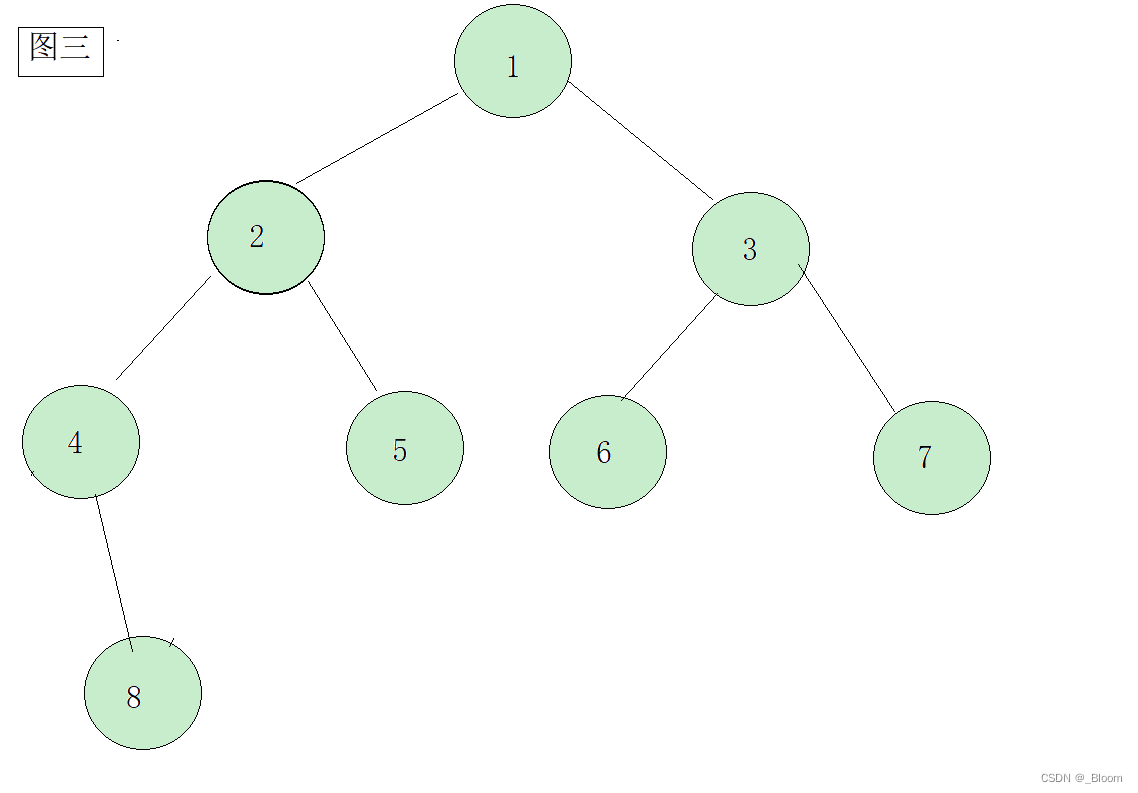
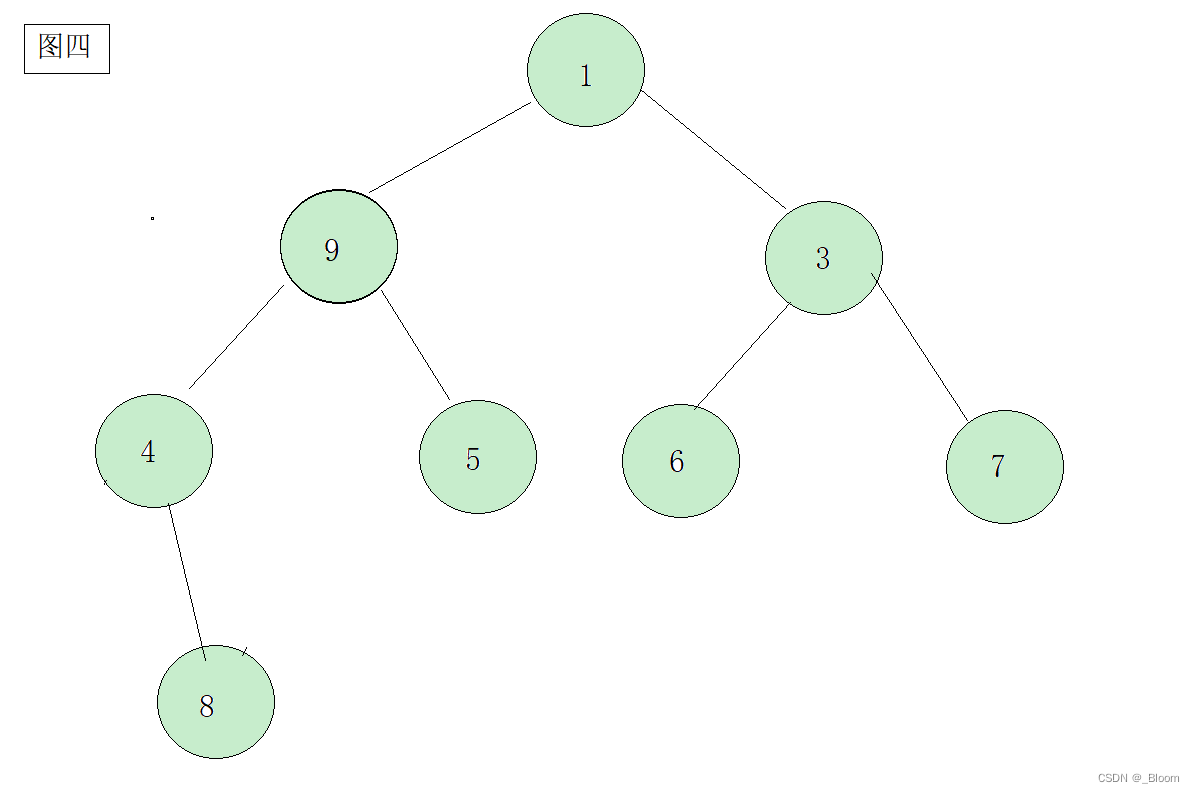
相信大家已经有了答案:图一:大堆 图二:小堆 图三:不是堆(图三不是完全二叉树) 图四:属于一般的堆,但既不是大堆也不是小堆
2.堆的存储与建立
2.1 堆的存储
我们一般把堆存储到数组中,但是非完全二叉树就不适合用数组结构存储,只适合于用链式结构
我们举个例子:
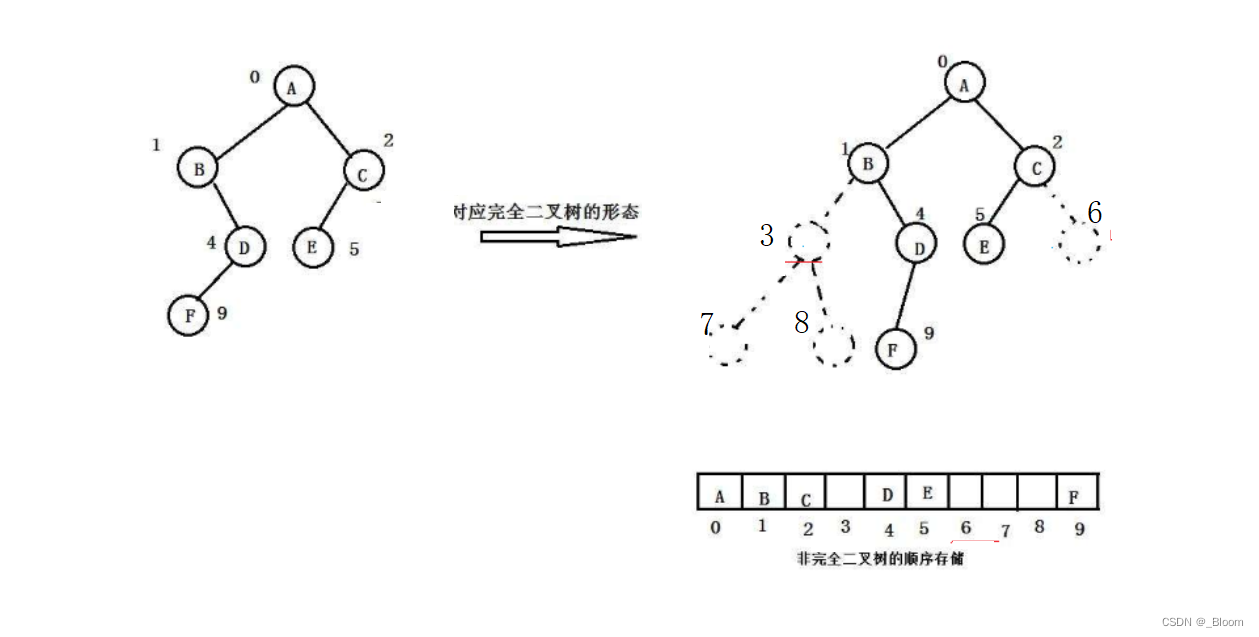
可以看见非完全二叉树存起来数组中有空缺的位置,这也是不适合的原因之一
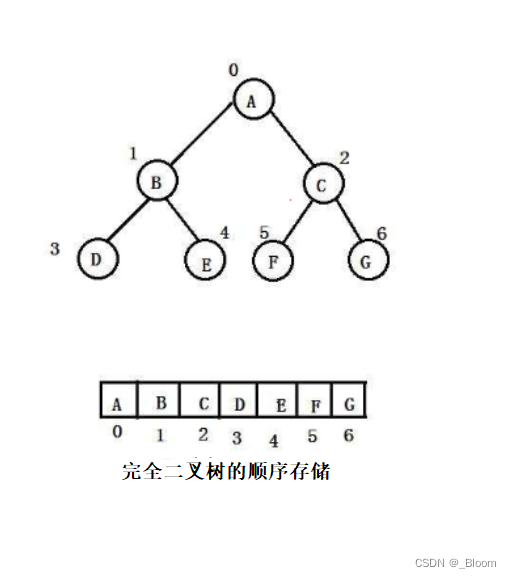
反之,我们可以发现堆不仅可以一层一层的进入数组,我们更是可以找到父亲节点与孩子节点之间下标的对应关系:

这是规律关系,并不是绝对关系,主要取决于编程者本身,比如说你不想下标为0的数组位置存节点,而是从下标为1的位置存节点,那么父子节点下标所具有的规律可能就发生了变化,但是大差不差。
2.2 堆的建立
说了这么多,那么大堆和小堆该如何建立起来呢?
我们采取两种方式来建立大堆(小堆类似)
a.向上调整算法建大堆
void AdjustUp(int *a,int child);
我们先把它的接口给出来,这个待传参的数组,我们假设为:
int a[5]={4,3,2,1,9}
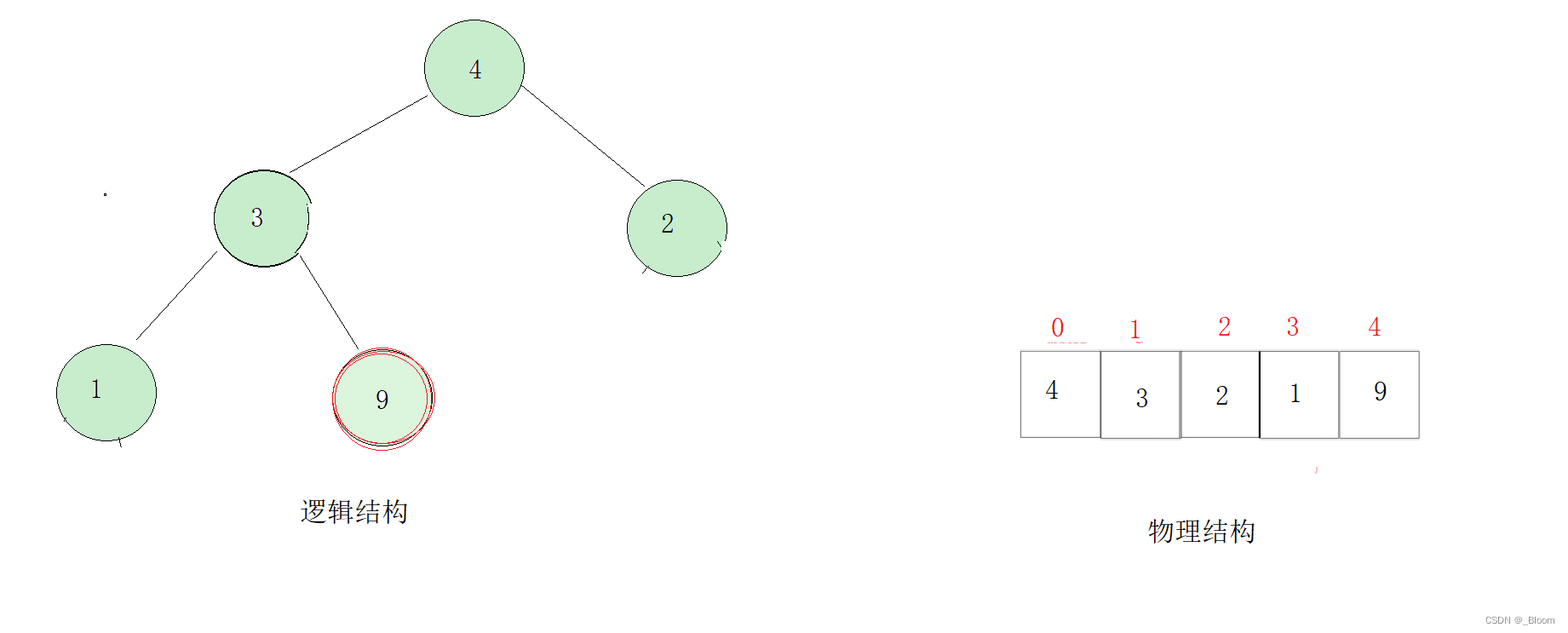
我们发现除了画红圈的元素,其他的元素组成的本身就是一个大堆,那么我们从9这个元素开始进行调整是不是就能把他都变成一个大堆呢?
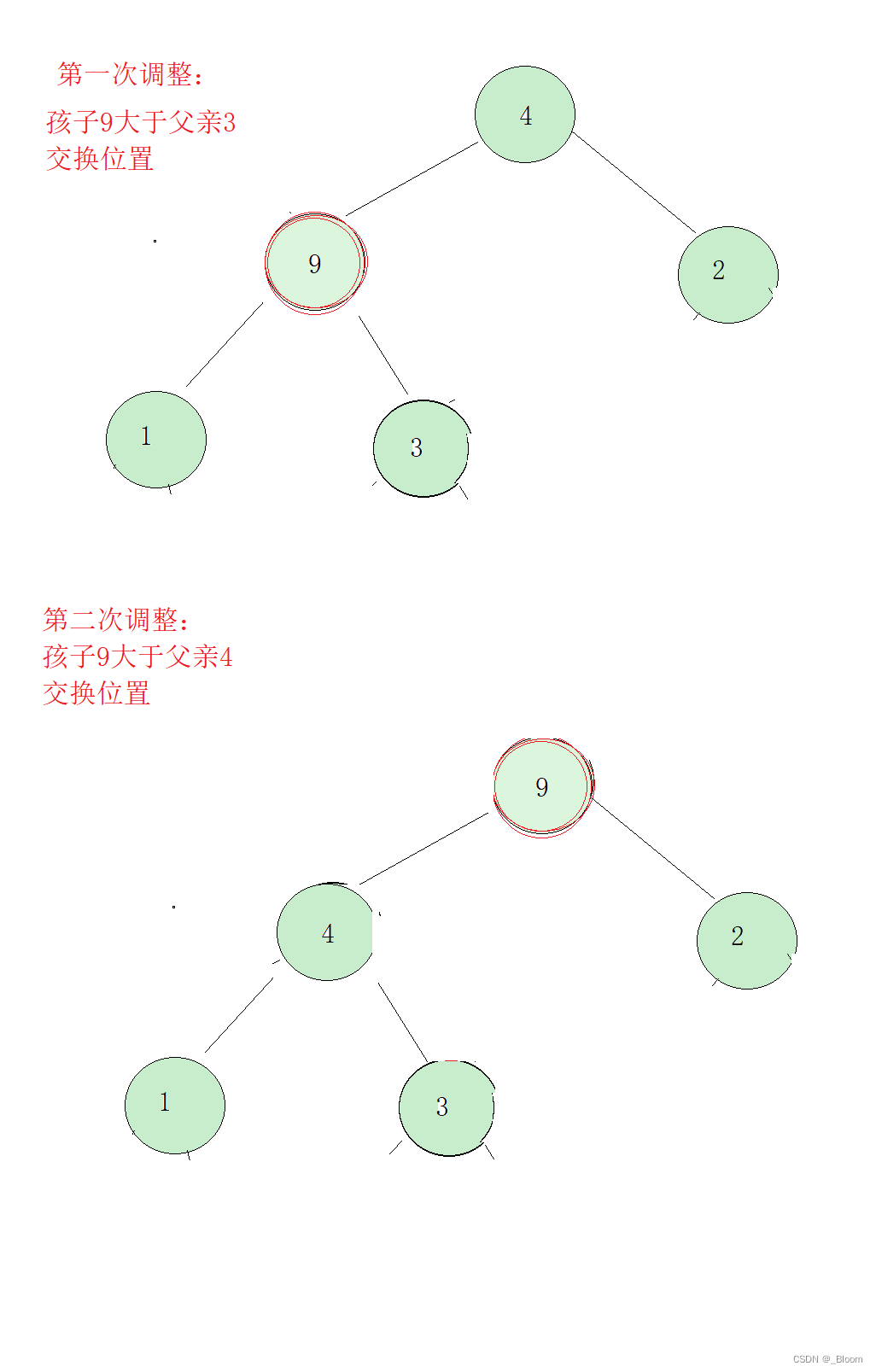
经过两次调整,我们惊奇的发现,整个堆都变成了一个大堆,但是我们调整的前提是除了那个最后一个元素之外,其他元素必须构成大堆,最后一个元素相当于插入大堆,再进行向上调整。那我们是不是可以默认第一个元素自己构成大堆,把数组从第二个元素依次插入,依次调整,以上是建立堆的思路,那我们先写一个向上调整算法。
void AdjustUp(HPDataType* a, int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[parent] > a[child])
{
Swap(&a[parent], &a[child]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
接下来我结合我举的例子解释一下:
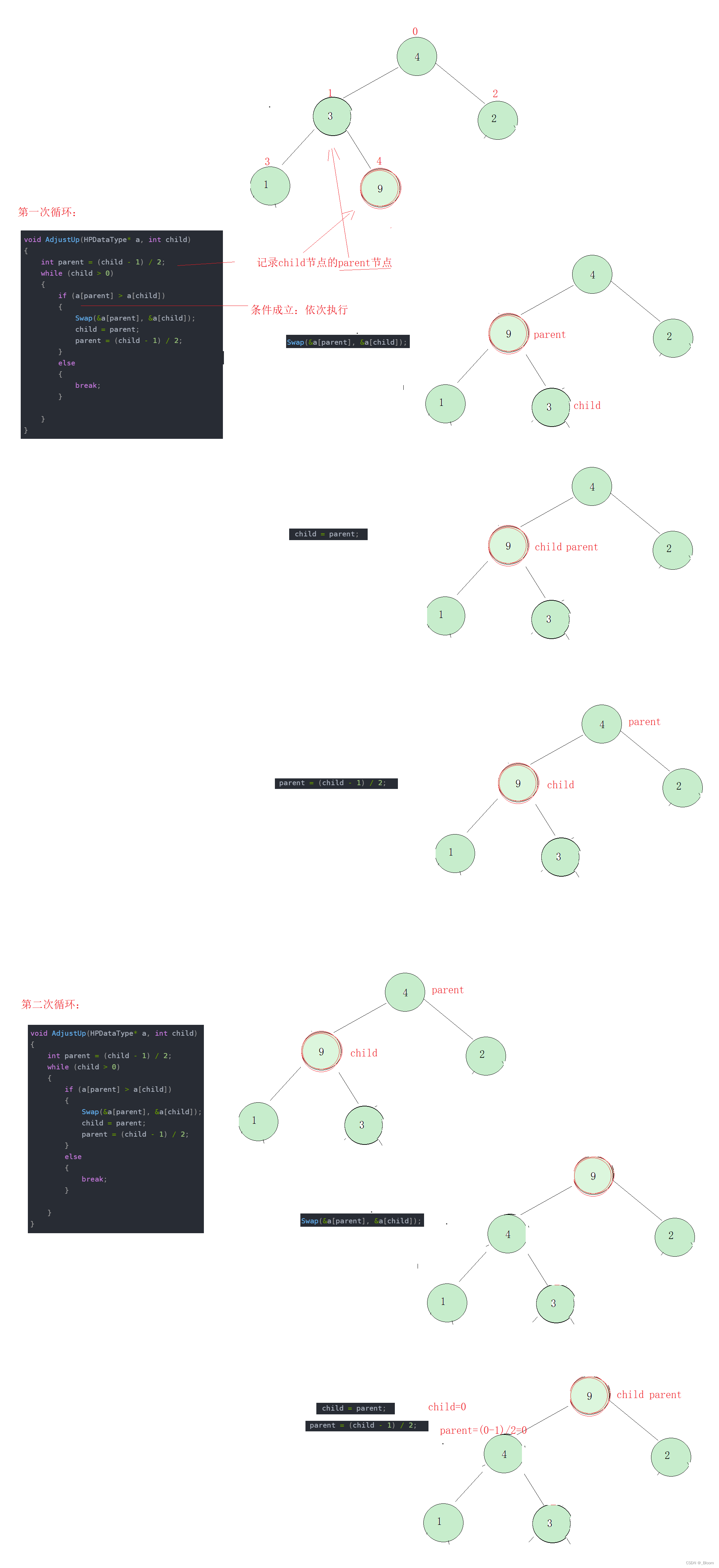
之后循环结束堆调整完毕
接下来就开始建堆:
for (int i = 1; i < n; i++)
{
AdjustUp(a, i);
}
默认第一个元素自己构成大堆,把数组从第二个元素依次插入,依次调整,以上是建立堆的思路,
如果不理解的话可以随意设置一个待建堆数组进行分析
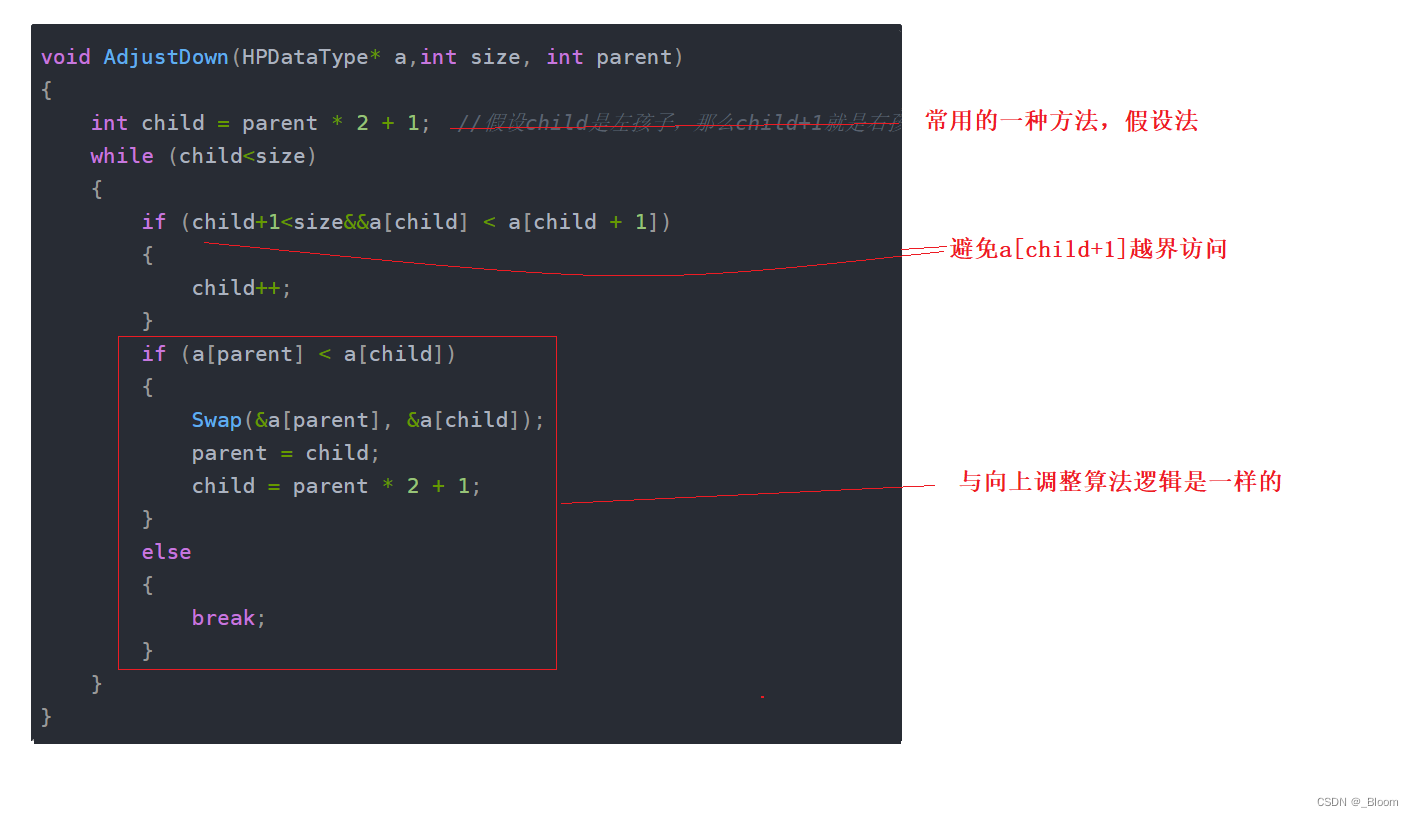
b. 向下调整算法建大堆
void AdjustDown(int *a,int size,int parent);
与向上调整算法类似,但是向下调整算法更加的常用,并且时间复杂度更低。因为后面的堆排序也要用到向下调整算法,因此要熟练掌握
向下调整算法建堆是比较有意思的,向下调整建堆也需要父亲节点的左右孩子都是堆,但从上往下不太容易处理,所以该算法建堆需要先找到最后一个节点的父亲
,从后面开始建堆
向下调整算法
void AdjustDown(HPDataType* a,int size, int parent)
{
int child = parent * 2 + 1; //假设child是左孩子,那么child+1就是右孩子
while (child<size)
{
if (child+1<size&&a[child] < a[child + 1])
{
child++;
}
if (a[parent] < a[child])
{
Swap(&a[parent], &a[child]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
向下调整算法建堆:
for(int i=(n-1-1)/2;i>=0;i--)
{
AdjustDown(a,n,i);
}
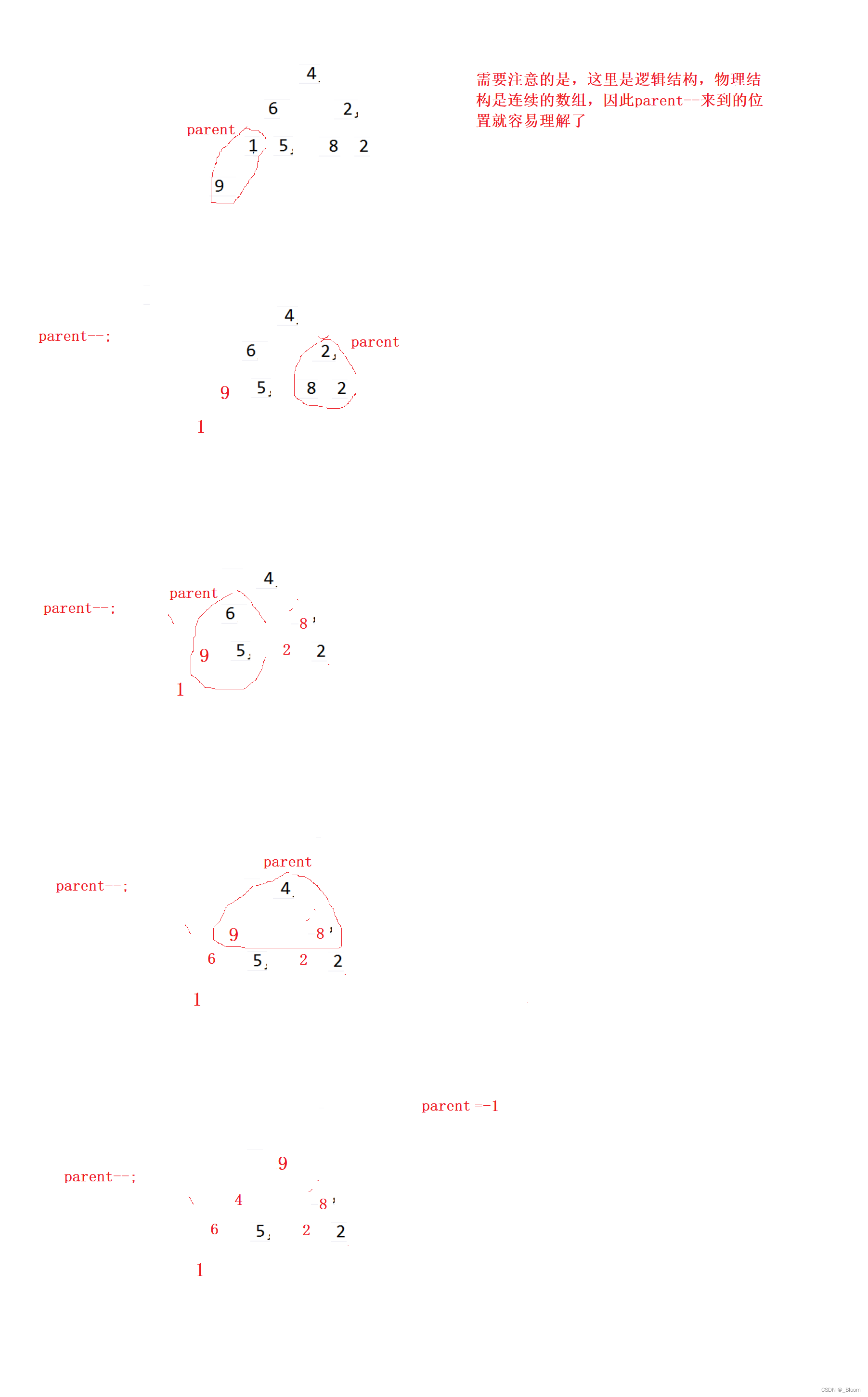
从上图可以看出,每次只处理一个圈里的问题,最后就迎刃而解了,而每一个红圈里使用的自然是向下调整算法。
这里解释一下i的初始值,(n-1)是最后一个节点(孩子)的下标,它的父亲下标是(n-1-1)/2。
二.堆排序代码及原理
实现堆排序很简单,在此之前我们必须要知道实现升序应该建立大堆还是小堆呢?
与想象的不同,实现升序应该建立大堆
试想一下,如果我们建立了小堆,我们确实找到了最小的数,但是这个数位于数组下标为0的位置,也许我们可以采取下面这种不太可靠的措施:
把最小的数存入另一个数组,把剩下的数重新建堆找到次小的数放入数组…这个方法问题很明显:1.消耗太大了 2.说好的排序,我们好像并没有直接对原数组排序,只是以升序的方式将元素存入另一个数组,违背了排序的初衷
因此这里建立大堆是比较合适的:
大堆的优势在哪里呢?
在于最大的元素在数组头上,我们可以将最后一个元素与数组头交换,这就实现了最大的元素在最后面,试想一下,头上的元素不好处理,尾上的元素还不好处理吗?我们可以将元素个数减一,不处理最后一个元素,因为最后一个元素相当于排好序了,
void HeapSort(int* a, int n)
{
// 建大堆
// O(N*logN)
/*for (int i = 1; i < n; i++)
{
AdjustUp(a, i);
}*/
// O(N)
for (int i = (n-1-1)/2; i >= 0; --i)
{
AdjustDown(a, n, i);
}
int end = n - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
--end;
}
}
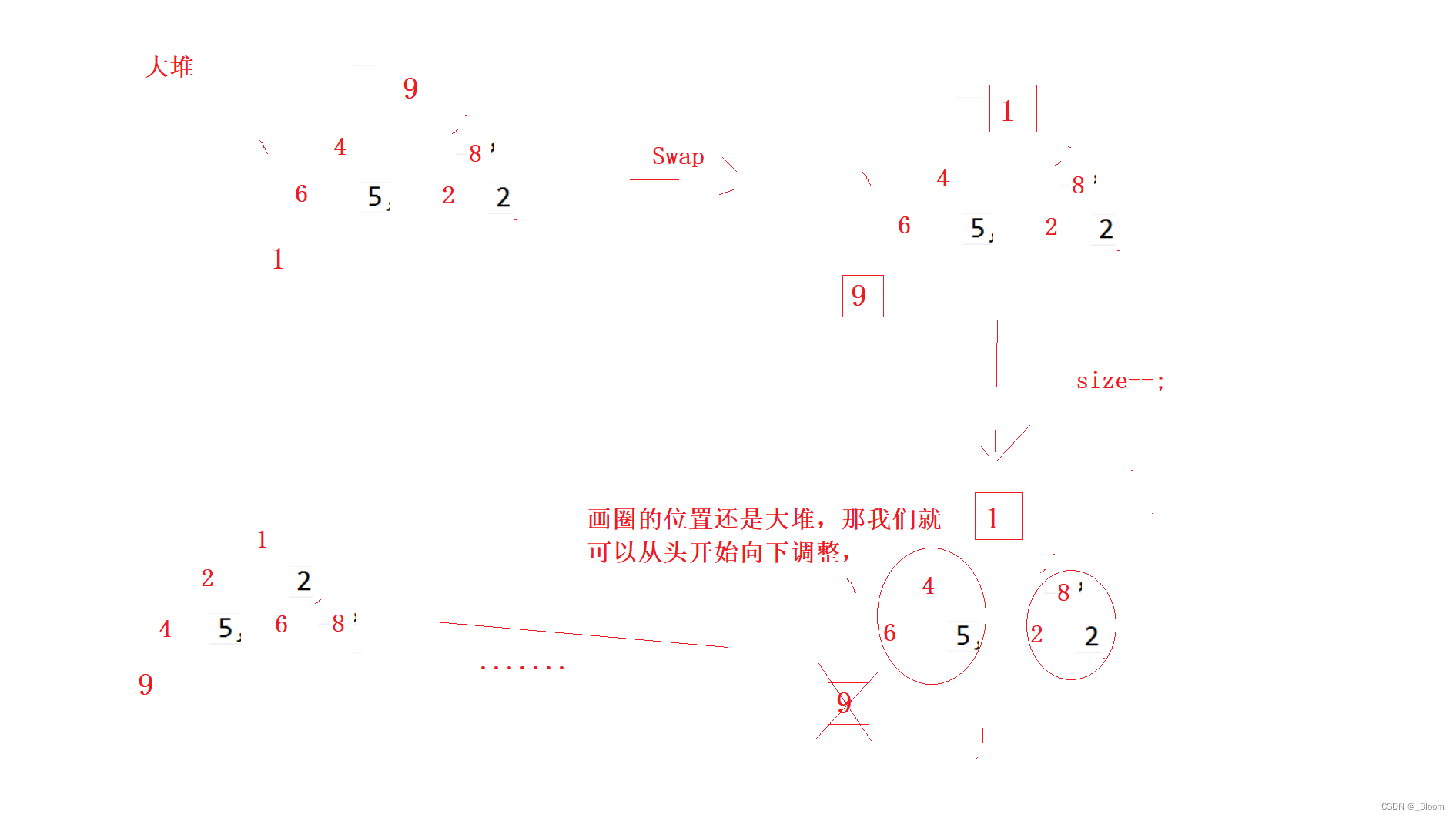
以上便是堆排序的代码及解释,主要还是要知道升序建大堆,降序建小堆。而堆排序主要就是分为建堆和选数两个过程。
三.堆排序的时间复杂度
堆排序的时间复杂度是O(n*logn)
(具体计算等八大排序写完,再一起写计算过程)
编程路上,愿你越走越远,收获满载而归。















 2753
2753











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









