







整体思路:
确定一个key值,将比key大的值放到key右边,比key小的值放到key左边,key在中间,这样key的位置就已经排好了,我们就只需要将key左右两边的数组用同样的方法进行排序,到最后分割出的数组只剩一个元素时,整个数组就变得有序了。
对数组的不断分裂再用相同的方法进行排序后再分裂,听起来有点递归的意思,我们这里用递归和非递归两种方式来实现快速排序。
单趟排序:
直接从图上来理解

单趟排序代码这样写:

由于我们会用到keyi对数组进行分割,所以函数要设定返回值
先测试一下单趟排序:
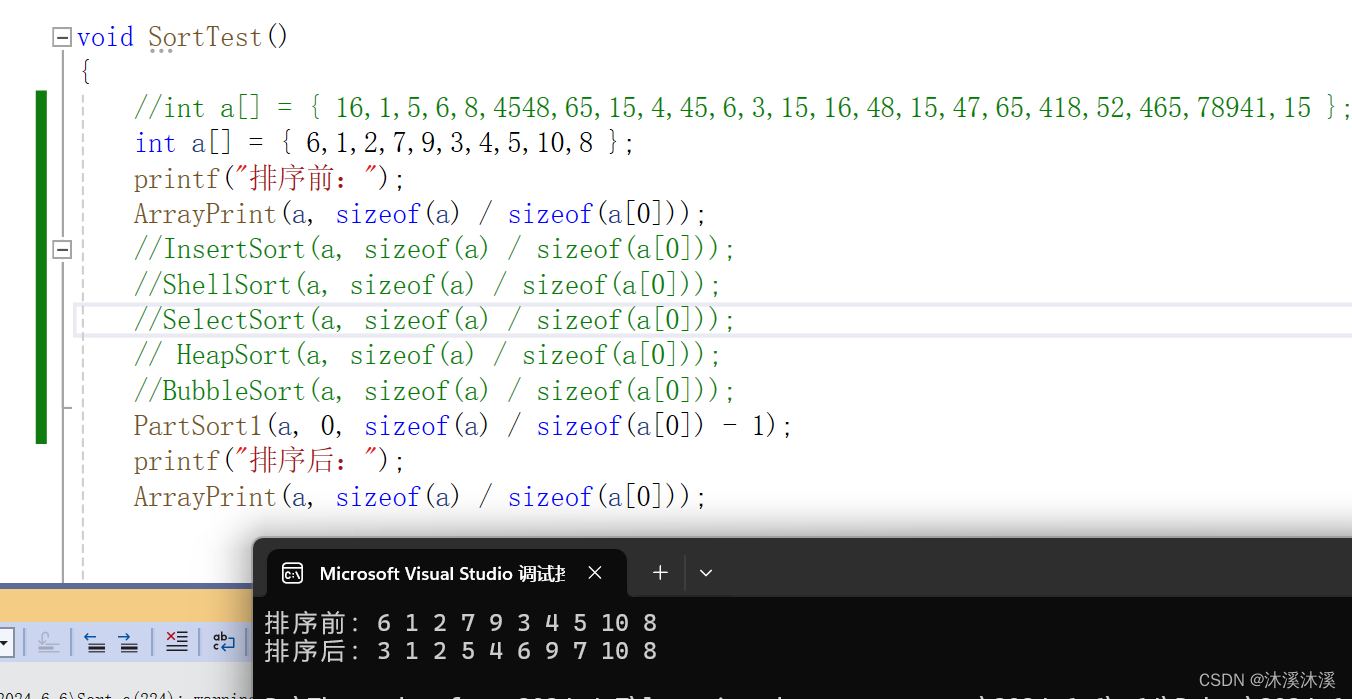
与图示结果相同,所以单趟排序没有问题
递归实现:
单趟排序完成后,我们就可以开始尝试递归实现快速排序。


如果是学过二叉树的各种操作的,这个递归应该很容易理解
每次调用快速排序都会把传入数组部分的key位置找好,然后再分割成两个数组再次递归,直至left>=right层层返回,排序结束。
这样一个简易版的快速排序就实现完成了 。
递归的缺陷及优化
缺陷一:可能有栈溢出风险
所有递归都有递归深度过高会导致有栈溢出的风险,快速排序一般用在大量数据的排序场景下。在极端一点的情况下,这份n组数据本来就是有序的,导致的情况就是快速排序需要递归n次,不仅效率大大降低,而且还可能导致栈溢出。
优化:三数取中
这里是对快速排序的key值做了优化,取left,mid,right三个位置的值的中位数作为key,把它交换到最左边的位置,来进行快速排序。这样就算在极端情况下快速排序仍能保持很高的效率。
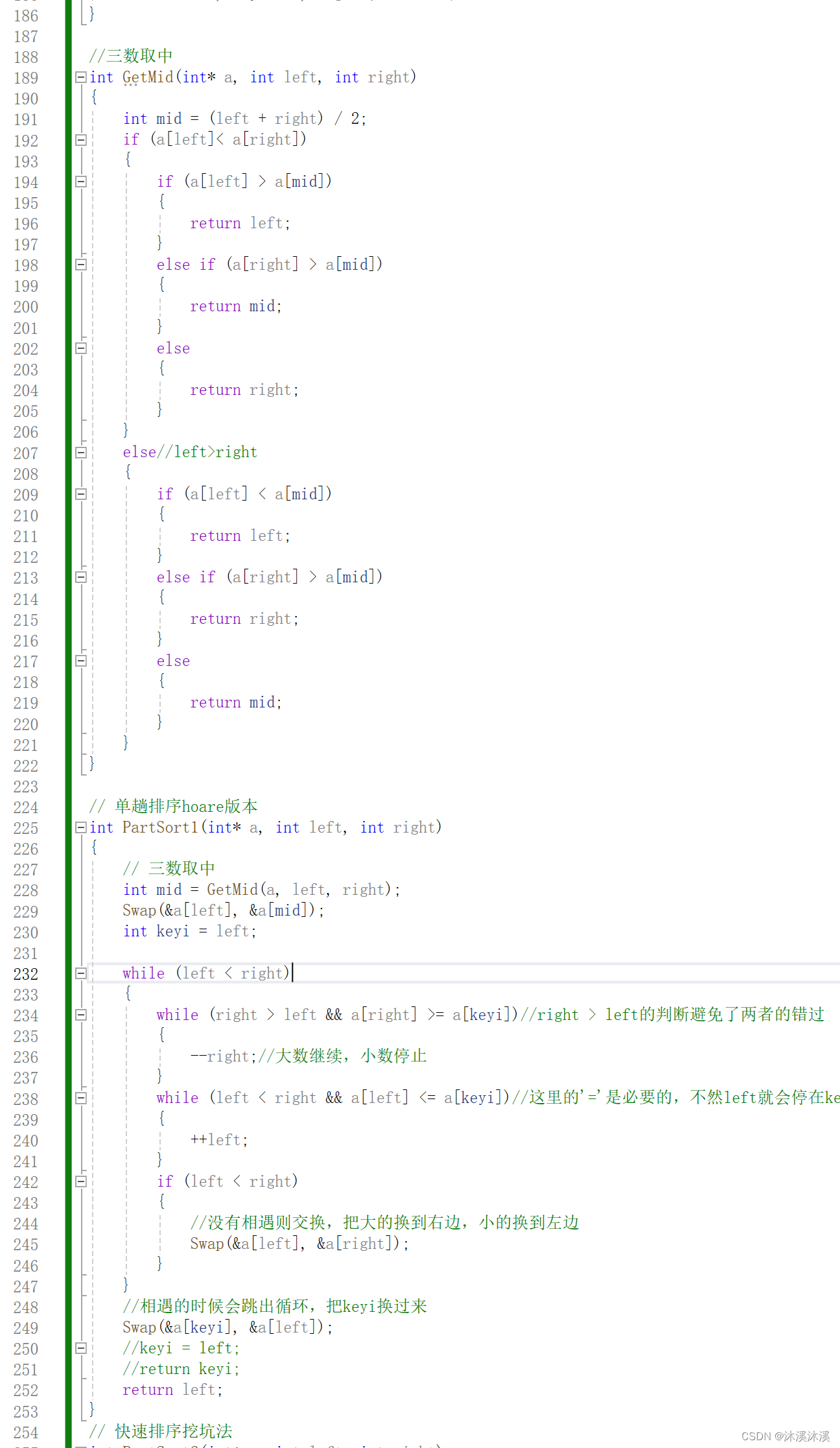
这里记得还要修改单趟排序,把得到的key换到最左边
缺陷二:递归的底层排序效率不高
递归越往后递归调用的自身函数次数就越多,而快速排序的递归会切断数组,到递归到一定深度时,数组长度不长,但是却要递归不少次,这样使用快速排序反而会使效率降低。

优化:小区间优化
我们可以考虑在数组分裂到一定程度的时候使用其他的排序算法来优化快速排序。
排序很快的方法还有堆排序和希尔排序,但是数组元素很少的时候,我们也没有必要建堆和进行预排序,所以我们只需要进行直接插入排序即可。(直接插入排序要优于冒泡排序和选择排序)

单趟排序的其他方法:
前面介绍的单趟排序方法是hoare首先创造快速排序时使用的方法,另外还有挖坑法和前后指针法等等,三种方法只是角度的不同,效率并没有什么区别,这里给出代码,就不详细介绍了。


快速排序的非递归实现:
不管怎么说,递归实现的快速排序始终是有栈溢出的风险的。函数调用会在栈区申请空间建立函数栈帧,而内存中栈区很小。相比而言我们可以利用栈(数据结构的栈)来模拟递归实现非递归的快速排序。
思路:建立循环,将分割的下标按顺序入栈存储再出栈调用
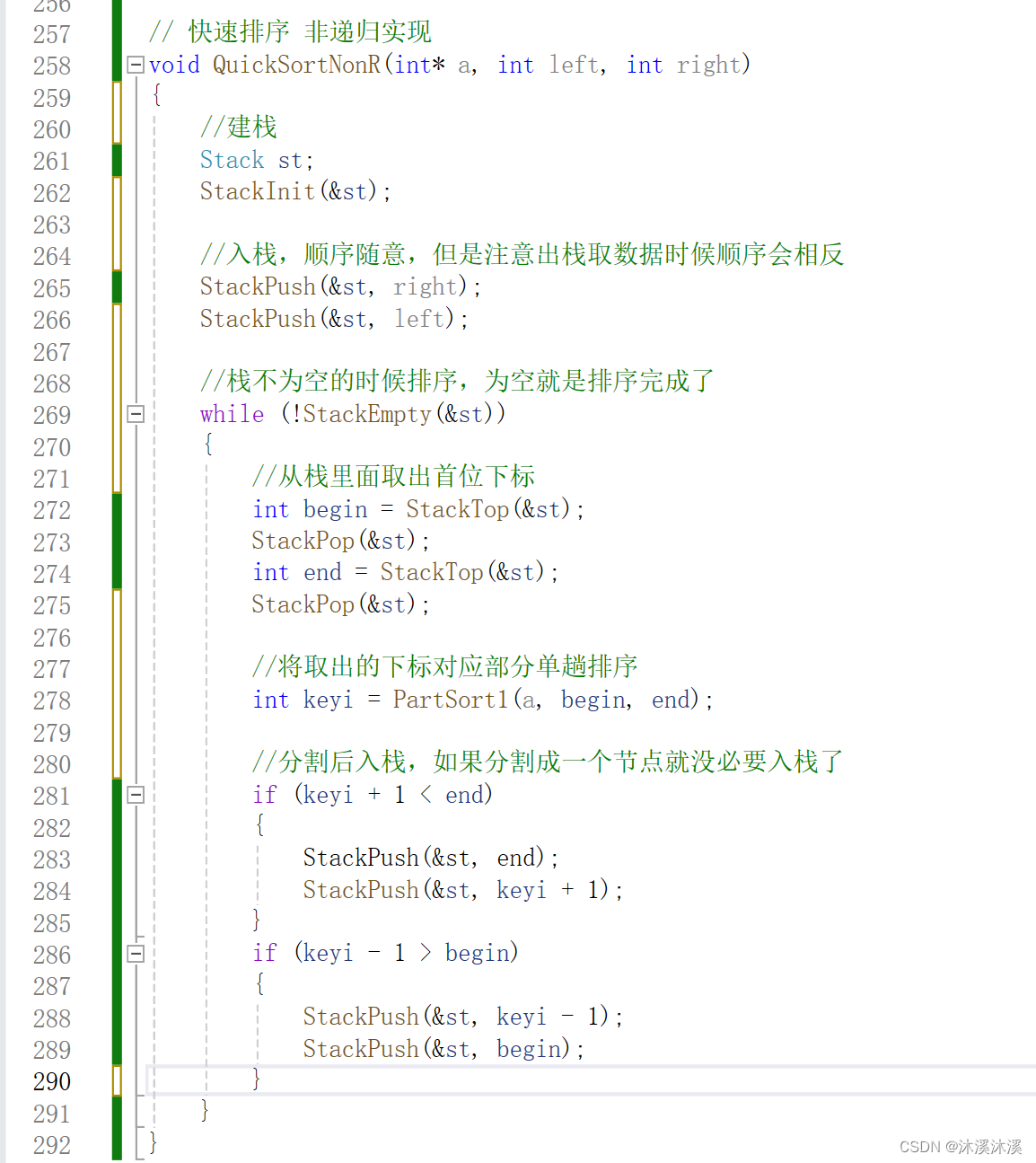
其实非递归用队列也是可以的,大家可以自己尝试一下,只不过是遍历的顺序不一样,栈是深度优先,队列为广度优先。
好了,我郑重宣布,快速排序优雅地完成了......















 1228
1228











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









