






 本文详细介绍了数据仓库的概念,与数据库的区别,数据仓库的分层架构,以及数据仓库ETL操作的四个关键步骤,包括数据抽取、清洗、转换和加载。同时涵盖了数据库表操作的相关知识,如创建表、内部表和外部表的区别,以及Hive中的表操作技巧。
本文详细介绍了数据仓库的概念,与数据库的区别,数据仓库的分层架构,以及数据仓库ETL操作的四个关键步骤,包括数据抽取、清洗、转换和加载。同时涵盖了数据库表操作的相关知识,如创建表、内部表和外部表的区别,以及Hive中的表操作技巧。
目录
数据仓库和数据库
一、什么是数据仓库和数据库
数据库:是一种逻辑概念,用来存放数据的仓库,通过数据库软件来实现。数据库由很多表组成,表是二维的,一张表里面有很多字段。字段一字排开,对数据就一行一行的写入表中。数据库的表,在于能够用二维表现多维的关系。如:oracle、DB2、MySQL、Sybase、MSSQL Server等。
数据仓库:数据仓库(Data Warehouse),可简写为DW或DWH,数据仓库,是为了企业所有级别的决策制定计划过程,提供所有类型数据类型的战略集合。它出于分析性报告和决策支持的目的而创建。为需要业务智能的企业 ,为需要指导业务流程改进、监视时间、成本、质量以及控制等。
数据仓库主要特征:
面向主题的(Subject-Oriented )、集成的(Integrated)、非易失的(Non-Volatile)和时变的(Time-Variant )
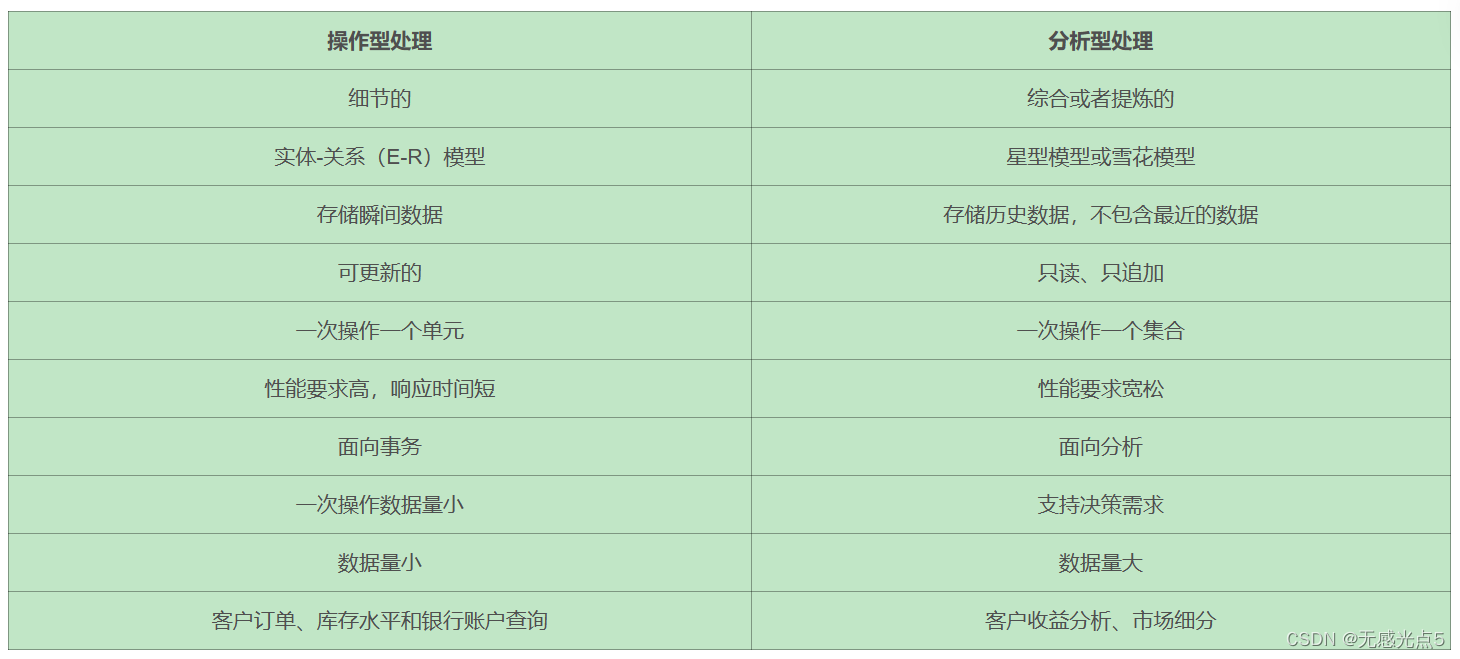
二、数仓和数据库的区别
*注:数据库与数据仓库的区别实际讲的是OLTP与OLAP的区别
- 操作型处理(数据库),叫联机事务处理OLTP(On-Line Transaction Processing),也可以称面向用户交易的处理系统,它是针对具体业务在数据库联机的日常操作,通常进行增删改查操作。用户较为关心操作的响应时间、数 据的安全性、完整性和并发支持的用户数等问题。传统的数据库系统作为数据管理的主要手段,主要用于操作型处理。
- 分析型处理(数据仓库),叫联机分析处理OLAP(On-Line Analytical Processing),也可以称为面向专业分析
人员进行数据分析,通常进行查询分析操作,一般针对某些主题的历史数据进行分析,支持管理决策。
数据仓库,是在数据库已经大量存在的情况下,为了进一步挖掘数据资源、为了决策需要而产生的。
数据仓库的出现,并不是要取代数据库,主要区别如下:
数据库是面向事务的设计,数据仓库是面向主题设计的。
数据库一般存储业务数据,数据仓库存储的一般是历史数据。
数据库是为捕获数据而设计,数据仓库是为分析数据而设计
数据库设计是尽量避免冗余,一般针对某一业务应用进行设计,比如一张简单的User表,记录用户名、密码等简单数据即可,符合业务应用,但是不符合分析。
数据仓库在设计是有意引入冗余,依照分析需求,分析维度、分析指标进行设计。
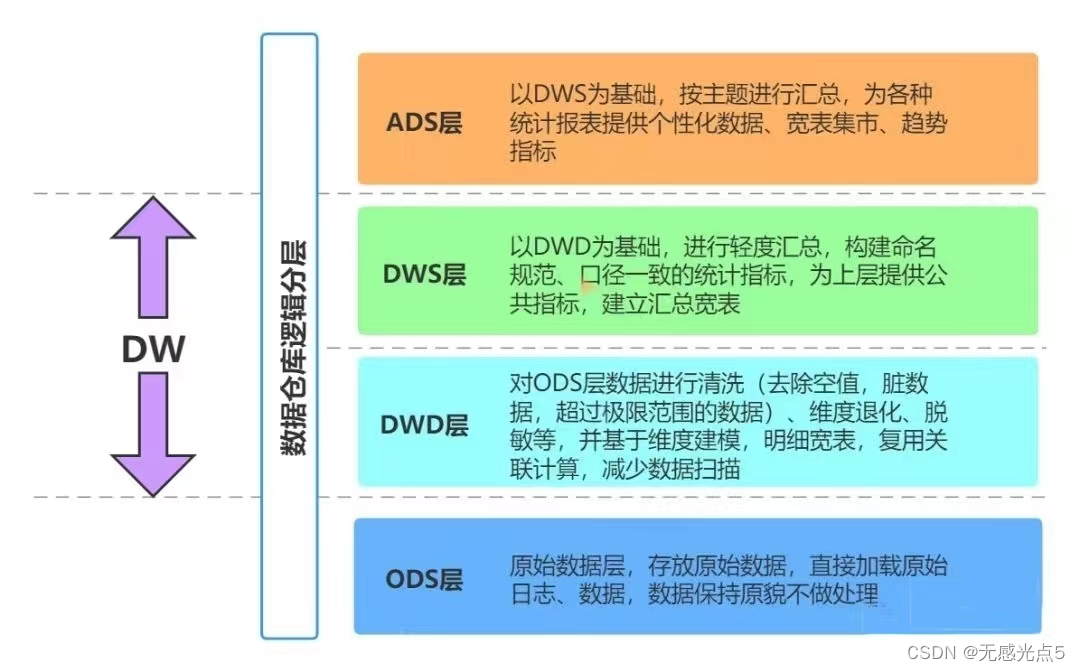
三、数据仓库的分层架构
数据仓库架构可分为三层——源数据层、数据仓库层、数据应用层
源数据层(ODS):此层数据无任何更改,直接沿用外围系统数据结构和数据,
不对外开放;为临时存储层,是接口数据的临时存储区域,为后一步的数据处理做准备。
数据仓库层(DW):也称为细节层,DW层的数据应该是一致的、准确的、干
净的数据,即对源系统数据进行了清洗(去除了杂质)后的数据。
数据应用层(DA或APP):前端应用直接读取的数据源;根据报表、专题分析需求而计算生成的数据。

四、数据仓库(ETL)的四个操作
ETL(extractiontransformation loading)负责将分散的、异构数据源中的数据抽取到临时中间层后进行清洗、转换、集成,最后加载到数据仓库或数据集市中。ETL 是实施数据仓库的核心和灵魂,ETL规则的设计和实施约占整个数据仓库搭建工作量的 60%~80%。
1)数据抽取(extraction)包括初始化数据装载和数据刷新:初始化数据装载主要关注的是如何建立维表、事实表,并把相应的数据放到这些数据表中;而数据刷新关注的是当源数据发生变化时如何对数据仓库中的相应数据进行追加和更新等维护(比如可以创建定时任务,或者触发器的形式进行数据的定时刷新)。
2)数据清洗主要是针对源数据库中出现的二义性、重复、不完整、违反业务或逻辑规则等问题的数据进行统一的处理。即清洗掉不符合业务或者没用的的数据。比如通过编写hive或者MR清洗字段中长度不符合要求的数据。
3)数据转换(transformation)主要是为了将数据清洗后的数据转换成数据仓库所需要的数据:来源于不同源系统的同一数据字段的数据字典或者数据格式可能不一样(比如A表中叫id,B表中叫ids),在数据仓库中需要给它们提供统一的数据字典和格式,对数据内容进行归一化;另一方面,数据仓库所需要的某些字段的内容可能是源系统所不具备的,而是需要根据源系统中多个字段的内容共同确定。
4)数据加载(loading)是将最后上面处理完的数据导入到对应的存储空间里(hbase,mysql等)以方便给数据集市提供,进而可视化。
数据表操作
一、创建数据库表语法
• EXTERNAL,创建外部表
• PARTITIONED BY, 分区表
• CLUSTERED BY,分桶表
• STORED AS,存储格式
• LOCATION,存储位置...
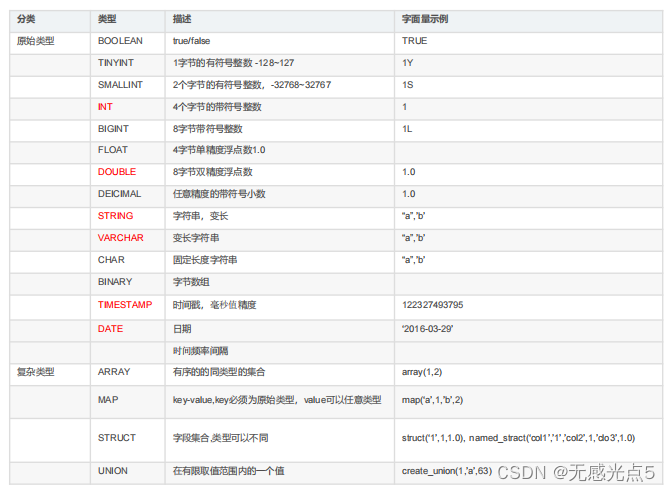
数据类型:
*注:其中红色是使用比较多的类型
二、内部表和外部表
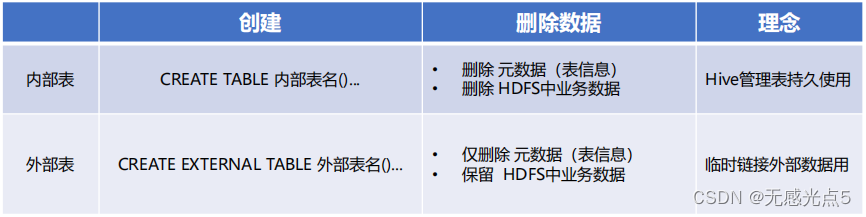
Hive中可以创建的表有好几种类型, 分别是:
• 内部表(MANAGED_TABLE)
• 分区表
• 分桶表
• 内部表(CREATE TABLE table_name ...)
未被external关键字修饰的即是内部表,内部表又称管理表或者托管表。
删除内部表:直接删除元数据和存储的业务数据
创建内部表: create table [if not exists] 内部表名(
字段名 字段类型 , ...
)...;
复制内部表:
复制表结构: CREATE TABLE 表名 like 存在的表名;
复制表结构和数据: CREATE TABLE 表名 as select语句;
删除内部表: drop table 内部表名;
查看表格式化信息:desc formatted 表名;
truncate清空内部表数据: truncate table 内部表名;
• 外部表(EXTERNAL_TABLE)
• 分区表
• 分桶表
• 外部表(CREATE EXTERNAL TABLE table_name ...)
被external关键字修饰的即是外部表,外部表又称非管理表或者非托管表。
删除外部表:仅仅是删除元数据,存储的业务数据并不会被删除
三、查看修改表
查看:
查看所有表:
show tables;
查看建表语句:
show create table 表名;
查看表结构信息:
desc 表名;
查看表格式化信息:
desc formatted 表名;
修改:
修改表名:
alter table 旧表名 rename to 新表名;
修改表路径:
alter table 表名 set location 'hdfs中存储路径';
*注: 建议使用默认路径
修改表属性:
alter table 表名 set tblproperties ('属性名'='属性值');
内外部表转换
• 内部表转外部表
alter table stu set tblproperties('EXTERNAL'='TRUE');
• 外部表转内部表
alter table stu set tblproperties('EXTERNAL'='FALSE');
通过stu set tblproperties来修改属性
*注:('EXTERNAL'='FALSE') 或 ('EXTERNAL'='TRUE')为固定写法,区分大小写!
一些小知识点
1. 创建库的语法为
CREATE DATABASE [IF NOT EXISTS] db_name [LOCATION position];
2. 删除库的语法为
DROP DATABASE db_name [CASCADE];
3. 数据库和HDFS的关系
- Hive的库在HDFS上就是一个以.db结尾的目录
- 默认存储在:/user/hive/warehouse内
- 可以通过LOCATION关键字在创建的时候指定存储目录
4.在HDFS的表默认存储路径:
/user/hive/warehouse/库名.db
5.查看表类型和详情:
DESC FORMATTED 表名;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









