






前言
本次笔记来源于学习Datawhale AI夏令营的记录概要,纯私人记录,部分公式推导图片来源于其他帖子。
资料链接:Datawhale-学用 AI,从此开始
3.1 基本形式
给定由d个属性描述的示例,其中
是x在第i个属性上的取值,线性模型(linear model)试图学得一个通过权重向量
和偏置项
的线性组合来进行预测的函数,即
一般用向量形式写成
许多功能更为强大的非线性模型(nonlinear model)可在线性模型的基础上通过引入层级结构或高维映射而得。此外,由于直观表达了各属性在预测中的重要性,因此线性模型有很好的可解释性(comprehensibility)。
3.2 一元线性回归
3.2.1最小二乘估计
基于均方误差最小化来进行模型求解的方法称为“最小二乘法”
我们可以将分别对
和
求导,得到
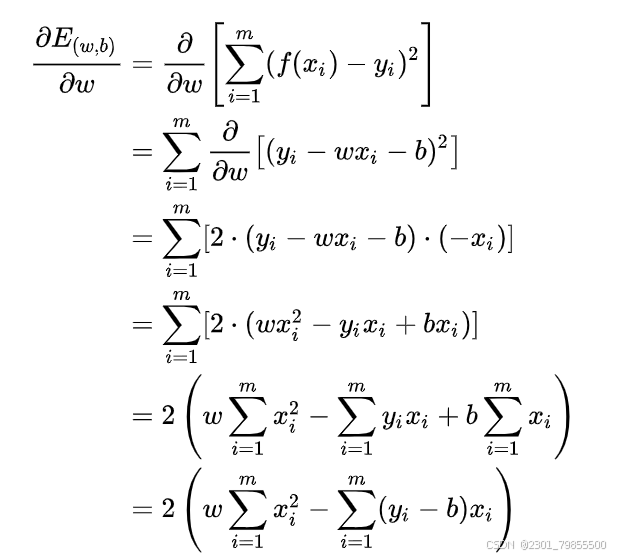
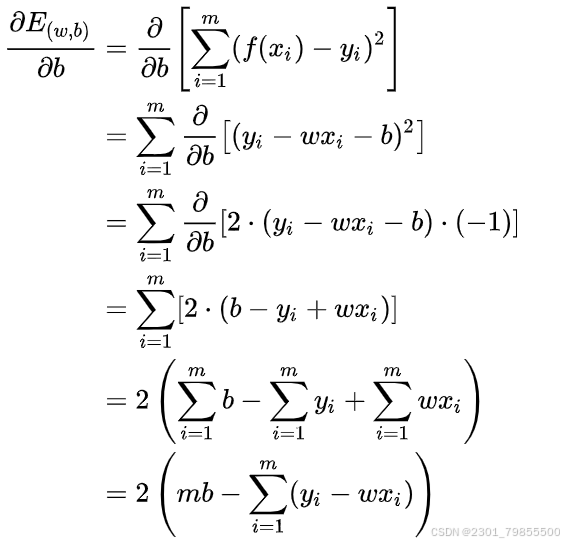
然后令两式为零可以得到 和
最优解的闭式
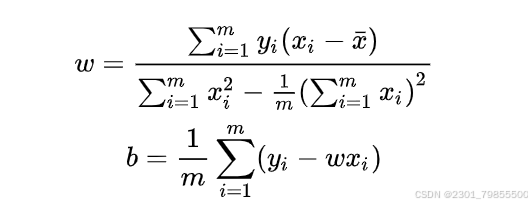
3.2.2 极大似然估计
用途:估计概率分布的参数值
方法:对于离散型、连续型随机变量X,假设其概率质量函数为,其中
为待估计的参数值(可以有多个),现有
是来自X的n个独立样本,他们的联合概率为
其中 是已知量,
是未知量,因此上述概率是一个关于
的函数,称为样本的似然函数。
机器学习三要素
1.模型:根据具体问题,确定假设空间
2.策略:根据评价标准,确定选取最优模型的策略(通常会产生一个“损失函数”)
3.算法:求解损失函数,确定最优模型
3.3 多元线性回归
在前文公式推导中,我们把 和
写入向量形式:
,相应地,把数据集D表示为一个
大小的矩阵,其中每行对应于一个示例,该行前d个元素对应于示例的d个属性值,最后一个元素恒置为1,即
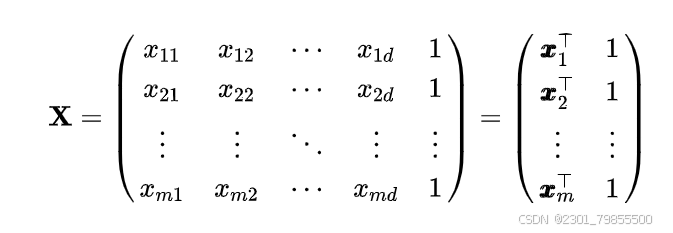
因此可得:
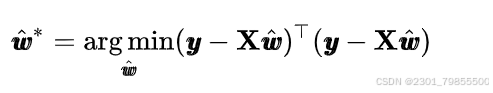
接下来我们求导可得
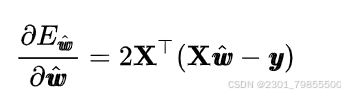
将其展开可得
![]()
求导得
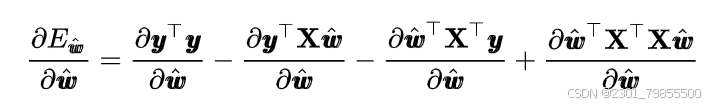
由矩阵微分式![]() 可得
可得

则最终学得的多元线性回归模型为
![]()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









