






 本文介绍了哈希表的基本概念,包括其定义、哈希思想的应用、哈希函数、键值对、哈希冲突的解决方法以及如何通过顺序表加链表实现哈希表。重点展示了如何通过哈希表提高查找效率,对比了与数组下标的区别。
本文介绍了哈希表的基本概念,包括其定义、哈希思想的应用、哈希函数、键值对、哈希冲突的解决方法以及如何通过顺序表加链表实现哈希表。重点展示了如何通过哈希表提高查找效率,对比了与数组下标的区别。
一、哈希表的引入:
在顺序表和链表的数据里查找一个数字的时候,我们通常会用到“遍历”,时间复杂度为O(n)。如果查找的数据是一个排好序的,那么我们还可以用“二分查找法”,时间复杂度为O(logn)。
那么是否存在一种数据结构,能够实现效率更高的查找算法呢。我们现在已知的数据结构有”二叉搜索树”,时间复杂度为O(logn)。我们不妨再胆大些。会不会有一种数据结构在实现查找算法时,时间复杂度能够达到O(1)呢?而这便是我们的哈希表。
二、哈希表的定义:
在了解哈希表之前我们现在了解一下什么是数组映射
二-1.哈希思想的具体体现:
1.通过哈希思想快捷的得出具体月份的具体天数
相信大家在学习编程基础的时候一定写过从某月的某天到某月的某天一共有多少天吧。
初学的时候我相信很多人都是通过switch-case语句来写。

费事费力还不讨好,不知不觉把12个月份都表示完了就花了50行代码。今天我们可以学习一种新的代码,不仅代码少,更可以增加复用性。使得代码更加美观。
我们不妨把月份1,2.....看成我们要查找的值,即我们需要知道几月有几天。通过查找的数据快速的到对应存储数据的地址直接拿走数据。其实这就是哈希表

可以看到如果我们想要一月份的天数其实就是month[ 1 ] = 31,同理三月份的就是month[ 3 ] = 31,这就是哈希思想带来的便捷性。并且如果年份是闰年的时候我们还可以这么写

短短几行代码就可以代替掉switch-case语句50行的代码,并且如果年份是闰年的话通过以上操作更可以增加代码的复用性。这就是哈希思想带来的好处。
2.通过哈希的思想直接了解某个数字出现的次数
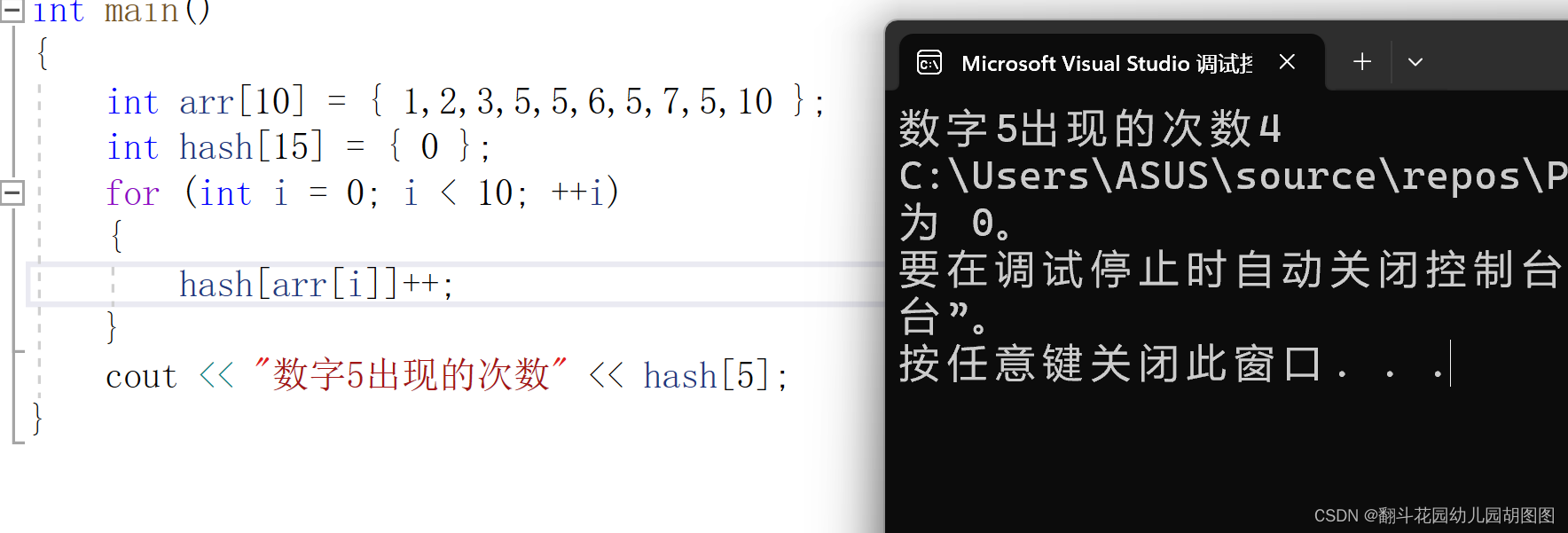
数字5数字出现的次数就是hash[5]的数据。这也是哈希思想的直观体现。
接下来我们就来系统的了解一下哈希表的概念
二、2.哈希表的概念
哈希表又称散列表,能够通过键值直接访问到要查找数据的内存空间这个过程又叫做哈希。我们要查找的数据本身其实就是一个关键字,通过一种函数映射将关键字变为键值即哈希值,而函数映射又叫做哈希函数。
那么实际存储数据的地址又称为哈希地址。可以直接理解为数组的下标。那么存储这些数据的表就成为哈希表。如下图。

以上便是哈希表的定义,只通过字面意思理解稍有难度,其实总结一下就是通过数组的下标直接访问数据。而这也是为什么哈希表的时间复杂度为O(1)。但是又和数组的下标访问数据的含义不同,因为此时的数组下标有了新的含义。例如具体的年份,具体的月份,或者某个字符串等等。
3.键值对的概念
键(key)就像上面的月份,其实就是键,但是键不止有整形,还有浮点型。比如我们还会遇到查找某个字符串出现的次数,那么这个时候的键就是字符串类型了。值就是对应存储空间存储的值。就像月份的具体天数。
但是在底层代码里,哈希表的实现通常是用顺序表实现的,因此键值一般情况下会通过哈希函数把他转化为整形,这样就可以通过数组下标直接访问从而达到O(1)的时间复杂度
4.哈希函数的概念
哈希函数我们可以直接抽象的理解为f(x) = x^2;其实就是通过某种特定的关系将我们要查找的数据转换我们需要的数据例如我们想要知道对3取模余几的数有几个,那么我们的哈希函数实现的过程就是hashkey = key%3。
但是我们这时候就会发现一个问题那就是不同的数据所形成的键值可能会相同例如8和5对3取模都是2,倘若此时我们不想知道对3取模余几的数有几个,而是想要通过这种哈希函数,存储键为8值为37。和键为5值为27时。这是就会发生冲突,这种冲突就叫哈希冲突。
5.哈希冲突的解决
为了解决哈希冲突我们可以采用顺序表加链表两种方式存储。怎么存储呢?还是用上面的数据,可以看如下图
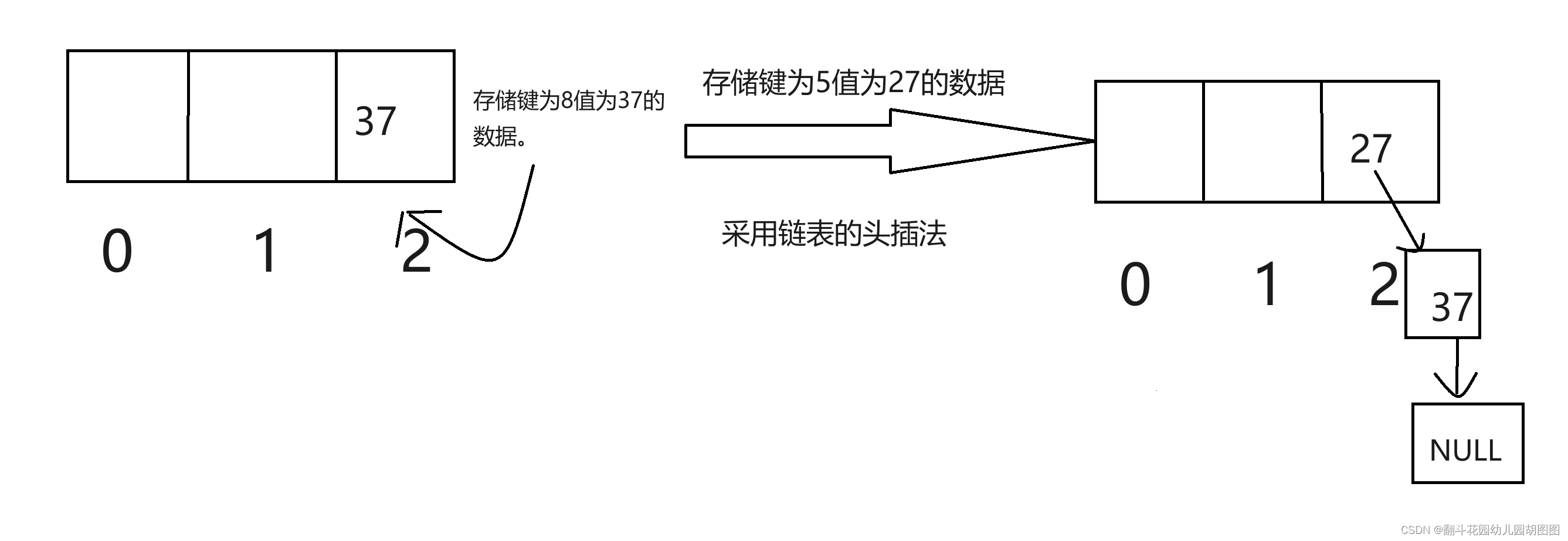
我们通过顺序表加链表的方式存储,顺序表的每个元素都是一个链表头,如果有键值相同的数据插入,那么就用头插法,插入到顺序表对应位置的空间,用这种方式,就可以完美的解决掉哈希冲突
接下来就让我们看一下哈希表的具体代码实现
A、哈希结点的类
template<class KeyType,class ValType>
class HashNode//哈希节点的类
{
public:
KeyType key;//键值
ValType val;//值
HashNode* next;//下一个结点的地址
HashNode(const KeyType& key, const ValType& val)//构造函数
{
this->key = key;
this->val = val;
this->next = NULL;
}
};key就是对应数据的键值,val就是值,由于采用顺序表加链表的存储方式,因此还需要带一个next指针来记录下一个节点的内存。
B、哈希表的类
template<class KeyType, class ValType>
class Hash//哈希表的类
{
int size;//大小
HashNode<KeyType, ValType>** table;//定义哈希表
int hash(const KeyType& key)const//计算键值函数
{
int hashkey = key % size;
if (hashkey < 0)
{
hashkey += size;
}
return hashkey;
}
public:
Hash(int size = 256);
~Hash();
void insert(const KeyType& key, const ValType& val);
void erase(const KeyType& key);
bool find(const KeyType& key, ValType& val)const;
}; 为什么table是二级指针呢,首先它是一个顺序表,我们用到动态数组,并且,他存储的每个数据就是一个链表头,所以是一个二级指针。
hash就是哈希函数,这里用到取模来求键值,其实就是table这个数组的下标了,比较直观。
C、构造函数
template<class KeyType, class ValType>
Hash< KeyType, ValType>::Hash(int size)//构造函数
{
this->size = size;
this->table = new HashNode<KeyType, ValType>* [size];
for (int i = 0; i < size; ++i)
{
this->table[i] = NULL;
}
}D、析构函数
template<class KeyType, class ValType>
Hash< KeyType, ValType>::~Hash()//析构函数
{
for (int i = 0; i < size; ++i)
{
if (table[i])
{
HashNode<KeyType, ValType>* cur = table[i];
while (cur)
{
HashNode<KeyType, ValType>* tmp = cur->next;
delete cur;
cur = tmp;
}
table[i] = NULL;
}
}
delete table;
table = NULL;
}E、插入函数
template<class KeyType, class ValType>
void Hash< KeyType, ValType>::insert(const KeyType& key, const ValType& val)//插入函数
{
int index = hash(key);//计算键值
HashNode<KeyType, ValType>* now = new HashNode<KeyType, ValType>(key, val);
if (table[index] == NULL)//判断是否头节点为空
{
table[index] = now;
}
else
{
now->next = table[index];
table[index] = now;
}
}如果index这个是空的话那就直接把new的数据存进去,否则就是链表的头插法了
F、删除函数
template<class KeyType, class ValType>
void Hash< KeyType, ValType>::erase(const KeyType& key)//删除函数
{
int index = hash(key);
if (table[index])
{
if (table[index]->key == key)//先判断头节点的值
{
HashNode<KeyType, ValType>* next = table[index]->next;
delete table;
table[index] = next;
}
else//再遍历头节点寻找链表的值
{
HashNode<KeyType, ValType>* cur = table[index]->next;
while (cur->next && cur->next->key != key)
{
cur = cur->next;
}
if (cur->next)
{
HashNode<KeyType, ValType>* next = cur->next->next;
delete cur->next;
cur->next = next;
}
}
}
}G、查找函数
template<class KeyType, class ValType>
bool Hash< KeyType, ValType>::find(const KeyType& key, ValType& val)const//查找函数
{
int index = hash(key);
if (table[index])
{
if (table[index]->key == key)
{
val = table[index]->val;
return true;
}
else
{
HashNode<KeyType, ValType>* cur = table[index]->next;
while (cur->next && cur->next->key != key)
{
cur = cur->next;
}
if (cur->next)
{
val = cur->next->val;
return true;
}
}
}
return false;
}查找和删除,其实就是链表的删除和查找,代码看起来比较多,其实比较简单,没有难点
Last、我们最后就来看一下哈希表的效果吧。
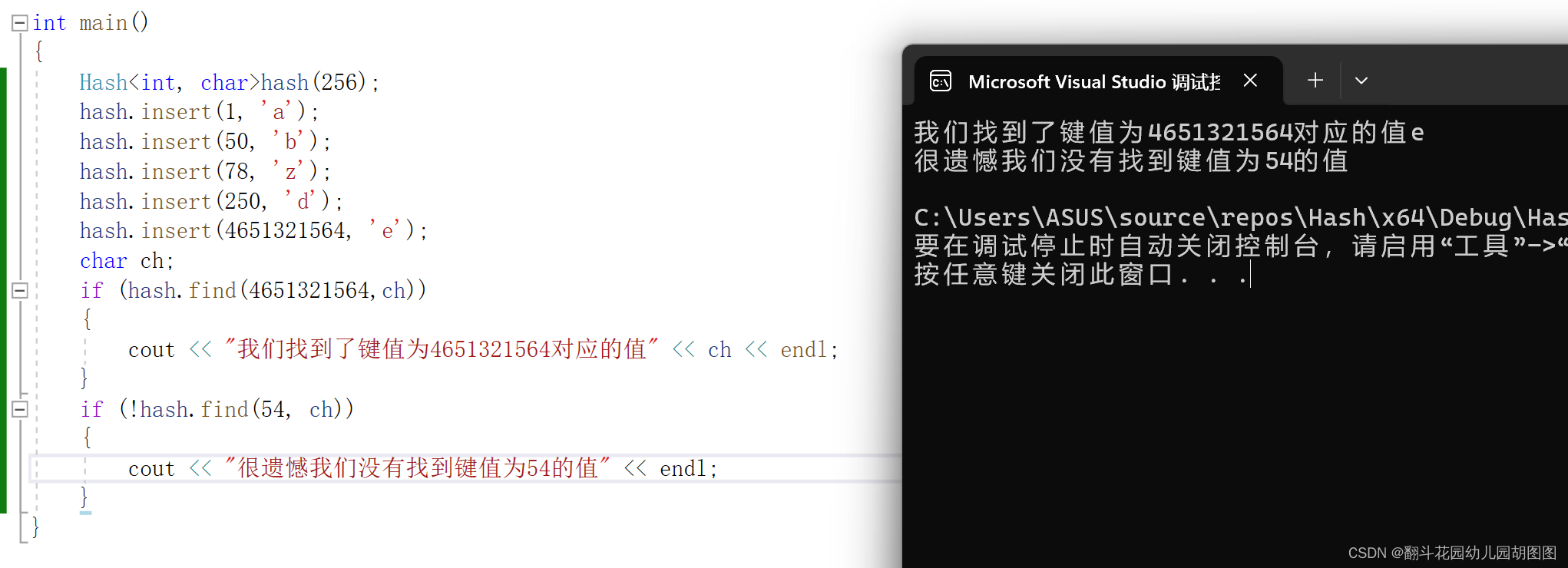 可以看到哈希表其实和数组的下标访问很相似!其实这里我们可以通过重载运算符[ ]来让他像数组下标访问一样。其实c++的stl为我们提供了现成的哈希表。在c++的stl里是支持[ ]直接访问内部数据的
可以看到哈希表其实和数组的下标访问很相似!其实这里我们可以通过重载运算符[ ]来让他像数组下标访问一样。其实c++的stl为我们提供了现成的哈希表。在c++的stl里是支持[ ]直接访问内部数据的
 以上就是哈希表的内容,由于作者是出于对知识的巩固来发布这个博客,因此不确保内容的无误性,如果有错误,恳请大家可以提出!!!
以上就是哈希表的内容,由于作者是出于对知识的巩固来发布这个博客,因此不确保内容的无误性,如果有错误,恳请大家可以提出!!!















 534
534











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









