






机器学习第一章1
1. 机器学习基本概念
2.机器学习的种类
- **regression(回归)**即为输出预测的函数值
- **classification(分类):**多适用于做选择
- **Structured Learning(结构化学习):**让机器学会创造
3.机器学习的步骤
3.1 Function with Unknown Parameters(未知参数函数)
y = b + w x 1 y=b+wx_1 y=b+wx1
b与w是未知的,称为参数(parameter)
这个带有Unknown的Parameter的Function,称之为Model(模型)
x1在这个Function中是已知的,是前一天的后台数据,称之为Feature(特征)
w是与Feature相乘的数,称之为weight(权重)
b没有与feature相乘,称之为Bias(偏离率)
3.2 Define Loss from Training Data(定义训练数据的损失函数)
根据训练资料,定义loss函数,用来衡量函数解和真实情况的差距。

**Loss:**是关于选取未知参数后的函数,不同参数的选择从而产生不同的函数,计算出不一样的Loss,而Loss的作用就是用来评估这些未知参数的选取好还是不好。
L越大,代表当前的参数值的选取越不好;L的值越小,代表当前的这一组参数的选取越好。
在之前的吴恩达深度学习中你已经学过了。试着想想。
3.3 Error Surface(误差曲面)

该图为一个真实数据计算出来的结果,我们可以调整b和w,让其取不同的值,每种组合都计算其Loss的值,画下其等高线图(Error Surface)。
在这个等高线图上面,越偏红色系,代表计算出来的Loss越大,就代表这一组w跟b未知参数的选取越差;如果越偏蓝色系,Loss越小,就代表这一组w跟b未知参数的选择越好。
3.4 Optimization(最优化)
最优化的目的就是找到使 loss最小的参数。
也就是找到一个合适的w与b,可以让Loss的值最小,我们让这两个合适的参数称为w**和b*。*
即为上图中蓝色区域最深的地方。
至于优化方法,还是熟悉的Gradient Descent(梯度下降)。
-
取w0和b0;(并不一定随机,有选择的方法);
-
分别对损失函数取w和b的偏导;
-
若在某点w和b的值为负(即偏导为负值),则令w和b增加不同的η(Learning rate,学习率);若在某点为正,则令w或者b减少η;重复上述操作。
-
找到相应的w和b偏导的零值,此处即为loss的最低阈值。
**Learning rate(学习率)**是影响w移动步长的重要因素,令学习速率为η。
η的值越大,w参数每次update到下一个位置的步长幅度就会越大;
η的值很小,则参数update就会很慢,每次只会改一点点参数的值。
(这类需要人手工设置的参数叫做hyperparameters 超参数)
其公式为
w
1
←
w
0
−
η
∂
L
∂
w
∣
w
0
w^1\leftarrow w^0-\eta \frac{\partial L}{\partial w}| _{w_0}
w1←w0−η∂w∂L∣w0
其中learning rate需要乘以前一参数的微分,再进行相减操作。即为
w
n
+
1
←
w
n
−
η
∂
L
∂
w
∣
w
n
w^{n+1}\leftarrow w^n-\eta \frac{\partial L}{\partial w}| _{w^n}
wn+1←wn−η∂w∂L∣wn
不断进行更新。
不难看出,当函数的微分 ∂ L ∂ w ∣ w n \frac{\partial L}{\partial w}| _{w^n} ∂w∂L∣wn为负值时,代表斜率为负,乘以减号和 η \eta η 刚好进行相加操作;反之斜率为正,将会对参数进行相减操作,使函数斜率不断朝零靠拢。
但是该方法也有一个缺点,因为停下来有两种情况:
- 在计算微分的时候操作者已经设置了更新次数的上限制,例如update达到100万次以后就不会再更新。
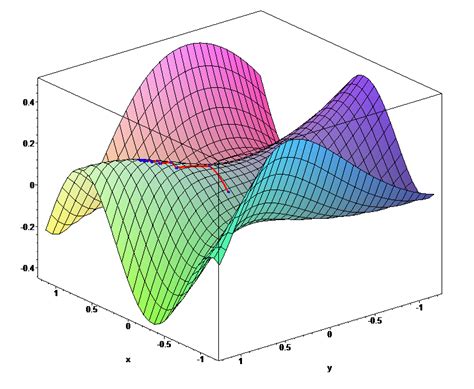
- 代表斜率已经为0,最好的情况是已经到达了global minima(全局最小值),使得Loss减小到了最小值。 但也无法分辨是否是达到了不好的情况,即:停止点仅仅是local minima(局部最小值),还没有到达Loss最低值,但更新操作已提前结束。如图所示。
4. 如何表示更复杂的模型
y = w x + b y = wx + b y=wx+b只是一条直线,无法拟合更复杂的关系。
**
**
如图所示, y = w x + b y = wx + b y=wx+b只能表示一条直线,改变w和b只能改变斜率和y的交点位置。若想拟合更加复杂的曲线(如图中红色曲线),可直观地看出无法拟合。
接下来,将讨论可能会面临的更复杂的关系,以及如何拟合这些复杂关系。
4.1 单变量:如何表示连续曲线

如图所示,这是一条光滑的曲线。
如何去拟合它呢?
充足的线性分段曲线可以逼近连续曲线。
因此可以使用分段线性曲线(Piecewise Linear Curves)。
4.1.1 分段线性曲线(Piecewise Linear Curves)

如图所示。
红色曲线(red curve)为分段线性曲线,蓝线是不同的hard sigmoid曲线。一组hard sigmoid曲线再加上常数可以
组成任何分段线性曲线(Piecewise Linear Curves)。
需要注意的是,hard sigmoid函数不能作为基础函数,因为转角处无法求微分,我们需要hard sigmoid曲线的近似曲线
*** sigmoid*** 作为基础函数。
如图所示。

4.2.2 Sigmoid function
其公式为
y
=
c
1
1
+
e
−
(
b
+
w
x
1
)
=
c
∗
s
i
g
m
i
o
d
(
b
+
w
x
1
)
y=c\frac{1}{1+e^{-(b+wx_1)}} \\ \\ =c*sigmiod(b+wx_1)
y=c1+e−(b+wx1)1=c∗sigmiod(b+wx1)
c、b、w各有不同的作用。

通过改变 c 、 b 、 w c、b、w c、b、w,可以拟合不同的hard sigmoid。
总结
通过sigmoid函数代表hard sigmoid,由不同的hard sigmoid组成分段线性曲线,进而拟合任何光滑曲线。
最终,分段线性曲线的公式为
y
=
b
+
∑
i
c
i
σ
(
b
i
+
w
i
x
1
)
y=b+\sum_i c_i\sigma(b_i+w_ix_1)
y=b+i∑ciσ(bi+wix1)
b为常数,公式后半部为sigmoid函数的加和。
注意
σ
=
s
i
g
m
o
i
d
\sigma=sigmoid
σ=sigmoid
4.2 多变量:如何表示更复杂的模型
我们可以不止用一个特征 x 1 x_1 x1,可以用多个特征带入不同的 c , b , w c,b,w c,b,w,从而得到更有灵活性(flexibility)的函数,如图所示。用 j j j 来代表特征(feature)的编号。如果要考虑前 28 天, j j j 就是 1 到 28。

将 j j j 设为3, x 1 x_1 x1、 x 2 x_2 x2、 x 3 x_3 x3分别为三天的数据,如图所示,每一个 i i i 就代表一个蓝色的函数。
每一个蓝色的函数都用一个 Sigmoid 函数来比近似它,序号①、②、③代表有个 Sigmoid 函数。

注意区分单变量与多变量的区别:
- 特征 x x x 唯一。通过改变sigmoid函数中的 c 、 w 、 b c、w、b c、w、b ,表示不同的hard sigmoid函数,进而表示分段线性函数。
- 特征 x x x 不唯一, c 、 w 、 b c、w、b c、w、b 也不唯一。例如,一个特征 x 1 x_1 x1有不同的 c i 、 w i 、 b i c_i、w_i、b_i ci、wi、bi 对应,衍生出不同的sigmoid函数, x 2 、 x 3 x_2、x_3 x2、x3类似。
多变量中,通过公式
y
=
b
+
∑
i
c
i
σ
(
b
i
+
∑
j
w
i
j
x
j
)
y=b+\sum_i{c_i\sigma(b_i+\sum_jw_{ij}x_j)}
y=b+i∑ciσ(bi+j∑wijxj)
拟合,
w
i
j
w_{ij}
wij 代表在第
i
i
i 个sigmoid中乘给第
j
j
j 个特征的权重。
设共有3个sigmoid,则第一个sigmoid需计算的值
r
i
=
b
i
+
∑
j
w
i
j
x
j
r_i=b_i+\sum_jw_{ij}x_j
ri=bi+j∑wijxj
即为
r
1
=
b
1
+
w
11
x
1
+
w
12
x
2
+
w
13
x
3
r_1=b_1+w_{11}x_1+w_{12}x_2+w_{13}x_3
r1=b1+w11x1+w12x2+w13x3
同理可得
r
1
=
b
1
+
w
11
x
1
+
w
12
x
2
+
w
13
x
3
r
2
=
b
2
+
w
21
x
1
+
w
22
x
2
+
w
23
x
3
r
3
=
b
3
+
w
31
x
1
+
w
32
x
2
+
w
33
x
3
r_1=b_1+w_{11}x_1+w_{12}x_2+w_{13}x_3\\ r_2=b_2+w_{21}x_1+w_{22}x_2+w_{23}x_3\\ r_3=b_3+w_{31}x_1+w_{32}x_2+w_{33}x_3
r1=b1+w11x1+w12x2+w13x3r2=b2+w21x1+w22x2+w23x3r3=b3+w31x1+w32x2+w33x3
化为线性代数的计算方法
[
r
1
r
2
r
3
]
=
[
b
1
b
2
b
3
]
+
[
w
11
w
12
w
13
w
21
w
22
w
23
w
31
w
32
w
33
]
[
x
1
x
2
x
3
]
\begin{bmatrix} r_1\\ r_2\\ r_3\\ \end{bmatrix}= \begin{bmatrix} b_1\\ b_2\\ b_3\\ \end{bmatrix}+ \begin{bmatrix} w_{11}&w_{12}&w_{13}\\ w_{21}&w_{22}&w_{23}\\ w_{31}&w_{32}&w_{33}\\ \end{bmatrix} \begin{bmatrix} x_1\\ x_2\\ x_3\\ \end{bmatrix}
r1r2r3
=
b1b2b3
+
w11w21w31w12w22w32w13w23w33
x1x2x3
⇕ \Updownarrow ⇕
r = b + W x \mathbf{r=b+Wx} r=b+Wx
具体的计算过程如图所示

其中:a为 σ ( r ) \sigma(r) σ(r) 。
将函数再次抽象为

- 对此图的解释:在该函数中, W 、 b 、 c T 、 b W、b、c^T、b W、b、cT、b 统称为未知参数。将未知参数向量化展开,展开成如图的色块( W W W的展开方式可以是整行也可以是整列),将这些展开的向量“拼”在一起,形成一个新的向量,这个新的向量也就是包含位置参数的向量称为 θ \theta θ 。
θ = [ θ 1 θ 2 θ 3 ⋮ ] \theta= \begin{bmatrix} \theta_1\\\theta_2\\\theta_3\\\vdots \end{bmatrix} θ= θ1θ2θ3⋮
4.2.1 多变量的Optimization
之前的损失函数 L ( w , b ) L(w,b) L(w,b)在多变量中表示为 L ( θ ) L(\theta) L(θ)。设一组初始 θ \theta θ 数值为 θ 0 \theta ^0 θ0 ,经最优化操作后的未知数向量为 θ ∗ \theta ^* θ∗ 。
由 **3.4 Optimization(最优化)**可知,求多变量的Loss函数最小值核心思想仍为
θ
n
+
1
←
θ
n
−
η
g
n
\theta ^{n+1} \leftarrow \theta^n-\eta g^n
θn+1←θn−ηgn
其中 g g g 为 L L L 对 θ \theta θ 中不同未知数的微分(与 L ( w , b ) L(w,b) L(w,b) 一样,均为分别求未知数的微分,然后通过梯度下降找出最优解。不同之处为未知数数量 θ \theta θ 更多)
设
θ
\theta
θ 的上标为同一组向量的批次,
θ
\theta
θ 的下标为该批次向量中的未知数。如下公式所示。
θ
1
=
[
θ
1
1
θ
2
1
θ
3
1
⋮
]
\theta ^1 = \begin{bmatrix} \theta_1^1\\\theta_2^1\\\theta_3^1\\\vdots \end{bmatrix}
θ1=
θ11θ21θ31⋮
上标为1,表示这是第1批次的
θ
\theta
θ ;下标为1,2,3…表示在该批次的
θ
\theta
θ 向量中,不同的未知数。
g
=
[
∂
L
∂
θ
1
∣
θ
=
θ
1
n
∂
L
∂
θ
2
∣
θ
=
θ
2
n
∂
L
∂
θ
3
∣
θ
=
θ
3
n
⋮
]
g=\begin{bmatrix} \frac{\partial L}{\partial \theta_1}|_{\theta=\theta_1^n} \\ \frac{\partial L}{\partial \theta_2}|_{\theta=\theta_2^n} \\ \frac{\partial L}{\partial \theta_3}|_{\theta=\theta_3^n} \\ \vdots \end{bmatrix}
g=
∂θ1∂L∣θ=θ1n∂θ2∂L∣θ=θ2n∂θ3∂L∣θ=θ3n⋮
g的含义为:在
L
L
L 中分别对
θ
\theta
θ 中的所有未知数求偏导,再将现批次的
θ
\theta
θ 中的值代入。
完整的公式为
[
θ
1
n
+
1
θ
2
n
+
1
θ
3
n
+
1
⋮
]
←
[
θ
1
n
θ
2
n
θ
3
n
⋮
]
−
η
[
∂
L
∂
θ
1
∣
θ
=
θ
1
n
∂
L
∂
θ
2
∣
θ
=
θ
2
n
∂
L
∂
θ
3
∣
θ
=
θ
3
n
⋮
]
\begin{bmatrix} \theta^{n+1}_1\\\theta^{n+1}_2 \\\theta^{n+1}_3\\\vdots \end{bmatrix}\leftarrow \begin{bmatrix} \theta^{n}_1\\\theta^{n}_2 \\\theta^{n}_3\\\vdots \end{bmatrix}- \eta\begin{bmatrix} \frac{\partial L}{\partial \theta_1}|_{\theta=\theta_1^n} \\ \frac{\partial L}{\partial \theta_2}|_{\theta=\theta_2^n} \\ \frac{\partial L}{\partial \theta_3}|_{\theta=\theta_3^n} \\ \vdots \end{bmatrix}
θ1n+1θ2n+1θ3n+1⋮
←
θ1nθ2nθ3n⋮
−η
∂θ1∂L∣θ=θ1n∂θ2∂L∣θ=θ2n∂θ3∂L∣θ=θ3n⋮
⇕ \Updownarrow ⇕
θ n + 1 ← θ n − η g n \theta ^{n+1} \leftarrow \theta^n-\eta g^n θn+1←θn−ηgn
4.2.2 批处理
笔者写不动了…光是公式笔者就敲了大半天,后续的批处理及更往后的几章,就静静等待后续更新。
有什么错误、改进的地方,欢迎各位大佬指正。
over –
written by Shepherd in 7&8/24,main references: leedl-tutorial ;zyd机器学习笔记 ↩︎
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









