






SparkSQL,创建表 ,查询数据
实验目的
1.了解Spark Shell、Spark SQL模式
2.学习使用Spark Shell、Spark SQL模式,创建表及查询数据
实验原理
Spark SQL的前身是Shark,Shark是伯克利实验室Spark生态环境的组件之一,它能运行在Spark引擎上,从而使得SQL查询的速度得到10-100倍的提升,但是,随着Spark的发展,由于Shark对于Hive的太多依赖(如采用Hive的语法解析器、查询优化器等等),制约了Spark的One Stack Rule Them All的既定方针,制约了Spark各个组件的相互集成,所以提出了SparkSQL项目。
SparkSQL抛弃了原有Shark的代码,汲取了Shark的一些优点,如内存列存储(In-MemoryColumnarStorage)、Hive兼容性等,重新开发了SparkSQL代码;由于摆脱了对Hive的依赖性,SparkSQL无论在数据兼容、性能优化、组件扩展方面都得到了极大的方便。
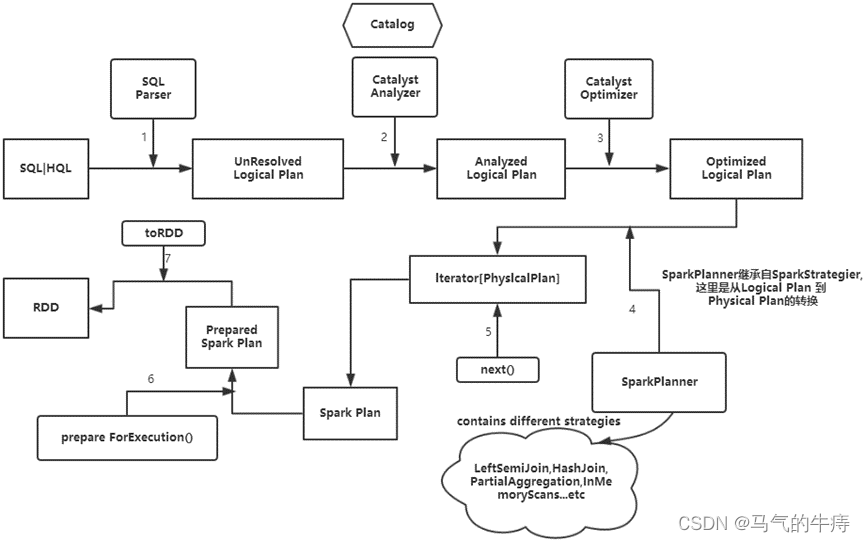
(Spark SQL 执行流程)
SQLContext具体的执行过程如下:
(1)SQL | HQL语句经过SqlParse解析成UnresolvedLogicalPlan。
(2)使用analyzer结合数据字典(catalog)进行绑定,生成resolvedLogicalPlan,在这个过程中,Catalog提取出SchemRDD,并注册类似case class的对象,然后把表注册进内存中。
(3)Analyzed Logical Plan经过Catalyst Optimizer优化器优化处理后,生成Optimized Logical Plan,该过程完成以后,以下的部分在Spark core中完成。
(4)Optimized Logical Plan的结果交给SparkPlanner,然后SparkPlanner处理后交给PhysicalPlan,经过该过程后生成Spark Plan。
(5)使用SparkPlan将LogicalPlan转换成PhysicalPlan。
(6)使用prepareForExecution()将PhysicalPlan转换成可执行物理计划。
(7)使用execute()执行可执行物理计划。
(8)生成DataFrame。
在整个运行过程中涉及到多个SparkSQL的组件,如SqlParse、analyzer、optimizer、SparkPlan等等。
实验环境
Linux Ubuntu 16.04
jdk-7u75-linux-x64
hadoop-2.6.0-cdh5.4.5
scala-2.10.5
spark-1.6.0-bin-hadoop2.6
实验内容
某电商平台,需要对订单数据进行分析,已知订单数据包括两个文件,分别为订单数据orders和订单明细数据order_items,orders记录了用户购买商品的订单ID,订单号,用户ID及下单日期。order_items记录了商品ID,订单ID以及明细ID。它们的结构与关系如下图所示:
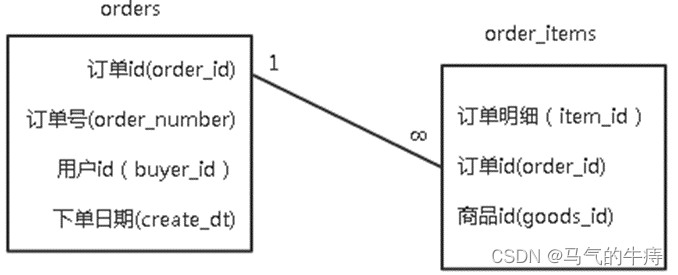
orders表:(order_id,order_number,buyer_id,create_dt)
- 订单ID 订单号 用户ID 下单日期
- 52304 111215052630 176474 2011-12-15 04:58:21
- 52303 111215052629 178350 2011-12-15 04:45:31
- 52302 111215052628 172296 2011-12-15 03:12:23
- 52301 111215052627 178348 2011-12-15 02:37:32
- 52300 111215052626 174893 2011-12-15 02:18:56
- 52299 111215052625 169471 2011-12-15 01:33:46
- 52298 111215052624 178345 2011-12-15 01:04:41
- 52297 111215052623 176369 2011-12-15 01:02:20
- 52296 111215052622 178343 2011-12-15 00:38:02
- 52295 111215052621 178342 2011-12-15 00:18:43
order_items表:(item_id,order_id,goods_id )
- 明细ID 订单ID 商品ID
- 252578 52293 1016840
- 252579 52293 1014040
- 252580 52294 1014200
- 252581 52294 1001012
- 252582 52294 1022245
- 252583 52294 1014724
- 252584 52294 1010731
- 252586 52295 1023399
- 252587 52295 1016840
- 252592 52296 1021134
- 252593 52296 1021133
- 252585 52295 1021840
- 252588 52295 1014040
- 252589 52296 1014040
- 252590 52296 1019043
创建orders表和order_items表,并统计该电商网站都有哪些用户购买了什么商品。
实验步骤
1.首先检查Hadoop相关进程,是否已经启动。若未启动,切换到/apps/hadoop/sbin目录下,启动Hadoop。
- jps
- cd /apps/hadoop/sbin
- ./start-all.sh
2.在Linux本地新建/data/spark5目录。
- mkdir -p /data/spark5
3.切换到/data/spark5目录下,使用wget命令,下载http://172.16.103.12:60000/allfiles/spark5中的orders和order_items。
- cd /data/spark5
- wget http://172.16.103.12:60000/allfiles/spark5/orders
- wget http://172.16.103.12:60000/allfiles/spark5/order_items
4.首先,在HDFS上新建/myspark5目录,然后将/data/spark5目录下的orders与order_items文件,上传到HDFS的/myspark5目录下。
- hadoop fs -mkdir /myspark5
- hadoop fs -put /data/spark5/orders /myspark5
- hadoop fs -put /data/spark5/order_items /myspark5
5.启动Spark Shell。
- spark-shell
6.在spark-shell下,使用case class方式定义RDD,创建orders表。
- val sqlContext = new org.apache.spark.sql.SQLContext(sc)
- import sqlContext.implicits._
- case class Orders(order_id:String,order_number:String,buyer_id:String,create_dt:String)
- val dforders = sc.textFile("/myspark5/orders").map(_.split('\t')).map(line=>Orders(line(0),line(1),line(2),line(3))).toDF()
- dforders.registerTempTable("orders")
验证创建的表是否成功。
- sqlContext.sql("show tables").map(t=>"tableName is:"+t(0)).collect().foreach(println)
- sqlContext.sql("select order_id,buyer_id from orders").collect
7.在Spark Shell下,使用applyScheme方式定义RDD,创建order_items表。
- import org.apache.spark.sql._
- import org.apache.spark.sql.types._
- val rddorder_items = sc.textFile("/myspark5/order_items")
- val roworder_items = rddorder_items.map(_.split("\t")).map( p=>Row(p(0),p(1),p(2) ) )
- val schemaorder_items = "item_id order_id goods_id"
- val schema = StructType(schemaorder_items.split(" ").map(fieldName=>StructField(fieldName,StringType,true)) )
- val dforder_items = sqlContext.applySchema(roworder_items, schema)
- dforder_items.registerTempTable("order_items")
验证创建表是否成功。
- sqlContext.sql("show tables").map(t=>"tableName is:"+t(0)).collect().foreach(println)
- sqlContext.sql("select order_id,goods_id from order_items ").collect
8.将order表及order_items表进行join操作,统计该电商网站,都有哪些用户购买了什么商品。
- sqlContext.sql("select orders.buyer_id, order_items.goods_id from order_items join orders on order_items.order_id=orders.order_id ").collect
9.退出Spark shell模式
- exit
下面演示Spark SQL模式
10.启动Spark SQL。
- spark-sql
11.创建表orders及表order_items。
- create table orders (order_id string,order_number string,buyer_id string,create_dt string)
- row format delimited fields terminated by '\t' stored as textfile;
- create table order_items(item_id string,order_id string,goods_id string)
- row format delimited fields terminated by '\t' stored as textfile;
12.查看已创建的表。
- show tables;
表名后的false意思是该表不是临时表。
13.将HDFS中/myspark5下的orders表和order_items表中数据加载进刚创建的两个表中。
- load data inpath '/myspark5/orders' into table orders;
- load data inpath '/myspark5/order_items' into table order_items;
14.验证数据是否加载成功。
- select * from orders;
- select * from order_items;
15.处理文件,将order表及order_items表进行join操作,统计该电商网站,都有哪些用户购买了什么商品。
- select orders.buyer_id, order_items.goods_id from order_items join orders on order_items.order_id=orders.order_id;
SparkSQL,加载文件, 处理文件,存储文件
实验目的
1.掌握Spark SQL的基本操作
2.了解Spark SQL对文件的存储
实验原理
Spark SQL重要的是操作DataFrame,DataFrame本身提供了Save和Load的操作,
Load:可以创建DataFrame。
Save:把DataFrame中的数据保存到文件或者说用具体的格式来指明我们要读取的文件类型,以及用具体的格式来指出我们要输出的文件是什么类型。
Spark SQL执行基本操作时,内部结构流程图如下:
DataFrame本质是数据 + 数据的描述信息(结构元信息)。
所有的上述SQL及DataFrame操作最终都通过Catalyst翻译成Spark程序RDD操作代码。
Spark SQL前身是Shark,大量依赖Hive项目的jar包与功能,但在上面的扩展越来越难,因此出现了Spark SQL,它重写了分析器,执行器脱离了对Hive项目的大部分依赖,基本可以独立去运行,只用到Hive项目的两个地方:
(1)借用了Hive词汇分析的jar即HiveQL解析器
(2)借用了Hive的metastore和数据访问API即Hive Catalog
也就是说上图的左半部分的操作,全部用的是SparkSQL本身自带的内置SQL解析器解析SQL进行翻译,用到内置元数据信息(比如结构化文件中自带的结构元信息,RDD的schema中的结构元信息)右半部分则是走的Hive的HQL解析器,还有Hive元数据信息。因此左右两边的API调用的底层类会有不同。
SQLContext使用:
1.简单的解析器(Scala语言写的SQL解析器)比如:
(1)在半结构化的文件里面使用SQL查询时,是用这个解析器解析的。
(2)访问(半)结构化文件的时候,通过sqlContext使用schema,类生成DataFrame,然后DataFrame注册为表时,registerTempTable(注册临时表)然后从这个表里面进行查询时,即使用的简单的解析器。
simpleCatalog此对象中存放关系(表),比如我们指定的schema信息,类的信息,都是关系信息。
2.HiveContext使用:
(1)HiveQL解析器支持Hive的HQL语法,如只有通过HiveContext生成的DataFrame才能调用saveAsTable操作。
(2)hiveCatalog(存放数据库和表的元数据信息)
实验环境
Linux Ubuntu 16.04
jdk-7u75-linux-x64
hadoop-2.6.0-cdh5.4.5
scala2.10.5
spark-1.6.0-bin-hadoop2.6
实验内容
将Linux本地的goods_visit.json文件上传到HDFS上/myspark6目录下,使用Spark读取HDFS上/myspark6目录下的goods_visit.json文件,然后用SparkSQL对goods_visit.json文件进行各种操作,最后将Spark上的goods_visit.json文件保存为parquet格式存储到HDFS上。
实验步骤
1.首先检查Hadoop相关进程,是否已经启动。若未启动,切换到/apps/hadoop/sbin目录下,启动Hadoop。
- jps
- cd /apps/hadoop/sbin
- ./start-all.sh
2.在Linux本地新建/data/spark6目录。
- mkdir -p /data/spark6
切换到/data/spark6目录下,使用wget命令,下载http://172.16.103.12:60000/allfiles/spark6中的文件。
- cd /data/spark6
- wget http://172.16.103.12:60000/allfiles/spark6/goods_visit.json
3.将文件goods_visit.json,上传到HDFS的/myspark6目录下,若目录不存在则需提前创建。
- hadoop fs -mkdir /myspark6
- hadoop fs -put /data/spark6/goods_visit.json /myspark6
4.启动Spark Shell。
- spark-shell
5.读取HDFS中/myspark6的goods_visit.json文件。
- val df=sqlContext.read.json("hdfs://localhost:9000/myspark6/goods_visit.json")
6.查看goods_visit.json中的所有数据。
- df.show()
7.查看goods_visit.json的表结构。
- df.printSchema()
- df.select("goods_id").show()
9.统计文件行数。
- df.count
10.条件查询,查询点击次数超过500商品。(show是返回字段和表数据,collect是返回集合)
- df.filter(df("click_num")>500).show
11.统计点击次数的最值、总和及平均数。
- df.agg(max("click_num"),sum("click_num"),min("click_num"),avg("click_num")).show
12.过滤点击次数小于200的商品。
- df.filter(df("click_num") < 200).show()
13.按点击次数进行分组统计。
- df.groupBy("click_num").count().show()
14.读取goods_visit.json文件,保存为parquet格式。
- val df = sqlContext.read.format("json").load("hdfs://localhost:9000/myspark6/goods_visit.json")
- df.select("goods_id", "click_num").write.format("parquet").save("goods_visit.parquet")
- hadoop fs -ls /user/zhangyu
实验结论及心得
通过本次实验,我学习了Spark Streaming的框架结构和实现原理,掌握了进行WordCount实验和Kafka传输数据到Spark Streaming的流程,以及Spark Streaming处理数据的方法。Spark是一个类似于MapReduce的分布式计算框架,核心是弹性分布式数据集,提供了比MapReduce更丰富的模型,能够在内存中对数据集进行多次迭代,支持复杂的数据挖掘算法和图形计算算法。而Spark Streaming是构建在Spark上的实时计算框架,扩展了Spark处理大规模流式数据的能力。















 1376
1376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}