






Python的正则表达式和文本文件的读写
目录
一、正则表达式
首先导入re库:import re
1.特殊字符的使用
". * + ? \ ^ { } | ( )"
在正则表达式中,特殊字符(元字符)具有特定的含义,用于匹配文本中的特定模式。以下是一些常见的特殊字符及其用法:
① '.'表示要匹配除了换行符的任何单个字符
content = """
苹果是,红色的
苹果是,绿色的
苹果是,白色的
"""
#注意,这里的r是为了防止转义,防止与\n,\t等混淆
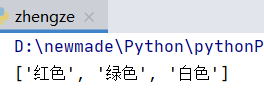
p = re.compile(r".色")
a = p.findall(content)
print(a) # 输出: ['红色', '绿色', '白色']
②*星号表示匹配前面的子表达式任意次数,包括0次
p = re.compile(r",.*")
a = p.findall(content)
print(a) # 输出: [',红色的', ',绿色的', ',白色的']
③{ }:指定前面字符的匹配次数。{a,b}表示匹配次数在a到b之间。
content2 = "红彤彤,绿油油,黄澄澄,油油油,油油油油油"
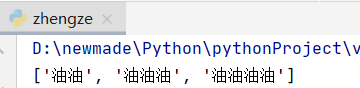
p = re.compile(r"油{2,4}")
mess = p.findall(content2)
print(mess) # 输出: ['油油', '油油油', '油油油']
④\:反斜杠用于转义特殊字符,使其失去特殊含义。
#练习:获取.前的值
content = """
苹果是.红色的
苹果是.绿色的
苹果是.白色的
"""
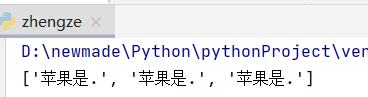
p = re.compile(".*\\.")
r = p.findall(content)
print(r) # 输出: ['苹果是.', '苹果是.', '苹果是.']
2.贪婪模式与非贪婪模式
正则表达式默认是贪婪模式,即尽可能多地匹配字符。非贪婪模式则尽可能少地匹配字符,通过在量词后加?来实现。
习题:
将以下的字符串中的所有html的标签都提取出来 #source ='<html><head><title>Title</title>' 得到:['<html>','<head>','<title>','</title>'] #这个例子中不能直接使用<>.*,因为<>中会尽可能多的获取<>,所以会把多个<><><>看成一个<> #解决方法:加上问号
-
贪婪模式:默认情况下,正则表达式会尽可能多地匹配字符。
source = '<html><head><title>Title</title>' p = re.compile(r"<.*>") a = p.findall(source) print(a) # 输出: ['<html><head><title>Title</title>'] -
非贪婪模式:在量词后加
?,使匹配尽可能少。source = '<html><head><title>Title</title>' p = re.compile(r"<.*?>") a = p.findall(source) print(a) # 输出: ['<html>', '<head>', '<title>', '</title>']
通过理解和使用这些特殊字符和模式,可以更灵活地处理文本匹配任务。
二、文本文件的读写
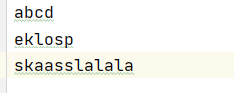
首先有一个file.txt文件,内容如下:
在Python中,使用open()函数可以打开文件并进行读写操作。open()函数的基本语法如下:
f = open("file.txt", "mode")
其中,mode参数指定文件的打开方式,常见的模式包括:
r:只读模式(默认)。r+:可读可写模式,文件指针在文件开头。w:只写模式,会覆盖文件内容,如果文件不存在则创建。w+:可读可写模式,会覆盖文件内容,如果文件不存在则创建。a:追加模式,文件指针在文件末尾,如果文件不存在则创建。a+:可读可写模式,文件指针在文件末尾,如果文件不存在则创建。
1.r:只读模式(默认)
选择相应的模式进行文件操作,这里先试用r,如果不指定也是默认使用r模式
无论使用哪种模式,都可使用read()方法来读取文件内容,另外read()方法可以指定读取的字符数,如果不指定则读取整个文件
#1.r只读模式(默认)
f = open("file.txt", "r")
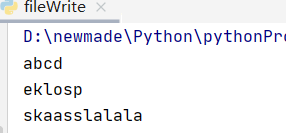
#①一般读取方式,读取文本中全部的内容,是一个字符串
content = f.read()
print(content)
f.close()
#②指定读取的字符个数方式
info2=f.read(7)
#读出来的字母比实际应该读出来的字母少一个,是因为还要读一个换行符
print(info2)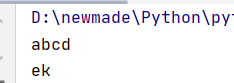
2.r+:可读可写模式
#2.r+表示可读可写,开始时文件指针在左上角第一行的位置,注意写入内容时指针位置,避免覆盖原内容
#如果存在想要写入的文件不存在的情况,不会写内容,更不会自动创建文件
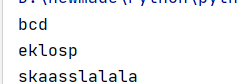
f=open("file.txt","r+")
f.write("e")
print(f.read())第一行读取出来后内容不完整,为bcd,是因为write后指针变为1了,而不是0,要想要读取全部内容,使用seek方法
f=open("file.txt","r+")
f.write("e")
#seek()用来启动文件指针
#移动文件指针后再读取内容,seek()中设置的是多少位置就移到多少
f.seek(0)
print(f.read())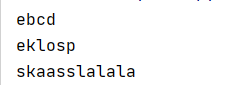
3.w:只写模式
原文件内容只剩下“e”了
#w,只能写,直接一股脑的覆盖掉原文件全部内容,如果存在想要写入的文件不存在的情况,则会自动创建此文件
f=open("file02.txt","w")
f.write("e")4.w+:可读可写模式
#w+,可读可写,直接一股脑的覆盖掉原文件全部内容,不存在则创建
#读之前会把内容全都覆盖为空值,只能读出创建后写入的内容
f=open("file03.txt","w+")
f.write("rrr")
print("位置:",f.tell())
#写入内容后需要将指针手动设置为0,否则指针在末尾还是读不出内容
f.seek(0)
print(f.readlines())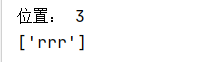
上面用到了两个方法:
①tell方法:用了获取文件指针位置
②readlines:获取当前文件所有内容
5.a:追加模式
#a 只能写(print会报错),从文件"底部"添加内容,不存在则创建
f=open("file.txt","a")
print(f.tell())
f.write("lalala")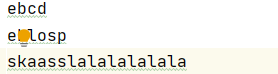
6.a+:可读可写模式
#a+ 可读可写,从文件顶部读取内容,从文件底部添加内容,不存在则创建
f=open("file03.txt","a+")
print(f.tell())
f.seek(0)
print(f.read())
f.write("llll")
print(f.tell())
f.seek(0)
print(f.read())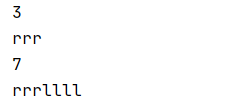
三、Excel文件的读写
在Python中,可以使用pandas库来读写Excel文件。首先需要安装pandas库和openpyxl库:
pip install pandas openpyxl
读取Excel文件
使用pandas的read_excel()函数可以读取Excel文件。
import pandas as pd
df = pd.read_excel("file.xlsx") # 读取Excel文件
print(df)
写入Excel文件
使用pandas的to_excel()函数可以将数据写入Excel文件。
import pandas as pd
data = {'Name': ['Alice', 'Bob'], 'Age': [25, 30]}
df = pd.DataFrame(data)
df.to_excel("output.xlsx", index=False) # 写入Excel文件
操作Excel文件
pandas提供了丰富的数据操作功能,可以对读取的Excel数据进行处理。
import pandas as pd
df = pd.read_excel("file.xlsx")
df['Age'] = df['Age'] + 1 # 对Age列进行加1操作
df.to_excel("output.xlsx", index=False)
通过以上方法,可以方便地进行文本文件和Excel文件的读写操作。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









