






目录
1.ZipList
redis中的ZipList是一种紧凑的内存储存结构,主要可以节省内存空间储存小规模数据。是一种特殊的双端链表,有一系列连续的内存组成,可以在任意一端进行压入/弹出操作,而且操作的时间复杂度为O(1)
常见方法:
LPUSH mylist "value1" "value2" //左边插入
RPUSH mylist "value3" "value4" //右边插入
LPOP mylist //从链表最左端弹出数据
RPOP mylist //从链表最右端弹出数据
LRANGE mylist 0 2 //获取左边指定范围的数据
LINDEX mylist 0 //获取指定下标数据
LLEN mylist //获取列表长度| zlbytes | zltail | zllen | entry | ... | entry | entry | zlend |
| 属性 | 类型 | 长度 | 用途 |
| zlbytes | uint32_t | 4字节 | 记录整个压缩链表占用的内存字节数 |
| zltail | uint32_t | 4字节 | 这个是偏移量,记录压缩列表尾节点到列表起始地址有多少字节,通过这个偏移量,可以确定尾节点地址 |
| zllen | uint16_t | 2字节 | 记录列表包含的节点数量。最大65534,如果超出也只是65535 |
| entry | 列表节点 | 不定 | 各个节点的长度由节点保存的内容确定 |
| zlend | uint8_t | 1字节 | 特殊值0xFF(255),用于标记压缩例表的末端 |
1.2.解析Entry:
ZipList的Entry不像普通链表那样记录前后节点的指针,因为记录前后节点指针需要16字节,大大浪费了内存。所以采用下面的结构来保存。
| previous_entry_length | encoding | content |
1.previous_entry_length:前一节点的长度,占1字节 或 5字节
当前一节点长度 < 254字节,采用 1字节保存这个长度值
当前一节点的长度 > 254字节,采用5字节保存这个长度值
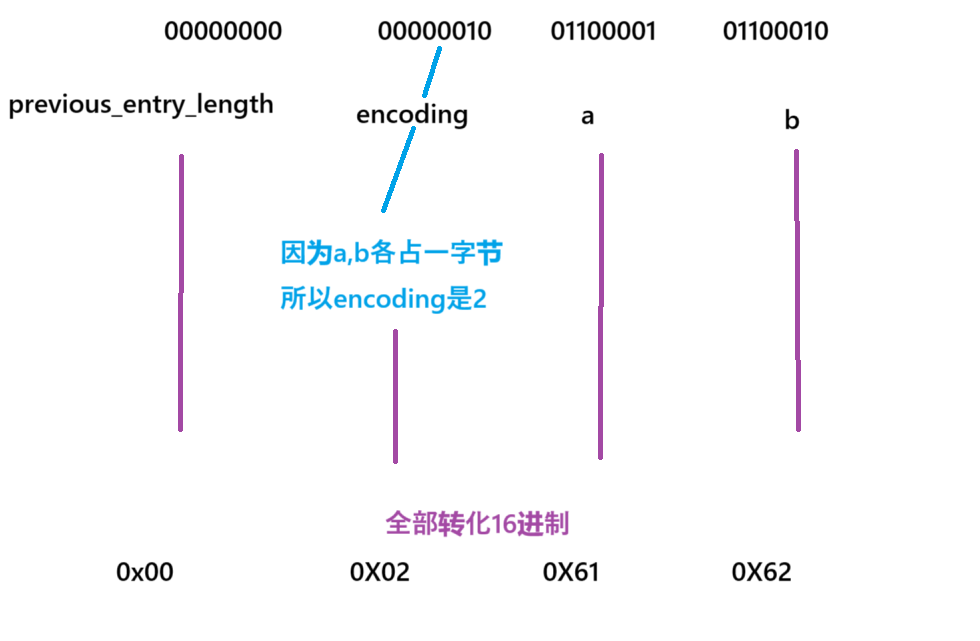
2.encoding:编码属性,记录content的数据类型(数字/字符串)及长度,占用1,2,5字节。
3.contents:负责保存具体的内容,可以是数字可以是字符串
注意:ZipList中所有储存长度的数值均采用小端字节序储存,低位在前,高位字节在后。
列如:0x1234,采用小端字节序后就是 0x3412
1.3Encoding编码
encoding编码分为两种:字符串和数字
字符串:encoding以00,01,10开头标识储存的是字符串。
下面长度不同的字符串对应encoding编码格式

举例:储存字符串ab,bc

1.4.ZipList连锁更新问题
ZipList的每个Entry都包含previous_entry_length来记录上一节点大小,长度为1个或5字节。
>>如果前一节点长度 < 254,那么采用1字节保存这个长度值。
>>如果前一节点 >= 254,则采用5字节保存这个长度值。
如果有N个连续的长度为250~253之间的entry,如果不巧有一个扩展那么又可能发生连锁反应,又可能所有都发生连锁更新,新增,删除都可能导致连锁更新发生。
总结:
1.压缩列表可以看作连续内存空间的“双向链表“
2.列表的节点之间不是通过指针链接,而是上一节点和本节点长度来寻址,大大节省内存
3.如果数据过多,链表过长,可能影响查询性能
4.增加删除都可能发生连续更新问题
2.QuickList
ZIpList虽然节省内存,但是申请内存必须是连续空间,如果内存占用过多那么申请效率变低
数据量过大超出上限采用分片储存数据,那么这些ZipList如何联系?
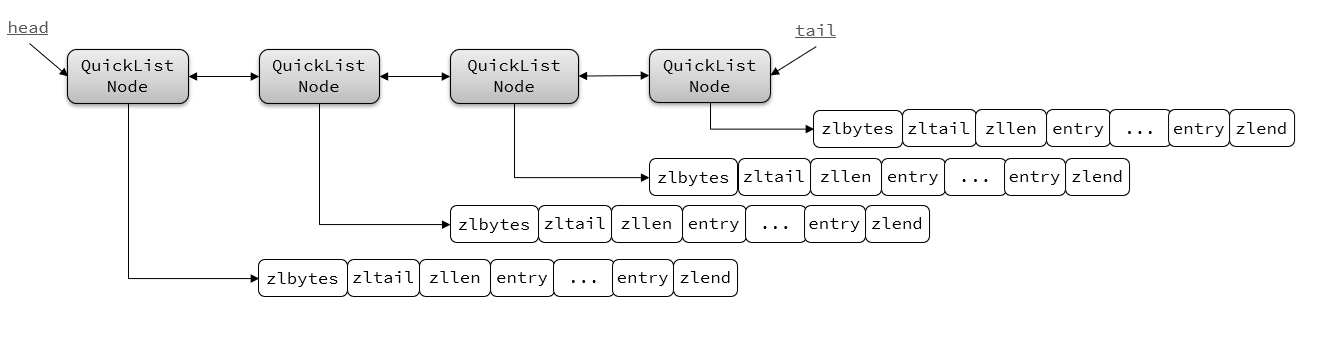
Redis3.2版本引入QuickList,是一个双端链表,只不过每个节点都是ZipList
Redis提供配置:list-max-ziplist-size
如果值是正:代表ZipList允许的最大entry数。
如果值是负:代表每个ZipList的最大内存大小。
| -1 | -2 | -3 | -4 | -5 |
| 4kb | 8kb | 16kb | 32kb | 64kb |

QuickList可以控制首尾是否进行压缩,通过配置项list-compress-depth来控制,这个参数是控制首尾不压缩的节点个数。
| 0 | 1 | 2 |
| 代表首尾节点不压缩 | 首尾各有一个1个不压缩,中间全压缩 | 首尾各有2节点不压缩,中间全压缩 |

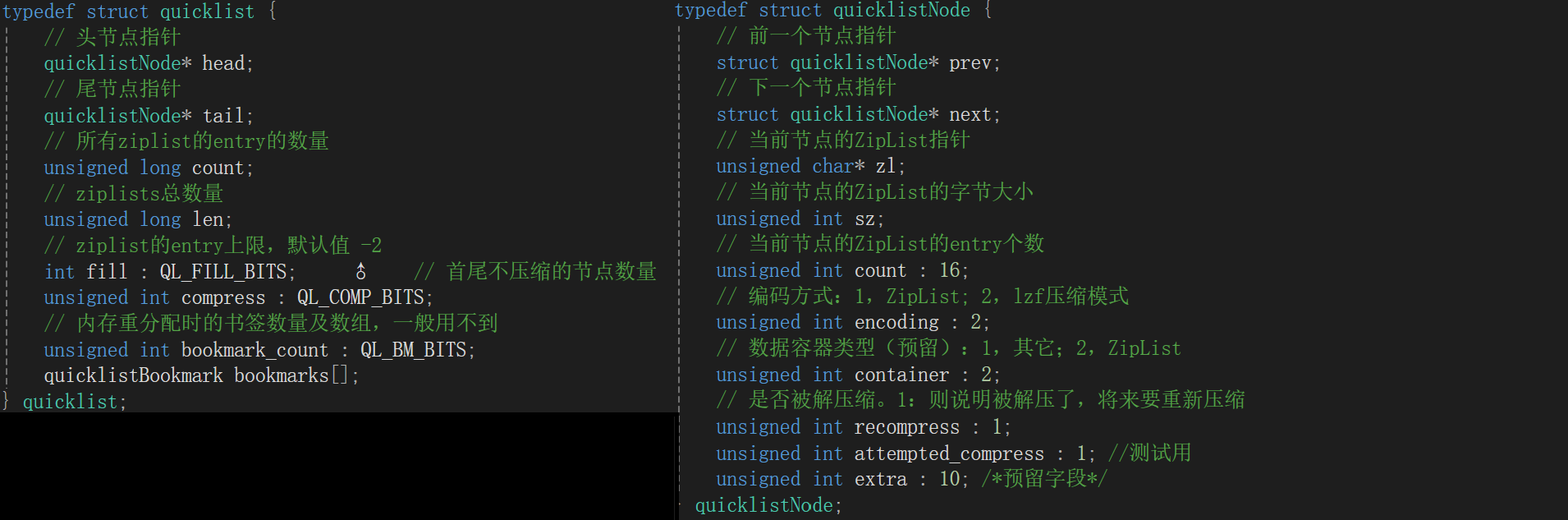
QuickList 和 Quick List Node的结构源码:
QuickList结构图:
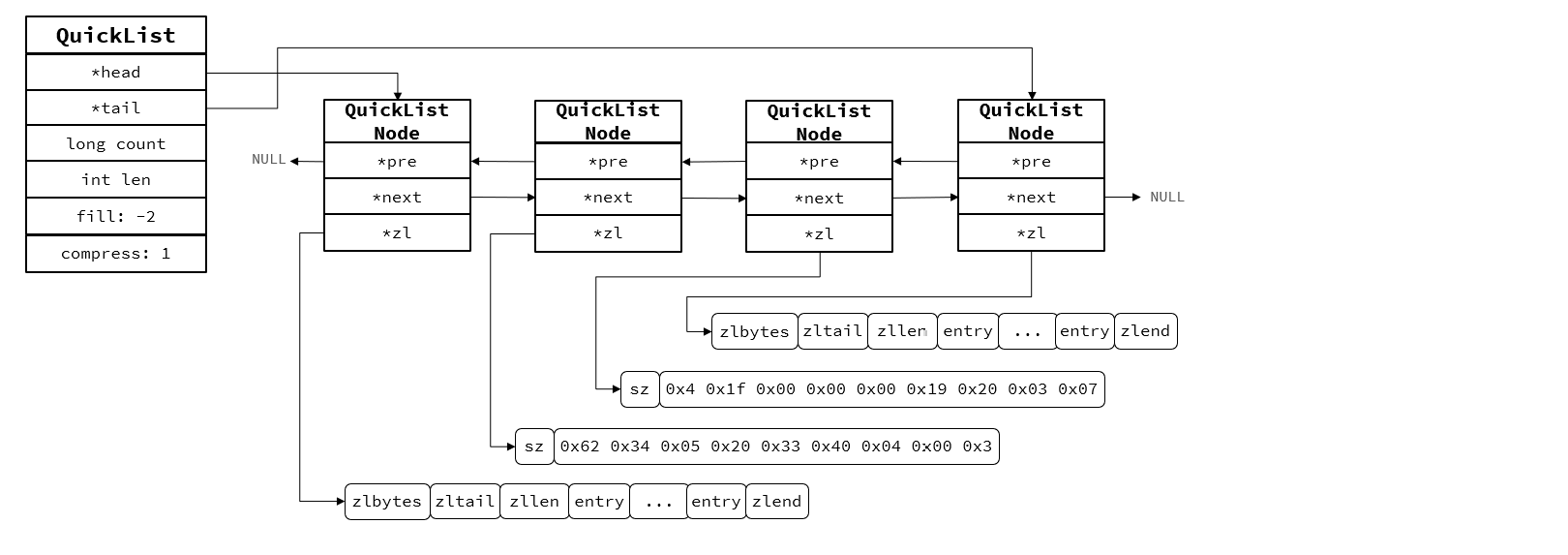
QuickList特性:
1.每个节点都是ZipList的双端链表
2.节点采用ZipList,解决传统链表的内存占用
3.控制ZipList大小,解决传统连续内存空间申请问题
4.中间节点可压缩,节省内存
SkipList跳表
是个链表,但不是普通链表,不同节点之间跨度不一样。
1.元素按照升序排列储存
2.节点可能包含多个指针,指针跨度不同
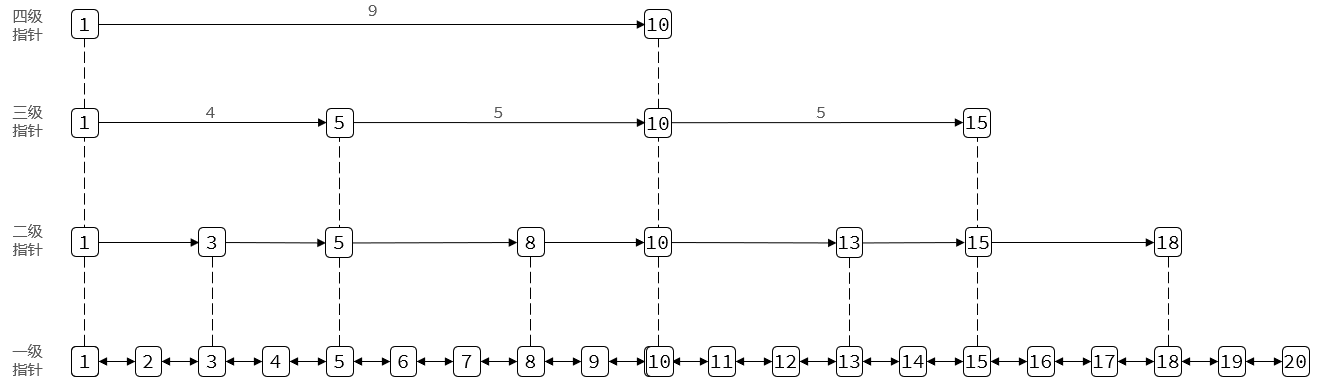
为了更快的找到所需要的元素,SkipList采用这种结构类似于二分查找。
以下是结构源码:
// t_zset.c
typedef struct zskiplist {
// 头尾节点指针
struct zskiplistNode* header, * tail;
// 节点数量
unsigned long length;
// 最大的索引层级,默认是1
int level;
} zskiplist;
// t_zset.c
typedef struct zskiplistNode {
sds ele; // 节点存储的值
double score;// 节点分数,排序、查找用
struct zskiplistNode* backward; // 前一个节点指针
struct zskiplistLevel {
struct zskiplistNode* forward; // 下一个节点指针
unsigned long span; // 索引跨度
} level[]; // 多级索引数组
} zskiplistNode;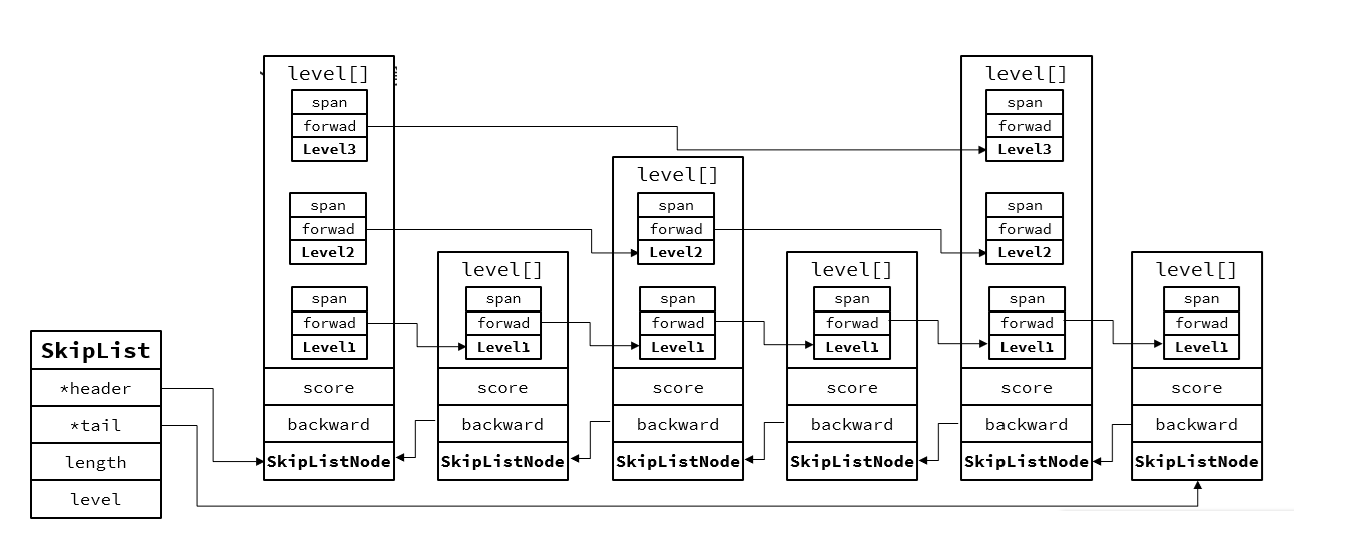
特性:
1.跳表是一个双向链表,每个节点包含存储的值和排序用的socre,用来保存别的节点的ele数组
2.节点按照score值排序,score值一样按照ele字典排序
3.每层指针到下一节点跨度不同,层级越高跨度越大
4.增删改查的效率与红黑树基本一致
RedisObject
在Redis中任意数据类型的键和值都会被封装在一个RedisObject中,也叫做Redis对象。
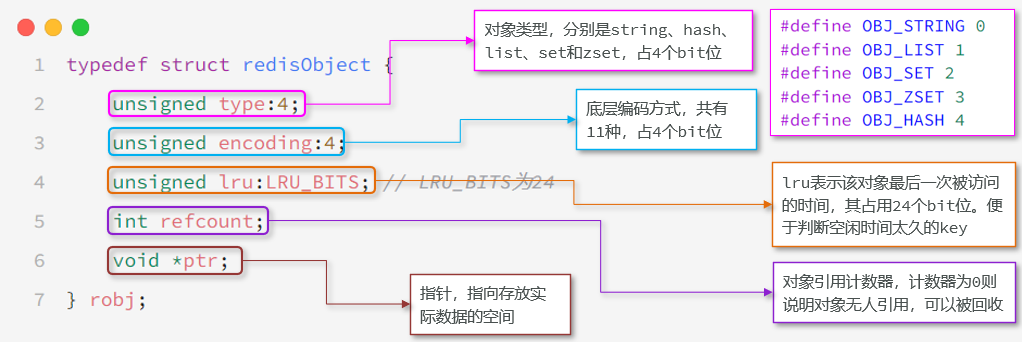
Redis会根据储存不同的数据类型选择不同的编码格式,共包含11种不同类型。
| 编号 | 编码方式 | 说明 |
|---|---|---|
| 0 | OBJ_ENCODING_RAW | 动态字符串(动态长度,非预分配) |
| 1 | OBJ_ENCODING_INT | 长整型(用 long 类型存储) |
| 2 | OBJ_ENCODING_HT | 哈希表(字典,基于 dict 实现) |
| 3 | OBJ_ENCODING_ZIPMAP | 已废弃的哈希压缩结构 |
| 4 | OBJ_ENCODING_LINKEDLIST | 双端链表(旧版 List 实现) |
| 5 | OBJ_ENCODING_ZIPLIST | 压缩列表(紧凑的二进制结构) |
| 6 | OBJ_ENCODING_INTSET | 整数集合(仅存储整数的有序集合) |
| 7 | OBJ_ENCODING_SKIPLIST | 跳表(有序集合的底层实现之一) |
| 8 | OBJ_ENCODING_EMBSTR | 短字符串(固定长度,预分配内存) |
| 9 | OBJ_ENCODING_QUICKLIST | 快速列表(双向链表 + 压缩列表) |
| 10 | OBJ_ENCODING_STREAM | Stream 流(消息队列结构) |
五种数据类型
String基于简单动态字符串SDS实现,存储上限为512mb,基本编码方式是RAM
List可以从首尾操作列表中的元素,3.2版本后统一采用QuickList来实现List
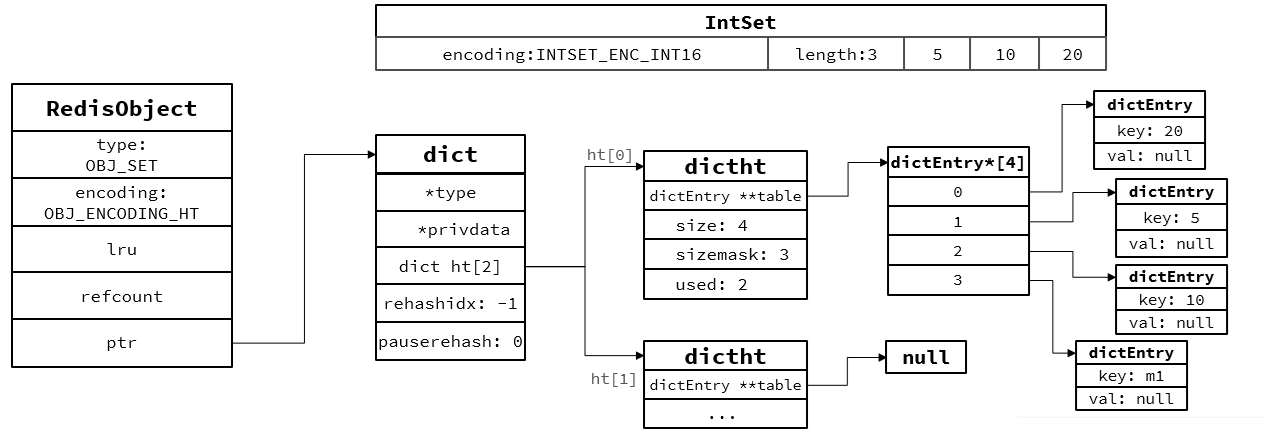
Set:
1.为了查询效率和唯一性,采用Dict编码,key为存储元素,value统一为null
2.所有数据都是整数,且元素数量不超过set-max-intset-entries,Set会采用IntSet编码
ZSet:
ZSet就是SortedSet,其中每个元素都需指定一个score 和 member值
可以根据score排序,且member必须唯一,可以根据member查询分数
当元素数数量小时,采用ZipList来节省内存,但是需要满足两个条件:
1.元素数量小于 zset_max_ziplist_entries (128)
2.每个元素都小于zset_max_ziplist_value(64)
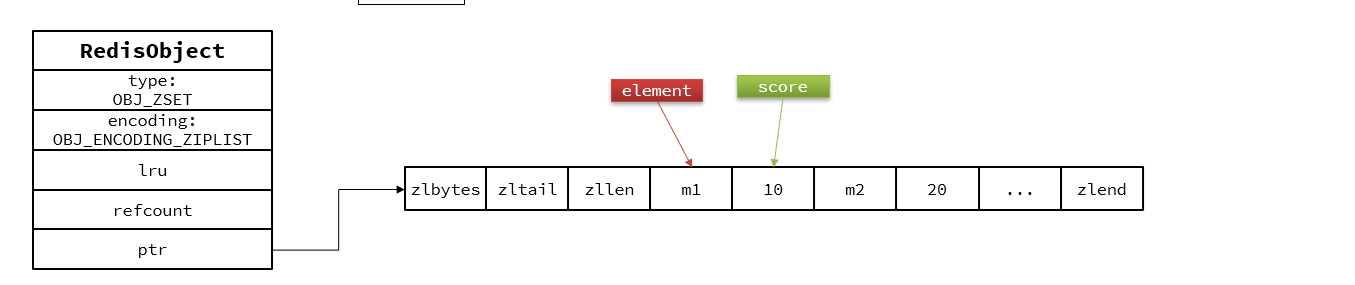
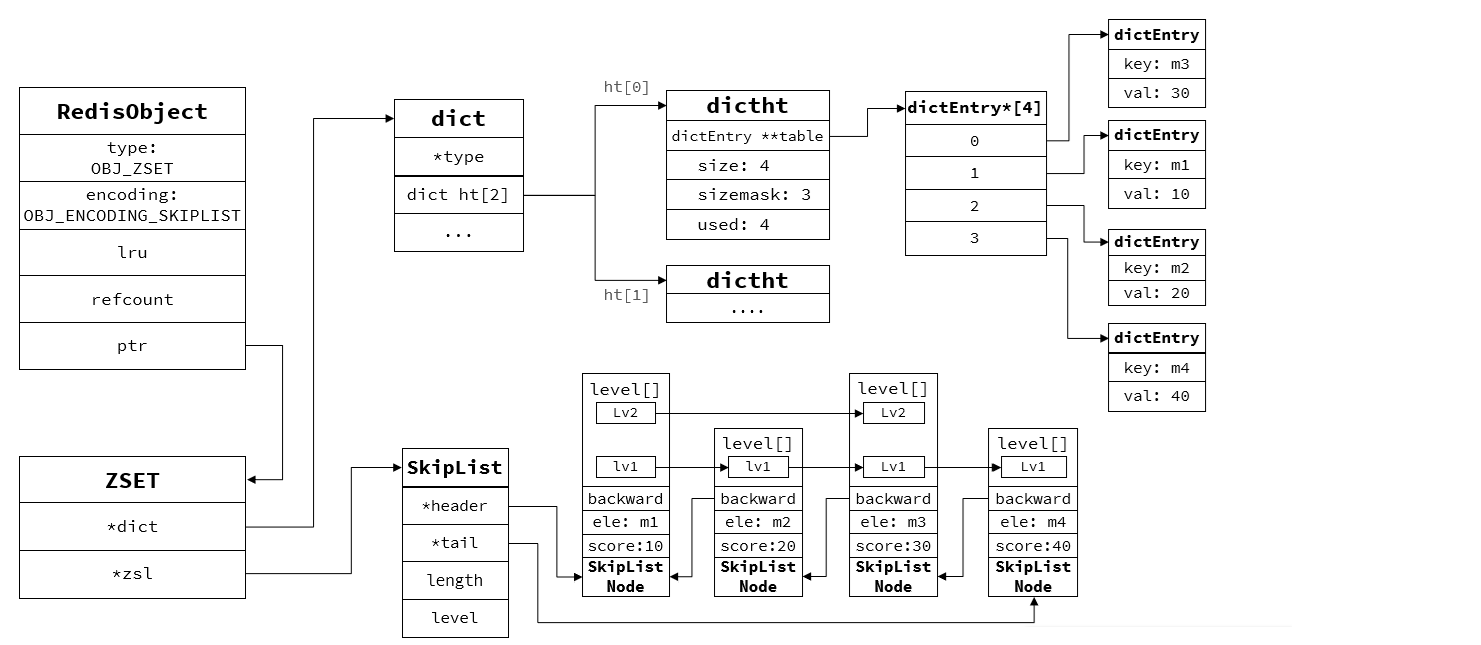
当数据量大时采用SkipList和HT结构
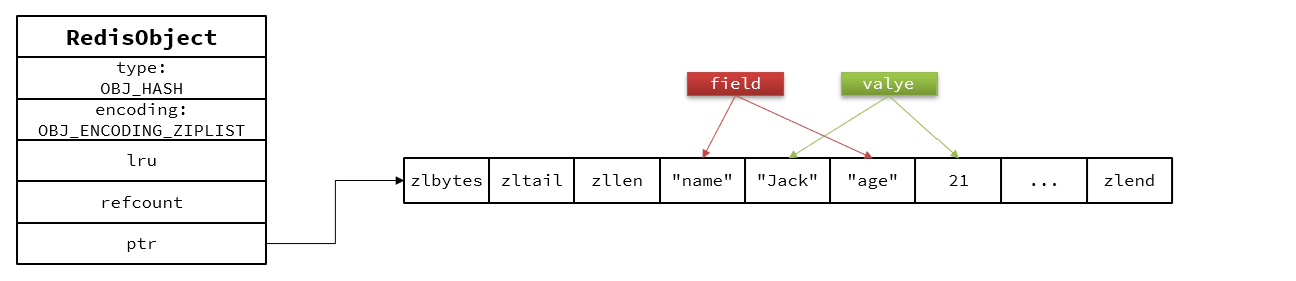
Hash:
hash底层的编码和ZSet基本一致,只需要把排序有关的SkipList去掉就行。
1.数据量小时,采用ZipList编码节省内存,ZipList中相邻的两个entry保存field和value
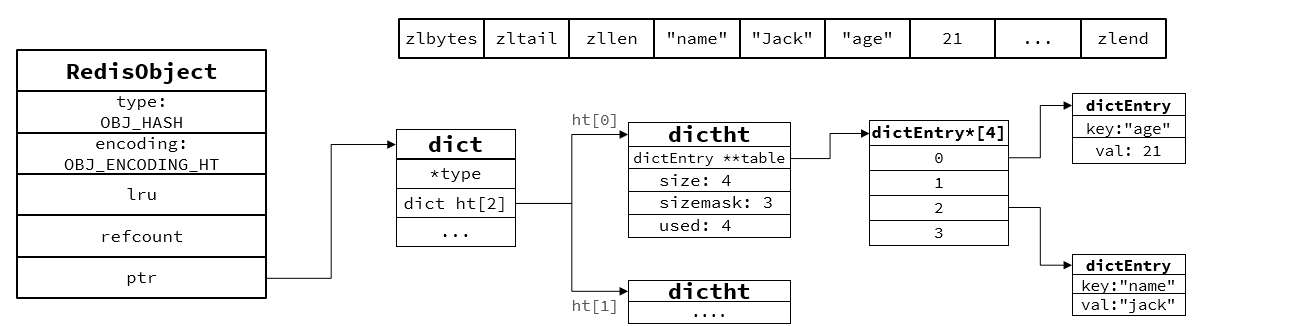
2.数据量大时,采用HT编码,就是Dict,触发条件是:元素数量超过512,每个entry超过64字节


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









