







此章将讲述多线程服务器(注意在LINUX环境下是pthread.h)

如下代码实例:
#include<iostream>
#include<pthread.h>
#include <unistd.h>
void* thread_main(void* arg);
int main(int argc,char* argv[]){
pthread_t id;
int thread_param=5;
if(pthread_create(&id,nullptr,thread_main,(void*)&thread_param)!=0){
puts("pthread_create()error");
return -1;
}
sleep(10);
puts("end of main");
return 0;
}
void* thread_main(void* arg){
int i=0;
int cnt=*((int*)arg);
for(;i<cnt;i++){
sleep(1);
puts("running thread");
}
return nullptr;
}注意在LINUX环境下直接编译会出错,虽然加上了<pthread.h> 但是会报错,因为是没有包含所需要的库,编译的时候+一个-pthread即可。

如上:注意pthread函数第四个参数是传递给第三个参数(函数指针),作为其调用的参数,第四个参数要强制转换为void* ,第三个参数指向的调用函数形参和返回类都是void*,注意。

注意代码中的sleep函数是为了让线程充分执行,如果主进程终止,那么其创建的线程也会终止。所以调用sleep函数延长主进程。
那么在多线程中是否必须运用SLEEP函数呢?

我们马上将介绍线程ID的用法,此用法是调用pthread_join函数

如上:当MAIN()函数主进程运行到pthread_join函数时,主进程会停止等待线程运行完毕后才会接着执行,这样就很好确定了执行顺序.下面是代码实例:
#include<iostream>
#include<pthread.h>
#include <unistd.h>
#include <string.h>
void* thread_main(void* arg);
int main(int argc,char* argv[]){
pthread_t id;
int thread_param=5;
void* thr_ret;
if(pthread_create(&id,nullptr,thread_main,(void*)&thread_param)!=0){//第四个参数强制转换为VOID* 作为第三个函数指针的形参
puts("pthread_create()error");
return -1;
}
if(pthread_join(id,&thr_ret)!=0){//线程返回的消息存入thr_ret
puts("pthread_join()error");
return -1;
}
std::cout<<"the thread return message: "<<(char*)thr_ret<<std::endl;//注意指针的强制转换-
return 0;
}
void* thread_main(void* arg){
int i=0;
int cnt=*((int*)arg);
char* meg=new char [50];
strcpy(meg,"hello i am pthread");
for(;i<cnt;i++){
sleep(1);
puts("running thread");
}
return (void*)meg;
}
其实很简单对吧,多线程的好处就是可以更好确定执行顺序,比多进程更加清晰些。
如果想让确保线程安全退出,没有留下任何杂质东西,可以调用如下两个函数



注意setcancelstate和setcanceltype是对于线程来调用的。
下面介绍信号量函数,信号量函数是用来在满足特定条件下通知一些线程开始运行的共享资源量
学过操作系统的各位都明白,多线程同时进行时,可能访问临界区资源,但是临界区资源只能被一个线程占用,所以多个线程一同访问此资源的代码块时可能会发生错误。临界区至少存在着这一类代码。


如上 多数函数是线程安全函数并且非线程安全函数里大多数有对应的线程安全函数,所以在多线程中一般要加上特定的宏和编译时加入特定的选项,如上图。
pthread_create(&id1,nullptr,thread_sum1,(void*)sum1);
pthread_create(&id2,nullptr,thread_sum1,(void*)sum2);//不需要传递参数就是nullptr;
pthread_join(id1,nullptr);//不需要接受返回值就是nullptr
pthread_join(id2,nullptr);(想让多线程能访问同一变量,此变量最好是全局变量,但多个线程访问同一个变量也会出现问题)
加入一个全局变量99 我们想同过两个线程,每个线程都使其自增1,最后变为101;

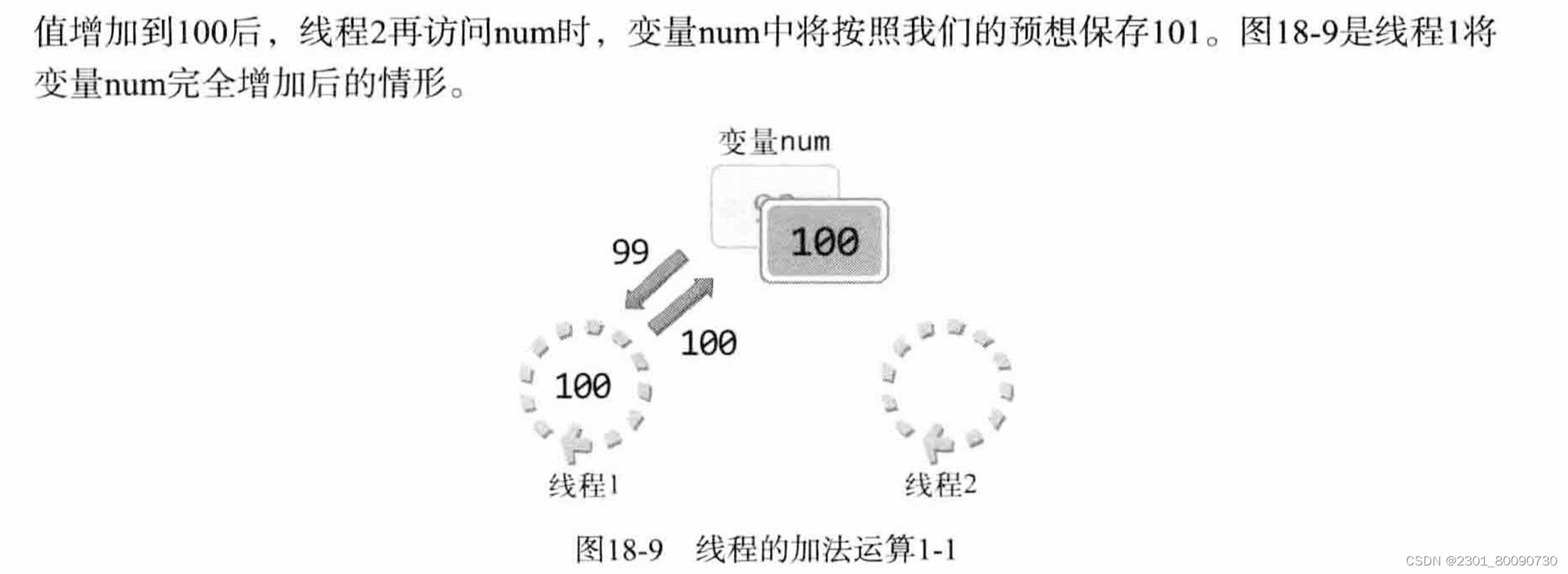
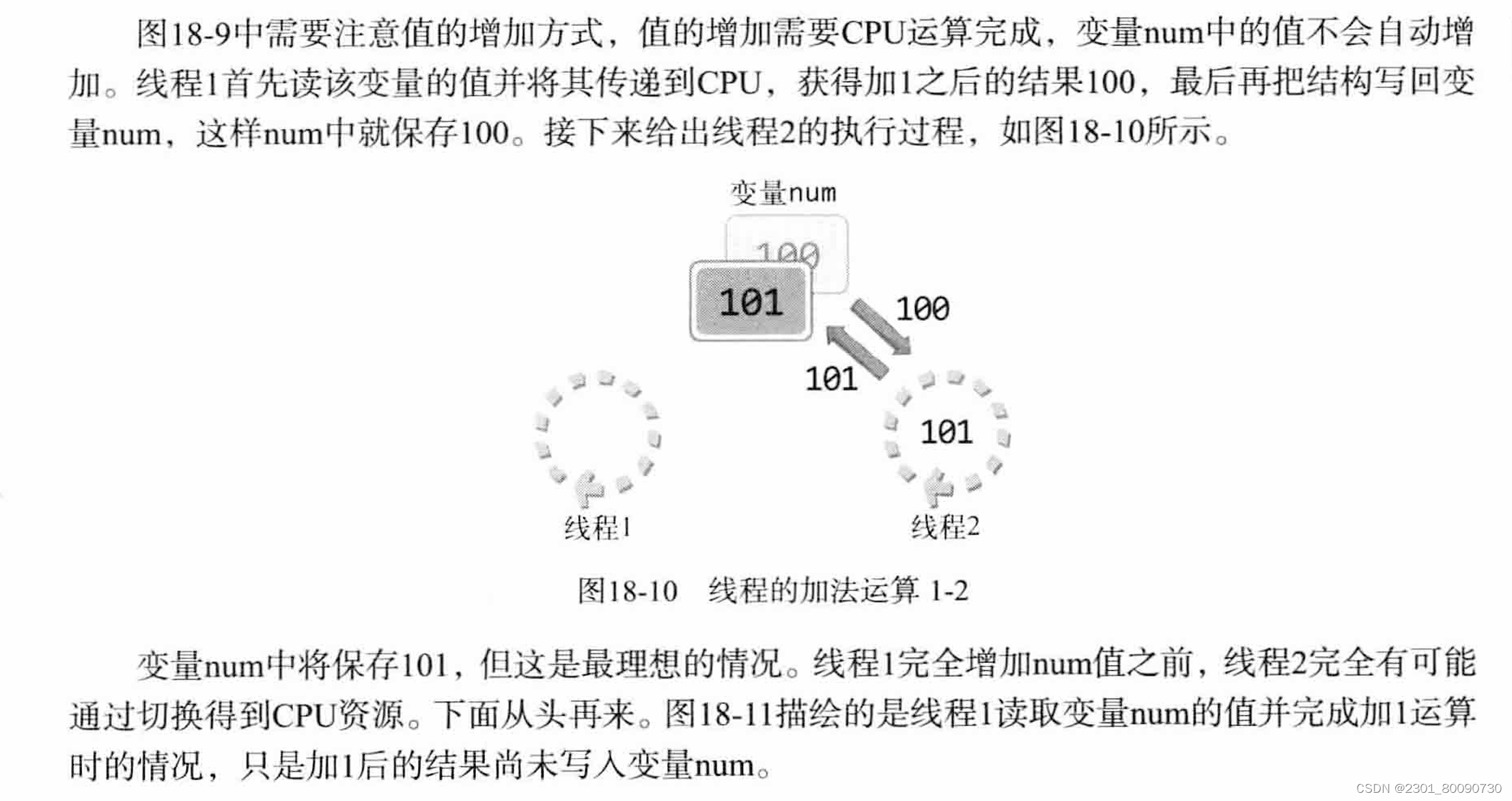
如上 首先线程读到变量,将其拿给CPU计算+1后返回给该线程,然后该线程把改变了的值返回给变量,这时变量被覆盖为100,此时线程二在进行相同的操作,最后值变为101;但是当线程1完成自增之前,线程二可能会抢占cpu.如下
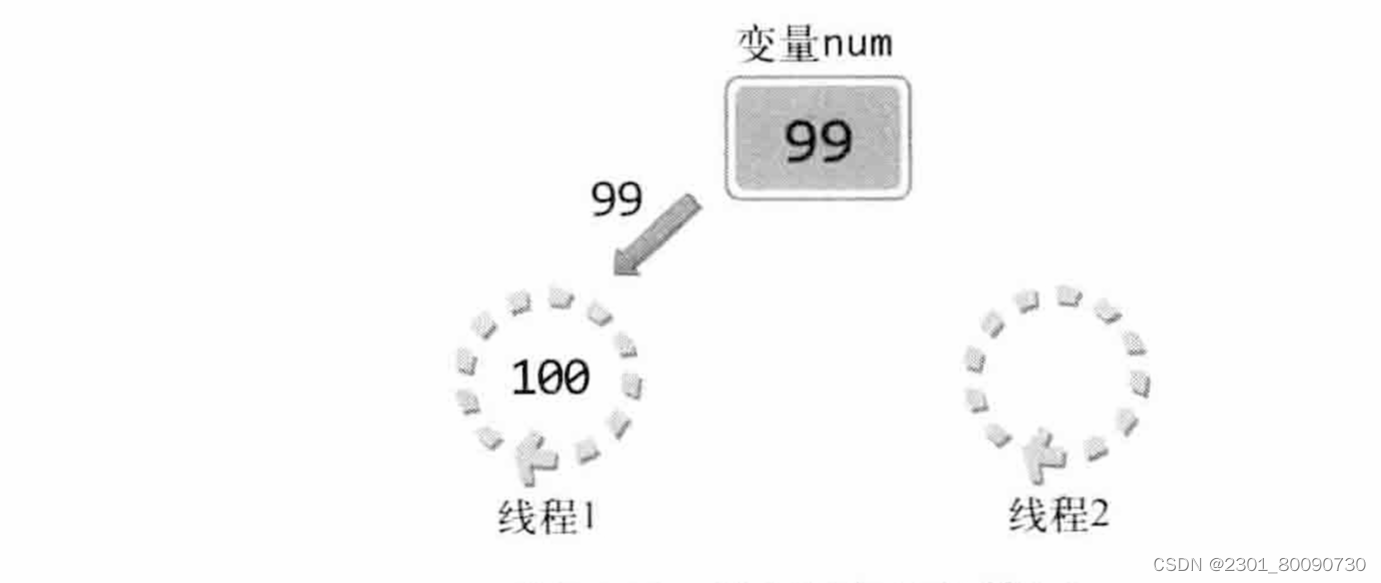
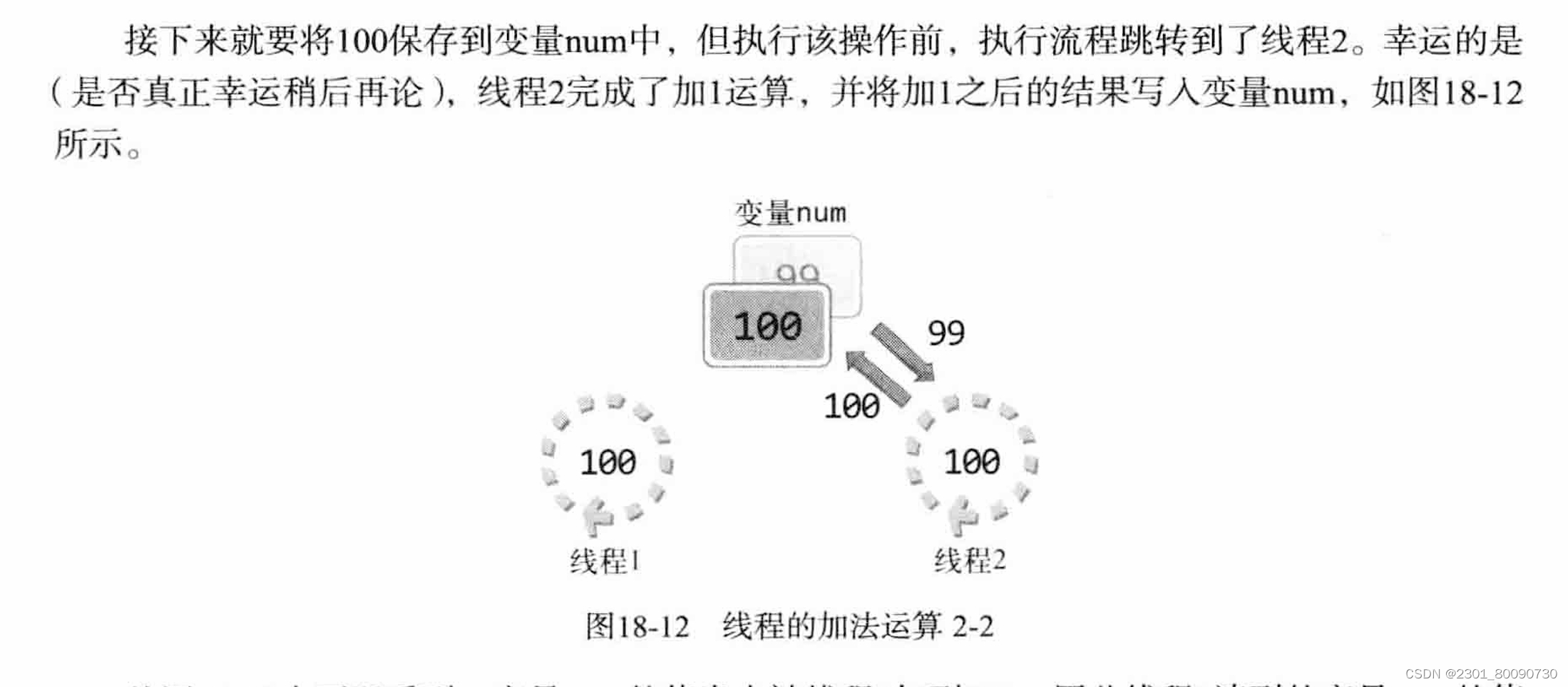

如上例子,我们应该阻止线程抢占资源。多线程时会抢占CPU,这样会出问题。那么我们如何解决如此问题呢?需要互斥量和信号量。并且我们需要从以下两个方面考查:

操作系统里有相关改变,加上锁等等。下面介绍互斥量的创建和销毁函数


但尽量还是用pthread_mutex_init来初始化
下面介绍用互斥量来锁住或释放资源的函数

即在临界区的部分,只能有一个线程访问,其他线程不能访问。下面是代码实例;
先访问的线程调用LOCK函数锁住,给自己运行,当自己运行完时解锁,允许其他线程来使用资源。(本质即使CPU调度后其他线程也不允许访问)
#include<iostream>
#include<pthread.h>
#include <unistd.h>
#include <string.h>
const int size=100;
void* pthread_inc(void* m1);
void* pthread_dsc(void* sc);
pthread_mutex_t mutex;//创造信号量
long long sum=0;
int main(int argc,char* argv[]){
pthread_t sp[size];
pthread_mutex_init(&mutex,nullptr);//注册死锁
for(int i=0;i<size;i++){
if(i%2){
pthread_create(&(sp[i]),nullptr,pthread_inc,nullptr);
}else{
pthread_create(&(sp[i]),nullptr,pthread_dsc,nullptr);
}
}
//注册100个线程
for(int i=0;i<size;i++)
pthread_join(sp[i],nullptr);//按顺序执行线程 但为了其他线程抢占 要上锁
std::cout<<sum<<std::endl;
pthread_mutex_destroy(&mutex);
return 0;
}
void* pthread_inc(void* m1){
pthread_mutex_lock(&mutex);
for(int i=0;i<500000;i++){
sum+=1;
}
pthread_mutex_unlock(&mutex);
return nullptr;
}
void* pthread_dsc(void* sc){
for(int i=0;i<500000;i++){
pthread_mutex_lock(&mutex);
sum-=1;
pthread_mutex_unlock(&mutex);
}
return nullptr;
}pthread_dsc与pthread_inc中用了互斥锁 但是前者解锁上锁是500000 后者上锁解锁是1次,在实际的代码中,要控制好临界区资源的大小和调用解锁和上锁的次数,以防过多的开销。
与互斥量接近的是信号量,下面介绍信号量函数。


注意信号量不能小于0,等于零时陷入阻塞,大于0时跳出阻塞。sem_t类似于标准库std::atomic<bool>,信号量本质是可以来实现无锁的数据结构的。
set_wait(&sem);//信号量变为0
//临界区开始
//。。。。。
//临界区结束
set_post(&sem);//信号量变为1即有线程调用SET_WAIT后进入临界区时,还未调用SET_POST函数期间,不允许其他进程进入临界区,该临界区资源独享。
#include<iostream>
#include<pthread.h>
#include<semaphore.h>
using namespace std;
void* ac1(void* s1);
void* ac2(void* s2);
static sem_t sem1;
static sem_t sem2;//设置两个信号量
static int num=0;
int main(int argc,char* argv[]){
pthread_t id1,id2;//要调用多少个函数就设置多少个进程
sem_init(&sem1,0,0);
sem_init(&sem2,0,1);//进行赋值
pthread_create(&id1,nullptr,ac1,nullptr);
pthread_create(&id2,nullptr,ac2,nullptr);//注册线程
pthread_join(id1,nullptr);
pthread_join(id2,nullptr);//执行线程
sem_destroy(&sem1);
sem_destroy(&sem2);
return 0;
}
void* ac1(void* m1){
for(int i=0;i<5;i++){
fputs("place:",stdout);
sem_wait(&sem2);
scanf("%d",&num);
sem_post(&sem1);
}
return nullptr;
}
void* ac2(void* m2){
int sum=0;
for(int i=0;i<5;i++){
sem_wait(&sem1);
sum+=num;
sem_wait(&sem2);
}
cout<<"the sum is"<<sum<<endl;
return nullptr;
}当信号量为0时,进程调用sem_wait会被阻塞 知道对应信号量变为1时,其才能调用sem_wait使信号量-1,自己进入临界区,其他线程不能访问,如上代码:先进行ac1代码,sem2首先为1,线程执行后调用ac1中sem_wait变为0,此时sem1,sem2都为零,即使ac1中还未调用sem_post使sem1变为1就发生cpu抢占,线程2也无法执行ac2,cpu再次被线程一抢占后调用sem_post使得sem1变为1,这时线程2抢占后就可以执行ac2,ac2调用sem_wait后sem_one又变为0 ,此时sem1 sem2都为零,任何线程无法调用ac1且只有一个线程能调用ac2,知道调用ac2中的sem_post后sem2变为1。如上就是一个循环。

下面介绍条件变量:
条件变量的作用是在线程并发中,当满足一定条件后通知一些线程唤醒,反之就会被阻塞。其是多个线程之间的一种共享数据


注意pthread_cond_wait函数类似于标准库的std::condtion_variable::wait只不过后者是靠相匹配的拉姆达表达式进行判断。但两者一样:未满足条件时会被放进等待列对中,满足条件时就会被唤醒出来开始工作。
线程的销毁

即detach函数使用后线程与原来主进程无关了,自己干自己的,所以调用时要各外注意
相信大家已经知道哪部分代码要上锁了,即多个线程运行时可能会共同访问的代码块或者访问的变量(大部分为全局变量,注意这部分代码要上锁)。
下面介绍多线程的服务端,客户端代码。
服务端:
#include<iostream>
#include<sys/socket.h>
#include<arpa/inet.h>
#include<unistd.h>
#include<pthread.h>
#include<string.h>
void* handle_clnt(void* arg);
void sendmess(char* mess,int len);
const int MAX_SIZE=100;
const int MAX_CLNT=256;
int clnt_cnt=0;
int clnt_socks[MAX_CLNT];
pthread_mutex_t mutex;
int main(int argc,char* argv[]){
int serv_sock,clnt_sock,strlen;
struct sockaddr_in serv,clnt;
socklen_t size;
pthread_t id;
if(argc!=2){
std::cout<<"error"<<std::endl;
exit(1);
}
pthread_mutex_init(&mutex,nullptr);
serv_sock=socket(PF_INET,SOCK_STREAM,0);
memset(&serv,0,sizeof(serv));
serv.sin_family=AF_INET;
serv.sin_port=htons(atoi(argv[1]));
serv.sin_addr.s_addr=htonl(INADDR_ANY);
if(bind(serv_sock,(struct sockaddr*)&serv,sizeof(serv))==-1){
std::cout<<"bind()error"<<std::endl;
}
if(listen(serv_sock,5)==-1){
std::cout<<"listen()error"<<std::endl;
}
while(1){
size=sizeof(clnt);
clnt_sock=accept(serv_sock,(struct sockaddr*)&clnt,&size);
pthread_mutex_lock(&mutex);
clnt_socks[clnt_cnt++]=clnt_sock;//连接服务器的所有文件描述符都存入其中
pthread_mutex_unlock(&mutex);
pthread_create(&id,nullptr,handle_clnt,(void*)&clnt_sock);
pthread_detach(id);//创造线程 线程与主进程脱离 类似于并发服务器
std::cout<<"connect the clnt"<<clnt_sock<<" the ip"<<(inet_ntoa(clnt.sin_addr));
}
close(serv_sock);
return 0;
}
//线程调用此函数
void* handle_clnt(void* arg){
int cil_sock=*((int*)arg);
int strlen=0;
char buf[MAX_SIZE];
while((strlen=read(cil_sock,buf,MAX_SIZE))!=0){
sendmess(buf,strlen);//进行传输回复消息 如果客户端没有传递信息 则会一直阻塞在判断while判断处 当对方套接字关闭套接字 传输FIN消息 这时进行套接字的删除
}
// 进行删除 进行上锁 把当前客户端删去再进行其他操作
pthread_mutex_lock(&mutex);
for(int i=0;i<clnt_cnt;i++){
if(clnt_socks[i]==cil_sock){
while(i<clnt_cnt-1){
clnt_socks[i]=clnt_socks[i+1];
i++;//顺序表操作 依次前移
}
break;
}
}
clnt_cnt--;
pthread_mutex_unlock(&mutex);
close(cil_sock);
return nullptr;
}
void sendmess(char* mess,int len){
pthread_mutex_lock(&mutex);
for(int i=0;i<clnt_cnt;i++)
write(clnt_socks[i],mess,len);
pthread_mutex_unlock(&mutex);
}
服务端代码上锁的正是全局变量,上述代码类似于SELECT

下面是客户端代码。
#include<iostream>
#include<sys/socket.h>
#include<arpa/inet.h>
#include<unistd.h>
#include<pthread.h>
#include<string.h>
const int MAX_SIZE=100;
const int MAME_SIZE=20;
void* readmes(void* c1);
void* sendmes(void* c2);
char name[MAME_SIZE]="[DEFAULT]";
char msg[MAX_SIZE];
int main(int argc,char* argv[]){
int sock;
struct sockaddr_in serv;
pthread_t m1,m2;
void* res;
if(argc!=4){
std::cout<<"error"<<std::endl;
exit(1);
}
sprintf(name,"[%s]",argv[3]);
sock=socket(PF_INET,SOCK_STREAM,0);
memset(&serv,0,sizeof(serv));
serv.sin_family=AF_INET;
serv.sin_addr.s_addr=inet_addr(argv[1]);
serv.sin_port=htons(atoi(argv[2]));
if(connect(sock,(struct sockaddr*)&serv,sizeof(serv))==-1){
std::cout<<"connect()error"<<std::endl;
}
pthread_create(&m1,nullptr,sendmes,(void*)&sock);
pthread_create(&m2,nullptr,readmes,(void*)&sock);
//创建读和写的线程
pthread_join(m1,&res);
pthread_join(m2,&res);
close(sock);
return 0;
}
void* sendmes(void* m2){
int sock=*((int*)m2);
char time[1024];
while(1){
fgets(msg,MAX_SIZE,stdin);
if(!strcmp(msg,"q\n")||!strcmp(msg,"Q\n")){
close(sock);
exit(0);
}
sprintf(time,"%s %s",name,msg);
write(sock,time,sizeof(time));
}
return nullptr;
}
void* readmes(void* m1){
int sock=*((int*)m1);
char buf[1024];
int strlen;
while(1){
strlen=read(sock,buf,1024);
if(strlen==-1){
return (void*)-1;
}
buf[strlen]=0;
fputs(buf,stdout);//输出到屏幕上
}
return nullptr;
}
对于客户端来说,只有写操作才访问了全局变量,即只有一个线程访问,所以不需要给读写操作加锁。
下面一点是十分重要的:
主进程 fork 之后,仅会复制发起调用的线程,不会复制其他线程,如果某个线程占用了某个锁,但是到了子进程,该线程是蒸发掉的,子进程会拷贝这把锁,但是不知道谁能释放,最终死锁。(所以注意fork()的时候要注意不要复制锁的资源)

代码实例
pthread_mutex_t mut;
void* text(void* arg){
std::cout<<"chr lock"<<std::endl;
pthread_mutex_lock(&mut);
sleep(5);
pthread_mutex_unlock(&mut);
}
void pr(){
pthread_mutex_lock(&mut);
}
void infork(){
pthread_mutex_unlock(&mut);
}
int main(){
pthread_mutex_init(&mut,NULL);
pthread_t id;
pthread_create(&id,NULL,text,NULL);
pthread_atfork(pr,infork,infork);
sleep(1);
int pid=fork();
if(pid<0){
pthread_join(id,NULL);
pthread_mutex_destroy(&mut);
return 1;
}else if(pid==0){
pthread_mutex_lock(&mut);
std::cout<<"i am ch";
pthread_mutex_unlock(&mut);
exit(0);
}else{
wait(NULL);//等待子进程结束 所以会死锁
// std::cout<<"i am handsome"<<std::endl;
}
pthread_join(id,NULL);
pthread_mutex_destroy(&mut);
std::cout<<"over\n";
return 0;
}注意pthread_atfork(A,B,C)中的A是在fork()之前进行执行,
B是在fock()返回之前父进程期间实行,C是在fock()返回前子进程期间执行。所以可以合理设计函数A,B,C来防止死锁的发生。(不是仅仅是关于锁的操作,其他分开操作也可以调用pthread_atfork())















 2590
2590











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









