






 本文介绍了DOM(文档对象模型),它是浏览器操作HTML或XML文档的核心API。DOM树构建了HTML文档的树状结构,DOM对象由浏览器生成并允许开发者直接或间接修改元素属性。主要讲解了querySelector和querySelectorAll的选择器功能,以及它们的区别和使用方法。
本文介绍了DOM(文档对象模型),它是浏览器操作HTML或XML文档的核心API。DOM树构建了HTML文档的树状结构,DOM对象由浏览器生成并允许开发者直接或间接修改元素属性。主要讲解了querySelector和querySelectorAll的选择器功能,以及它们的区别和使用方法。
什么是DOM
- DOM(DocumentObjectModel——文档对象模型)是用来呈现以及与任意HTML或XML文档交互的API
- 白话文:DOM是浏览器提供的一套专门用来操作网页内容的功能
DOM作用
- 开发网页内容特效和实现用户交互
DOM树
DOM树是什么
- 将HTML文档以树状结构直观的表现出来,我们称之为文档树或DOM树
- 描述网页内容关系的名词
- 作用:文档树直观的体现了标签与标签之间的关系
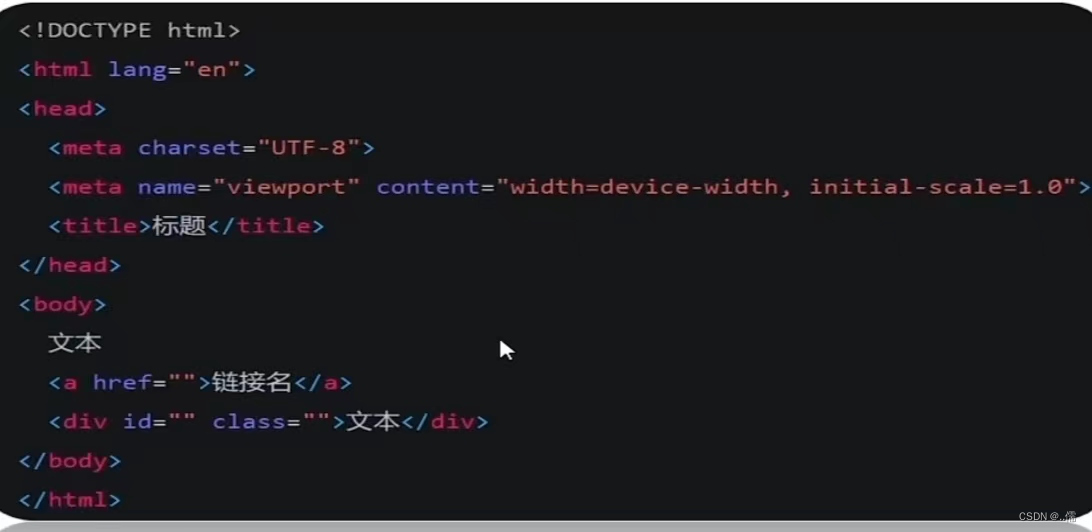
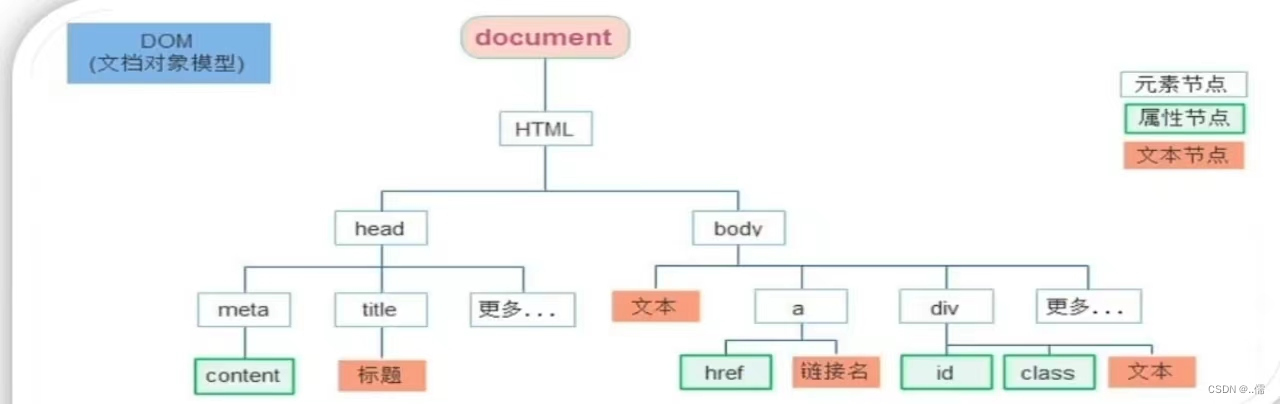
DOM对象
DOM对象:浏览器根据html标签生成JS对象
- 所有的标签属性都可以在这个对象上面找到
- 修改这个对象的属性会自动映射到标签身上
根据CSS选择器来获取DOM元素
1.选择匹配的第一个元素
语法:
document.querySelector('css选择器')参数:包含一个或多个有效的CSS选择器字符串
返回值:CSS选择器匹配的第一个元素,一个HTMLElement对象。
2.选择匹配的多个元素
语法:
document.querySelectorAl1('css选择器')参数:包含一个或多个有效的CSS选择器字符串
返回值:CSS选择器匹配的NodeList对象集合
document.querySelectorAll('ul 1i')document.querySelectorAll('css选择器’)用上述方法得到的是一个伪数组:
- 有长度有索引号的数组
- 但是没有pop()push()等数组方法
- 想要得到里面的每一个对象,则需要遍历(for)的方式获得。
注意事项
哪怕只有一个元素,通过querySelectAl)获取过来的也是一个伪数组,里面只有一个元素而已
总结:
1.获取一个DOM元素我们使用谁?能直接操作修改吗?
>querySelector()
>可以
2.获取多个DOM元素我们使用谁?能直接修改吗?如果不能可以怎么做到修改
>querySelectorAll
>不可以,只能通过遍历的方式一次给里面的元素做修改
1.获取页面中的标签我们最终常用那两种方式?
- querySelectorAll()
- querySelector()
2.他们两者的区别是什么?
- querySelector()只能选择一个元素,可以直接操作
- querySelectorAll()可以选择多个元素,得到的是伪数组,需要遍历得到每一个元素
3.他们两者小括号里面的参数有神马注意事项?
- 里面写css选择器
- 必须是字符串,也就是必须加引号
其他获取DOM元素方法(了解)
/根据id获取一个元素
document.getElementById('nav')//根据标签获取一类元素获取页面所有div
document.getElementsByTagName('div")/根据类名获取元素获取页面所有类名为w的
document.getElementsByClassName('w')














 5074
5074











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









