






研究意义
传统的机器学习方法假设训练数据和测试数据从相同的分布中独立且相同地提取。然而,当测试分布(目标)与训练分布(源)不同时,我们就会面临分布移位的问题。这种转移对部署在野外的机器学习系统构成了重大挑战,例如不同摄像机捕获的图像,不同城市的道路场景,以及不同医院的成像设备。因此,研究界开发了各种泛化或自适应技术,以提高模型对分布变化的鲁棒性。
研究背景
机器学习方法力求在训练过程中获得一个鲁棒模型,即使在分布变化的情况下也能很好地泛化到测试样本。然而,由于未知的测试分布,这些方法往往会受到性能下降的影响。测试时间适应(Test-time adaptation, TTA)是一种新兴的范式,它有可能在做出预测之前,在测试期间使预先训练好的模型适应未标记的数据。该范式的最新进展突出了在推理之前利用未标记数据训练自适应模型的显着好处。在本研究中,我们将TTA划分为几个不同的类别,即无源域自适应(Source-Free Domain Adaptation, SFDA) 、测试时批量适应(Test-Time Batch Adaptation, TTBA) 、在线测试时适应(Online Test-Time Adaptation, OTTA)和测试时先验适应(Test-Time Prior Adaptation, TTPA) 。
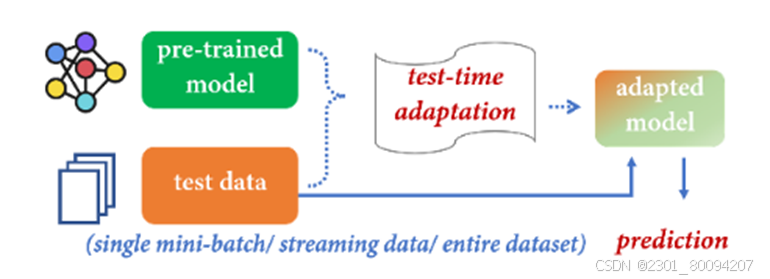
SFDA(无源域自适应Source-Free Domain Adaptation)
工作原理:SFDA的目标是在没有源域数据的情况下,利用目标域的未标记数据来调整预训练模型。这通常通过一些无监督的适应技术实现,比如利用目标域数据的聚类信息、生成模型来模拟源域数据、或者通过自监督学习的方式来提取对源域和目标域都有效的特征表示。
适用场景:SFDA适用于那些无法获取源域数据或者源域数据获取成本很高的情况。例如,在医学图像分析中,不同医院的成像设备可能产生不同分布的图像数据,而医生可能希望一个在特定设备上训练的模型能够在其他设备上同样表现良好。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









