






- 引言:当谈到互联网时,我们不可避免地提到网络爬虫,这些神奇的程序在我们的日常生活中扮演着重要的角色。今天,我们将深入了解网络爬虫,探索它们的工作原理、应用场景以及对于互联网的意义。
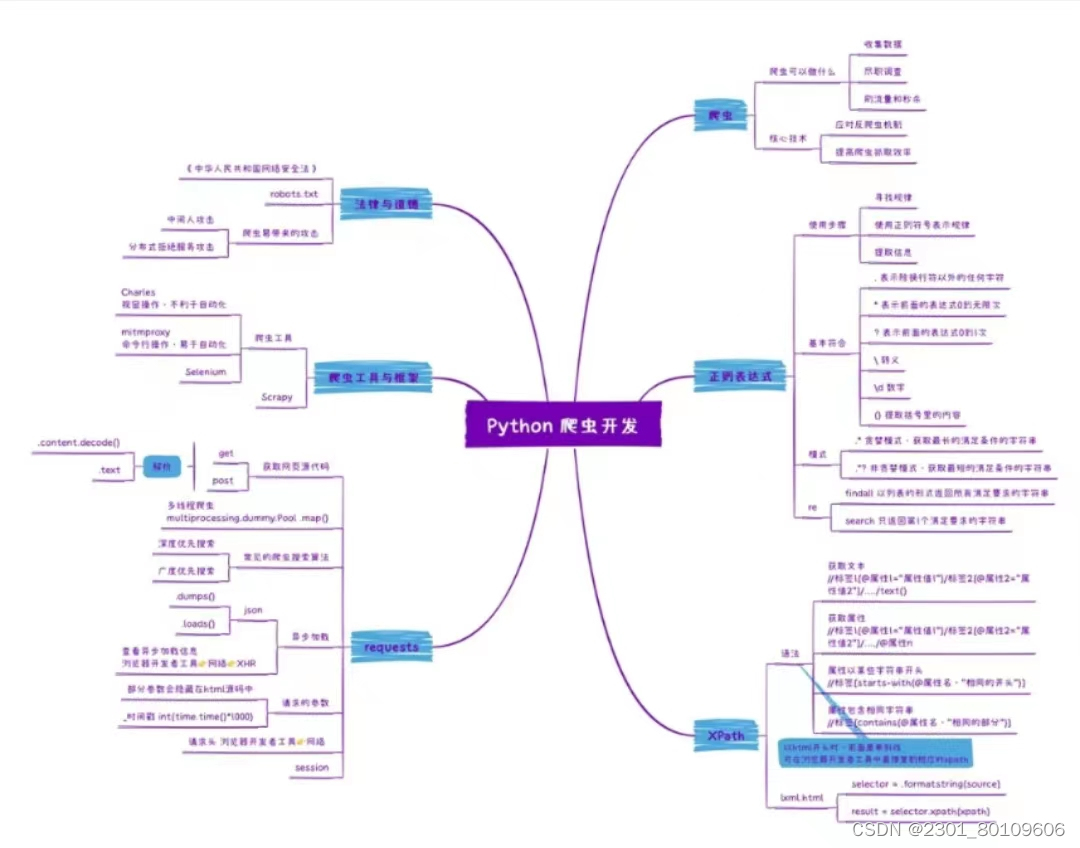
- 网络爬虫,也被称为网络蜘蛛、网络机器人或网络爬虫程序,是一种能够自动浏览互联网并收集信息的程序。它们的任务是按照预定的算法和规则,在网页间跳转、抓取数据并将其存储以备后续处理。
- 工作原理:在网页间的探索之旅
网络爬虫的工作原理类似于我们在互联网上冒险寻找信息的过程。它们从一个起始点(例如一个网页的URL)出发,然后根据一系列规则,如链接、标签等,持续地访问并抓取页面内容。这种迭代的过程使得网络爬虫能够不断扩展它们的数据收集范围。
#使用urllib快速爬取itcast网页
import urllib.request
#调用urllib.request库的urlopen方法,并传入一个url
response=urllib.request.urlopen('http://www.baidu.com')
#使用read方法获取到的网页内容
html=response.read().decode('UFT-8)
#打印网页内容- 应用场景:发挥无限潜能
网络爬虫在各个领域发挥着重要作用。搜索引擎如 Google、百度等利用爬虫收集信息,帮助用户找到他们需要的内容。金融领域利用爬虫来收集市场数据进行分析和预测。社交媒体公司也使用爬虫来监控用户行为和趋势。
以下是一个简单的使用Python的requests和BeautifulSoup库来抓取网页内容的例子:
import requests
from bs4 import BeautifulSoup
url = 'https://twitter.com/search?q=product%20review&src=typed_query'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
tweets = soup.find_all('div', class_='tweet')
for tweet in tweets:
content = tweet.find('p', class_='tweet-text').text
print(content)- 使用Scrapy框架来收集网页信息。Scrapy是一个流行的Python爬虫框架,可以轻松地抓取网页内容并提取所需的数据。
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://example.com']
def parse(self, response):
# 提取网页中的链接和文本内容
links = response.xpath('//a/@href').getall()
texts = response.xpath('//p/text()').getall()
# 将提取到的数据存储到csv文件中
with open('output.csv', 'a', newline='') as f:
writer = csv.writer(f)
writer.writerow([links, texts])该代码示例使用Scrapy框架创建一个名为MySpider的爬虫类,指定要抓取的起始URL,以及定义一个解析方法来提取网页中的链接和文本内容。提取到的数据将被存储到名为output.csv的CSV文件中。
- 在实际应用中,网络爬虫在对网页的数据进行抓取、解析之后,便可以获得最终要采集的目标数据,然后对这些目录数据进行持久化存储,以便后期投入数据研究工作中。
网络爬虫存储数据具体实例可以使用Python语言来实现。
例如,可以使用Python中的requests库获取网页数据,然后使用BeautifulSoup库解析网页数据,并将解析得到的数据存储到文件中或者数据库中。
以下是一个简单的Python爬虫程序,用于获取中国大学的排名信息,并将数据存储到CSV文件中:
import requests
from bs4 import BeautifulSoup
import csv
# 获取网页数据
url = 'https://www.shanghairanking.cn/rankings/bcur/202011'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 解析数据并存储到CSV文件中
with open('universities.csv', 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
for row in soup.find_all('tr'):
cols = row.find_all('td')
if cols:
name = cols[1].text.strip()
rank = cols[0].text.strip()
province = cols[2].text.strip()
type = cols[3].text.strip()
score = cols[4].text.strip()
writer.writerow([name, rank, province, type, score])在上述代码中,首先使用requests库发送GET请求获取网页数据,然后使用BeautifulSoup库解析网页数据,并将解析得到的数据存储到CSV文件中。在CSV文件中,每行表示一个大学的排名信息,包括学校名称、排名、所在省份、类型和总分等信息。
- 爬虫存储数据的方式可以有很多种,以下是一些常见的存储方式:
- 文件存储:爬虫可以将数据存储在本地文件中,如文本文件、CSV文件、JSON文件等。这种方式适用于小型数据集,但不适合大规模的数据处理。
- 关系型数据库:爬虫可以将数据存储在关系型数据库中,如MySQL、PostgreSQL等。这种方式可以处理大规模的数据,并提供高效的数据查询和处理功能。
- 非关系型数据库:爬虫可以将数据存储在非关系型数据库中,如MongoDB、Redis等。这种方式适用于大规模的数据存储和查询,并提供灵活的数据结构。
- 内存数据库:爬虫可以将数据存储在内存数据库中,如Redis、Memcached等。这种方式可以提供快速的数据读写操作,适用于需要实时处理的数据。
- 未来展望:技术的不断演进
随着技术的不断进步,网络爬虫也在不断演进。智能化的爬虫能够更加精准地收集数据,同时更加尊重网站的隐私和规则。对于大数据和人工智能的发展,网络爬虫将继续扮演着关键的角色,帮助我们探索和理解这个数字化的世界。
- 结语:网络爬虫是互联网世界中不可或缺的一部分。它们以其强大的数据收集能力和广泛的应用领域,为我们打开了信息的大门。然而,在使用网络爬虫时,我们也需要意识到其中的挑战与责任,以确保其合法、合规、以及对互联网生态的良性发展。网络爬虫作为探索互联网世界的魔法使者,为我们提供了无限的可能性和机遇。















 391
391











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









