






20232203 梁朔宁 2023-2024-2 《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 2322班
姓名: 梁朔宁
学号: 20232203
实验教师:王志强
实验日期:2024年5月15日
必修/选修: 公选课
1.实验内容
【1】实验整体内容:
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
(1)编写从社交网络爬取数据,实现可视化舆情监控或者情感分析。
(2)利用公开数据集,开展图像分类、恶意软件检测等
(3)利用Python库,基于OCR技术实现自动化提取图片中数据,并填入excel中。
(4)爬取天气数据,实现自动化微信提醒
(5)利用爬虫,实现自动化下载网站视频、文件等。
(6)编写小游戏:坦克大战、贪吃蛇、扫雷等等
注:在Windows/Linux系统上使用VIM、PDB、IDLE、Pycharm等工具编程实现。
【2】本实验聚焦内容:
(1)编写从社交网络爬取数据,实现自动化提取数据,并填入excel中。
(2)利用python实现爬取天气数据、电影热搜以及音乐榜单。
(3)利用爬虫实现自动化提取网站照片,实现可视化舆情监控。
2. 实验过程及结果
(一)利用爬虫技术实现百度热搜的爬取,并存于excel表格中
【1】实验四【一】过程:
(1)实验设计原因:
平时通过看百度或者微博热搜获得时事热点或者八卦信息,必然会出现感兴趣和不感兴趣的热搜,与此同时,有的时候无法立即获得相关热搜,所以可能会错过很多很好吃的瓜,那么我觉得做出这个程序可以帮助我轻松获得时事热点与八卦信息。
(2)实验设计思路:
第一部分:库函数安装:
- requests库函数:用于发送HTTP请求。
- BeautifulSoup库函数:用于解析HTML内容。
- openpyxl库函数:用于操作Excel文件。
import requests
from bs4 import BeautifulSoup
import openpyxl
第二部分:主要内容设计:
1-设置目标URL并获取页面内容:
- url:定义了百度热搜排行榜的网址。
- requests.get(url):发送GET请求到指定的URL。
- response.content:获取响应的内容。
url = 'https://top.baidu.com/board?tab=realtime'
response = requests.get(url)
html = response.content
2-使用BeautifulSoup解析HTML:
- BeautifulSoup(html, ‘html.parser’):创建一个BeautifulSoup对象,用于解析HTML。
soup = BeautifulSoup(html, 'html.parser')
3-提取热搜数据:
- soup.find_all(‘div’, {‘class’: ‘c-single-text-ellipsis’}):查找所有具有特定类名的标签。
- hot_searches.append(item.text):将每个标签的文本内容添加到hot_searches列表中。
hot_searches = []
for item in soup.find_all('div', {'class': 'c-single-text-ellipsis'}):
hot_searches.append(item.text)
4-创建并操作Excel文件:
- workbook = openpyxl.Workbook():创建一个新的Excel工作簿。
- sheet = workbook.active:获取活动的工作表。
- sheet.title = ‘Baidu Hot Searches’:设置工作表的标题。
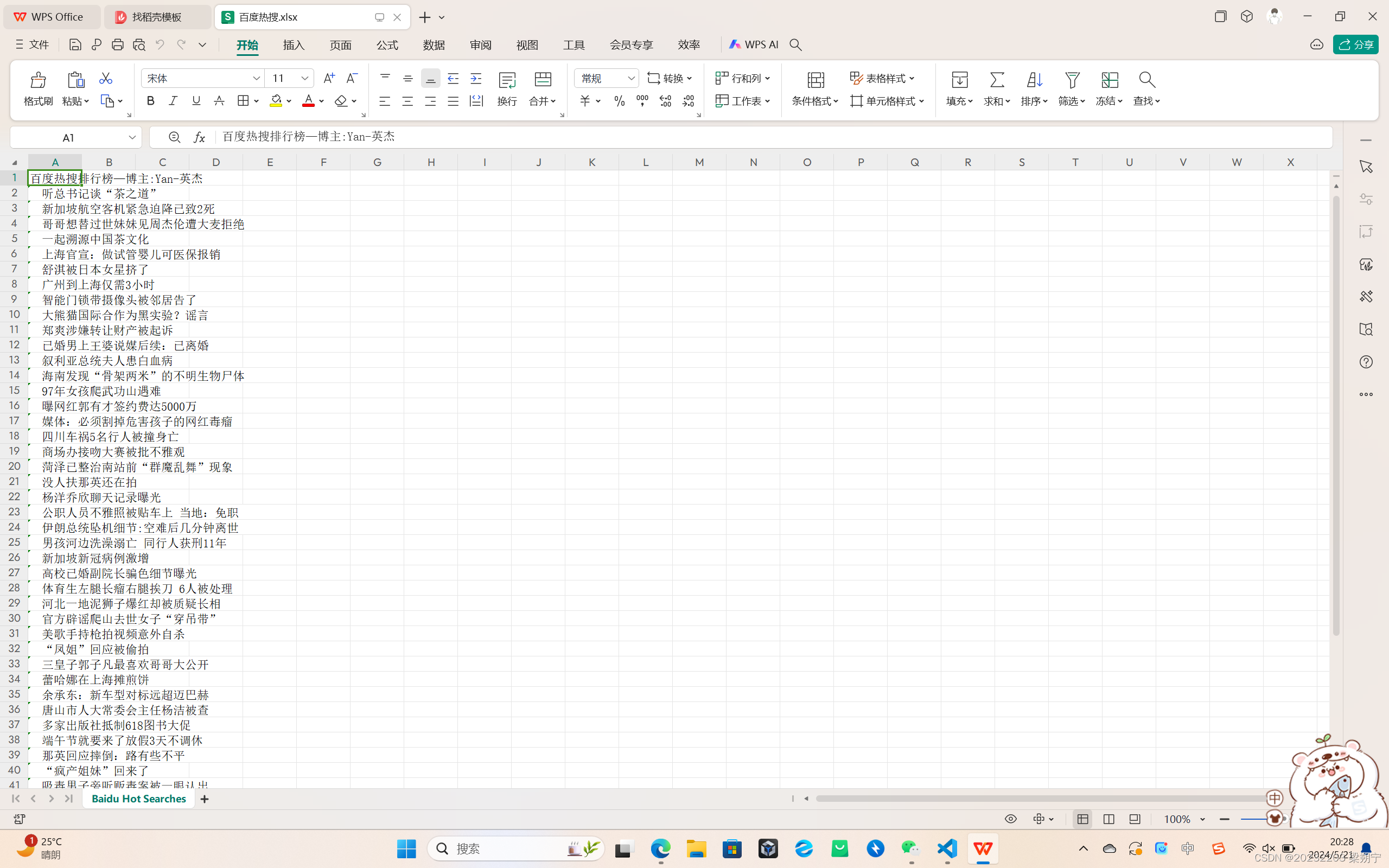
- sheet.cell(row=1, column=1, value=‘百度热搜排行榜—博主:Yan-英杰’):在工作表的第一行第一列写入标题。
- sheet.cell(row=i+2, column=1, value=hot_searches[i]):将热搜数据写入从第二行开始的每一行第一列。
- workbook.save(‘百度热搜.xlsx’):保存工作簿到名为“百度热搜.xlsx”的文件中。
workbook = openpyxl.Workbook()
sheet = workbook.active
sheet.title = 'Baidu Hot Searches'
sheet.cell(row=1, column=1, value='百度热搜排行榜—博主:Yan-英杰')
for i in range(len(hot_searches)):
sheet.cell(row=i+2, column=1, value=hot_searches[i])
workbook.save('百度热搜.xlsx')
5-输出提示信息:
- print(‘热搜数据已保存到 百度热搜.xlsx’):在控制台输出提示信息,告知用户数据已保存。
print('热搜数据已保存到 百度热搜.xlsx')
(3)实验完整代码:
import requests
from bs4 import BeautifulSoup
import openpyxl
url = 'https://top.baidu.com/board?tab=realtime'
response = requests.get(url)
html = response.content
soup = BeautifulSoup(html, 'html.parser')
hot_searches = []
for item in soup.find_all('div', {'class': 'c-single-text-ellipsis'}):
hot_searches.append(item.text)
workbook = openpyxl.Workbook()
sheet = workbook.active
sheet.title = 'Baidu Hot Searches'
sheet.cell(row=1, column=1, value='百度热搜排行榜—博主:Yan-英杰')
for i in range(len(hot_searches)):
sheet.cell(row=i+2, column=1, value=hot_searches[i])
workbook.save('百度热搜.xlsx')
print('热搜数据已保存到 百度热搜.xlsx')
【2】实验四【一】结果:
(1)成功爬取百度热搜,并将其存储于excel表格中,实现可视化。
实验一视频展示
(二)利用python实现爬取天气数据、电影热搜以及音乐榜单。
【1】实验四【二】过程:
(1)实验设计原因:
为了更便利的获得当天的必需信息,例如天气数据,与此同时,对于电影与音乐这一类可以丰富我们日常生活的信息,我们也可以利用python爬虫实现数据提取,更容易获得自己想要获取到的电影与音乐数据,减少平时搜索时间。
(2)实验设计思路:
第一部分:库函数安装:
- requests:发送HTTP请求。
- BeautifulSoup:解析HTML内容。
- time:暂停程序的执行。
- pandas:把数据保存到CSV文件。
- lxml.etree:解析HTML内容
import requests
from bs4 import BeautifulSoup
import time
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
from pandas import Series,DataFrame
import requests
from lxml import etree
import csv
第二部分:主要内容设计:
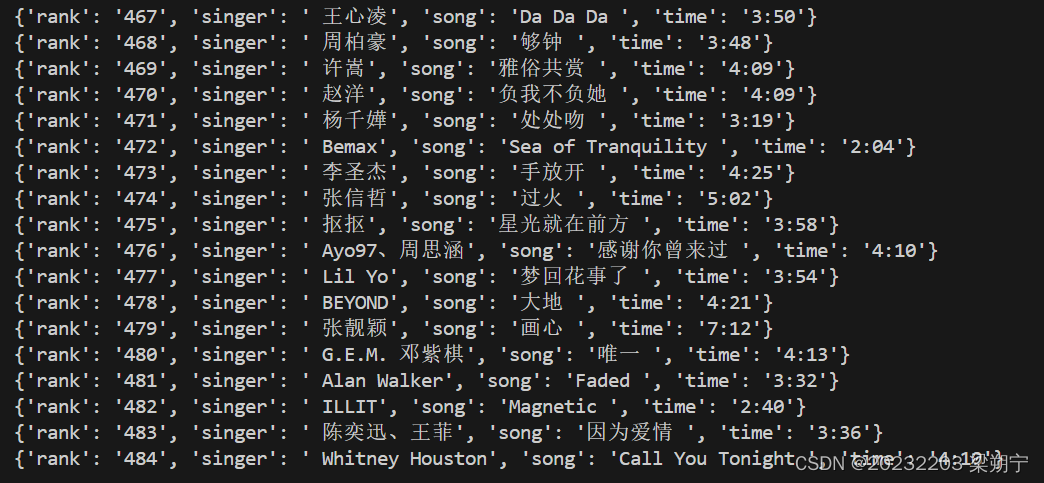
【1】实现音乐数据爬取
1-设置请求头:
- headers:定义了HTTP请求的头部信息。
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
}
2-定义函数:
- 使用requests.get(url, headers=headers)发送GET请求到指定的URL。
- BeautifulSoup(web_data.text, ‘lxml’)创建一个BeautifulSoup对象,用于解析HTML。
- select选择HTML中包含排名、歌曲、歌手和时间的元素。
- 提取文本内容。
- 创建一个字典data,包含排名、歌手、歌曲和时间信息。
- 打印出每个歌曲的信息。
def get_info(url):
web_data = requests.get(url, headers=headers)
soup = BeautifulSoup(web_data.text, 'lxml')
ranks = soup.select('span.pc_temp_num')
titles = soup.select('div.pc_temp_songlist > ul > li > a')
times = soup.select('span.pc_temp_tips_r > span')
for rank, title, time in zip(ranks, titles, times):
data = {
"rank": rank.get_text().strip(),
"singer": title.get_text().replace("\n", "").replace("\t", "").split('-')[1],
"song": title.get_text().replace("\n", "").replace("\t", "").split('-')[0],
"time": time.get_text().strip()
}
print(data)
3-特殊部分:
- 在学习过程中,我认识到请求也会对服务器造成压力,所以需要time库函数来进行延缓时间,在每次请求后,使用time.sleep(1)暂停1秒钟,避免过于频繁的请求对服务器造成压力。
for url in urls:
get_info(url)
time.sleep(1)
【2】实现对天气数据的爬取:
1-设置请求头:
- headers:定义了HTTP请求的信息
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.63',
'Host':'lishi.tianqi.com',
'Accept-Encoding': "gzip, deflate",
'Connection': "keep-alive",
'cache-control': "no-cache"}
2-定义目标URL并获取页面内容:
- url:定义了历史天气网站的网址。
- requests.request(“GET”, url, headers=headers):发送请求到指定的URL网址。
url='https://lishi.tianqi.com/ganyu/202404.html'
resp= requests.request("GET", url, headers=headers)
3-使用BeautifulSoup解析HTML:
- soup = bs(resp.text,‘html.parser’):解析HTML。
4-提取天气数据:
- tian_three=soup.find(“div”,{“class”:“tian_three”}):找到包含天气数据的HTML元素。
- lishitable_content=tian_three.find_all(“li”):找到所有包含天气信息的列表项。
- 遍历列表项,提取每个天气记录的数据,并添加到data_all列表中。
- weather=pd.DataFrame(data_all):将提取的数据转换为DataFrame。
- 保存数据到CSV文件
for i in lishitable_content:
lishi_div=i.find_all("div")
data=[]
for j in lishi_div:
data.append(j.text)
data_all.append(data)
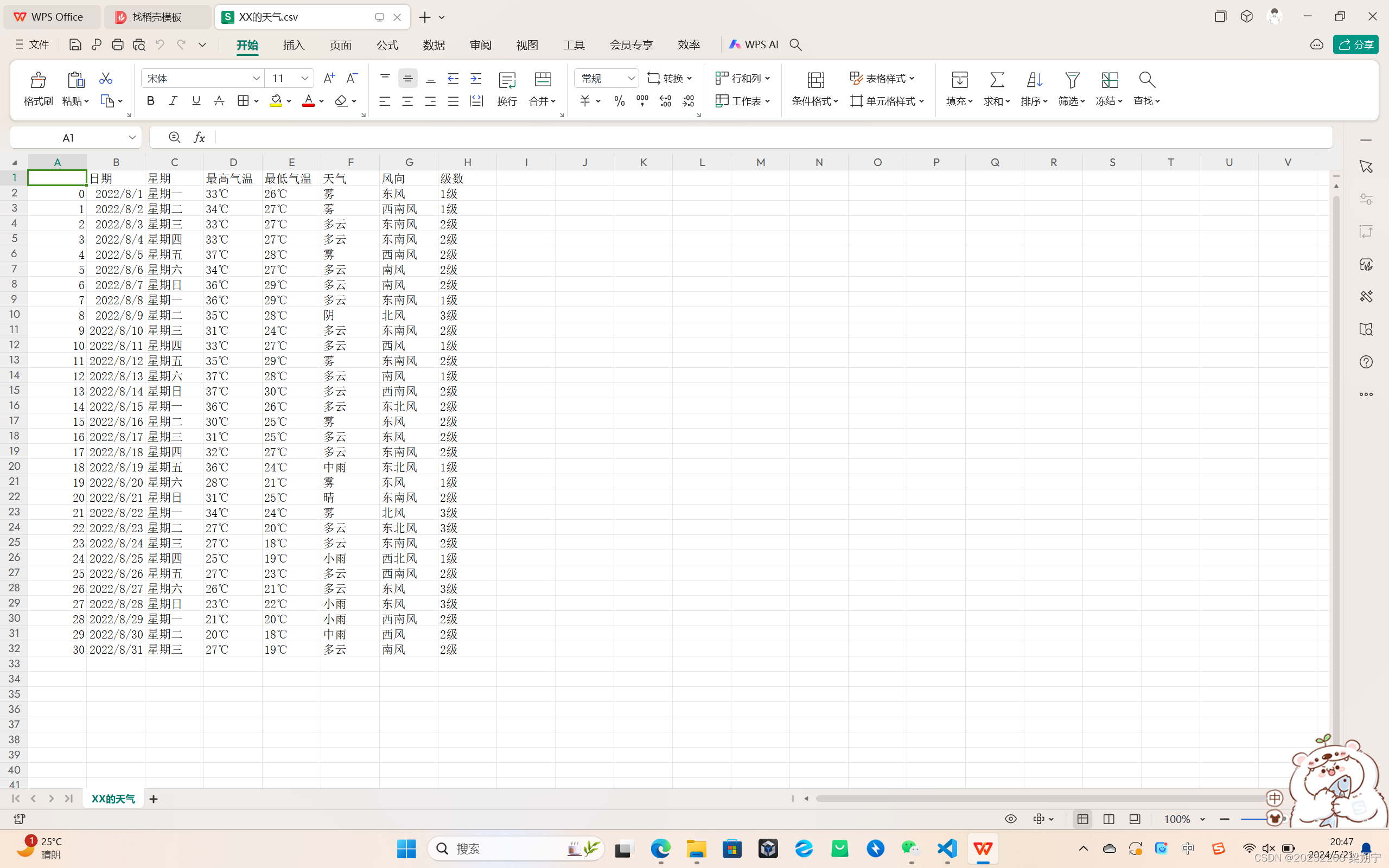
weather=pd.DataFrame(data_all)
weather.columns=["当日信息","最高气温","最低气温","天气","风向信息"]
weather_shape=weather.shape
weather['当日信息'].apply(str)
result = DataFrame(weather['当日信息'].apply(lambda x:Series(str(x).split(' '))))
result=result.loc[:,0:1]
result.columns=['日期','星期']
weather['风向信息'].apply(str)
result1 = DataFrame(weather['风向信息'].apply(lambda x:Series(str(x).split(' '))))
result1=result1.loc[:,0:1]
result1.columns=['风向','级数']
weather=weather.drop(columns='当日信息')
weather=weather.drop(columns='风向信息')
weather.insert(loc=0,column='日期', value=result['日期'])
weather.insert(loc=1,column='星期', value=result['星期'])
weather.insert(loc=5,column='风向', value=result1['风向'])
weather.insert(loc=6,column='级数', value=result1['级数'])
weather.to_csv("XX的天气.csv",encoding="utf_8")
【3】实现对电影数据的爬取:
1-定义目标URL并获取页面内容:
- doubanUrl:定义豆瓣电影Top 250的网址.
- getSource(url):发送GET请求到指定的URL.
doubanUrl = 'https://movie.douban.com/top250?start={}&filter='
def getSource(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
}
2-使用lxml解析HTML并提取电影数据:
- getEveryItem(source):使用lxml解析HTML。
- 使用XPath表达式选择包含电影信息的HTML元素。
- 提取标题、副标题、URL、评分和引言。
- 将提取的数据存储在字典中。
for eachMoive in movieItemList:
movieDict = {}
title = eachMoive.xpath('div[@class="hd"]/a/span[@class="title"]/text()') # 标题
otherTitle = eachMoive.xpath('div[@class="hd"]/a/span[@class="other"]/text()') # 副标题
link = eachMoive.xpath('div[@class="hd"]/a/@href')[0] # url
star = eachMoive.xpath('div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()')[0] # 评分
quote = eachMoive.xpath('div[@class="bd"]/p[@class="quote"]/span/text()') # 引言(名句)
if quote:
quote = quote[0]
else:
quote = ''
movieDict['title'] = ''.join(title + otherTitle)
movieDict['url'] = link
movieDict['star'] = star
movieDict['quote'] = quote
movieList.append(movieDict)
print(movieList)
return movieList
3-主程序部分:
-
writeData(movieList):打开“douban.csv”的CSV文件。
-
使用csv.DictWriter将电影数据写入CSV文件。
-
定义一个空的电影列表movieList。
-
遍历豆瓣电影Top 250的前十页。
-
提取电影数据。
-
将提取的电影数据添加到电影列表中。
-
将电影列表写入CSV文件。
def writeData(movieList):
with open('douban.csv', 'w', encoding='utf-8', newline='') as f:
writer = csv.DictWriter(f, fieldnames=['title', 'star', 'quote', 'url'])
writer.writeheader() # 写入表头
for each in movieList:
writer.writerow(each)
if __name__ == '__main__':
movieList = []
for i in range(10):
pageLink = doubanUrl.format(i * 25)
source = getSource(pageLink)
movieList += getEveryItem(source)
writeData(movieList)
(3)实验代码实现:
(一)实现音乐数据爬取
import requests
from bs4 import BeautifulSoup
import time
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36"
}
def get_info(url):
web_data = requests.get(url, headers=headers)
soup = BeautifulSoup(web_data.text, 'lxml')
ranks = soup.select('span.pc_temp_num')
titles = soup.select('div.pc_temp_songlist > ul > li > a')
times = soup.select('span.pc_temp_tips_r > span')
for rank, title, time in zip(ranks, titles, times):
data = {
"rank": rank.get_text().strip(),
"singer": title.get_text().replace("\n", "").replace("\t", "").split('-')[1],
"song": title.get_text().replace("\n", "").replace("\t", "").split('-')[0],
"time": time.get_text().strip()
}
print(data)
if __name__ == '__main__':
urls = ["https://www.kugou.com/yy/rank/home/{}-8888.html".format(str(i)) for i in range(1, 24)]
for url in urls:
get_info(url)
time.sleep(1)
(二)实现天气数据爬取
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
from pandas import Series,DataFrame
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.102 Safari/537.36 Edg/104.0.1293.63',
'Host':'lishi.tianqi.com',
'Accept-Encoding': "gzip, deflate",
'Connection': "keep-alive",
'cache-control': "no-cache"}
url='https://lishi.tianqi.com/ganyu/202404.html'
resp= requests.request("GET", url, headers=headers)
resp.encoding = 'utf-8'
soup = bs(resp.text,'html.parser')
data_all=[]
tian_three=soup.find("div",{"class":"tian_three"})
lishitable_content=tian_three.find_all("li")
for i in lishitable_content:
lishi_div=i.find_all("div")
data=[]
for j in lishi_div:
data.append(j.text)
data_all.append(data)
weather=pd.DataFrame(data_all)
weather.columns=["当日信息","最高气温","最低气温","天气","风向信息"]
weather_shape=weather.shape
weather['当日信息'].apply(str)
result = DataFrame(weather['当日信息'].apply(lambda x:Series(str(x).split(' '))))
result=result.loc[:,0:1]
result.columns=['日期','星期']
weather['风向信息'].apply(str)
result1 = DataFrame(weather['风向信息'].apply(lambda x:Series(str(x).split(' '))))
result1=result1.loc[:,0:1]
result1.columns=['风向','级数']
weather=weather.drop(columns='当日信息')
weather=weather.drop(columns='风向信息')
weather.insert(loc=0,column='日期', value=result['日期'])
weather.insert(loc=1,column='星期', value=result['星期'])
weather.insert(loc=5,column='风向', value=result1['风向'])
weather.insert(loc=6,column='级数', value=result1['级数'])
weather.to_csv("XX的天气.csv",encoding="utf_8")
(三)实现电影榜单提取
import requests
from lxml import etree
import csv
doubanUrl = 'https://movie.douban.com/top250?start={}&filter='
def getSource(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
}
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
return response.text
def getEveryItem(source):
html_element = etree.HTML(source)
movieItemList = html_element.xpath('//div[@class="info"]')
movieList = []
for eachMoive in movieItemList:
movieDict = {}
title = eachMoive.xpath('div[@class="hd"]/a/span[@class="title"]/text()') # 标题
otherTitle = eachMoive.xpath('div[@class="hd"]/a/span[@class="other"]/text()') # 副标题
link = eachMoive.xpath('div[@class="hd"]/a/@href')[0] # url
star = eachMoive.xpath('div[@class="bd"]/div[@class="star"]/span[@class="rating_num"]/text()')[0] # 评分
quote = eachMoive.xpath('div[@class="bd"]/p[@class="quote"]/span/text()') # 引言(名句)
if quote:
quote = quote[0]
else:
quote = ''
movieDict['title'] = ''.join(title + otherTitle)
movieDict['url'] = link
movieDict['star'] = star
movieDict['quote'] = quote
movieList.append(movieDict)
print(movieList)
return movieList
def writeData(movieList):
with open('douban.csv', 'w', encoding='utf-8', newline='') as f:
writer = csv.DictWriter(f, fieldnames=['title', 'star', 'quote', 'url'])
writer.writeheader() # 写入表头
for each in movieList:
writer.writerow(each)
if __name__ == '__main__':
movieList = []
for i in range(10):
pageLink = doubanUrl.format(i * 25)
source = getSource(pageLink)
movieList += getEveryItem(source)
writeData(movieList)
【2】实验四【二】结果:
(一)实现对音乐榜单的提取:
(二)实现对电影榜单的提取:

(三)实现对天气数据的提取(初级版):
实验二视频展示
3. 实验过程中遇到的问题和解决过程
-
问题1:安装库函数问题,部分库函数不清楚应该使用怎样的命令去安装。
-
问题1解决方案:在CSDN上查找了相关的资料后,了解的在本实验中代码所需要的库函数的安装方式(pip install +库函数名字//pip3 install +库函数名字)
-

-
问题2:在某些库函数通过终端安装后,无法正常使用
-
问题2解决方案:库函数安装后,会显示库函数被存放的位置,应该将代码放在库函数所安装的文件夹内, 保证代码可以识别到库函数的存在,不会出现报错现象。
-
问题3:对于电影数据爬取与音乐榜单数据爬取,实验预期希望能将数据存在excel表格,但是在本实验代码实现过程中,代码出现报错现象。
-
问题3解决方案:实现终端输出以及excel的输出,在CSDN了解并借鉴excel所需要使用的库函数以及代码的书写方式。
-
问题4:在最初实验预设中,期望在直播平台通过F12访问控制台与源代码、网络实现网络舆情实时监控,在实现的过程遇到了平台反爬问题。
-
问题4解决方案:无法获取网络相关信息,选择遵守法律去实现其他的可行实验方案。
-
问题5:对于网易云音乐的爬取,在未使用time库函数时出现了错误,无法正常运行。
-
问题5解决方案:请求也会对服务器造成压力,所以需要time库函数来进行延缓时间,在每次请求后,使用time.sleep(1)暂停1秒钟,避免过于频繁的请求对服务器造成压力。
4. 其他(感悟、思考等)
【1】实验四感悟:
在本次实验四的过程中,对我来说最大的感悟是深刻了解到python爬虫在日常生活的强大应用,最初了解到python爬虫是在大创项目,但是由于了解浅薄,没能认识到python爬虫的实用性与应用性,在本次课程上以及实验四的设计过程中,当我真正用5秒钟实现可能平时要花10分钟去搜索的数据的爬取,感叹python以及计算机语言的强大性与效率之高,在以后的日常生活中,我将继续深入研究python爬虫技术,并在法律允许的范围内,利用python实现日常生活的高效率与便利化。
【2】课程感想体会、意见及建议:
1-感想体会:最初选择志强老师的报python程序设计选修课的原因有二:一是想要在学一个计算机语言技术,丰富自己的技术储备与提高自己的技术能力,二是很多学长学姐都推荐选择这门课程。在本课程中,志强老师带我们由浅入深学习,从第一个人生苦短,我用python,到最后的爬虫技术,虽然感觉一周就一节课,但是学到的知识远远大于课时数,真的感叹,那么厚的一本书,居然在PPT里呈现的如此简单通俗易懂,我觉得这是这门课非常与众不同的特点!最后祝老师与同学们结课快乐!感恩志强老师的辛勤付出与陪伴!如果有机会,还想再选志强老师的课程。
2-意见与建议:希望老师以后能多出一些小问题,这样就可以点名点到我啦!在其他方面,我觉得与其他任意一门课程相比,python程序设计这门课都是完美的。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









