







目录
田忌赛马用代码表示,需要left和right两个指针来对齐威王选择pk
核心思想:废物最大利用
1.优势洗牌(田忌赛马)
链接: 870. 优势洗牌
给定两个长度相等的数组 nums1 和 nums2,nums1 相对于 nums2 的优势可以用满足 nums1[i] > nums2[i] 的索引 i 的数目来描述。
返回 nums1 的 任意 排列,使其相对于 nums2 的优势最大化。
示例 1:
输入:nums1 = [2,7,11,15], nums2 = [1,10,4,11]
输出:[2,11,7,15]示例 2:
输入:nums1 = [12,24,8,32], nums2 = [13,25,32,11]
输出:[24,32,8,12]给定两个长度相等的数组 nums1 和 nums2,nums1 相对于 nums2 的优势可以用满足 nums1[i] > nums2[i] 的数目来描述。
也就是说相同位置只要nums1[i]>nums2[i] 就存在一个优势。
返回 nums1 的任意排列,使其相对于 nums2 的优势最大化。也就是想办法对第一个数组进行排序,使排序后的优势使最大的。

题解
我们先回忆田忌赛马的故事,当把这道题题意搞清楚后你会发现它和田忌赛马的故事是一模一样的。田忌赛马无非就三匹马在比,我们这里是有很多马在比。
但是它的策略和田忌赛马的策略是一样的。我们从田忌赛马的故事提取最优策略。
- 田忌赛马故事很简单,齐威王和田忌在赛马,按照等级把马划分为上、中、下三匹马,它们每次都按照上、中、下的顺序比较,但是同级别下齐威王的马比田忌的好,所以结果都每次都是齐威王赢。
- 这个时候来了一个孙膑,它给田忌出了一个策略,让田忌更改一下马的出场顺序,改成 下、上、中。此时田忌在和齐威王比较,虽然他的下等马对齐威王的上等马是惨败的,但是他的上等马是胜于齐威王的中等马,中等马胜于齐威王的下等马。
此时田忌获得胜利。
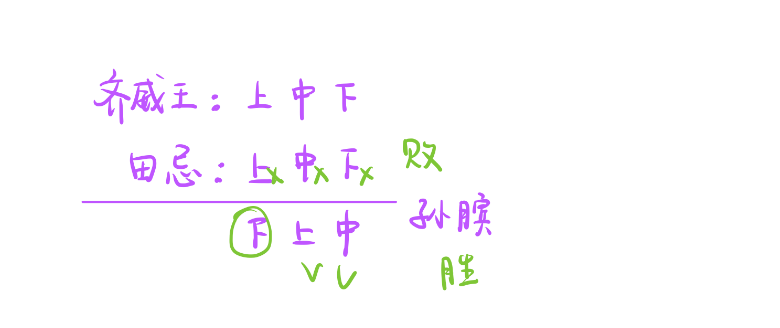
接下来我们从这个故事中提取孙膑的最优策略,为了方便叙述我们将他俩的马从小到大排序。
- 刚开始拿着田忌的下等马去比齐威王的下等马你会发现是干不过的,如果比不过就相当于齐威王所有的马,田忌的下等马都比不过。
- 因为我们已经按照从小到大排序了,如果田忌的下等马连齐威王最差的那匹马都比不过,那它所有的马都比不过。这里我们的第一个贪心策略,如果连最差的比不过,那就去拖累掉最强的那匹马(废物利用最大化)。
接下来考虑田忌的中等马,发现中等马能打过齐威王的下等马,上等马也能打过齐威王的下等马,此时第二个贪心策略,当前最差的马就已经能比掉齐威王最差的马,绝对不会浪费更优秀的马。
总结一下最优策略:
- 排序
- 如果比不过,就去拖累掉对面最强的那一个(废物最大利用)
- 如果能比过,那就直接比
接下来我们模拟一下:
- 先对数组进行排序,(我们是要把nums1数组修改成ret)
- 8比不过11,我们的策略是废物利用最大化,直接去匹配最强的32
- 12比的过11,直接放
- 24比的过13,直接放
- 32比的过25,直接放
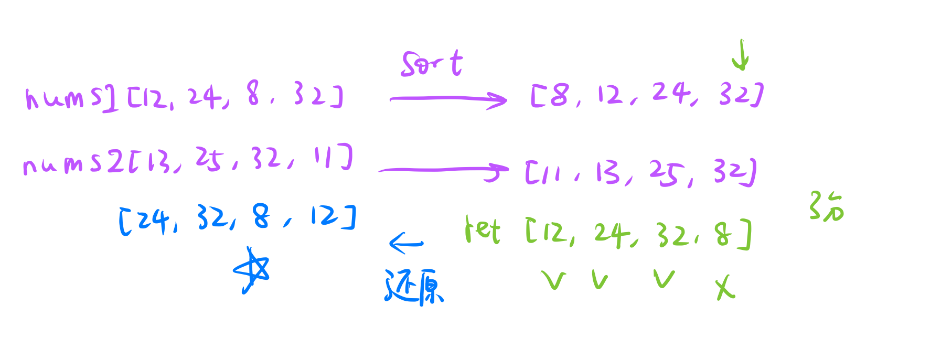
这个ret就是我们最优的策略,但是这个结果和答案给的不一样!

原因是答案是按照未排序之前的num2的顺序来匹配最终结果的。意思就是如果是11对12,应该是原始的nums2数组的11的位置放12,而不是在排完序后的第一个位置放12.
- 同理其他都是如此,然后这个数组才是我们要的最终结果
- 原因就在于我们排完序之后是要按照之前排序之前的数组来还原的,所以就出现了,虽然想排序,但是原来的顺序我还要知道。那如何实现这一点呢?
- 《身高排序》 这到题我们正好用了这个技巧,又想让数组排序,又想找到之前的相对位置,我们的策略是直接排序下标数组。不排原始数组,对下标数组进行排序,然后通过下标数组找到原始的数,最终就能把ret对应到原始的位置。

接下来我们在模拟一下这个过程。
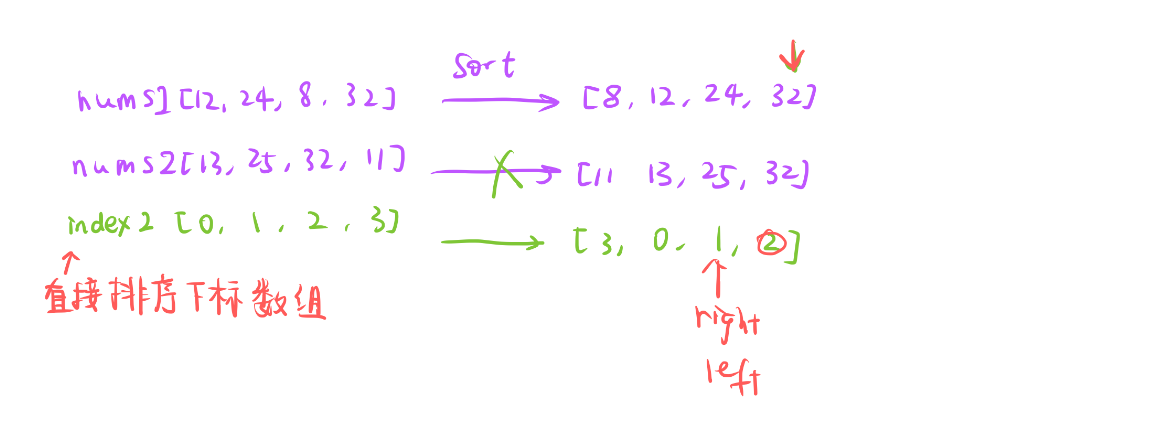
- 先对下标数组排序,如何排序之前已经说过改变排序规则,这里我们还需要两个指针,left指向num2下标数组排序后的第一个元素的下标,right指向nums2下标数组排序后的最后一个元素的下标。
依次遍历nums1,每次和left所指向的下标,和 nums2[index2[left]] 比较
对于 num2 的下标使用,采取 再套一层的方式

8比不过11,把8放在最后一个位置,此时并不是把8放在ret最后一个位置
- 而是把8放在nums2排完序之后的最后一个位置所对应的下标的位置。
- 也ret下标为2的位置。然后right–,代表之前的数已经匹配过了,此时最后一个位置的就是下标1。
12比的过left所指向下标对应的数11,就放在第一个位置,第一个位置下标是3,然后left++
- 24比的过left所指向下标对应的数13,就放在0位置,然后left++
- 32比的过left所指向下标对应的数25,放在下标1的位置,此时nums1遍历完就结束了。
class Solution {
public:
vector<int> advantageCount(vector<int>& nums1, vector<int>& nums2)
{
vector<int> index;
int n=nums1.size();
for(int i=0;i<n;i++)
index.push_back(i);
sort(nums1.begin(),nums1.end());
sort(index.begin(),index.end(),[&nums2](int a,int b)
{
return nums2[a]<nums2[b];
});
//这么 嵌套使用,即可实现跳着填表,不改变num2
//nums2[index[left]]
int left=0,right=n-1; // 比对nums2
vector<int> ret(n);
for(int i=0;i<n;i++) // 操作nums1
{
if(nums1[i]<=nums2[index[left]])
{
ret[index[right]]=nums1[i]; //存结果位置时,取出映射
right--; //num2 这个位置,已经被比较过了
}
else
{
ret[index[left]]=nums1[i];
left++;
}
}
return ret;
}
};超时:

解决:

证明:
证明方法:交换论证法
nums1表示排序后升序的样子,nums2也表示排序后的样子,并且nums1表示的贪心解
- 在来一个nums1表示最优解的情况
- 交换论证法就是在最优解不失去最优性的情况下调整成贪心解的话,那我们就说贪心解就是最优解。
- 从左往右扫描贪心解和最优解的匹配情况,当遇到第一个它们俩匹配不同的情况,就考虑这个点。
我们要分两种情况讨论:
- 贪心解比的过
贪心解比得过,那就去匹配第一个,最优解和贪心解不一样,最优解就去匹配后面的。然后最优解后面的在和第一个匹配
接下来就看最优解调整成贪心解会不会变差。
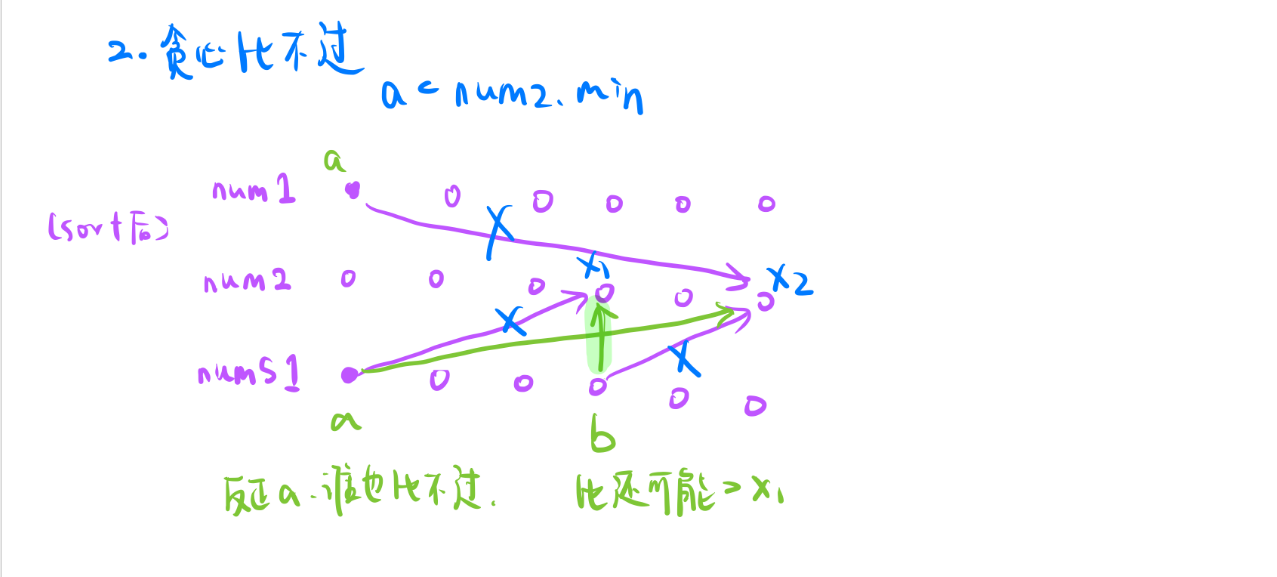
- 如何调整就是调的和贪心解一样就可以了,这里我们设一些变量,然后在贪心解比得过我们有一个不等式 b > a > x1
- a > x1,b > x1,这两条线可以抵消
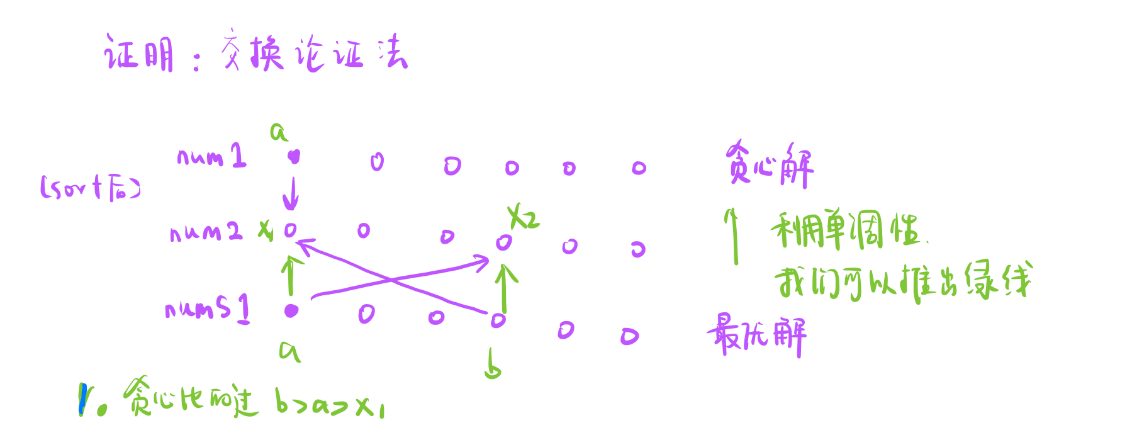
剩下两条线我们不容易得出胜负情况, 我们仅知道 b > a > x1,我们并不知道a是否大于x2,也并不知道b是否大于x2。
- 但是我们可以粗略估计一下用b来比较x2是更优的,原因是最优解之前拿的是较小的a都能和x2匹配,调整完之后拿较大的b和x2匹配,所以绝对是更优的。
- a能胜过x2,b一定能胜过,a打不过x2,但是b比a大是有可能打得过x2的。
所以我们第一种情况是可以的。
2. 贪心解比不过
如果比不过,贪心选择的策略就是和最后一个抵消,最优解肯定不是最后一个,接下来我们继续调整。依旧是调整后的别比之前的差就可以。
- 我们的谈贪心解是比不过第一个才会抵消最后一个,也就是比nums2最小的还要小。调整之前拿最优解的a和nums2前面的匹配,调整后和nums2最后一个匹配,反正都不会得分所以可以抵消。
- 剩下还有两条线,你会发现调整最优解b之后是更优的,b是固定的,之前b是去匹配较大的的x2,现在是匹配较小的x1,b能打过x1一定能打过x2,b打不过x2可能会打过x1。
因为我们最优解调整后是更优的,所以最优解肯定能在不失去最优性的前提下调整到贪心解。
2.最长回文串
链接: 409. 最长回文串
给定一个包含大写字母和小写字母的字符串 s ,返回 通过这些字母构造成的 最长的 回文串 的长度。
在构造过程中,请注意 区分大小写 。比如 "Aa" 不能当做一个回文字符串。
示例 1:
输入:s = "abccccdd"
输出:7
解释:
我们可以构造的最长的回文串是"dccaccd", 它的长度是 7。示例 2:
输入:s = "a"
输出:1
解释:可以构造的最长回文串是"a",它的长度是 1。给一个包含大小字母的字符串,从里面挑选出来一些字母构成一个最长回文串,然后返回它的长度。
题解
我们可以先统计每个字符的个数
- 为什么先统计次数呢,我们发现构建的回文串从中间劈开后,相同的字符左边放一个右边放一个。
- 把所有能用的字符能放就全部放那就是我们的贪心策略。
- 所以先统计每个字符出现的个数,然后以中间线为分割线左边放一个右边放一个。
上面是我们的总体思路,接下来考虑一下细节问题。
- 字符可能是偶数个,也可能是奇数个。
- 如果是偶数的话太好了全都放。但是如果是奇数个就有问题了,因为我们要左边放一个右边放一个要能对称
- 此时最贪心的想法就是奇数-1变成偶数然后放。
虽然上面把一左一右的搞定的,但是还是有一个小问题
回文串中间这个分割线也是可以摆一个字符,只要我们在统计字符个数的时候发现某个字符出现了奇数次,一左一右我们肯定会漏这一个字符,所以中间这里可以把这个字符加上。
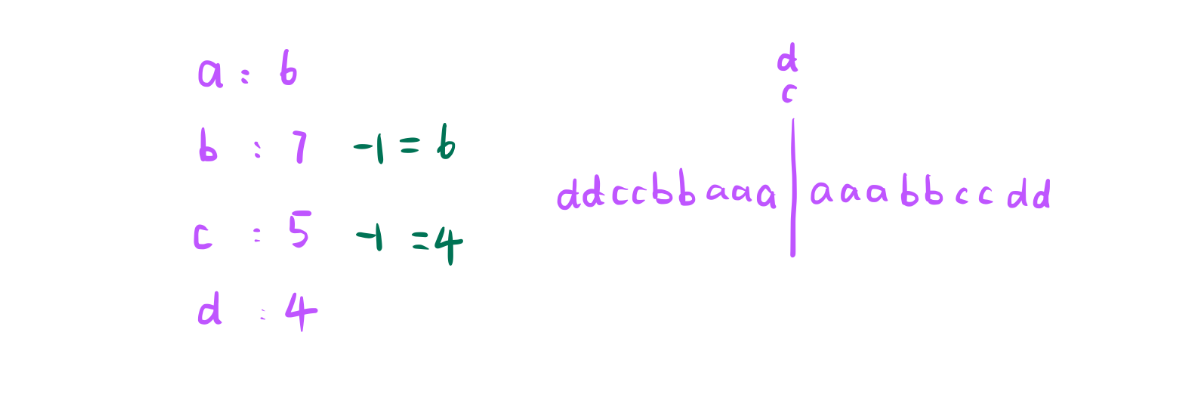
所以我们策略出来了,如果偶数全部加上,如果是奇数 - 1 后在加上
- 所以情况都考虑完,在考虑中间这个地方能不能摆,取决于有没有出现一个字符出现奇数次,如果出现就在中间摆一个。
- 写代码的时候奇偶是可以放在一块写的,假设字符出现 x 次,ret += x / 2 * 2。因为 算 / 2 是一个向下取整 , 7 / 2 = 3, 3 * 2 =6,相当于就是7 - 1 = 6,如果是偶数 / 2 * 2 是不变的。
还有在最后要统计一下是否有个字符出现奇数次,其实也没有必要
其实用最后统计出来的ret和s.size()比较一下
- 如果小于 ret + 1,原因就是如果字符都出现偶数那么ret = s.size() 一左一右
- 如果小于那肯定有字符出现了奇数次。
class Solution {
public:
int longestPalindrome(string s)
{
unordered_map<char,int> hash;
for(auto& c:s)
hash[c]++;
int ret=0;
for(auto& [a,b]:hash)
{
ret+=b/2*2;//实现 向下取整
}
return ret==s.size()?ret:ret+1;
//中间 还可以 再插一个
}
};3.增减字符串匹配
链接: 942. 增减字符串匹配
由范围 [0,n] 内所有整数组成的 n + 1 个整数的排列序列可以表示为长度为 n 的字符串 s ,其中:
- 如果
perm[i] < perm[i + 1],那么s[i] == 'I' - 如果
perm[i] > perm[i + 1],那么s[i] == 'D'
给定一个字符串 s ,重构排列 perm 并返回它。如果有多个有效排列perm,则返回其中 任何一个 。
示例 1:
输入:s = "IDID"
输出:[0,4,1,3,2]示例 2:
输入:s = "III"
输出:[0,1,2,3]示例 3:
输入:s = "DDI"
输出:[3,2,0,1]- I 是下一个大,D 是当前大
由范围 [0,n] 内所有整数组成的 n + 1 个整数的排列序列可以表示为长度为 n 的字符串 s ,其中:
- 如果 perm[i] < perm[i + 1] ,那么 s[i] == ‘I’
如果 perm[i] > perm[i + 1] ,那么 s[i] == ‘D’
其实s字符串就是描述[0,n]组成的数组的序列增减情况。
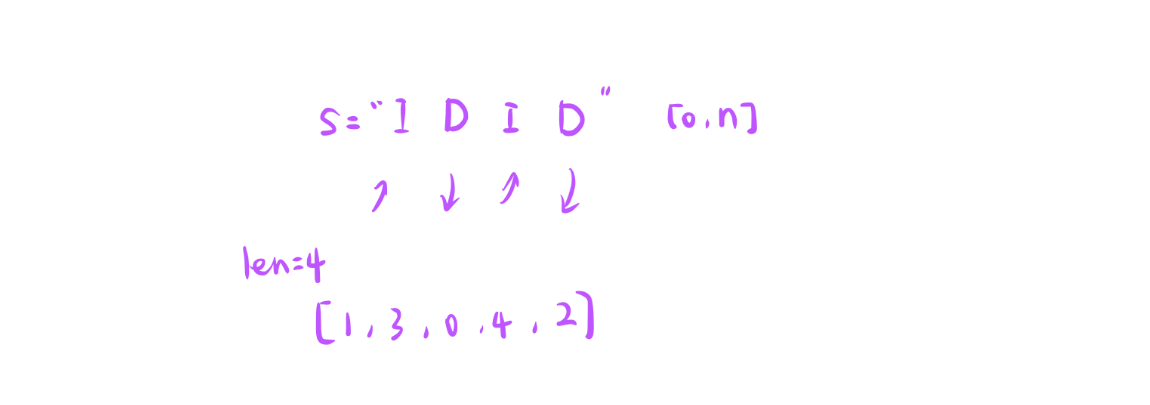
题解
下面用一个例子说明一下
刚开始要符合一个增的形式,此时有很多选项可以放这里,那放5好不好?
- 肯定是不好的,5是当前最大的数,接下来是一个增长趋势这里放5,下一个放谁都增不了,这里就有一个贪心的策略,我不会把最大的数放这里,因此我就贪到底,把最小的数放这里。
- 接下来是降,如果是降,会把1放这里吗?
- 绝对不会,如果把最小的数放在这里接下来还降个锤子,此时还是贪到底,把最大的数放这里。
同理后面都是这样选择的。 - 最后在把最后一个数放在后面
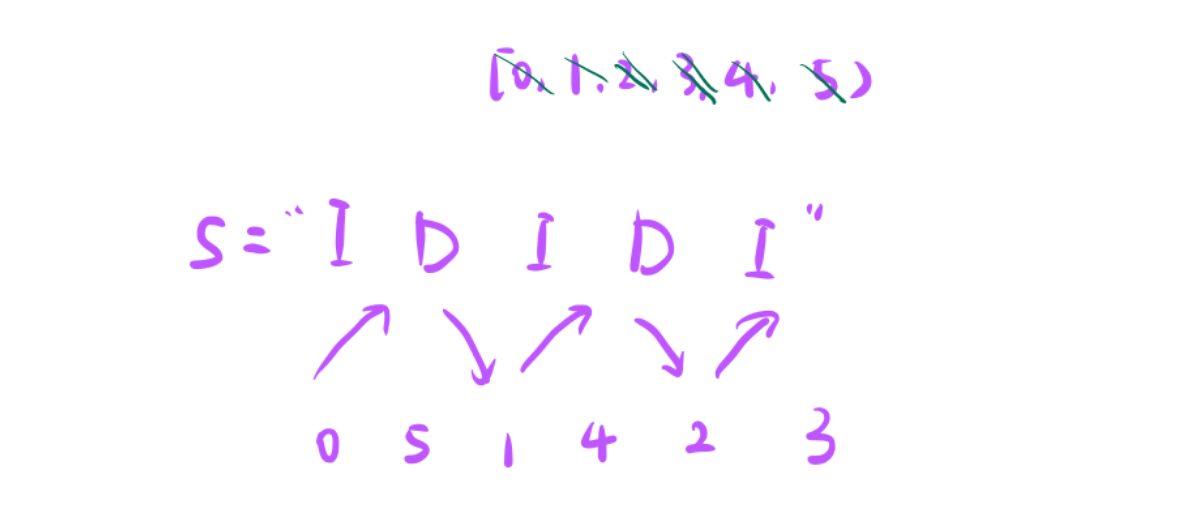
我们的贪心策略:
- 当遇到 " I ",选择当前最小的那个数
- 当遇到 " D ",选择当前最大的那个数
这里简单证明一下我们这个策略是正确的。
- 当在增长的时候,如果我们选择较小的数摆,那无论接下来下一个数选谁绝对都是符合情况的。
- 后面的数都是比我大。所以是绝对正确的。
- 同理如果第一个是降的话,拿最大的数摆,那括号里待选的数都是比我选的,无论较小的数如何排列,接下来下一个数绝对呈现下降趋势。
处理完之后,接下来对括号里面处理是一样的,这其实就是一个递归的过程,当算法一直递归下去的时候,每一个摆放都是合理的,所以我们和用归纳法来证明我们这个贪心策略是正确的。
class Solution {
public:
vector<int> diStringMatch(string s)
{
int low=0,up=s.size();
vector<int> ret;
for(char& c:s)
{
if(c=='I')
{
ret.push_back(low);
low++;
}
if(c=='D')
{
ret.push_back(up);
up--;
}
}
ret.push_back(low++); //放 最后一个元素
return ret;
}
};4.分发饼干
链接: 455. 分发饼干
假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。
对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j,都有一个尺寸 s[j] 。如果 s[j] >= g[i],我们可以将这个饼干 j 分配给孩子 i ,这个孩子会得到满足。你的目标是满足尽可能多的孩子,并输出这个最大数值。
示例 1:
输入: g = [1,2,3], s = [1,1] //g孩子
输出: 1
解释:
你有三个孩子和两块小饼干,3 个孩子的胃口值分别是:1,2,3。
虽然你有两块小饼干,由于他们的尺寸都是 1,你只能让胃口值是 1 的孩子满足。
所以你应该输出 1。示例 2:
输入: g = [1,2], s = [1,2,3]
输出: 2
解释:
你有两个孩子和三块小饼干,2 个孩子的胃口值分别是 1,2。
你拥有的饼干数量和尺寸都足以让所有孩子满足。
所以你应该输出 2。有一群孩子,还有一堆饼干,拿着这些饼干去喂这些孩子,问最多能喂饱多少孩子?
喂饱孩子的要求是饼干尺寸要大于等于孩子的胃口。
题解
看下面这个示例,我们来想贪心策略。
- 首先我们要将胃口和饼干升序排列,如果数组乱序我们找的时候还需要去遍历数组很麻烦。
- 所以我们先要把数组排序。
如果搞清题意的话,不知道会不会想到《优势洗牌 - 田忌赛马》这道题,田忌赛马这道题也是给数组之后我们给数组排下序,然后尽可能多的去赢。
- 这道题是数组排序后,然后挑一些去满足上面的数,其实也是打败它。所以田忌赛马这道题的经验是有可能应用到我们这道题的。
- 这里我们就针对某个孩子然后去挑选饼干。
此时挑的时候发现,当前最小的饼干就能满足孩子,此时贪心就来了
- 如果最小的饼干就能这个孩子,后面的饼干肯定更能满足,此时我们的贪心就是选择较小的饼干去满足,尺寸较大的饼干可以去满足胃口更大的孩子。
- 如果此时最小的饼干满足不了孩子胃口,在田忌赛马哪里我们是让它直接去拖累掉最后一个元素,但是我们这里是喂孩子,不能拿最小的饼干去喂孩子
- 所以当我们发现当前数组中最小的饼干都不能满足孩子胃口的时候,那上面所有孩子胃口都不能满足
- 因为我们是升序排序的,所以当前这个饼干跳过,然后针对这个孩子,再去选前提饼干。
后序操作如上,直到所有饼干用完,那 i 前面这堆孩子是全部都能满足的,返回它的数量就可以了。
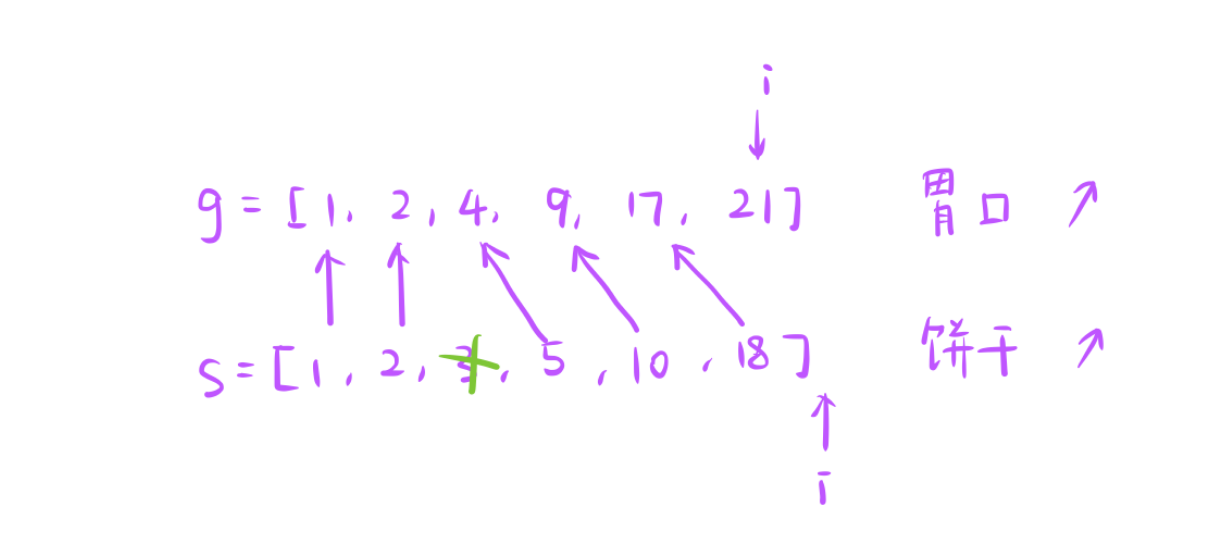
总结一下贪心策略:
排序,针对当前胃口最小的孩子,然后挑选饼干
- 能满足,直接喂
- 不能满足,跳过这个饼干
class Solution {
public:
int findContentChildren(vector<int>& g, vector<int>& s)
{
sort(g.begin(),g.end());
sort(s.begin(),s.end());
int cnt=0,n=s.size();
int left=0; //孩子
for(int i=0;i<s.size();i++)
{
if(left==g.size()) return cnt;
if(s[i]>=g[left])
{
cnt++;
left++;
}
}
return cnt;
}
};证明:
证明方法:交换论证法
- 最优解在不失去最优性的前提下能调整成贪心解,就说明贪心解是正确的。
- 从左往右扫描贪心解和最优解饼干匹配情况,当第一次遇到匹配不相等,此时根据贪心解的策略,分两种情况讨论:
- 喂不饱
贪心策略是删去这个饼干,最优解如果和贪心解不一样的话,最优解会让这个饼干去喂某个孩子。
- 但是这种情况是不可能发生的,因为我们是升序的,如果当前饼干连最小的孩子都不能满足,那后面的孩子也满足不了
- 所以这个贪心和最优是一样的,都是直接删掉。
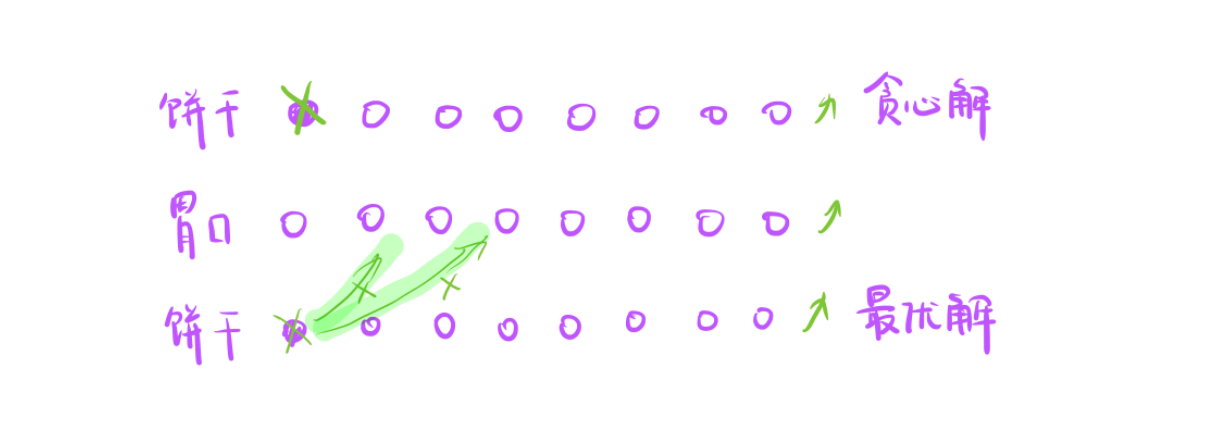
2. 能喂饱
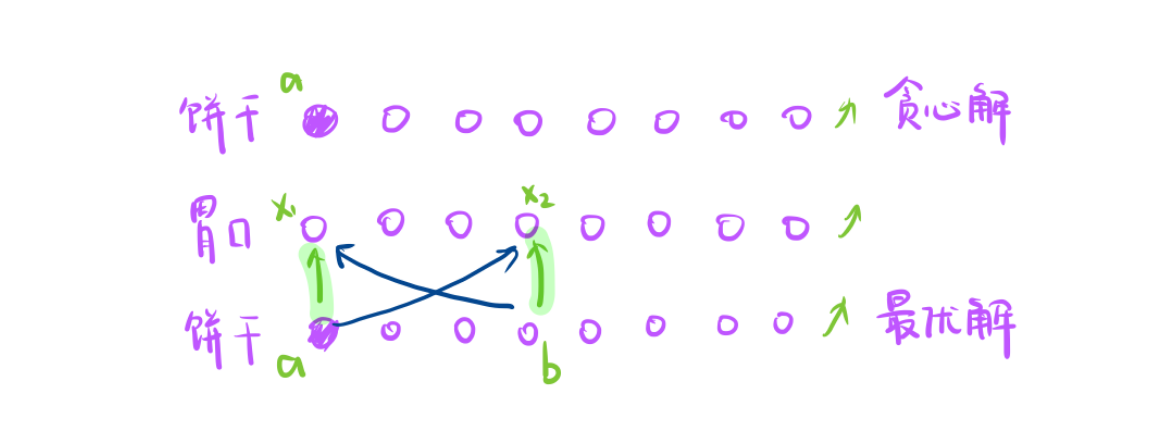
能喂饱我们的贪心是直接喂,最优解其实是有两种情况
- 要么这个饼干喂后面的孩子,要么这个饼干压根就没用。
- 这个孩子也有情况情况,要么后面有饼干来喂这个孩子,要么没有饼干来喂这个孩子。
两两结合我们要分四种情况讨论。
- 一:饼干用了,这个孩子也被后面饼干满足了。
二:饼干用了,孩子没被满足
三:饼干没用,孩子被满足
四:饼干没用,孩子没被满足
考虑第一种情况:
- 此时调整就是,就是绿色情况,只要证明绿色和紫色同样优秀就可以了
- 紫色的线有两个不等式,b > x1, a > x2,又因为升序 b > a,所以 b > a > x2,
所以b一定能喂x2,a调整喂x1贪心告诉我们是可以的。 调整前喂得饱,调整后也喂得饱,所以第一种情况是可以的。 - 调整后 甚至更优
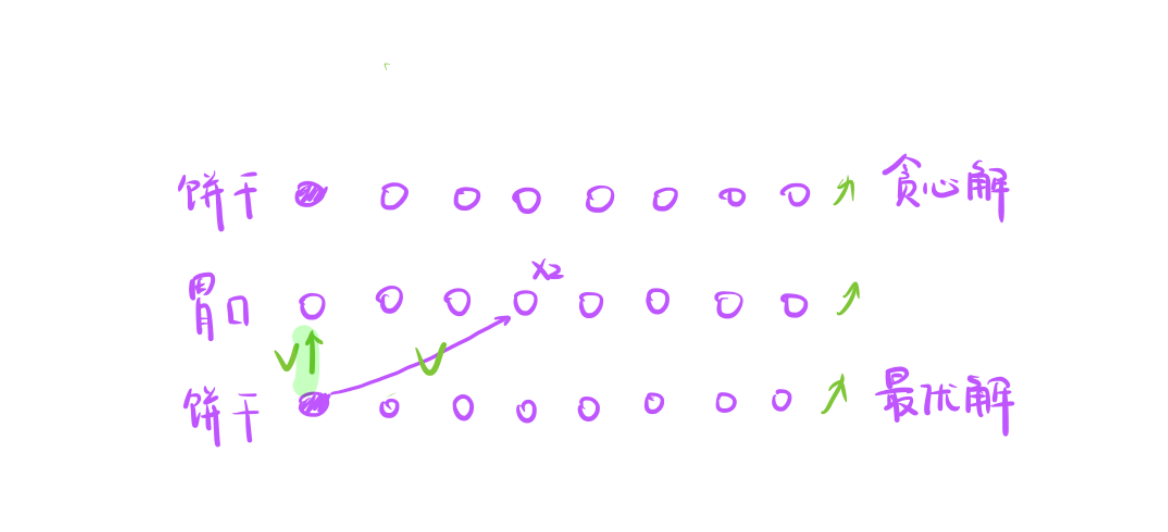
考虑第二种情况:
饼干喂了后面孩子x2,但是x1这个孩子没人喂。
- 此时调整a去喂x1也不会破坏最优,把a喂x2可以填饱肚子,那此时不喂x2,去喂x1也是可以填饱肚子,并且孩子个数没有发生改变,所以第二种情况是可以的。
考虑第三种情况:
没有用a这个饼干,x1这个孩子被后面b喂。
此时调整,不用b喂了,用a喂,也是可以的,在贪心解里知道a 是可以满足x1的,所以也是可以的。
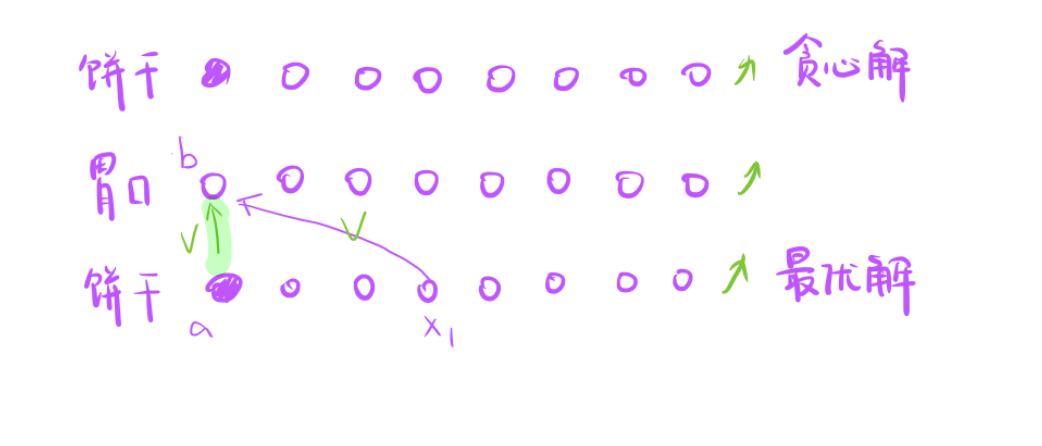
考虑第四种情况:
没有a饼干,也没有x1这个孩子
- 此时调整a去喂x1
- 相当于由原来的舍弃B变为舍弃a
- 所以贪心更优最优解,所以绝对是可以的。
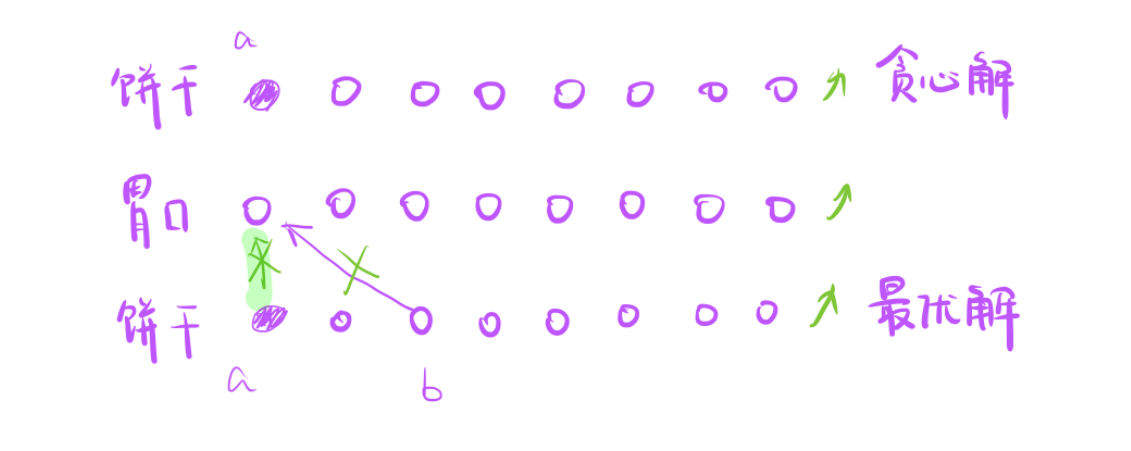
综上所述,无论是上述情况哪一种我们都可以调整的,所以能喂饱也是可以的。
此时我们的贪心就是正确的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









