









本文的主要内容是讲解C语言在内存当中的对齐方式以及对齐原因,如果你连C语言的结构体都不太了解的话,推荐你看这篇文章C语言当中结构体的两种声明方式以及结构体的无名声明方式。
首先我们来看案例:
struct Node1
{
char data1;
char data2;
double count;
};
struct Node2
{
char data1;
double count;
char data2;
};
int main()
{
printf("%d %d\n", sizeof(Node1), sizeof(Node2));
}这里声明了两个结构体Node1和Node2,两种结构体的成员变量完全一样,只是顺序不同。
现在我们来看两种结构体的大小,在计算大小之前,我们可以先大致推测一下结构体的大小:两个char类型的成员变量占两个字节,一个double类型的成员变量占8个字节,总共占内存空间10个字节。然后我们使用sizeof()去分别计算Node1和Node2的大小并且打印,在VS2022中按Ctrl+F5执行代码,得到的结果如下:

Node1节点的大小为16,Node2节点的大小为24,与我们推测的并不相同。其实,这就是C语言当中结构体的内存对齐导致的。
在C语言当中,结构体在内存当中的存储并非线性的,存完一个数据并非立即存储下一个数据,而是遵循一定规则,一共有四个规则,且听我一一道来:
规则一:结构体第一个成员变量与结构体变量偏移0字节的位置对齐。
为了方便理解,我们先来看代码:
struct Node1
{
char data1;
char data2;
double count;
};
int main()
{
Node1 node = { 'X','Y',3.14159 };
printf("%c\n", *(char*)(&node));
}我们这里创建了Node1的结构体变量node,并且对其成员变量赋值'X','Y','3.14159',接着我们取出node的地址,并且强转为char*类型的指针,再对指针解引用,并且打印。由于结构体变量偏移0字节的位置存放的是结构体第一个成员变量,所以我们可以推测打印的结果是我们对成员变量data1赋的值'X',来看看程序运行的结果:
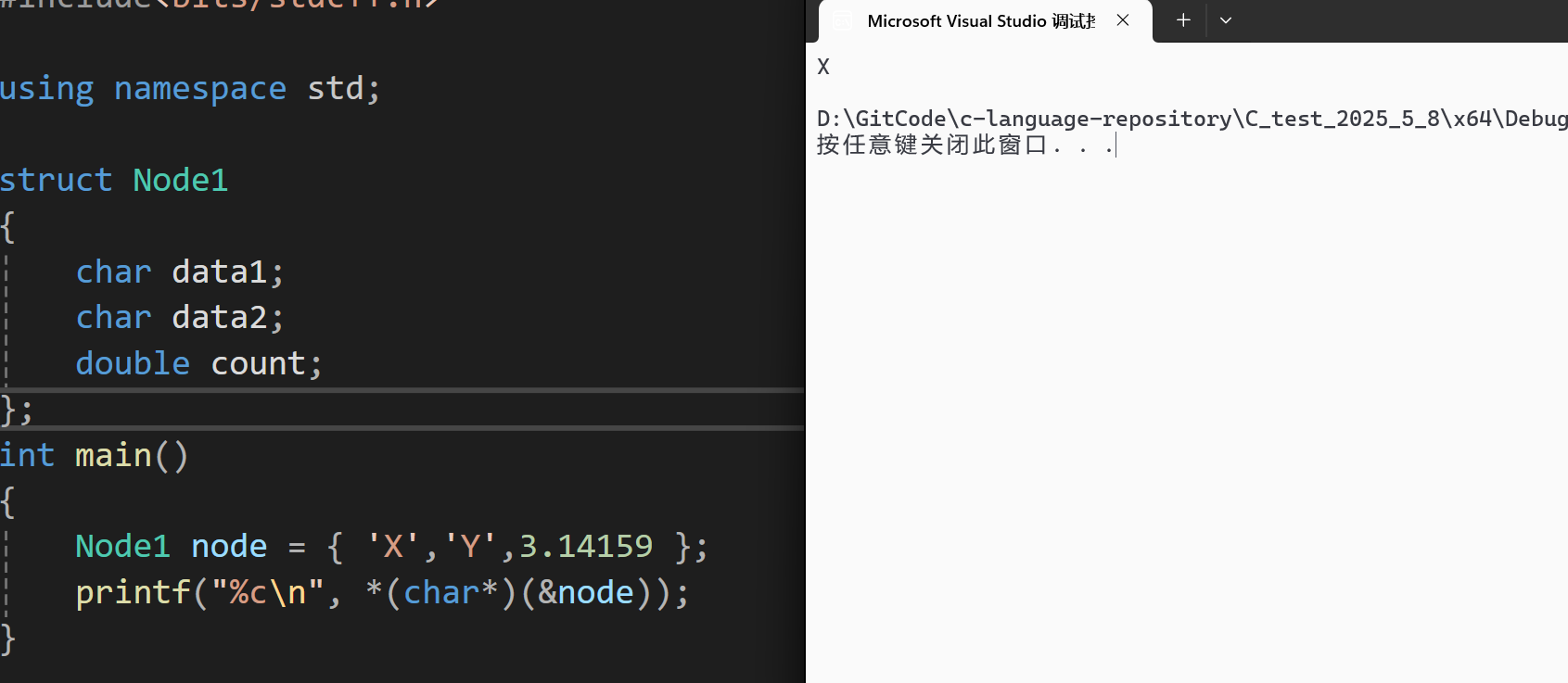 与我们预期的相符,说明结构体第一个成员变量存放的位置就是结构体变量的首地址。
与我们预期的相符,说明结构体第一个成员变量存放的位置就是结构体变量的首地址。
规则二:其他成员变量必须存放在该成员变量对齐数的整数倍的位置上。
这里涉及到一个对齐数的概念,对齐数是什么呢?对齐数就是某一成员变量的数据类型的大小(比如int类型大小是4字节,double类型的大小是8字节)与编译器默认对齐数的大小的最小值(单位:字节)。每个成员变量都有一个对应的对齐数。
但是!!不是所有的编译器都有默认对齐数,VS的默认对齐数是8字节,但是有些编译器可能是4字节或者根本就没有默认对齐数。当编译器没有默认对齐数的时候,成员变量的对齐数就是成员变量本身数据类型的大小。

比如说这里的Node2节点中的count,它本身是double类型的,大小为8字节,取本身大小和VS编译器默认对齐数8字节的最小值,所以count的对齐数的值为8,所以根据规则二,count应该存放在结构体首地址偏移8字节的整数倍的位置上,前面的data1在结构体首地址偏移量为0的地址处,同时它本身为char类型,只占一个字节,中间空了七个字节,在内存中的表示如下图(红色为内存当中被使用的空间,蓝色为未被使用,被浪费的空间)

struct Node2
{
char data1;
double count;
char data2;
};
int main()
{
Node2 node = { 'A',2.718,'B' };
printf("%lf", *(double*)((char*)&node+8));
} 这里需要先将Node2类型的结构体变量node取地址,强制转换为char*之后+8就可以得到count的首地址,但是这个时候的类型还是char*,需要先将其转换为double*,再解引用,才能进行打印。打印之后的结果如下图: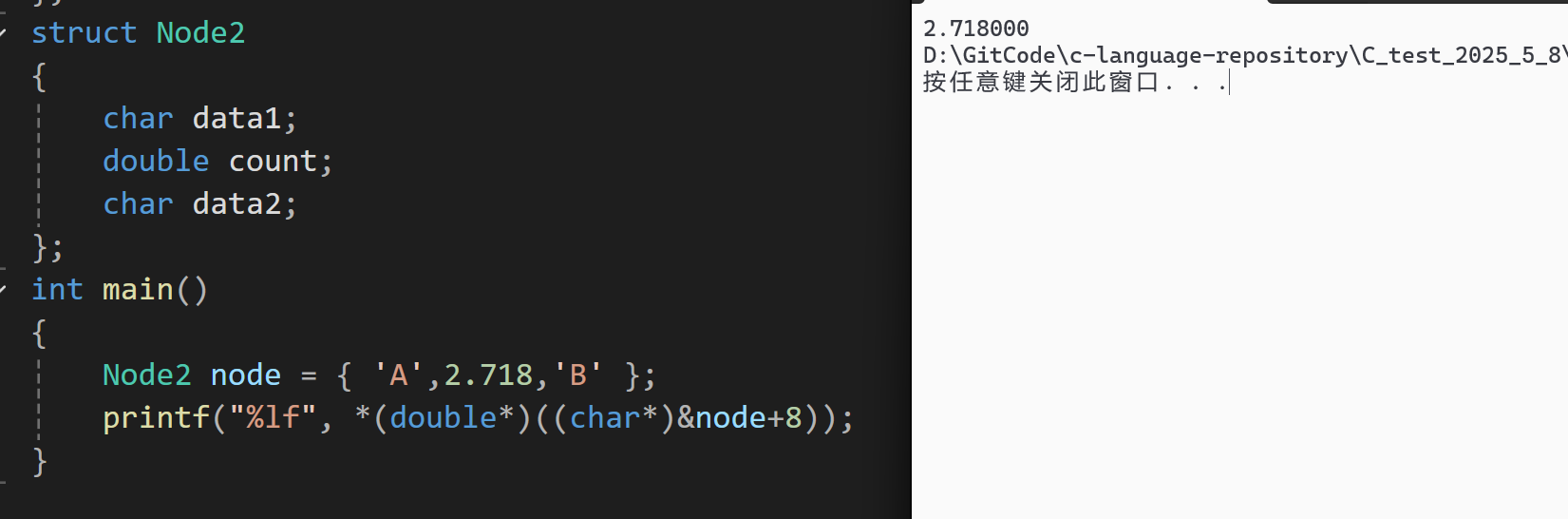
结果也与我们赋的值相符合,说明C语言结构体在内存当中确实存在对齐,而且遵循规则二。
规则三:结构体的总大小必须是所有成员变量(包括第一个成员变量)对齐数的整数倍。

如上图中是Node2在内存当中的对空间的使用情况,红色部分是结构体使用的空间,蓝色部分是结构体因为内存对齐而浪费的空间。接下来我们来对规则三进行讲解:
虽然Node2最后一个成员变量的类型是char,只占一个字节,但是由于规则三的存在,data2之后的7字节的空间依旧要被划分到结构体变量中,此时我们可以计算一下Node2类型所占空间的大小:data1:1+7(对齐)字节,count:8字节,data2:1+7(对齐)字节,总共是24字节,现在我们再回到计算Node2类型的大小来验证我们的结果: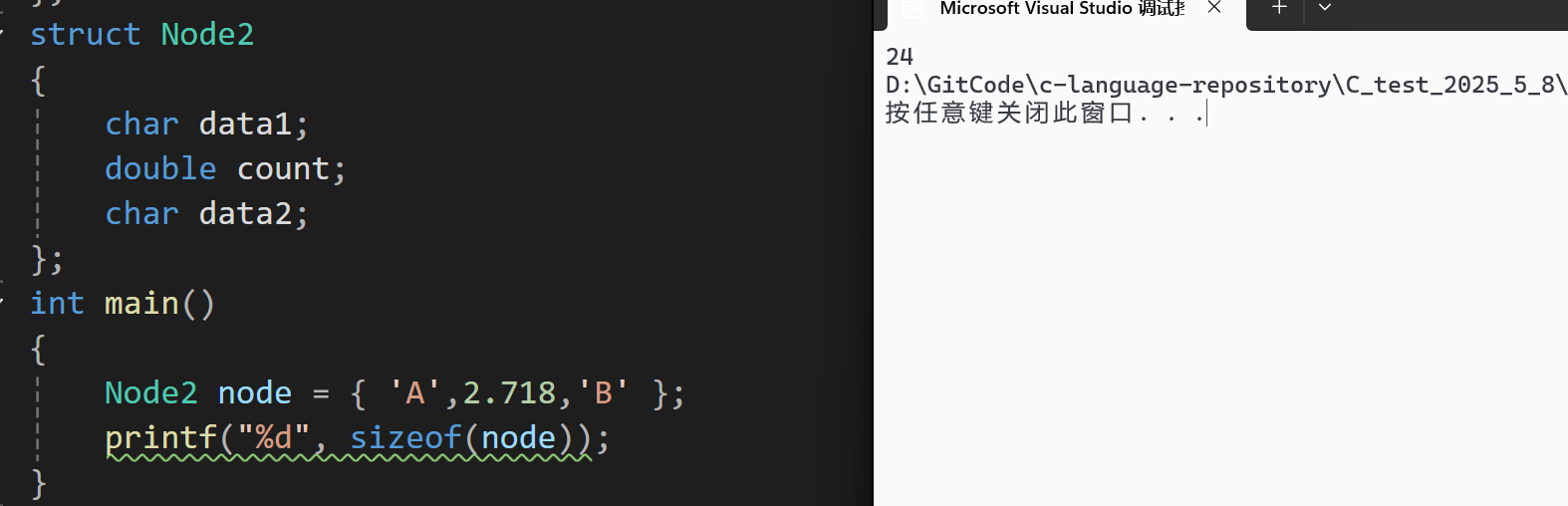
结果也为24字节,与我们的计算相符合。
现在,我们讲完了前三条规则,现在我们来先利用前三条规则去分析一个结构体在内存当中的大小。
分析一下Node1的大小: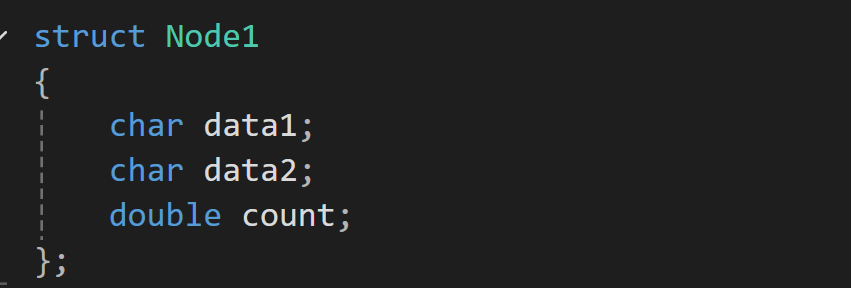

data1是第一个成员变量,要和结构体的首地址对齐,data2的对齐数为1和8的最小值1,所以data2可以直接放在data1的后面,但是count是double类型的,对齐数为8和8(vs默认值)的最小值8,所以count必须放在结构体首地址偏移8的整数倍的位置上,由于最近是8的倍数的位置正好是8,所以count就被存放在了距离结构体首地址八个字节的位置上。此时结构的大小为16字节也正好是所有成员变量对齐数的最大值的{1,1,8}倍数,所以最后结构体的大小为8。
我们在vs中执行以下程序:
struct Node1
{
char data1;
char data2;
double count;
};
int main()
{
printf("%d", sizeof(Node1));
}得到结果如下:
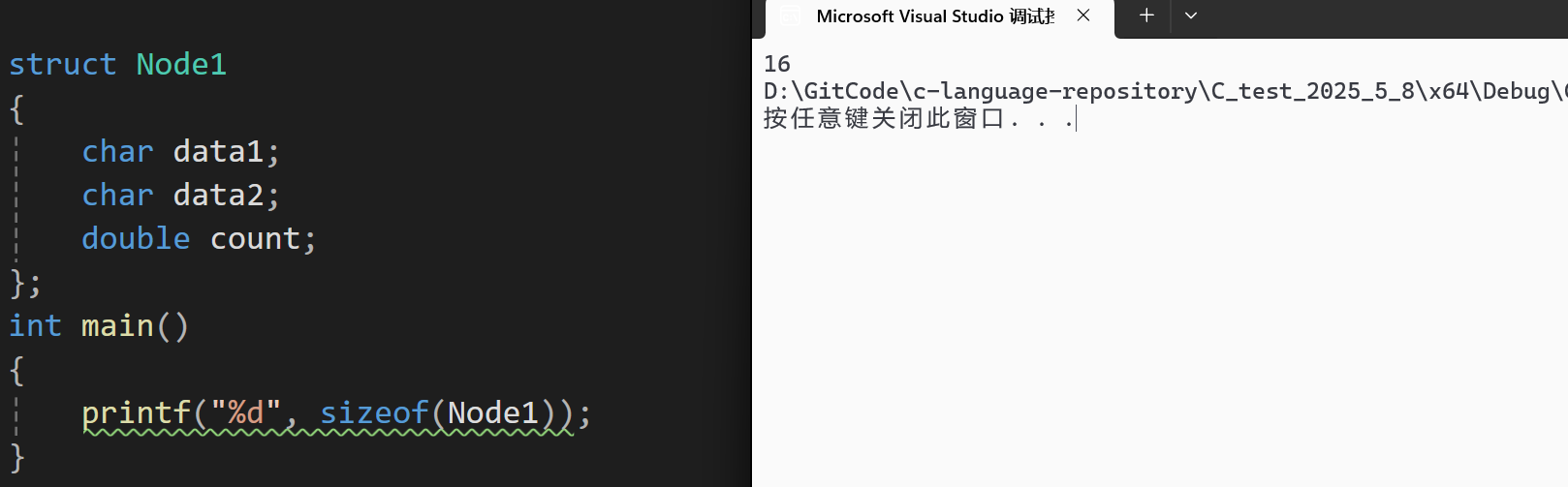
说明结构体的大小遵循以上三个规则。
规则四:当结构体中嵌套了其他结构体时,被嵌套的结构体的对齐数按该被嵌套结构体当中的对齐数的最大值来算。
比如现在我让Node2嵌套进Node1当中,如下
struct Node2
{
char data1;
double count;
char data2;
};
struct Node1
{
char data1;
char data2;
double count;
Node2 node;
};
int main()
{
printf("%d", sizeof(Node1));
}Node2成员变量的对齐数分别为1,8,1,最大值为8,所以以在Node1当中node的对齐数为8。此时我们来推测Node1的大小,如图:
 这里node存放的位置正好的8的倍数,所以直接存放即可,总计40字节的大小,也正好是所有成员变量对齐数最大值8的倍数,所以结构体Node1的大小为40字节,接着我们来看vs当中执行的结果,如下图:
这里node存放的位置正好的8的倍数,所以直接存放即可,总计40字节的大小,也正好是所有成员变量对齐数最大值8的倍数,所以结构体Node1的大小为40字节,接着我们来看vs当中执行的结果,如下图:
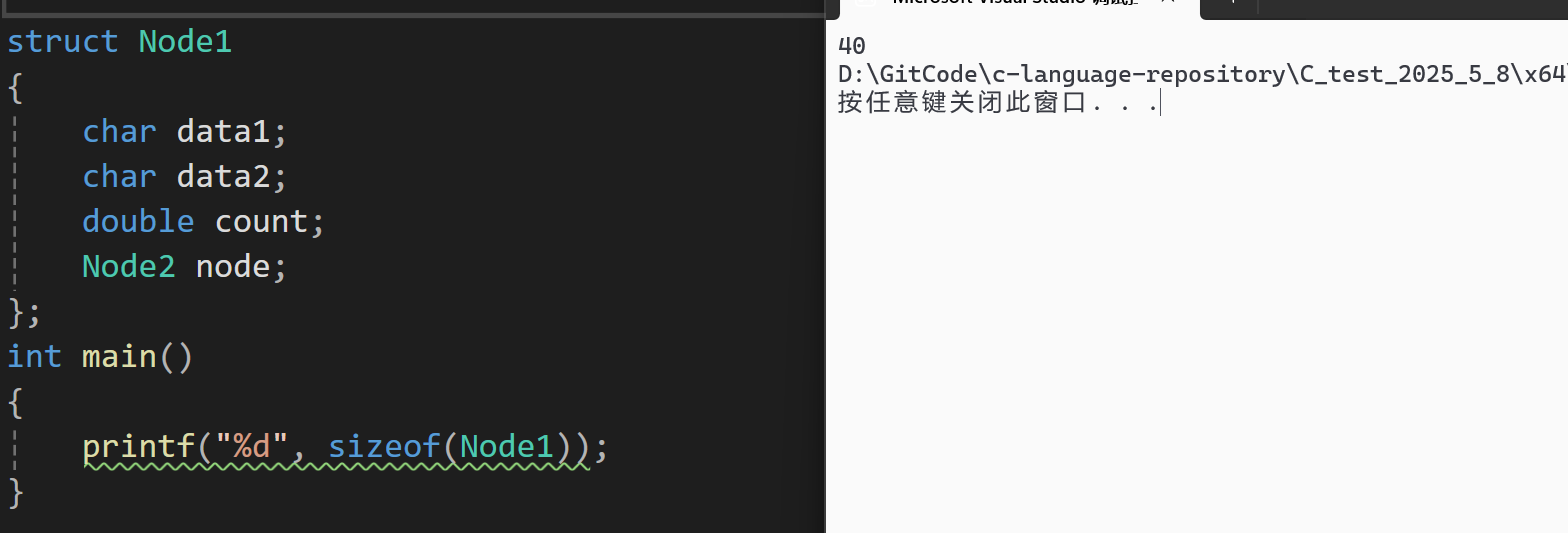 也与预期相符合
也与预期相符合
那么为什么要这样子对齐呢?原因有两条
原因一:为了兼容性,不是所有的硬件都可以对内存当中任意地址的数据进行读写,有些硬件只能在一些特定的内存地址处进行读写,比如在4的倍数处,如果从非4的倍数的内存地址进行读写,某一些硬件可能直接报错,而为了兼容绝大多数硬件,C语言设计了这套内存的对齐原则。
原因二:方便CPU对内存进行读写,在计算机早期的时候,CPU大多是32位的,一次只能读取4个字节,如果不对齐,对于一些数据的读写要进行两甚至是多次操作,这会明显降低计算机的执行速度。
总结:
C语言当中结构体内存对齐四大规则:
规则一:第一个成员变量与结构体的首地址对齐
规则二:其他的成员变量要存放到该成员变量的对齐数的整数倍的位置上
规则三:结构体总大小必须为成员变量(包括第一个)的最大值的整数倍
规则四:如果该结构体的成员变量中有其他结构体,那么该成员变量的对齐数取结构体成员变量当中最大的对齐数
内存对齐的原因:
提升C语言兼容性,兼容更多硬件。
加快计算机的运行速度,以空间换时间。
好了以上就是本文的全部内容了,这里是站长李蔚~~,一个专注于C/C++的程序员,想了解更多关于C/C++的话CSDN/知乎搜索站长李蔚。如果这篇文章有帮助到您,不妨给我一个免费的赞,您的点赞和支持就是我最大动力,感谢您的阅读~~如果您有问题和好的想法,不妨在下面评论区提出你的见解~~~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









