







LeetCode 617.合并二叉树
1、题目
题目链接:617. 合并二叉树
给你两棵二叉树: root1 和 root2 。
想象一下,当你将其中一棵覆盖到另一棵之上时,两棵树上的一些节点将会重叠(而另一些不会)。你需要将这两棵树合并成一棵新二叉树。合并的规则是:如果两个节点重叠,那么将这两个节点的值相加作为合并后节点的新值;否则,不为 null 的节点将直接作为新二叉树的节点。
返回合并后的二叉树。
注意: 合并过程必须从两个树的根节点开始。
示例 1:
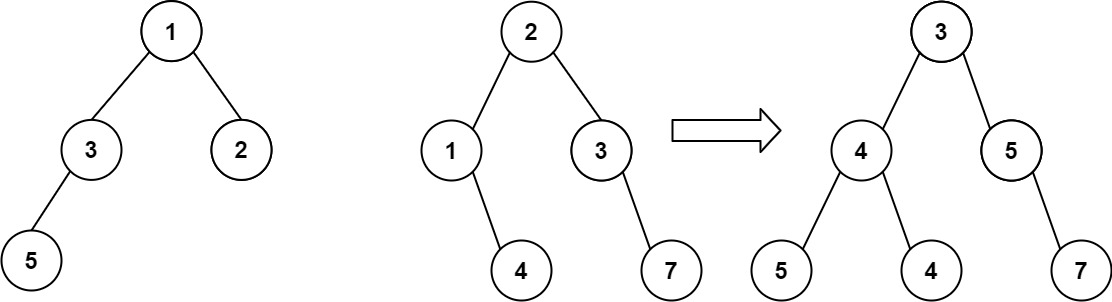
输入:root1 = [1,3,2,5], root2 = [2,1,3,null,4,null,7]
输出:[3,4,5,5,4,null,7]
示例 2:
输入:root1 = [1], root2 = [1,2]
输出:[2,2]
提示:
- 两棵树中的节点数目在范围 [0, 2000] 内
- -104 <= Node.val <= 104
2、深度优先搜索(递归前序遍历)
思路
- 确定递归函数的参数和返回值:
首先要合入两个二叉树,那么参数至少是要传入两个二叉树的根节点,返回值就是合并之后二叉树的根节点。
代码如下:
TreeNode* mergeTrees(TreeNode* root1, TreeNode* root2) {
- 确定终止条件:
因为是传入了两个树,那么就有两个树遍历的节点 root1 和 root2,如果 root1 == nullptr 了,两个树合并就应该是 root2 了(如果 root2 也为 nullptr 也无所谓,合并之后就是 nullptr)。
反过来如果 root2 == nullptr,那么两个数合并就是 root1(如果root1也为 nullptr 也无所谓,合并之后就是nullptr)。
代码如下:
if (root1 == nullptr) return root2; // 如果root1为空,合并之后就应该是root2
if (root2 == nullptr) return root1; // 如果root2为空,合并之后就应该是root1
- 确定单层递归的逻辑:
单层递归的逻辑就比较好写了,这里我们重复利用一下 root1 这个树, root1 就是合并之后树的根节点(就是修改了原来树的结构)。
那么单层递归中,就要把两棵树的元素加到一起。
t1->val += t2->val;
接下来 root1 的左子树是:合并 root1 左子树 root2 左子树之后的左子树。
root1 的右子树:是 合并 root1 右子树 root2 右子树之后的右子树。
最终 root1 就是合并之后的根节点。
代码如下:
root1->left = mergeTrees(root1->left, root2->left);
root1->right = mergeTrees(root1->right, root2->right);
return root1;
代码
class Solution {
public:
TreeNode* mergeTrees(TreeNode* root1, TreeNode* root2) {
// 如果 root1 为空,合并之后就应该是 root2
if (root1 == nullptr) {
return root2;
}
// 如果 root2 为空,合并之后就应该是 root1
if (root2 == nullptr) {
return root1;
}
root1->val += root2->val;
// 递归合并root1和root2的左子树
root1->left = mergeTrees(root1->left, root2->left);
// 递归合并root1和root2的右子树
root1->right = mergeTrees(root1->right, root2->right);
return root1;
}
};
复杂度分析
- 时间复杂度:O(min(m,n)),其中 m 和 n 分别是两个二叉树的节点个数。
- 空间复杂度:O(min(m,n)),其中 m 和 n 分别是两个二叉树的节点个数。
3、深度优先搜索(递归中序遍历)
思路
代码
class Solution {
public:
TreeNode* mergeTrees(TreeNode* root1, TreeNode* root2) {
// 如果 root1 为空,合并之后就应该是 root2
if (root1 == nullptr) {
return root2;
}
// 如果 root2 为空,合并之后就应该是 root1
if (root2 == nullptr) {
return root1;
}
// 递归合并root1和root2的左子树
root1->left = mergeTrees(root1->left, root2->left);
root1->val += root2->val;
// 递归合并root1和root2的右子树
root1->right = mergeTrees(root1->right, root2->right);
return root1;
}
};
复杂度分析
- 时间复杂度:O(min(m,n)),其中 m 和 n 分别是两个二叉树的节点个数。
- 空间复杂度:O(min(m,n)),其中 m 和 n 分别是两个二叉树的节点个数。
4、深度优先搜索(递归后序遍历)
思路
代码
class Solution {
public:
TreeNode* mergeTrees(TreeNode* root1, TreeNode* root2) {
// 如果 root1 为空,合并之后就应该是 root2
if (root1 == nullptr) {
return root2;
}
// 如果 root2 为空,合并之后就应该是 root1
if (root2 == nullptr) {
return root1;
}
// 递归合并root1和root2的左子树
root1->left = mergeTrees(root1->left, root2->left);
// 递归合并root1和root2的右子树
root1->right = mergeTrees(root1->right, root2->right);
root1->val += root2->val;
return root1;
}
};
复杂度分析
- 时间复杂度:O(min(m,n)),其中 m 和 n 分别是两个二叉树的节点个数。
- 空间复杂度:O(min(m,n)),其中 m 和 n 分别是两个二叉树的节点个数。
5、广度优先搜索(迭代法)
思路
代码
class Solution {
public:
TreeNode* mergeTrees(TreeNode* rooroot1, TreeNode* rooroot2) {
if (rooroot1 == nullptr) {
return rooroot2;
}
if (rooroot2 == nullptr) {
return rooroot1;
}
// 使用队列进行层次遍历
queue<TreeNode*> que;
que.push(rooroot1);
que.push(rooroot2);
while (!que.empty()) {
// 取出队列中的第一个节点,对应rooroot1的当前节点
TreeNode* node1 = que.front();
que.pop();
// 取出队列中的第二个节点,对应rooroot2的当前节点
TreeNode* node2 = que.front();
que.pop();
// 将当前两个节点的值相加,并更新到rooroot1的当前节点
node1->val += node2->val;
// 如果rooroot1和rooroot2的当前节点都存在左子节点
if (node1->left != nullptr && node2->left != nullptr) {
// 将rooroot1和rooroot2的左子节点分别加入队列
que.push(node1->left);
que.push(node2->left);
}
// 如果rooroot1和rooroot2的当前节点都存在右子节点
if (node1->right != nullptr && node2->right != nullptr) {
// 将rooroot1和rooroot2的右子节点分别加入队列
que.push(node1->right);
que.push(node2->right);
}
// 如果rooroot1的当前节点不存在左子节点,但rooroot2的当前节点存在左子节点
if (node1->left == nullptr && node2->left != nullptr) {
// 将rooroot2的左子节点赋值给rooroot1的左子节点
node1->left = node2->left;
}
// 如果rooroot1的当前节点不存在右子节点,但rooroot2的当前节点存在右子节点
if (node1->right == nullptr && node2->right != nullptr) {
// 将rooroot2的右子节点赋值给rooroot1的右子节点
node1->right = node2->right;
}
}
return rooroot1;
}
};
复杂度分析
- 时间复杂度:O(min(m,n)),其中 m 和 n 分别是两个二叉树的节点个数。对两个二叉树同时进行广度优先搜索,只有当两个二叉树中的对应节点都不为空时才会访问到该节点,因此被访问到的节点数不会超过较小的二叉树的节点数。
- 空间复杂度:O(min(m,n)),其中 m 和 n 分别是两个二叉树的节点个数。空间复杂度取决于队列中的元素个数,队列中的元素个数不会超过较小的二叉树的节点数















 1890
1890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









