






SQL基础
NoSQL和MySQL的区别?
数据库的三大范式
1.数据库的每一列都是不可分隔的最小原子项
2.在1NF的基础上,消除了非主属性对主键的部分函数依赖
3.在2NF的基础上,所有的非主属性不依赖于其他的非主属性,消除了传递函数依赖
Mysql怎么连表查询
内连接,左外连接,右外连接,全外连接
char和varchar区别
char是定长字符串,会在末尾补足空格
varchar是非定长字符串,指定最大长度,根据实际存储长度去占用空间
varchar后代表字节还是字符
字符,根据字符集的不同占用的字节数也不同,ASCII字符集,一个字符占用一个字节。UTF-8字符集,每个字符占用1-4个字节
int(1) 和 int(10)的区别
显示宽度的不同,不改变存储方式
唯一作用,ZEROFILL补零显示,字段设置为ZEROFILL时,会用前导0
ip地址如何存储
32位的二进制数,通常以点分十进制表示法呈现
1.字符串类型的存储方式
2。整数类型的存储方式
外键约束
外键约束的作用是维护表和表之间的关系,确保了两张表之间数据库的准确性和一致性
MySQL的关键字in和exist
IN:检查左边的表达式是否存在于右边的列表或子查询的结果当中,存在返回true,否则为false
exist关键字用于判断子查询是否返回一行数据,返回了则为true,否则为false
Mysql的一些基本函数
字符串:CONCAT(str1,str2...) LENGTH(str) substring(str,pos,len) replace(str,from_str,to_str)
数值函数:ABS(num) 绝对值 POWER(num,exponent) 指定幂次方
日期函数:NOW() 当前日期 CURDARE() 当前日期
聚合函数: COUNT() SUM() AVG() MAX() MIN()
存储引擎
SQL查询语句的执行顺序
from 和 join 确定数据来源
where 对数据初步筛选
group by 数据分组
having 分组后进行过滤
select 选择返回的列
distinct 去除重复行
order by 结果排序
limit/offset 限制返回的行数
如何用Mysql实现一个可重入的锁
1.新建表,id,lock_name,holder_thread,reentry_count 分别表示锁的名称,锁被哪个线程所持有以及存储锁的重入次数
SQL请求的过程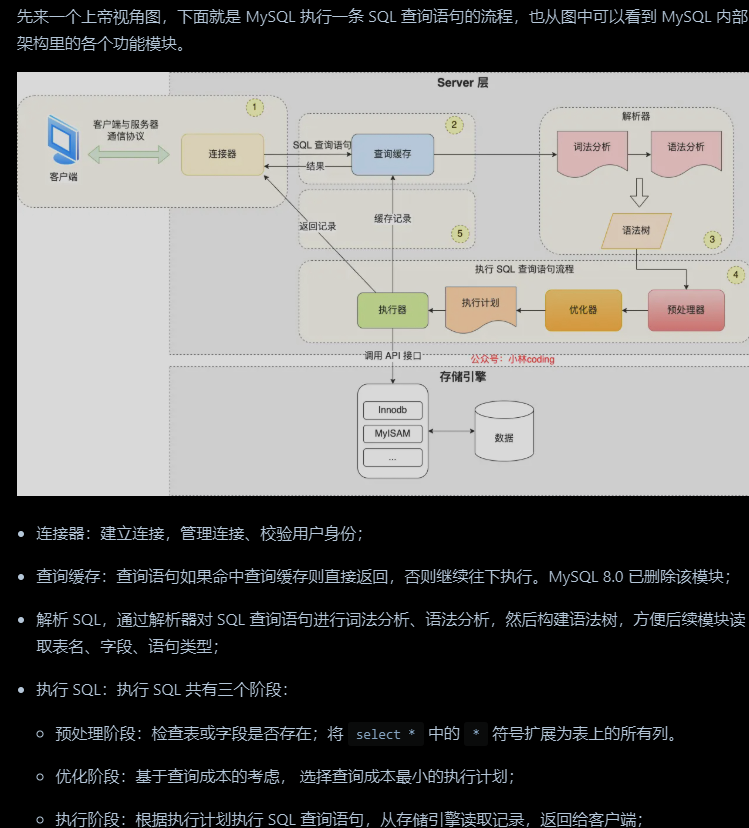
讲一讲Mysql的引擎
IooDB默认引擎的原因
ACID,事务支持,行级锁,外键约束
事务支持:InnoDB引擎提供了十五万的支持,可以进行ACID属性的操作,MyISAM引擎是不支持事务的
并发性能:InnoDB采用行级锁定的机制,提供更好的并发性能.MyIASM只支持表级锁,锁的粒度比较大
崩溃恢复:InnoDC采用redolog日志实现了崩溃恢复
IooDB和MyISAM的区别
事务:前者支持,后者不支持
索引结构:IooDB是聚簇索引,MyISAM是非聚簇索引,聚簇索引要求行数据都存储在主键索引的叶子节点上,因此IooDB必须要包含主键,通过主键索引效率很很高,但是辅助索引需要经过两次查询,先查询到主键,在根据主键去查询数据。MyISAM是非聚簇索引,索引保存的是数据的指针。
锁粒度:IooDB最小的锁粒度是行级锁,MyISAM最小的锁粒度是表锁,一个更新语句会锁住整张表
count效率:IooDB不保存表的具体行数,执行select count(*) from table 时需要全表扫描。而MyISAM用一个变量保存了整个表的行数,执行效率很高
数据文件大体分为哪几种数据文件
每创建一个database,都会在/var/lib/mysql目录里面创建一个以database为名的目录,然后保存表结构和表数据的文件都会在这个目录中
db.opt 存储当前数据库的默认字符集和字符校验规则
databaseName.frm 存储数据库表结构
databaseName.ibd 存储数据库的内容
索引
索引是什么,好处?
索引类似于一本书的目录,可以减少扫描的数据量,提高查询效率
查询的时候如果未用到索引,就会使用全表扫描,这时候的时间复杂度为O(n)
用到了索引,查询的时候可以基于二分查找算法,通过索引快速定位到目标数据,MySQL索引的数据结构一般是b+树
索引的分类
数据结构:B+Tree索引,Hash索引,Full_Text索引
物理存储:聚簇索引,非聚簇索引
字段特性:主键索引,唯一索引,普通索引,前缀索引
字段个数:单列索引,联合索引
数据结构:
InnoDB引擎是Mysql 5.5之后才成为默认引擎的
创建表时,InnoDB存储引擎会根据不同的场景选择不同的列作为索引
存在主键,默认会使用主键作为聚簇索引的索引键
不存在主键,就会选择第一个不包含NULL值的唯一列作为聚簇索引的索引键
如果都不存在,InnoDB将自动生成一个隐式自增id列作为聚簇索引的索引键
其他索引都属于辅助索引,也被称为二级索引或者非聚簇索引
物理存储:
分为聚簇索引和非聚簇索引
聚簇索引存储行数据 - > 数据行物理存储顺序与索引顺序一致,叶子节点存放整行数据
非聚簇索引索引存储的是主键id - > 索引结构与数据存储分开,叶子节点存索引列值和指向聚簇索引(如主键 )的指针,查询可能需回表操作
字段特性
主键索引 :建立在主键字段上的索引,通常在创建表的时候一起创建,一张表最多只允许一个主键索引,索引列的值不允许有空值
唯一索引:建立在UNIQUE字段上的索引,一张可以有多个唯一索引,索引列的值必须唯一,但是允许有空值
普通索引:建立在普通字段上的索引,不要求为主键也不要求字段为UNIQUE
前缀索引:对字符类型字段的前几个字符建立的索引,而不是在整个字段上建立的索引,前缀索引可以建立在字段类型为char,varchar,binary,varbinary的列上
使用前缀索引的目的是为了减少索引占用的存储空间,提升查询效率
字段个数
分为单列索引和联合索引
单列索引:建立在单列上的索引,比如主键索引
联合索引:建立在多列上的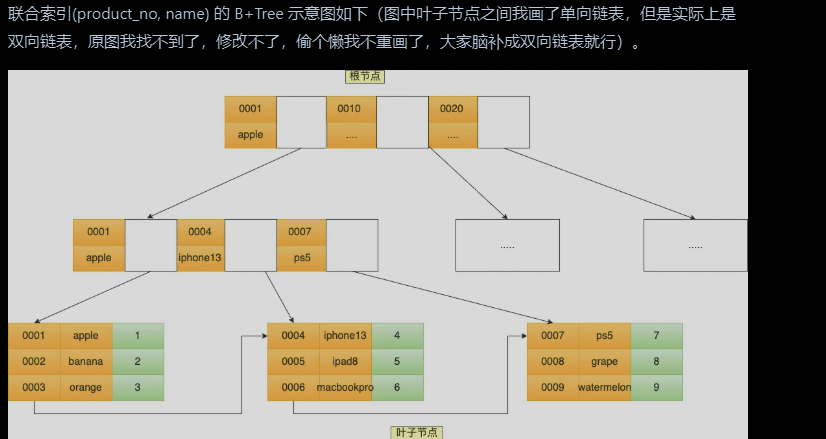
非叶子节点用两个字段的值作为B+Tree的key值,使用联合索引去查询数据时,先按照product_no字段比较,相同的情况再按照name进行排序
因此,使用联合索引时,存在最左匹配原则,即按照最左优先的方式进行索引的匹配,如果不遵循最左匹配原则,索引会失效
聚簇索引和非聚簇索引的区别
数据存储: 聚簇索引中,数据行按照索引键值的顺序存储,也就是说,叶子节点包含了实际的数据行,而非聚簇索引的叶子节点不包含完整的数据行,而是包含指向数据行的指针或主键值
索引与数据关系: 聚簇索引不需要回表查询 ,非聚簇索引需要
唯一性 : 聚簇索引通常是基于主键创建的,因此每个表只能有一个聚簇索引 ,但是一个表可以有多个非聚簇索引
效率:对于范围查询和排序查询,聚集索引通常效率更高,因为他避免了额外的寻址开销,非聚簇索引在使用覆盖索引进行查询时效率更高,因为他不需要读取完整的数据行。但是需要进行回标的操作,用非聚簇索引效率比较低
覆盖索引? --> 查询的列例如select num1,num2 存在联合索引的时候,联合索引的叶子节点中已经包含了所需要查询的这两列值,不需要进行回表操作
如果聚簇索引的数据更新,他的存储需不需要变化
Mysql的主键是聚簇索引吗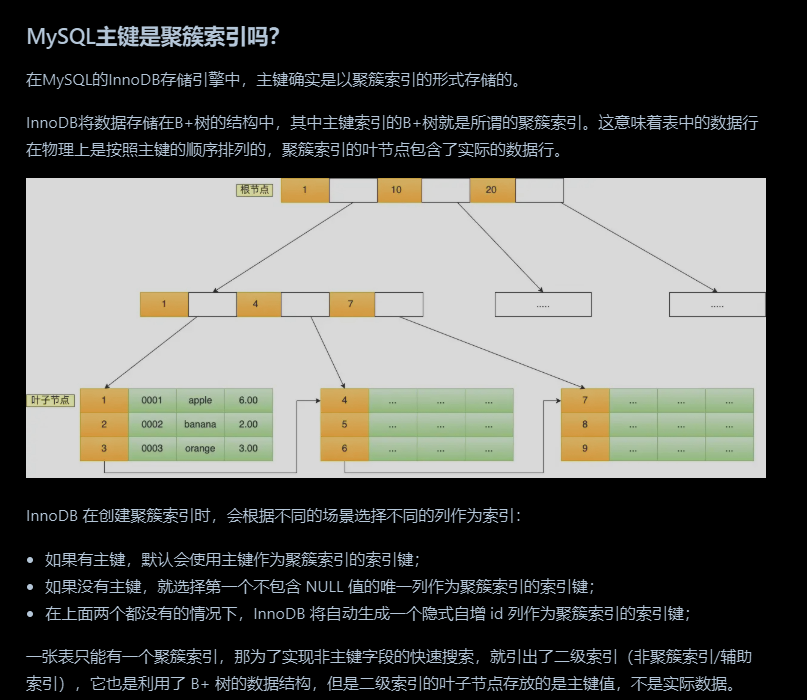
什么字段适合当主键
字段具有唯一性,且不能为空
字段最好具有递增的趋势,如果字段的值随机,可能会导致页分裂的问题,影响新能
一般不建议业务数据作为主键,因为我们无法预测未来会不会因为业务需要,而出现字段重复或者重用的情况
十个字段主键是用UUID还是自增
为什么自增ID比UUID要快?
B+树的特性
B+树和B树的区别
B+树的好处
更矮更胖,叶子节点的数据是双向链表的,更便于范围查找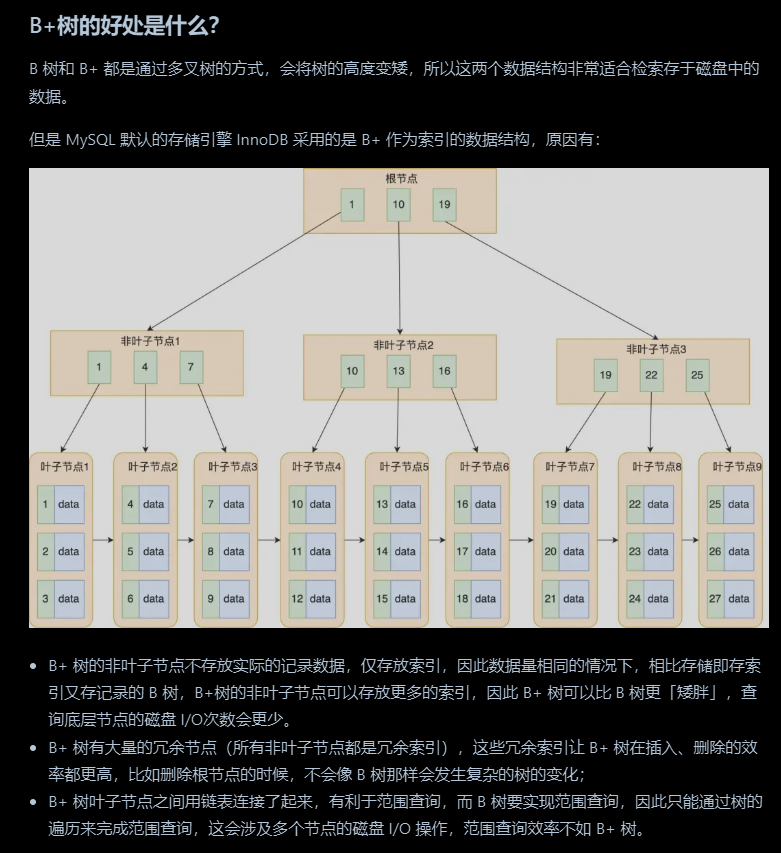
B+树叶子节点的链表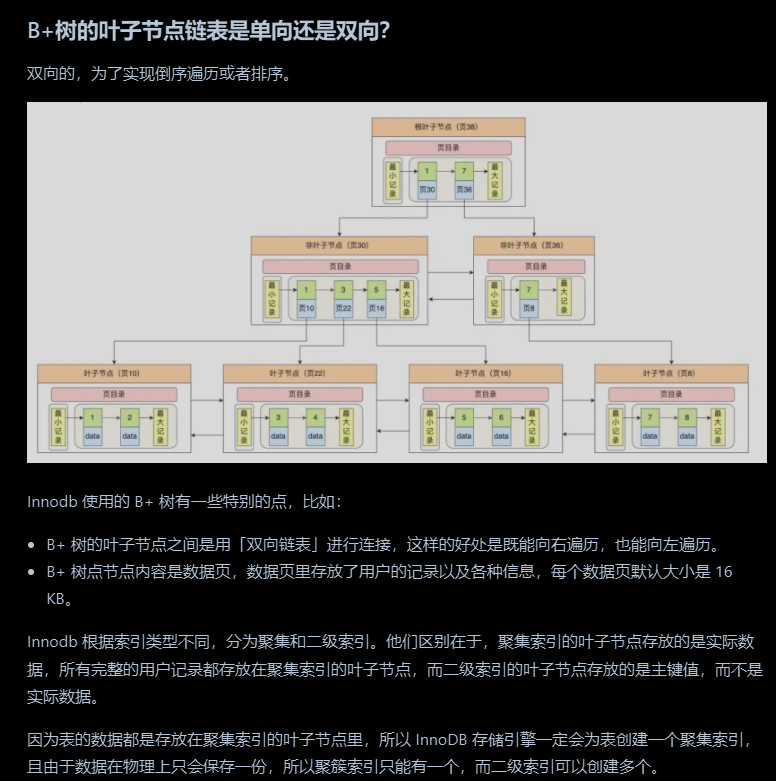
为什么用B+树,和其他结构相比的特点
B+树是怎么增添数据的
1.叶子节点和索引节点都没满,直接将新数据插入到叶子节点中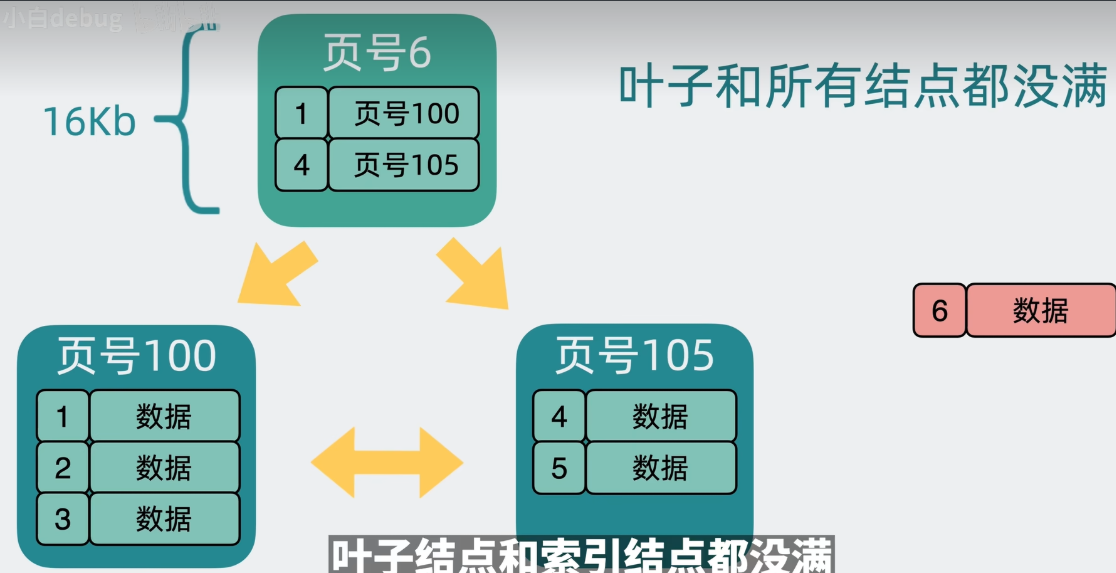
2.叶子节点满了,但是索引节点没满,会拆分叶子节点,添加到新的叶子节点中,而且要补充索引节点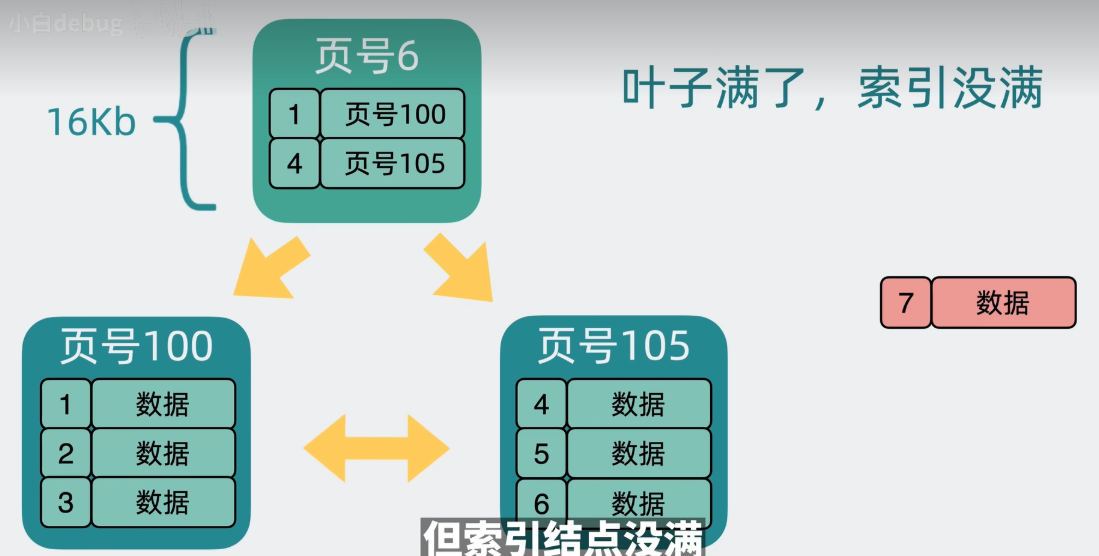
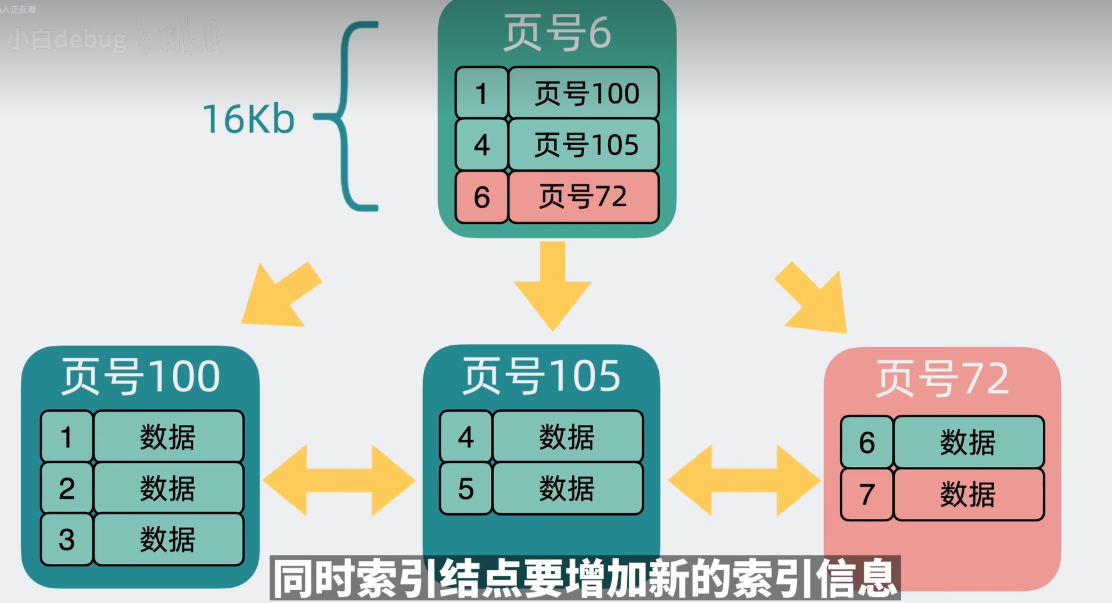
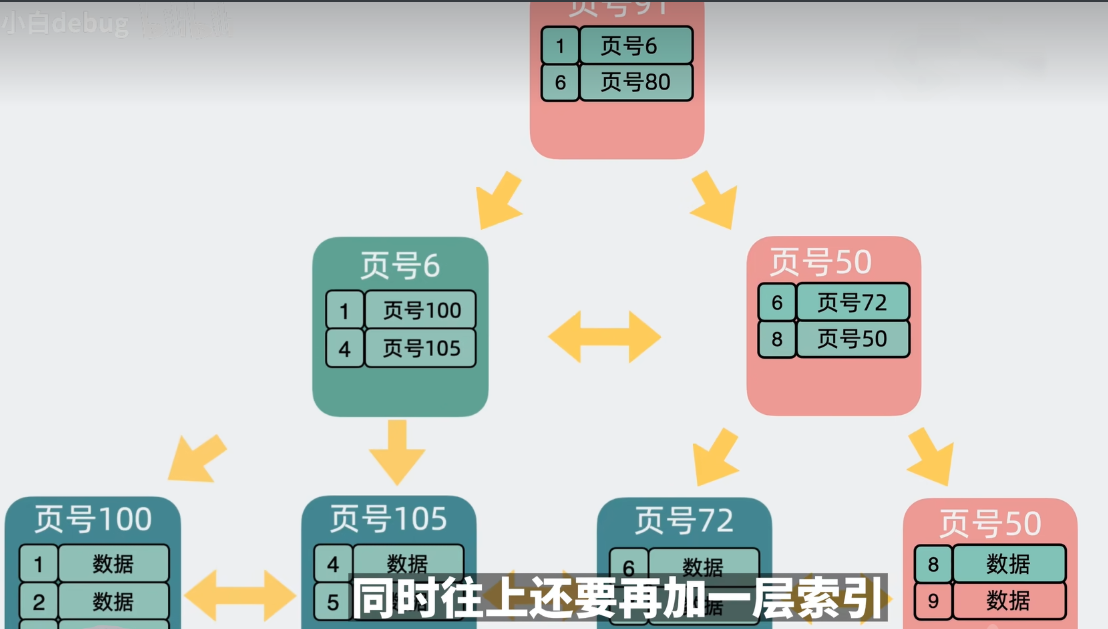
3.叶子节点和索引节点都满了,叶子节点和索引节点都会拆分,并且会生成一个新的索引节点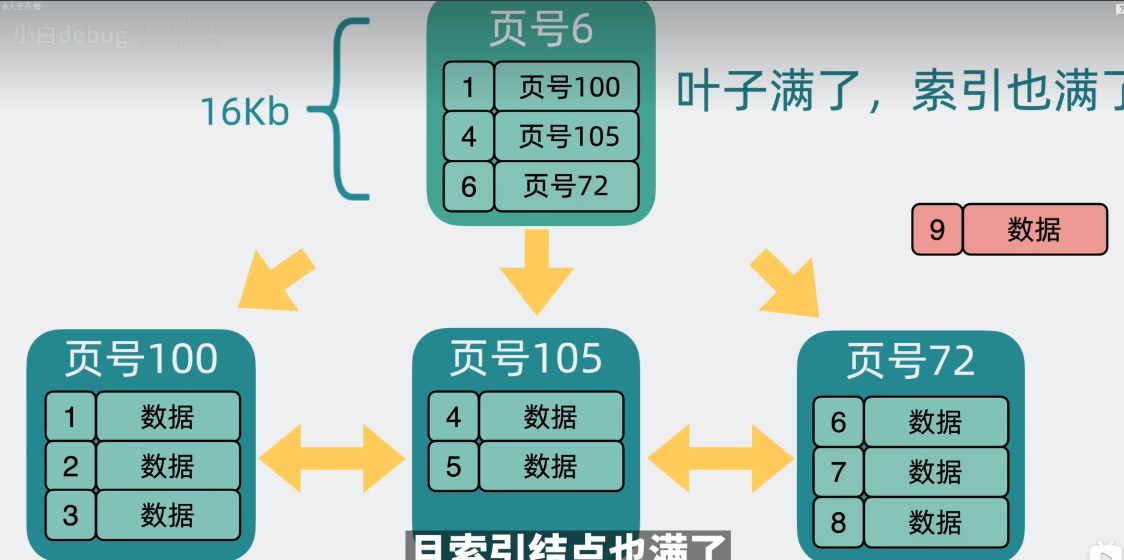
联合索引的实现原理
联合索引的非叶子节点存储的是被设置为联合索引的字段,例如abc三个字段,在叶子节点中,先是按照a字段进行排序,如果a字段相同,再用b排序,如果b相同再根据C进行排序,所以全局只有a是有序的b和c单独都不是有序的,这也是为什么不按照索引的顺序会导致索引失效的原因

创建联合索引时需要注意的条件

场景索引推断

索引失效

什么情况会回表查询

什么是覆盖索引

既是单列索引也是联合索引的优化选择

索引是否是越多越好?
不是,如果是写入操作过多的情况下,每写入一个数据都会需要去维护索引结构,这样反而会造成性能的浪费
索引的优缺点

怎么决定建立哪些索引
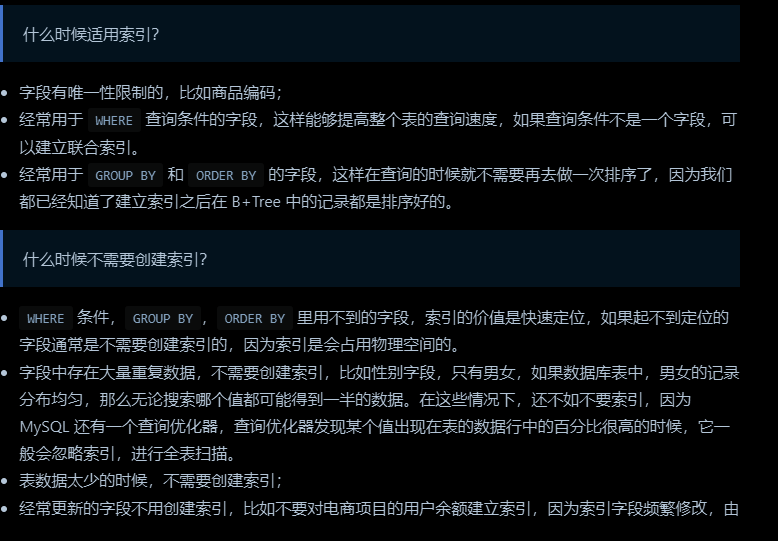
索引优化

事务
事务的特性是什么,如何实现的?
ACID:原子性,一致性,隔离性,持久性
原子性:undolog(回滚日志)来保证
持久性:redolog(重做日志)来保证的
隔离性:MVCC(多版本并发控制)或锁机制来保证
一致性:持久性+原子性+隔离性
出现的并发问题
脏读:一个事务读取到了另外一个未提交事务的数据
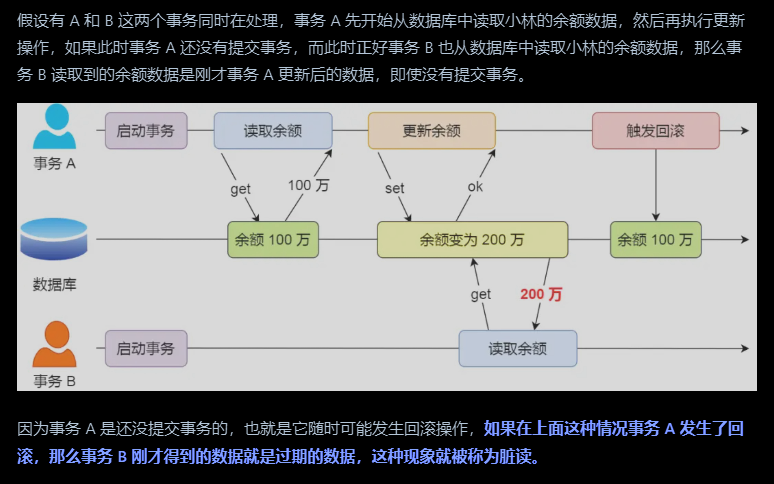
不可重复读
在一个事务内多次读取同一个数据,发生了前后不一致的情况,称为不可重读读,侧重于数值的变化情况
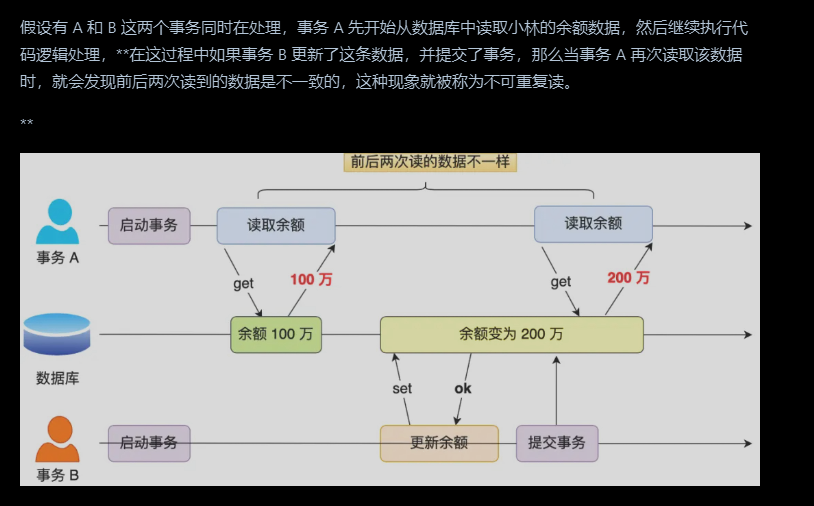
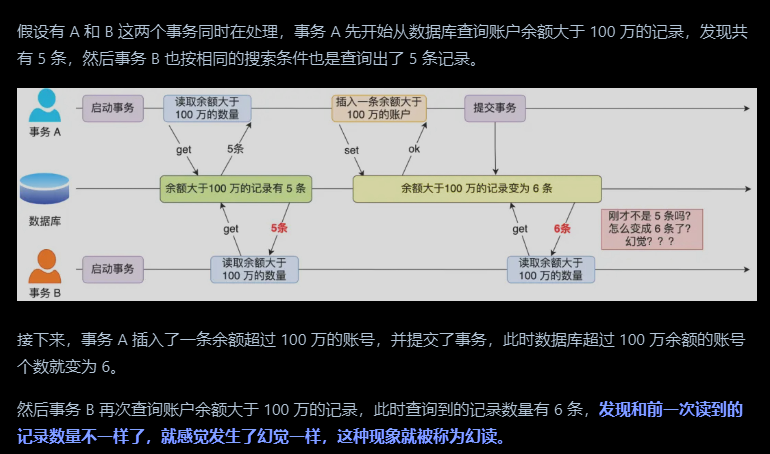
幻读
在一个事务内多次查询符合条件的数据,发现了前后查询同一个数据但是结果不一样的情况,称作幻读,侧重于数据行数的变化
不适合脏读的例子

Mysql如何解决并发问题的
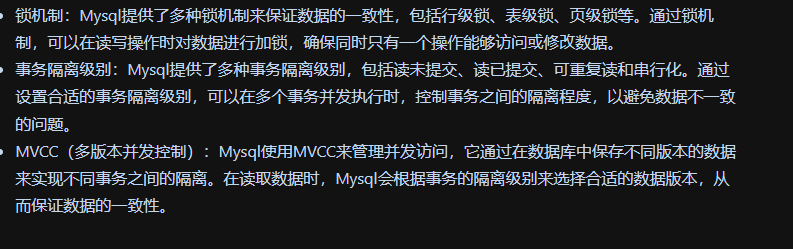
事务的隔离级别有哪些


















 5107
5107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









