







1.整数在内存中的存储
在讲解操作符的时候,我们就讲过了下⾯的内容:
整数的2进制表⽰⽅法有三种,
即 原码、反码和补码
三种表⽰⽅法均有符号位和数值位两部分,符号位都是⽤0表⽰“正”,⽤1表⽰“负”,⽽数值位最 ⾼位的⼀位是被当做符号位,剩余的都是数值位。
正整数的原、反、补码都相同。
负整数的三种表⽰⽅法各不相同。
- 原码:直接将数值按照正负数的形式翻译成⼆进制得到的就是原码。
- 反码:将原码的符号位不变,其他位依次按位取反就可以得到反码。
- 补码:反码+1就得到补码。
对于整型来说:数据存放内存中其实存放的是补码。
为什么呢? 在计算机系统中,数值⼀律⽤补码来表⽰和存储。 原因在于,使⽤补码,可以将符号位和数值域统⼀处理; 同时,加法和减法也可以统⼀处理(CPU只有加法器)此外,补码与原码相互转换,其运算过程是 相同的,不需要额外的硬件电路。
2.⼤⼩端字节序和字节序判断
当我们了解了整数在内存中存储后,我们调试看⼀个细节:
#include <stdio.h>
int main()
{
int a = 0x11223344;
return 0;
}
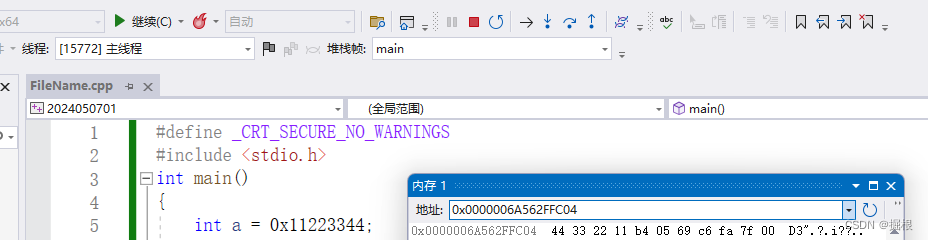 我们发现内存里存的怎么是44332211呢?别着急,我们马上解释
我们发现内存里存的怎么是44332211呢?别着急,我们马上解释
2.1.大小端
C语言中的大小端(Endianness)指的是字节顺序的不同方式,即如何将多字节的数据类型(如整数、浮点数)在内存中存储。
2.1.1高低位
先来了解数字的高低位
0x12345678
越靠近1这边的位就叫高位,越靠近8那边的位叫低位
2.1.2高低地址
什么是高地址,什么是低地址,举举例说明?
可以把主存看成一本空白的作业本,你现在要在笔记本上记录一些内容,他的页码排序是
第一页 : 0x0000001
第二页 : 0x0000002
…
最后一页: 0x00000921 如果你选择从前向后记录(用完第一页,用第二页,类推)这就是先使用低地址,后使用高地址.
0x0000001 -> 0x0000002-> … -> 0x0000092业内有这样表述:动态分配内存时堆空间向高地址增长,说的就是这种情况.
这个向高地址增长就是先使用低地址,后使用高地址的意思.
2 如果你选择从后往前记录(先用笔记本的最后一页,用完后使用倒数第二页,类推) 这就是先使用高地址,后使用低地址
0x0000092 -> … ->0x0000002 -> 0x0000001业内表述:0xbfac 5000-0xbfad a000是栈空间,其中高地址的部分保存着进程的环境变量和命令行参数,低地址的部分保存函数栈帧,栈空间是向低地址增长的.
这个向低地址增长就是先使用高地址,后使用低地址的意思.
2.1.3区分高低地址和高低位
这个
高地址与低地址容易与高位低位产生混淆.比如我这个月工资为
1234(一千二百叁拾肆块),那么这串数字的左边我们称呼为高位,右边称为低位.
(这个高低来自于人类的阅读习惯,数字从左向右,表示由大到小)
在计算机中以int类型存储工资,假设int占用四个字节,每个字节地址如下
0x00008
0x00009
0x0000a
0x0000b把工资加载到内存中时,就会有两种存储方式,如下:
// 大端法
0x00008 => 1
0x00009 => 2
0x0000a => 3
0x0000b => 4如果把上边的存储方式反过来,内存中的高地址存储工资中的高位,则称为小端法
或者
// 小端法
0x00008 => 4
0x00009 => 3
0x0000a => 2
0x0000b => 1内存中的低地址存储工资中的高位这种方式称为大端法.
(注释:可以采用异或方法来记忆 低地址存低位为小端法).
主机采用大端还是小端表示数据由CPU的架构决定,如果两个主机只见交互数据,但是字节序表示不同,需要同化.
2.2.小端字节序存储(Little Endian):
在小端字节序中,最低有效字节存储在最低地址,最高有效字节存储在最高地址。
例如,整数值0x12345678在内存中的存储方式如下:
低地址 ─────> 高地址
78 56 34 12
这种字节顺序在x86架构的计算机上被广泛使用,包括大部分的个人电脑和服务器。
2.3.大端字节序存储·(Big Endian):
在大端字节序中,最高有效字节存储在最低地址,最低有效字节存储在最高地址。
例如,整数值0x12345678在内存中的存储方式如下:
低地址 ─────> 高地址
12 34 56 78
这种字节顺序在一些嵌入式系统和网络协议中使用较多。
2.4.为什么会有大小端?
这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着⼀个字节,⼀个字节为8 bit 位,但是在C语⾔中除了8 bit 的 char 之外,还有16 bit 的 short 型,32 bit 的 long 型(要看 具体的编译器)
另外,对于位数⼤于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度⼤ 于⼀个字节,那么必然存在着⼀个如何将多个字节安排的问题。
因此就导致了⼤端存储模式和⼩端存 储模式。
例如:⼀个 16bit 的 short 型 x ,在内存中的地址为 0x0010 , x 的值为 0x1122 ,那么 0x11 为⾼字节, 0x22 为低字节。对于⼤端模式,就将 0x11 放在低地址中,即 0x0010 中, 0x22 放在⾼地址中,即 0x0011 中。⼩端模式,刚好相反。我们常⽤的 X86 结构是⼩端模式,⽽ KEIL C51 则为⼤端模式。很多的ARM,DSP都为⼩端模式。有些ARM处理器还可以由硬件来选择是 ⼤端模式还是⼩端模式。
简单点说就是硬件厂商各有所好,并没有统一的约定制作制作哪一个,
- 大端的优势在于第一个字节就是高位,很容易判断正负性。
- 小端的优势在于第一个字节是低位,最后一个字节是高位,可以依次取出相应的字节进行运算,并且最终会把符号位刷新,这样运算起来更高效。
2.5.如何确定大小端?
当我们不知道当前换将是大端存储还是小端存储的时候,就需要用代码来确定当前环境的大小端,下面给出了两种确定大小端的方式:
2.5.1共用体确定大小端
共用体里面的变量是公用一块空间的,
int a = 0x11 22 33 44占据了四个字节,
假设是小端第一个字存的就是数据的低位0x44 ,char c只占据了第一个字节
#include<stdio.h>
union U
{
int a;
char c;
};
int A()
{
union U u;
u.a = 0x11223344;
if (u.c == 0x44)
{
return 1;
}
else
return 0;
}
int main()
{
int i = A();
if (i == 1)
{
printf("小端模式\n");
}
else
{
printf("大端模式\n");
}
return 0;
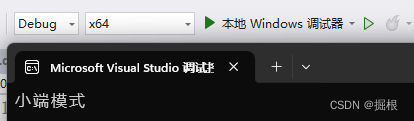
}在我的设备上运行结果如下
2.5.2指针确定大小端
强制类型转换会发生截取,下面用char*强制类型转换,截取了第一个字节的地址,然后解引用读取了第一个字节的数据。
#include<stdio.h>
int B()
{
int i = 0x11223344;
if (*(char*)(&i) == 0x44)
{
return 1;
}
else
return 0;
}
int main()
{
int i = B();
if (i == 1)
{
printf("小端模式\n");
}
else
{
printf("大端模式\n");
}
return 0;
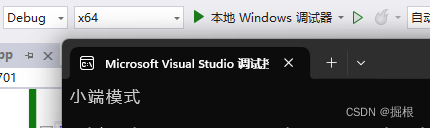
}















 3561
3561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









