







1.进程创建
1.1.再谈fork
在linux中fork函数时非常重要的函数,它从已存在进程中创建一个新进程。新进程为子进程,而原进程为父进程。
#include <unistd.h>
pid_t fork(void);//pid_t为整形 返回值:子进程中的fork()返回0,父进程中的fork()返回子进程的id (pid),出错时返回 -1
在前面创建子进程的时候就学过了fork函数,它能从已经存在进程中创建一个新进程,新进程为子进程,而原进程为父进程。

当进程调用fork,当控制转移到内核中的fork代码后,操作系统会做下列操作:
pid_t fork(void)
{
- 1.分配新的内存块和内核数据结构(task_struct和mm_struct和页表)给子进程
- 2.将父进程部分数据结构内容拷贝至子进程
- 3.添加子进程到系统进程列表当中
- 4.fork返回,开始调度器调度
}
就像下面这样子

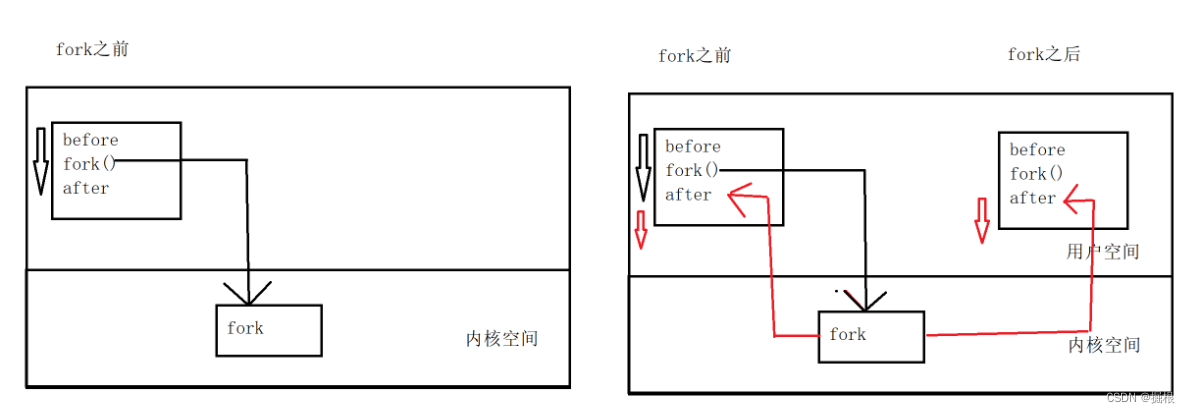 fork之前父进程独立执行,fork之后,父子两个执行流分别执行。注意,fork之后,谁先执行完全由调度器决定。
fork之前父进程独立执行,fork之后,父子两个执行流分别执行。注意,fork之后,谁先执行完全由调度器决定。
子进程的特点:
1.将父进程的所有数据都 共享或拷贝 到了子进程中。(若子进程不对父进程的数据进行修改的话,父子进程的数据也是共享的。若子进程对父进程的数据进行修改时,会发生写时拷贝,将父进程的数据进行拷贝一份到子进程中)
写时拷贝 :(是一种延时申请技术,可以提高整机内存的使用率)
2.子进程和父进程的所有代码共享
3.由于 程序计数器 和 CPU中存储上下文数据的寄存器 原因,子进程虽然可以共享父进程的所有代码,但是在子进程中是从fork()创建子进程之后的代码开始执行的,fork()创建子进程之前的代码默认已经执行过,不会重复执行,所以子进程会执行子进程创建之后的代码。但是由于fork()进行返回值是在子进程创建之后进行返回的,所以子进程依然会执行fork()的返回值。

我们之前详细讲过fork函数,就不再讨论fork函数了
1.2.创建进程
我们要创建5个进程,该怎么做?
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#define N 5
void runChild ()
{
int cnt=10;
while(cnt)
{
printf("I am child:%d ,ppid: %d\n",getpid(),getppid());
sleep(1);
cnt--;
}
}
int main()
{
for(int i=0;i<N;++i)
{
pid_t id =fork();
if(id==0)
{
runChild();
exit(0);
}
}
sleep(1000);
}我们运行看看,用另外一个账号来看看
while :; do ps ajx | grep 'mytest' ;sleep 1; echo "######################"; done

 最后子进程全变僵尸进程了
最后子进程全变僵尸进程了
2.进程退出
2.1.进程退出场景
- 此时代码运行完毕,结果正确 (这个时候main函数的返回值为0则为正确,0:success)
- 此时代码运行完毕,结果不正确(这个时候main函数的返回值非0则为不正确,返回值:报错信息)
- 此时代码异常终止,意思就是代码没跑完(这个时候main函数的返回值不具有意义,此时应该去看退出信号)
2.2. 退出码
退出码(或退出状态)是指在命令执行结束后,系统返回给使用者的一个数值,用以表示命令的执行状态。
通过判断退出码,我们可以了解命令是成功完成还是以错误结束。
基本来说,退出码是一个用来反馈命令执行结果的重要指标。
我们以前在写c/c++代码的时候,通常main函数最后都要有一句return 0,这些数字有什么意义吗?
int main()
{
//...
return 0;
}
事实上,这个return 0里的0就是进程的退出码,返回给这个c/c++程序的父进程,这个返回码包含了这个子进程的运行状况,退出码都是一个数字,不同数字对应不同的执行状况
我们可以来看看
#include<stdio.h>
#include<string.h>
int AddtoTarget(int from,int end)
{
int sum=0;
for(int i=from;i<end;++i)
{
sum+=i;
}
return sum;
}
int main()
{
//写代码是为了完成某件事情,我们如何得知事情完成的怎么样呢?
//进程退出码
int num=AddtoTarget(1,100);
if(num == 5050)
return 0;
else
return 1;
return 0;
}
$? 该符号永远记录最近一个进程在命令行中执行完毕时对应的退出码
echo $? //查看进程退出码
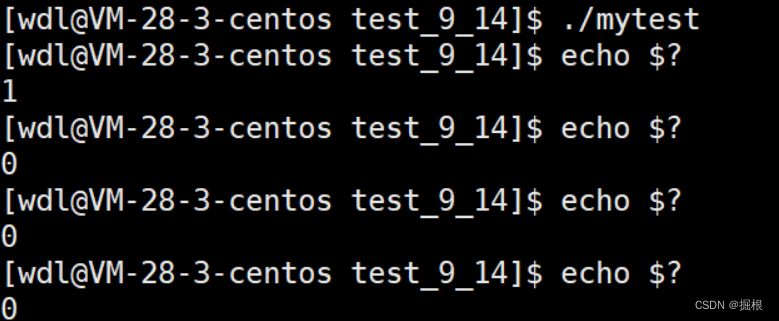
这里下面的三个0是怎么回事呢?
这是因为echo 也是一个子进程,因此剩下的三个的是echo $?是一个echo子进程的退出码。
(main函数的返回值实际上是 进程的退出码,用于表示进程是否是正确返回。)
- 第一种:若退出码是0,则表示进程正确返回,0:success。
- 第二种:若退出码为非0,则表示进程不正确返回,并且每个退出码都对应一个报错信息,退出码:报错信息。
- 意义:将返回值返回给上一进程,用于监控进程的退出状态。出错时方便定位错误。
有人就说了退出码都是数字,我们怎么知道它们分别对应什么错误?
还好c语言自带了一个查询退出码的函数——strerror
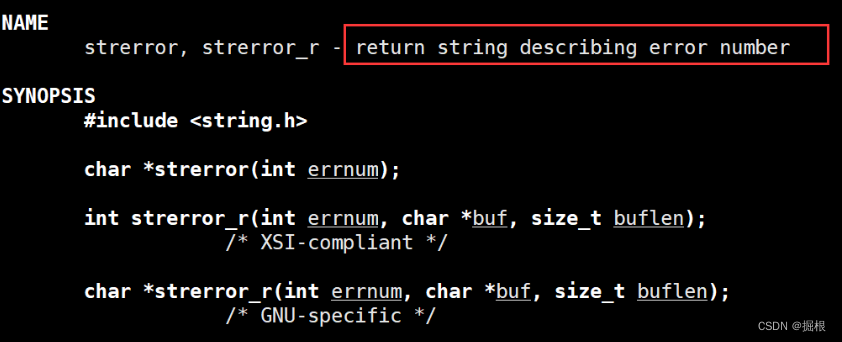
#include<stdio.h>
#include<string.h>
int main()
{
for(int i=0;i<200;++i)
{
printf("%d: %s\n",i,strerror(i));
}
return 0;
}
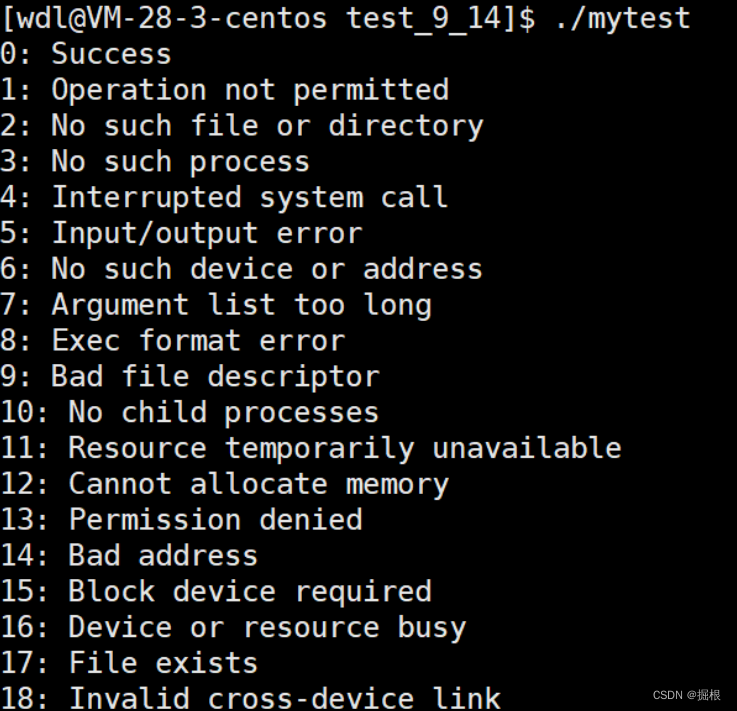
strerror记录了对应的退出码的映射信息,总共135个,这里截取了一小部分。
嗯?第二条怎么这么熟悉?我们拿ll来找一个不存在的目录看看

神奇吧!!!!!
ls也是一个进程,它也有退出码
我们可不可以自己设置一套退出码体系?
#include<stdio.h>
#include<string.h>
char* errorarray[]={
"error1","error2","error3","error4"};
int main()
{
for(int i=0;i<200;++i)
{
printf("%d: %s\n",i,strerror(i));
}
return errorarry[0];
}父进程为什么要关心退出码?
其实父进程也只是个跑腿的,真正关心的应该是用户才对
c语言里有一个错误码,只记录最近一次的进程的错误,搭配strerror就可得到错误码里的信息

2.3.退出信号
子进程执行过程中出现了错误,OS此刻直接把正在执行的进程干掉,不让进程继续执行了。当我们的程序运行(进程)语言层面上是崩溃,系统层面上是OS杀死进程。
- 语言层面上,编程运行奔溃了
- 系统层面上,OS杀死了进程,此时退出码就没有意义了。
我们可查询一下这个退出信号

我们来见见这个退出信号
#include<stdio.h>
#include<unistd.h>
int main()
{
while(1)
{
printf("hello linux!pid:%d\n",getpid());
sleep(1);
}
}我们在一个账号运行

我们在另一个账号里杀掉这个进程

信号9的作用就是这样
我们再运行一下这个程序


左边怎么有这个提示,这个就是信号8的作用
我们再来


怎么样呢?这就是信号11的意思
进程出现异常,本质就是我们的进程收到了信号
2.4.怎么退出进程
2.4.1.main函数return返回,其他函数return是调用结束。
return是一种更常见的退出进程方法。执行return n等同于执行exit(n),因为调用main的运行时函数会将main的返 回值当做 exit的参数。
2.4.2.任意地方调用exit。
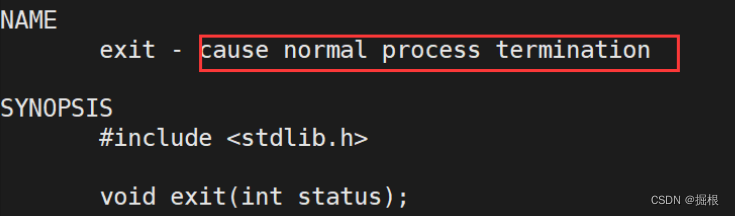
我们来使用一下
#include<stdio.h>
#include<string.h>
#include<unistd.h>
#include<stdlib.h>
int AddtoTarget(int from, int end)
{
int sum = 0;
for (int i = from; i <= end; ++i)
{
sum += i;
}
exit(12);
// return sum;
}
int main()
{
int ret = AddtoTarget(1, 100);
if (ret == 5050)
return 0;
else
return 1;
}

2.4.3.任意地方调用_exit(了解)
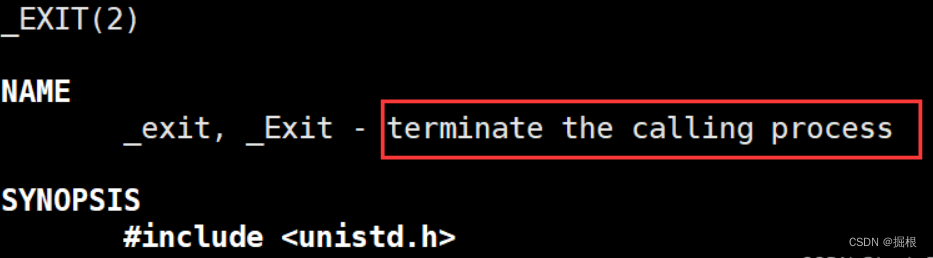
我们来使用一下
#include<stdio.h>
#include<string.h>
#include<unistd.h>
#include<stdlib.h>
int AddtoTarget(int from, int end)
{
int sum = 0;
for (int i = from; i <= end; ++i)
{
sum += i;
}
_exit(12);
// return sum;
}
int main()
{
int ret = AddtoTarget(1, 100);
if (ret == 5050)
return 0;
else
return 1;
}对比exit和_exit发现,都可以使进程在任意地方结束。
2.4.4.exit()和_exit()的区别
我们先来看两段代码
#include<stdio.h> #include<string.h> #include<unistd.h> #include<stdlib.h> int main() { printf("hello linux"); sleep(2); exit(1); }
#include<stdio.h> #include<string.h> #include<unistd.h> #include<stdlib.h> int main() { printf("hello linux"); sleep(2); _exit(1); }
对比发现,exit会刷新缓存区,而_exit并不会刷新缓存区——说明exit可能会调用_exit。


事实上:
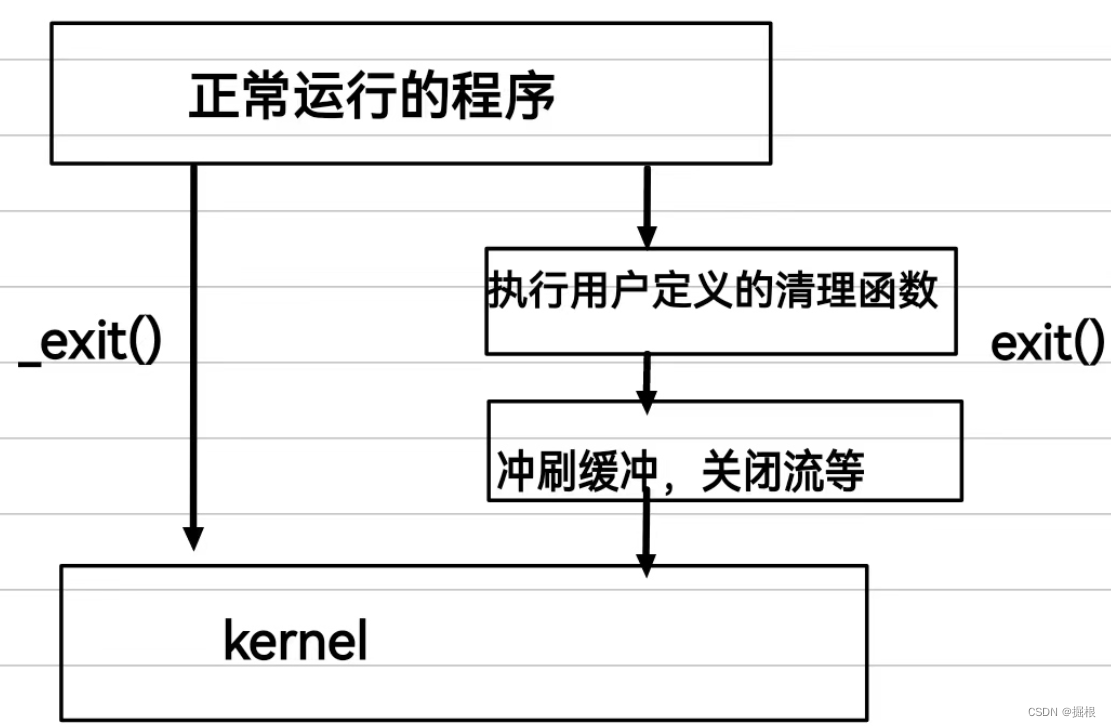
exit()和_exit()的底层区别:
- _exit():_exit()是系统调用接口的函数。
- exit():而exit()是把_exit()封装在内,并且增加了其他的函数,共同组合成exit()——是一个库函数。
exit是库函数,_exit是系统调用。库函数在系统调用上面。
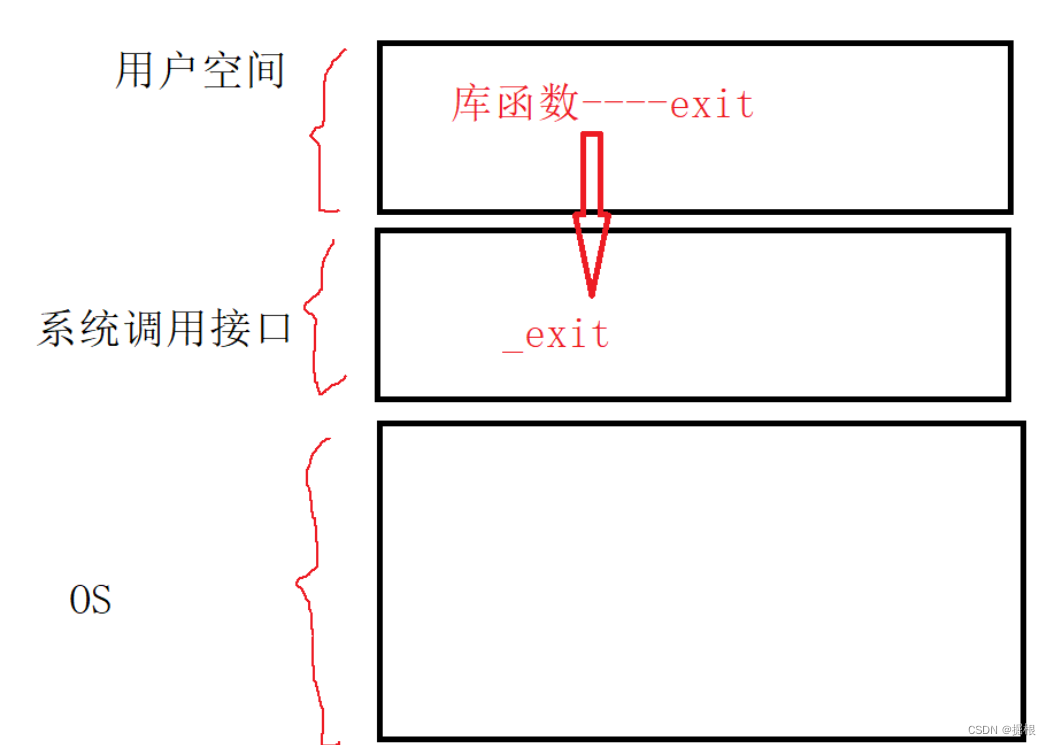
如果缓存区在内存,exit调用_exit去终止进程,exit/_exit都应该会刷新缓冲区。
所以缓冲区在用户空间,是用户级的缓冲区。
2.4.5.异常退出
·ctrl + c,信号终止















 3094
3094











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









