






XML解析
1.1 解析概述
当将数据存储在XML后,我们就希望通过程序获取XML的内容。我们使用Java基础所学的IO知识是可以完成的,不过需要非常繁琐的操作才可以完成,且开发中会遇到不同问题(只读、读写)。
人们为不同问题提供不同的解析方式,使用不同的解析器进行解析,方便开发人员操作XML。
1.2 解析方式和解析器
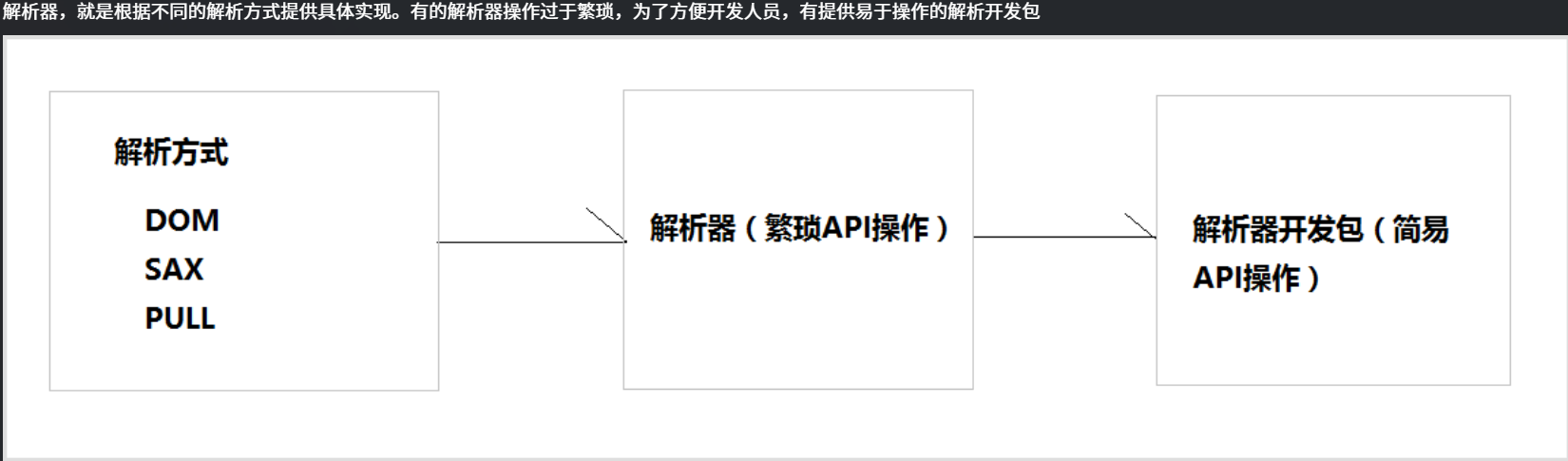
开发中比较常见的解析方式有三种,如下:
- DOM:要求解析器把整个XML文档装载到内存,并解析成一个Document对象a)优点:元素与元素之间保留结构关系,故可以进行增删改查操作。b)缺点:XML文档过大,可能出现内存溢出
- SAX:是一种速度更快,更有效的方法。它逐行扫描文档,一边扫描一边解析。并以事件驱动的方式进行具体解析,每执行一行,都触发对应的事件。a)优点:处理速度快,可以处理大文件b)缺点:只能读,逐行后将释放资源,解析操作繁琐。
- PULL:Android内置的XML解析方式,类似SAX。(了解)
常见的解析器

小结
xml的常用解析方式:
- DOM
- SAX
- PULL
基于解析方式,常用的解析工具包: Dom4j
Dom4j的基本使用
DOM解析原理及结构模型
解析原理
将整个XML文档加载到内存,生成一个DOM树,并获得一个Document对象,通过Document对象就可以对DOM树进行操作。以下面books.xml文档为例。
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book id="0001">
<name>JavaWeb开发教程</name>
<author>张孝祥</author>
<sale>100.00元</sale>
</book>
<book id="0002">
<name>三国演义</name>
<author>罗贯中</author>
<sale>100.00元</sale>
</book>
</books>结构模型
DOM中的核心概念就是节点,在XML文档中的元素、属性、文本,在DOM中都是节点!所有的节点都封装到了Document对象中。
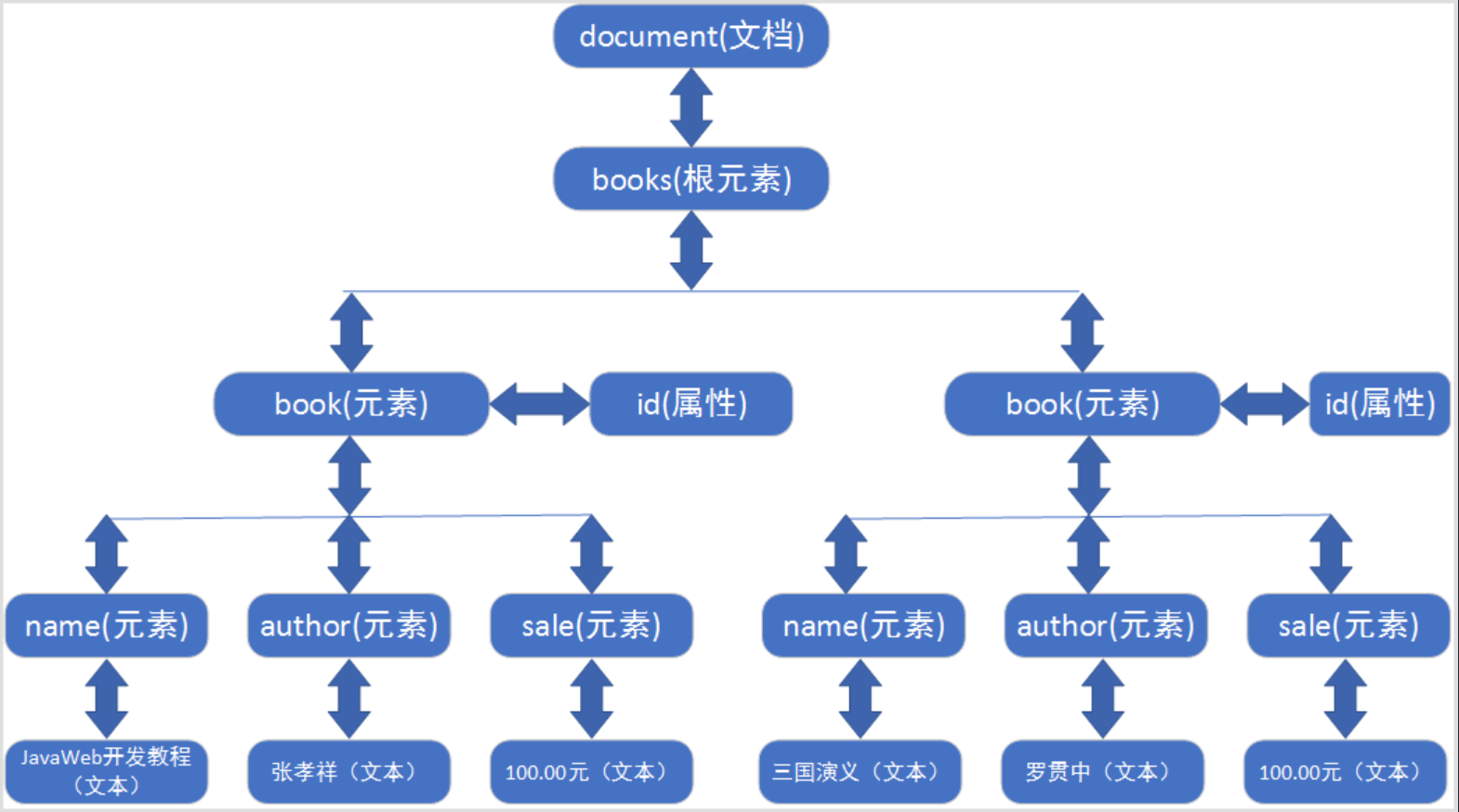
结论:使用Document对象,就可以去访问DOM树中的每一个节点
引入dom4j的jar包
去官网下载 zip 包。Making Your own Website - HTML, Javascript, PHP, Online marketing and other website making information...
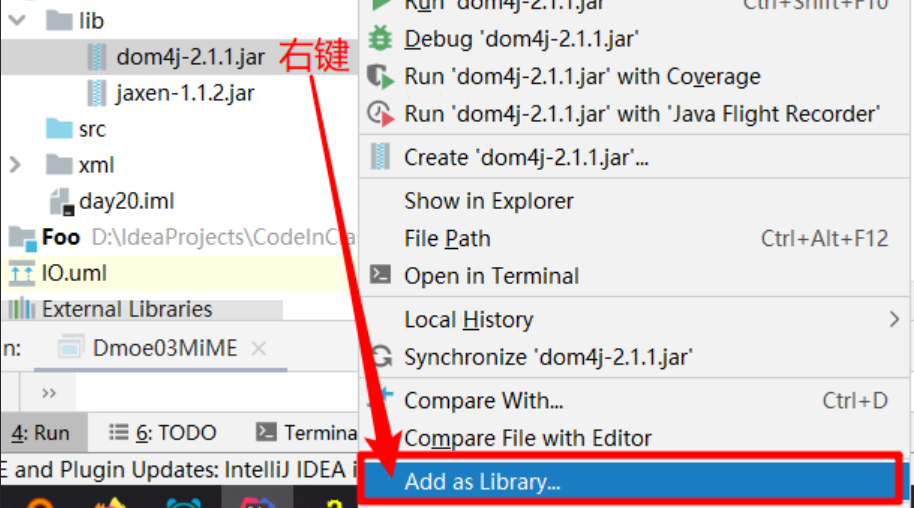
通常我们会在项目中创建lib文件夹,将需要依赖的库放在这里库导入方式:
- 在IDEA中,选择项目鼠标右键--->弹出菜单-->open Module settings”-->Dependencies-->+-->JARs or directories... 找到dom4j-1.6.1.jar,成功添加之后点击"OK" 即可。
- 直接右键选择:Add as Library
-
小结
dom4j的解析思想,先把xml文档加载到内存中,从而得到一个DOM树,并创建一个Document对象去维护dom树。
利用Document对象,就可以去解析DOM树(解析XML文件)
常用的方法
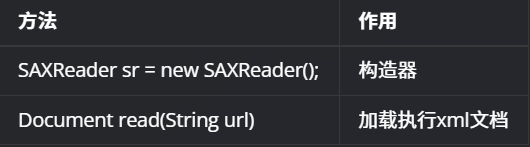
dom4j 必须使用核心类SaxReader**加载xml文档获得Document,通过Document对象获得文档的根元素,然后就可以操作了。
SAXReader对象
Document对象
Element对象

小结
解析xml的步骤:
- 创建SaxReader对象,调用read方法关联xml文件,得到一个Document对象
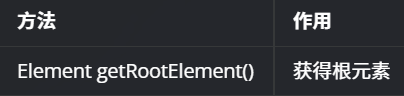
- 通过Document对象,获取根元素
- 获取根元素之后,就可以层层深剥,运用Element相关的API进行解析其子元素
方法演示
复制资料下的常用xml中"books.xml",内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book id="0001">
<name>JavaWeb开发教程</name>
<author>张孝祥</author>
<sale>100.00元</sale>
</book>
<book id="0002">
<name>三国演义</name>
<author>罗贯中</author>
<sale>100.00元</sale>
</book>
</books>注意:为了便于解析,此xml中没有添加约束
Dom4J结合XPath解析XML
XPath使用步骤
步骤1:导入jar包(dom4j和jaxen-1.1-beta-6.jar)
步骤2:通过dom4j的SaxReader获取Document对象
步骤3: 利用Xpath提供的api,结合xpath的语法完成选取XML文档元素节点进行解析操作。

我们熟知的Document,Element等都是Node的子类型,因此也能使用上述selectNode的方法。如下图

XPath语法XPath也是一种解析XML或者HTML的方式。
- XPath表达式,就是用于选取XML文档中节点的表达式字符串。获取XML文档节点元素一共有如下4种XPath语法方式:
-
- 绝对路径表达式方式 例如: /元素/子元素/子子元素...
- 相对路径表达式方式 例如: 子元素/子子元素.. 或者 ./子元素/子子元素..
- 全文搜索路径表达式方式 例如: //子元素//子子元素
- 谓语(条件筛选)方式 例如: //元素[@attr]
在xml解析得到的一个文档对象中,Document,Element,Attribute,Text ,都是接口Node的子类型。
Node中存在两个方法,可以结合xpath使用查询节点:
List<Node> selecteNodes(路径) :将所有满足路径的节点给获取出来
Node selecteSingleNode(路径) :获取单个满足路径的节点
xpath使用步骤:
- 创建SAXReader对象,调用read方法,关联xml文件。得到Document对象
- 就可以使用Document对象来调用方法传入xpath路径
绝对路径表达式
格式:
String xpath="/根元素/子元素/子子元素...";绝对路径是以“/”开头,一级一级描述标签的层级路径就是绝对路径,
这里注意不可以跨层级
- 演示需求(将素材中的Contact.xml拷贝到项目中)
采用绝对路径获取从根节点开始逐层的查找name节点列表并打印信息
String path="/contactList/contact/name";实现步骤:
- 先创建SAXReader对象,调用read方法,将Contact.xml关联,得到Document对象
- 定义绝对路径
- 调用selectedNodes
public class Demo01 {
public static void main(String[] args) throws DocumentException {
//采用绝对路径获取从根节点开始逐层的查找name节点列表并打印信息
//1. 先创建SAXReader对象,调用read方法,将Contact.xml关联,得到Document对象
SAXReader sr = new SAXReader();
Document doc = sr.read("day15/xml/Contact.xml");
//2. 定义绝对路径
String xpath = "/contactList/contact/name";
//3. 调用selectedNodes
List<Node> nameNodes = doc.selectNodes(xpath);
for (Node nameNode : nameNodes) {
String text = nameNode.getText();
System.out.println("text = " + text);
}
}
}
text = 潘金莲
text = 武松
text = 武大狼相对路径表达式
相对路径介绍
格式:
String xpath2="./子元素/子子元素"; // "./"代表当前元素路径位置需求:先采用绝对路径获取 contact 节点 再采用相对路径获取下一级name子节点并打印信息
public class Demo01 {
public static void main(String[] args) throws DocumentException {
//先采用绝对路径获取 contact 节点 再采用相对路径获取下一级name子节点并打印信息。
//1. 先创建SAXReader对象,调用read方法,将Contact.xml关联,得到Document对象
SAXReader sr = new SAXReader();
Document doc = sr.read("day15/xml/Contact.xml");
//先使用绝对路径,获取contact
List<Node> contactNodes = doc.selectNodes("/contactList/contact");
for (Node contactNode : contactNodes) {
//使用相对路径获取name,并获取文本打印
Node node = contactNode.selectSingleNode("./name");
System.out.println("node.getText() = " + node.getText());
}
}
}
node.getText() = 潘金莲
node.getText() = 武松
node.getText() = 武大狼全文搜索路径表达式
全文搜索路径介绍
格式:
String xpath1="//子元素//子子元素";“/”符号,代表逐级写路径
“//”符号,不用逐级写路径,可以直接选取到对应的节点,是全文搜索匹配的不需要按照逐层级
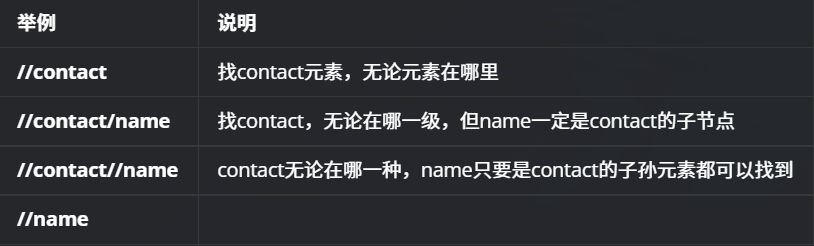
需求:直接全文搜索所有的 name元素并打印
public class Demo01 {
public static void main(String[] args) throws DocumentException {
//需求:直接全文搜索所有的 name元素并打印
//1. 先创建SAXReader对象,调用read方法,将Contact.xml关联,得到Document对象
SAXReader sr = new SAXReader();
Document doc = sr.read("day15/xml/Contact.xml");
List<Node> nodes = doc.selectNodes("//name");
for (Node node : nodes) {
System.out.println("node.getText() = " + node.getText());
}
}
}
/ 表示根节点 (不能跨层级)
// 表示全文任意节点 (可以跨层级)
谓语
介绍
谓语,又称为条件
筛选方式,就是根据条件过滤判断进行选取节点格式:
String xpath1="//元素[@属性名]";//查找元素对象,全文中只要含有该属性名的元素
String xpath2="//元素[@属性名=value]";//查找元素对象,全文中只要含有该属性,并指定的值需求:查找含有id属性的contact元素
public class Demo01 {
public static void main(String[] args) throws DocumentException {
//查找含有id属性的contact元素
SAXReader sr = new SAXReader();
Document doc = sr.read("day15/xml/Contact.xml");
//List<Node> nodes = doc.selectNodes("//contact[@id]");//获取含有属性id的元素
List<Node> nodes = doc.selectNodes("//contact[@id=1]");//获取含有属性并且值为1的元素
for (Node node : nodes) {
//将节点,先转换Element
Element contact = (Element) node;
System.out.println("contact.elementText(\"name\") = " + contact.elementText("name"));
}
}
}小结
- 在xpath解析xml方式中,最核心的就是使用了"路径表达式"
-
- xpath是利用"路径表达式"实现对xml文件的解析
- 路径表达式的语法:
-
- 绝对路径表达式 /根元素/子元素/子子元素/.... (一层一层查找)
- 相对路径表达式 ./子元素/子子元素/.....
- 全文搜索路径表达式 //元素 (会跨层级进行全文查找)
- 条件筛选表达式 //元素[@属性名]
//元素[@属性名=属性值]















 5248
5248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









