







requests库
1. 实例感受
使用get请求对百度网站发送请求,获取百度网页的部分源码:
import requests
r = requests.get('https://www.baidu.com/')
print(type(r))
print(r.status_code)
print(type(r.text))
print(r.text[:100])
print(r.cookies)
输出结果:
<class 'requests.models.Response'>
200
<class 'str'>
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charse
<RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
2. requests发送get请求
通过requests.get()请求方式向目标服务器发送请求
2.1. 获取网页源代码
这里只输出部分(一般网页源代码都很长)
import requests
url = 'https://www.baidu.com/'
r = requests.get(url = url)
print(r.text[:100])
输出为:
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charse
上述代码只是对get请求的最基础的用法,即在requests.get()方法只中放入url参数即可获取网页源代码,但是在很多情况下,这种方式会被服务器检测到,于是可以传入更多的参数来为爬虫做伪装,即让爬虫程序看起来更像是浏览器。
2.2 添加请求头
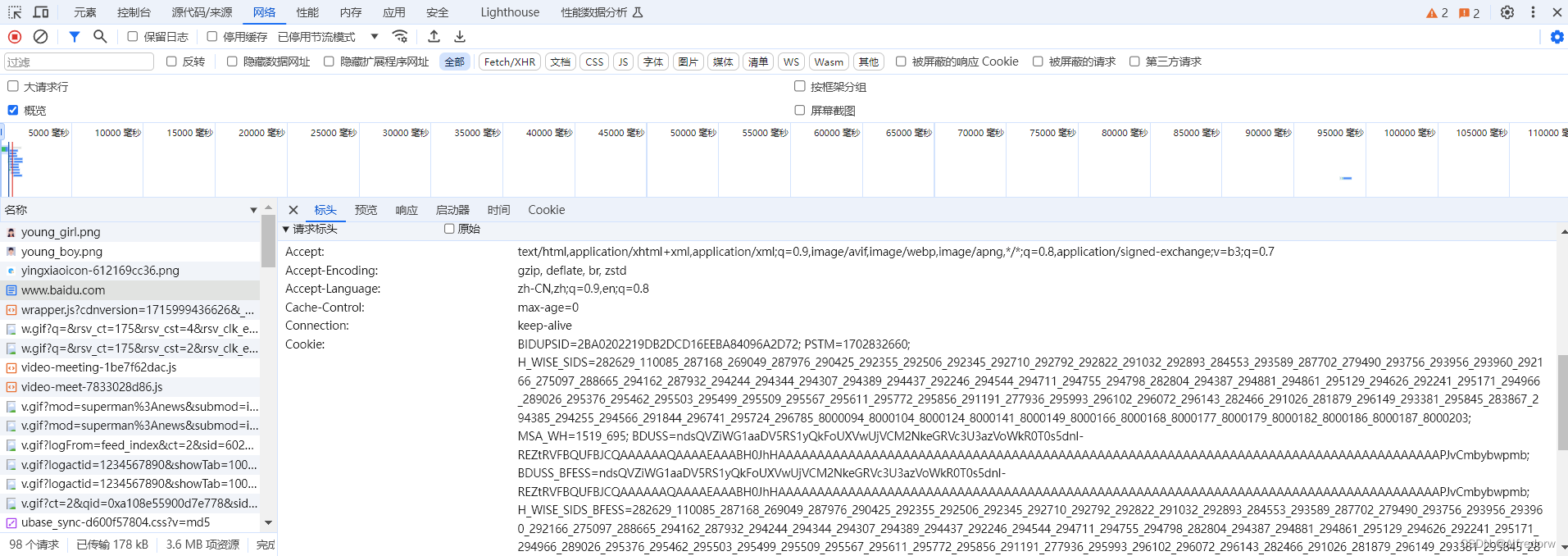
在这里显示的就是我们的请求头部分,在使用get请求时,添加请求参数,让爬虫程序得到一成伪装
import requests
url = 'https://www.baidu.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT......',
'Cookir': '......',
}
r = requests.get(url=url,headers=headers)
可以看到,在上述代码中,我们添加了headers参数,同时headers为字典型变量,里面可以添加很多东西,而这些东西都是来源于浏览器的请求头里面的内容。
2.3 添加附加额外信息
在get请求中,添加第三个参数params,作为添加额外信息的内容,这样,可以加快对目标需求的获取
import requests
r = requests.get('https://www.httpbin.org/get')
print(r.text)
import requests
data = {
'name': 'germey',
'age': 25
}
r = requests.get('https://httpbin.org/get', params=data)
print(r.text)
输出结果为:
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "www.httpbin.org",
"User-Agent": "python-requests/2.31.0",
"X-Amzn-Trace-Id": "Root=1-6648165a-3b8775a57dd055223ad2da3a"
},
"origin": "111.181.49.208",
"url": "https://www.httpbin.org/get"
}
{
"args": {
"age": "25",
"name": "germey"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.31.0",
"X-Amzn-Trace-Id": "Root=1-6648165c-151b9e0448eb6aa857fa7654"
},
"origin": "111.181.49.208",
"url": "https://httpbin.org/get?name=germey&age=25"
}
输出解释:
- 第一个输出是基本的 GET 请求,没有添加任何 params。因此,args 部分是一个空字典 {}。
- 第二个输出是添加了 params 参数的 GET 请求。在这个例子中,params 是一个字典 {‘name’: ‘germey’, ‘age’: 25}。这些参数被自动转换为查询字符串 ?name=germey&age=25 并附加到 URL 末尾。在服务器响应的 JSON 中,这些参数显示在 args 部分,即 {“name”: “germey”, “age”: “25”}。
- 至于为什么这些参数在响应中位于 args 部分,这是因为 httpbin.org 的设计。
3. requests发生post请求
post请求更多是运用在需要对表单数据发送请求时使用,比如登录。
示例:
import requests
data = {'name': 'germey', 'age': '25'}
r = requests.post("https://www.httpbin.org/post", data=data)
print(r.text)
输出结果:
{
"args": {},
"data": "",
"files": {},
"form": {
"age": "25",
"name": "germey"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "18",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "www.httpbin.org",
"User-Agent": "python-requests/2.31.0",
"X-Amzn-Trace-Id": "Root=1-664817cd-0bc47513648ca8ee5dbd2364"
},
"json": null,
"origin": "111.181.49.208",
"url": "https://www.httpbin.org/post"
}
输出解释:
在post请求中,我们传入了data参数,在返回结果中,form部分就是我们提交的数据。
4. 高级用法
4.1 Cookie设置
获取github的用户信息时,添加cookie值来获取
import requests
headers = {
'Cookie': '_octo=GH1.1.1849343058.1576602081; _ga=GA1.2.90460451.1576602111; __Host-user_session_same_site=nbDv62kHNjp4N5KyQNYZ208waeqsmNgxFnFC88rnV7gTYQw_; _device_id=a7ca73be0e8f1a81d1e2ebb5349f9075; user_session=nbDv62kHNjp4N5KyQNYZ208waeqsmNgxFnFC88rnV7gTYQw_; logged_in=yes; dotcom_user=Germey; tz=Asia%2FShanghai; has_recent_activity=1; _gat=1; _gh_sess=your_session_info',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36',
}
r = requests.get('https://github.com/', headers=headers)
print(r.text)
输出结果:
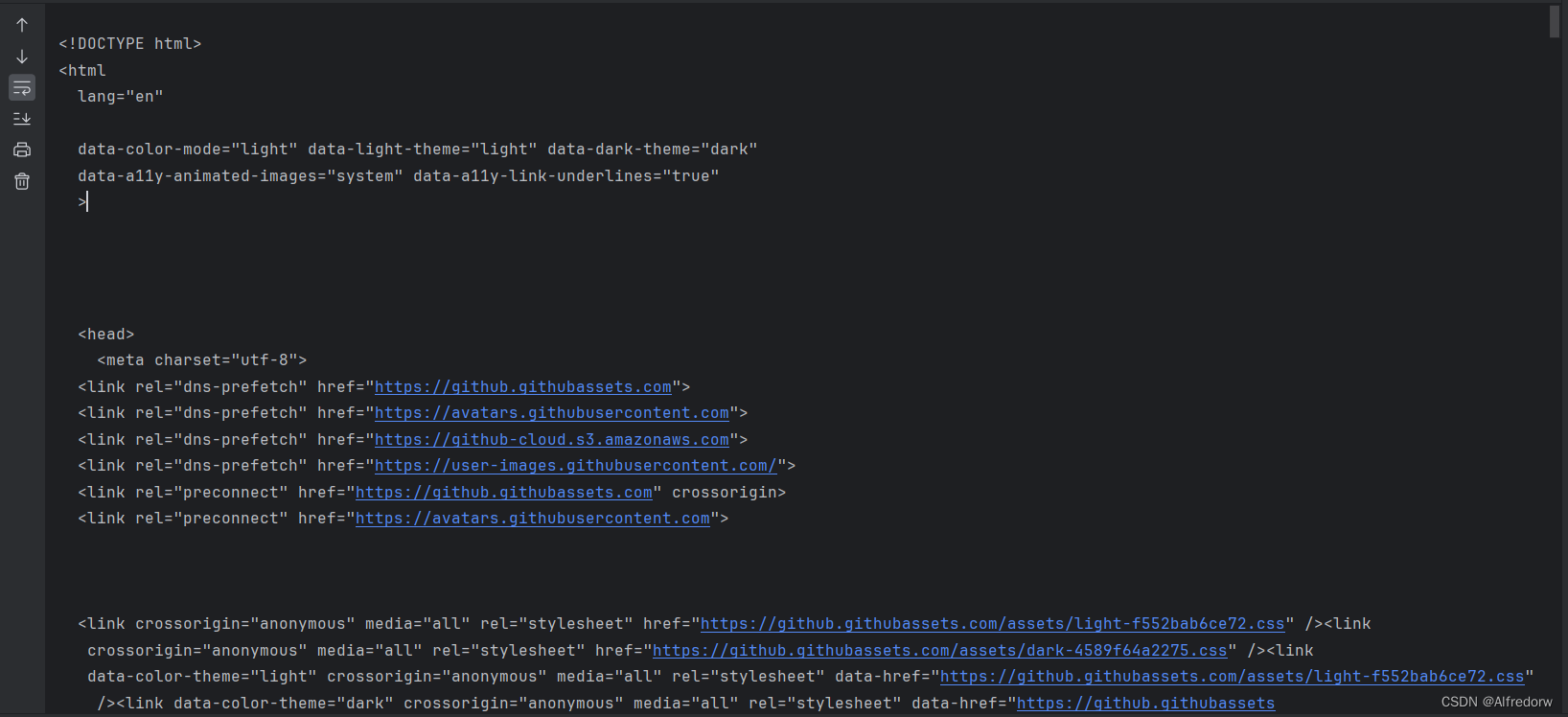
使用Cookie成功模拟了登录状态
4.2 Session维持
为什么要使用session维持来获取?
当我们爬取一个网页信息时,会用到get和post两种请求方式,但当这两个方式实际上是不同的session,或者说用两个浏览器打开了不同的页面。即使添加cookie参数也不一定都会解决,因为每个网页的Cookie值可能会不相同,所以在这种情况下,我们使用session维持的手段来爬取信息。
以测试网址为例,获取测试网址的Cookie值
在使用Session维持时,需要实例化一个Session对象,在这个实例化对象的基础上,再使用get或post方法
import requests
requests.get('https://www.httpbin.org/cookies/set/number/123456789')
r = requests.get('https://www.httpbin.org/cookies')
print(r.text)
import requests
s = requests.Session()
s.get('https://www.httpbin.org/cookies/set/number/123456789')
r = s.get('https://www.httpbin.org/cookies')
print(r.text)
输出结果
{
"cookies": {}
}
{
"cookies": {
"number": "123456789"
}
}















 7643
7643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









