






深入剖析缓存三兄弟:穿透、击穿、雪崩
在现代高并发、高性能的系统中,缓存(如 Redis、Memcached)扮演着至关重要的角色,它能极大减轻数据库压力,提升系统响应速度。然而,缓存并非万能,使用不当或遭遇特定场景时,会引发三个令人头疼的问题:缓存穿透、缓存击穿和缓存雪崩。它们就像潜伏的“三兄弟”,随时可能让你的系统性能急剧下降甚至崩溃。本文将深入浅出地解析这三者的概念、区别、危害,并提供详细的解决方案和实战图解。
一、缓存穿透
-
概念: 查询一个数据库中根本不存在的数据。由于缓存中没有,请求会直接穿透缓存层,每次都去查询数据库。如果短时间内有大量这类恶意或无效的请求,数据库将不堪重负。
-
核心问题: 查询不存在的数据。
-
危害:
- 大量无效请求直接冲击数据库,消耗数据库连接和计算资源。
- 可能导致数据库连接池耗尽,服务不可用。
- 容易被恶意攻击者利用(如用随机ID发起大量请求)。
-
场景举例: 用户查询一个不存在的商品ID (product_id=9999999)。缓存中没有,数据库中也找不到。短时间内大量这样的查询涌向数据库,数据库的压力就会剧增。
-
解决方案:
-
缓存空对象 :
-
做法: 当数据库查询返回为空时,仍然将这个空结果缓存起来,并设置一个较短的过期时间 ,防止太多的空数据占据资源。
-
优点: 实现简单,能有效拦截短时间内对同一个不存在Key的重复查询。
-
缺点:
- 消耗缓存空间存储大量无效Key。
- 如果攻击者使用海量不同的无效Key,此方案效果有限(缓存空间可能被撑爆)。
- 存在短暂的数据不一致(在空对象过期前,如果数据库新增了该数据,客户端看到的仍是空/无效状态)。
-
图解:
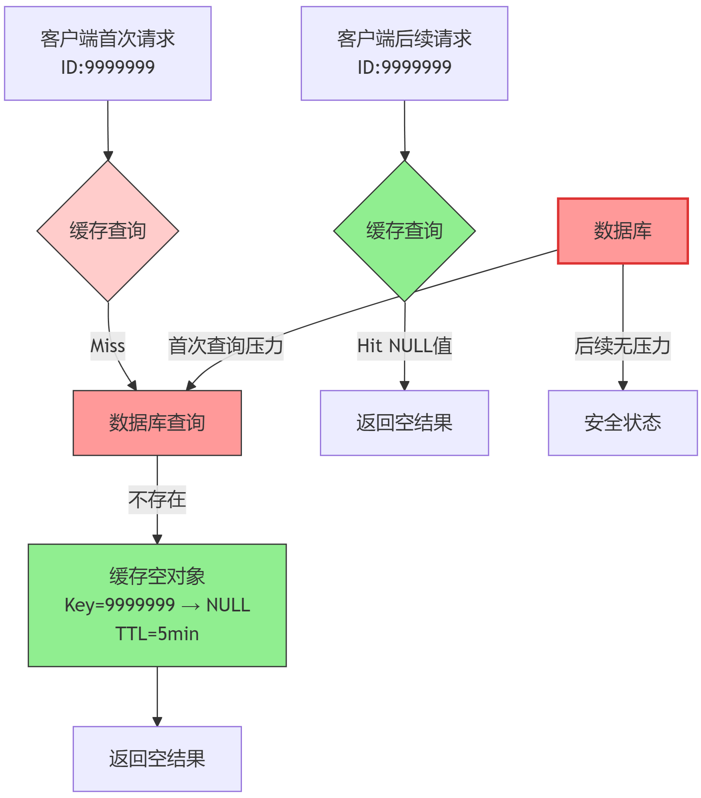
-
-
布隆过滤器 :
- 做法: 在缓存层之前,设置一个布隆过滤器。布隆过滤器是一个概率型数据结构,用于快速判断一个元素是否“绝对不存在”或“可能存在”于一个集合中。将所有可能存在的有效Key(如数据库中所有有效的商品ID)预先加载到布隆过滤器中。
- 流程:
- 请求到来,先查布隆过滤器。
- 如果布隆过滤器说 “不存在” -> 该Key肯定不存在 -> 直接返回空/错误,不查缓存和数据库。
- 如果布隆过滤器说 “可能存在” -> 该Key 可能 存在 -> 继续走正常的缓存查询流程(查缓存 -> 缓存Miss则查数据库 -> 回种缓存)。
- 优点:
- 内存占用极小(相比缓存空对象),能高效拦截大量无效Key的数据库查询。
- 非常适合防止缓存穿透攻击。
- 缺点:
- 存在误判率 (False Positive): 布隆过滤器判断“可能存在”时,实际数据可能不存在(但概率可控)。这意味着少量无效请求仍可能穿透到缓存层(但缓存层还有空对象或正常流程兜底)。
- 不支持删除操作(传统布隆过滤器)。删除Key需要重建过滤器或使用变种(如 Counting Bloom Filter)。
- 需要预热(初始化时加载有效Key集合)。
- 图解:
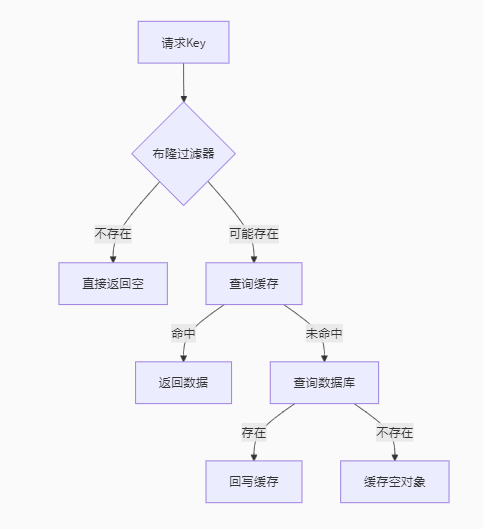
-
接口层校验:
- 做法: 在API网关或业务逻辑入口处,对请求参数进行强校验。例如,检查ID格式(必须是正整数)、范围限制、业务状态等。
- 优点: 简单直接,能过滤掉一部分明显不合法的请求。
- 缺点: 只能拦截格式明显错误的请求,对于符合格式但数据库不存在的无效请求无能为力。通常作为辅助手段。
-
二、缓存击穿
-
概念: 某个热点数据(访问量非常大) 在缓存过期失效的瞬间,同时有大量的请求进来。由于缓存刚好失效,这些请求全部穿透到数据库,瞬间给数据库造成巨大压力,甚至压垮数据库。
-
核心问题: 热点Key在失效瞬间的高并发访问。
-
危害:
- 数据库瞬间承受远超其处理能力的请求洪峰。
- 可能导致数据库连接池爆满、CPU/IO飙升、响应延迟激增,甚至宕机。
- 影响范围通常局限于该热点Key相关的业务。
-
图解说明:
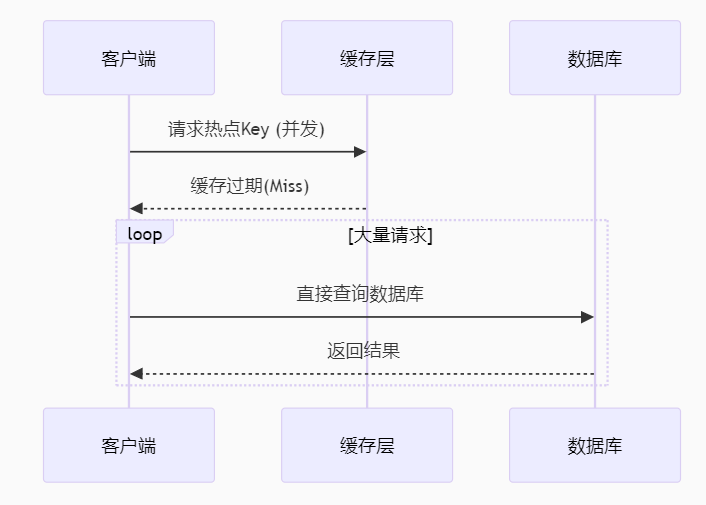
-
例子: 一个秒杀活动中,热门商品
product_id=1001的缓存设置过期时间为1小时。1小时后的瞬间,大量用户同时点击购买,此时缓存刚好过期,所有请求同时涌向数据库查询该商品库存信息。 -
解决方案:
-
互斥锁 (Mutex Lock / 分布式锁):
- 做法:
- 当第一个发现缓存失效的线程,尝试去获取一个与该Key关联的分布式锁(如使用 Redis 的
SETNX或 Redlock)。 - 如果获取锁成功:
- 该线程负责查询数据库。
- 将结果回种到缓存。
- 释放锁。
- 其他未能获取锁的线程:
- 等待一小段时间(例如自旋、sleep)。
- 然后重新尝试读取缓存(因为第一个线程可能已经回种好了)。
- 如果等待超时仍未获取到数据,可以返回错误、默认值或降级内容(需根据业务设计)。
- 当第一个发现缓存失效的线程,尝试去获取一个与该Key关联的分布式锁(如使用 Redis 的
- 优点: 能有效保证同一时间只有一个线程去查询数据库,防止数据库被击垮。
- 缺点:
- 实现相对复杂,需要引入分布式锁。
- 增加了系统复杂度。
- 如果获取锁的线程查询数据库或回种缓存失败或过慢,可能导致其他线程长时间等待(需设置合理的超时和重试)。
- 存在死锁风险(需谨慎处理锁的获取和释放)。
- 图解:
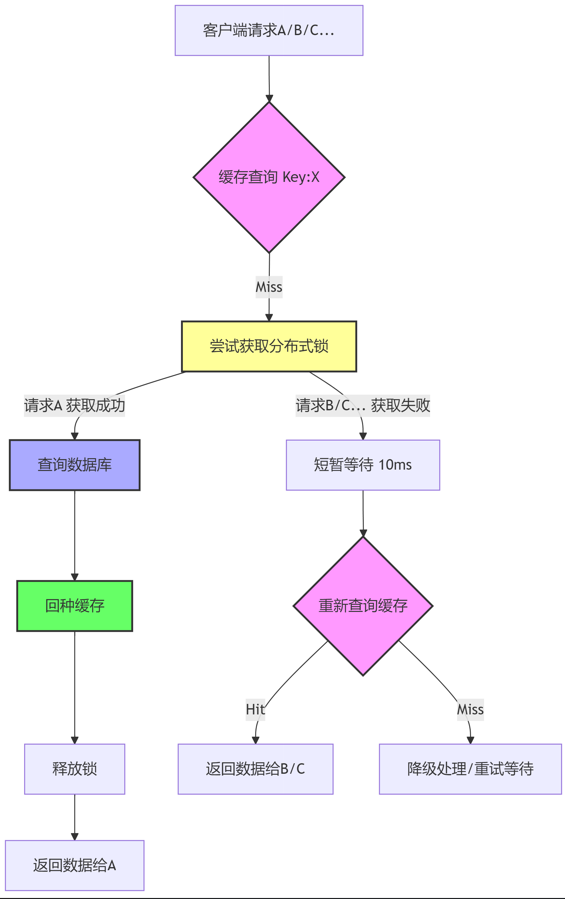
- 做法:
-
逻辑过期 (Logical Expiration):
-
做法:
- 不在缓存中设置物理TTL(过期时间)。
- 在缓存Value中额外存储一个逻辑过期时间字段。
- 当应用从缓存中读取数据时:
- 如果发现数据存在且逻辑未过期 (
current_time < expire_time),直接使用。 - 如果发现数据存在但逻辑已过期 (
current_time >= expire_time):- 尝试获取该Key的分布式锁。
- 获取锁成功的线程:异步(开启新线程/提交到线程池)去查询数据库更新缓存(同时更新数据和逻辑过期时间)。
- 获取锁失败的线程:直接返回已过期的旧数据(或根据业务降级)。
- 如果发现数据存在且逻辑未过期 (
-
优点:
- 用户请求几乎总能快速返回(即使数据逻辑过期,也先返回旧数据),体验好。
- 后台异步更新,对数据库的压力是平缓的。
-
缺点:
- 实现更复杂。
- 存在短暂的数据不一致(用户可能看到略微过期的数据)。
- 需要维护额外的逻辑过期字段。
-
图解:
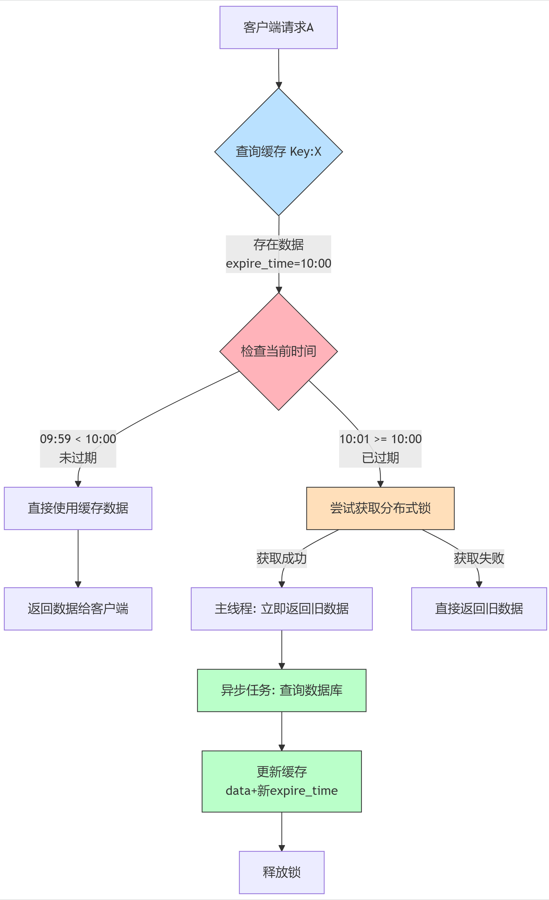
-
-
三、缓存雪崩
-
概念: 大量的缓存数据在同一时间段内集中过期失效,或者缓存服务(如Redis集群)整体宕机。导致原本应该访问缓存的请求,全部转向查询数据库,造成数据库瞬时压力巨大甚至崩溃。影响范围是整个系统或大部分数据。
-
核心问题: 大量Key同时失效 或 缓存服务不可用。
-
危害:
- 数据库瞬间承受海量查询,极易被压垮。
- 系统响应时间急剧增加,吞吐量骤降。
- 可能导致整个服务不可用,影响范围巨大。
-
例子:
- 场景1:系统初始化时批量加载了一批数据到缓存,并设置了相同的过期时间(如2小时)。2小时后,这批数据同时失效,导致所有相关查询瞬间涌向数据库。
- 场景2:Redis主节点故障,哨兵/集群正在选举新主节点或发生网络分区,导致整个缓存服务暂时不可用。所有请求直接访问数据库。
-
解决方案:
-
差异化过期时间:
- 做法: 为缓存数据设置过期时间时,在基础过期时间上增加一个随机值(如
基础过期时间 + 随机(0~5分钟))。 - 优点: 实现极其简单,成本最低,效果显著。将大量Key的失效时间打散,避免集中失效。
- 缺点: 不能解决缓存服务整体宕机的问题。极端情况下,如果随机范围不够大或Key数量极其庞大,仍可能有较多Key同时失效。
- 做法: 为缓存数据设置过期时间时,在基础过期时间上增加一个随机值(如
-
构建高可用缓存集群:
- 做法: 使用 Redis Sentinel(哨兵)或 Redis Cluster(集群)模式部署缓存服务,实现主从复制、自动故障转移。
- 优点: 解决单点故障问题,提高缓存服务整体的可用性。即使主节点宕机,也能快速切换到从节点继续提供服务。
- 缺点: 部署和维护复杂度增加。网络分区(脑裂)问题需要关注。
-
服务降级与熔断:
- 做法:
- 降级: 当检测到缓存服务不可用或数据库压力过大时,对于非核心业务或读请求,直接返回预定义的默认值(兜底数据)、错误页面或简化版数据。例如,商品详情页暂时不展示推荐列表、评论等次要信息。
- 熔断: 使用熔断器(如 Hystrix, Sentinel)监控数据库或下游服务的状态。当错误率或延迟超过阈值时,自动熔断(快速失败,直接走降级逻辑),给数据库恢复的时间。过一段时间后再尝试恢复。
- 优点: 牺牲部分非核心功能或数据一致性,保全核心服务和数据库不被压垮,保证系统整体可用性。
- 缺点: 用户体验可能受损(看到不完整数据或错误提示)。
- 做法:
-
提前预热与刷新:
- 做法: 对于已知即将到来的访问高峰(如大促活动)或已知即将大量失效的Key:
- 预热: 在高峰来临前,提前将热点数据加载到缓存中。
- 刷新: 在缓存过期前,通过后台任务主动刷新(延长有效期或更新数据)。
- 优点: 主动避免失效。
- 缺点: 需要预测热点和失效时间,对突发流量无效。
- 做法: 对于已知即将到来的访问高峰(如大促活动)或已知即将大量失效的Key:
-
多级缓存:
- 做法: 构建多级缓存体系。例如:
本地缓存 (如 Caffeine, Ehcache)->分布式缓存 (如 Redis)->数据库- 或者
CDN->网关缓存->应用本地缓存->分布式缓存->数据库
- 优点:
- 即使分布式缓存(Redis)崩溃,应用本地缓存还能扛住部分请求(特别是热点数据),为Redis恢复争取时间。
- 减少对分布式缓存的访问压力,提升性能。
- 缺点:
- 架构更复杂,数据一致性维护更困难(需要处理多级失效)。
- 本地缓存容量有限,且集群环境下更新同步麻烦。
- 图解:
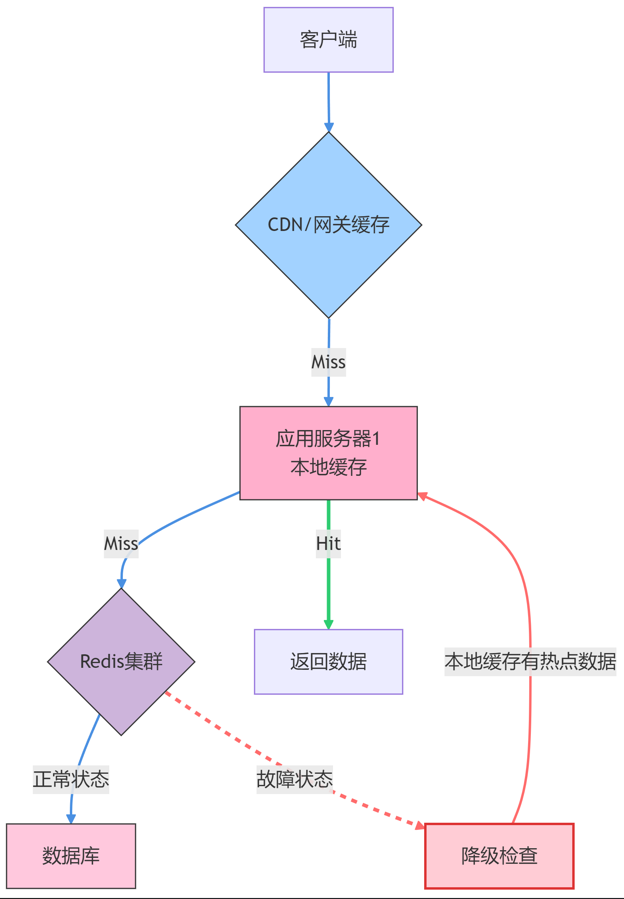
- 做法: 构建多级缓存体系。例如:
-
四、总结与对比
| 名称 | 缓存穿透 | 缓存击穿 | 缓存雪崩 |
|---|---|---|---|
| 核心问题 | 查询不存在的数据 | 单热点Key在失效瞬间高并发 | 大量Key同时失效 或 缓存服务宕机 |
| 触发条件 | 恶意请求、无效ID | 热点Key + 缓存过期 + 高并发 | 批量加载同TTL、缓存服务故障 |
| 影响范围 | 特定不存在的数据 | 单个热点Key | 大量数据 或 整个缓存服务 |
| 危害对象 | 数据库 (无效查询冲击) | 数据库 (热点查询冲击) | 数据库 (海量查询冲击) |
| 类比 | 拿着假通行证硬闯检查站 | 明星出场,通道瞬间挤爆 | 检查站系统瘫痪或大量通行证同时到期 |
| 关键方案 | 布隆过滤器、缓存空对象、参数校验 | 互斥锁、逻辑过期 | 差异化TTL、高可用集群、降级熔断、多级缓存 |

















 345
345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









