






尽可能利用第三方平台去收集目标服务器的信息(保护自己的信息)
1.概述
渗透测试的本质就是信息收集,信息搜集的广度决定了攻击的广度,知识面的广度决定了攻击的深度。
信息收集很重要,如确定资产,比如他有哪些域名、子域名、C 段、旁站、系统、微信小程序或者公众号,确定好站点或者目标系统之后,就是常规的指纹识别,像中间件、网站,扫目录,后台,确定功能然后分析每个功能点上会有哪些漏洞,就比如一个登录页面,我们可以考虑的是爆破账号密码,社工账号密码,SQL 注入,XSS 漏洞,逻辑漏洞绕过等。
在短时间内你无法去提升你的技术或者是挖掘一个新的思路,这个时候就体现了资产搜集的能力,信息搜集是最难的,也是最麻烦耽误时间的,且必须要实时去关注的一件事情。
红队最最最关键的就是要做好信息收集,信息收集的前提是确定目标,通常来讲,HW期间,目标可能存在金融,政府,学校,企业,公安等各类行业目标,通过首选企业去打,相对来讲企业是比较好打的,政府,金融等安全防护做的相对来说较好,安全设备较多,所以首选企业,其次学校,其次是政府单位等。
2.信息收集的种类
信息收集分为被动收集和主动收集两种方式。
- 被动信息收集:利用第三方的服务对目标进行访问:Google搜索、Shodan搜索、其他综合工具,被动信息收集是指京可能多低收集与目标相关的信息
- 主动信息收集:通过直接扫描目标主机或者网站,主动方式能获取更多的信息,目标系统可能会记录操作信息。
在信息收集中,需要收集的信息:目标主机的DNS信息、目标IP地址、子域名、旁站和C段、CMS类型、敏感目录、端口信息、操作系统版本、网站架构、漏洞信息、服务器与中间件信息、邮箱、人员、地址等。
在信息收集中,首先可以先进行被动收集,确定网络范围内目标,与目标相关的人员的邮箱,地址等信息,然后在选择出重点渗透的目标,在针对性的进行主动信息收集。

3.一些常用的网站
ICP 备案查询:https://icp.aizhan.com
权重查询:https://rank.aizhan.com/www.wondercv.com/
多地 ping:https://www.ping.cn/d
whois 查询:https://www.whois365.com/cn/ip/119.23.74.200
IP 反查:https://www.ip138.com/iplookup.asp?ip=166.111.53.94&action=2
以 xxx 公司为例,根域名:xxx.cn
信息收集可以从多个领域来看:公司,子公司,域名,子域名,IPV4,IPV6,小程序,APP,PC 软件等等
可以重点关注备案网站,APP,小程序,微信公众号,甚至是微博。
这里说一点小思路,首先可以找到官网,用 cmd ping 他的官网,可以看到 IP 地址,然后可以定位whois,whois 中包含了用户、邮箱,以及购买的网段。
有了网段就可以进行一些主动信息收集,可以使用一些强大的资产测绘工具,goby 的资产测绘还是很不错的,会有一些 web 服务,不用担心没有 banner,往往这些没有 banner 的才有问题。
注意观察一下网站底部是否有技术支持:xxxx | 网站建设:xxxx 之类的标注,一些建站企业会出于知识产权保护或者是对外宣传自己的公司,会在自家搭建的网站上挂上技术支持等之类的标注,很多建站企业往往某种类型的网站都是套用的同一套源码,换汤不换药。
4.CDN(*)
CDN的全称是(Content Delivery Network),即内容分发网络。其目的是通过在现有的Internet中增加一层新的CACHE(缓存)层,将网站的内容发布到最接近用户的网络”边缘“的节点,使用户可以就近取得所需的内容,提高用户访问网站的响应速度
在线CDN检测平台:https://www.boce.com/ping

5.端口及服务
在线平台:
工具:nmap
Nmap用于快速扫描一个网络和一台主机开放的端口,使用TCP/IP协议栈特征探测目标主机的操作系统版本。安装链接:https://nmap.org/download.html

6.收集工具和平台
6.1站长工具

6.2Maltego
Maltego是一款综合信息收集工具,可以帮助获取和可视化情报收集。Maltego在Kali linux中自带。Maltego使用之前需要进行注册,注册之后可以使用社区版免费版。也可参考官方指导文档。
在Kali linux打开Maltego之后,利用之前注册的账户进行登录,然后就可以使用Maltego进行信息收集。
7.搜索引擎
7.1google
可以通过Google的语法规则,利用Google进行搜索,进行针对性的敏感信息搜集。
常用的语法参数如下:

示例:
Google hack实战-搜索敏感文件
filetype:txt 登录
site:xxx.com filetype:doc intext:pass
site:xxx.com filetype:conf
filetype:log iserror.log
Google hack实战-搜索登陆后台
intitle:后台管理
intitle:login
intitle: 后台管理 inurl:admin
intitle:index of /
site:example.com filetype:txt 登录
site:example.com intitle: 后台管理
site:example.com admin
site:example.com login
site:example.com system
site:example.com 管理
site:example.com 登录
site:example.com 内部
site:example.com 系统
site:xxx.com admin
site:xxx.com login
site:xxx.com 管理
site:example.com system
site:example.com 登录
site:example.com 内部
site:example.com 系统
site:example.com filetype:txt 登录
site:example.com intitle:后台管理
inurl:login|admin|manage|member|admin_login|login_admin|system|login|user|main|cms
site:example.com intext:管理|后台|登录|用户名|密码|验证码|系统|账号|admin|login|sys|management|password|username
7.2shodan
Shodan是一个搜索引擎,允许用户使用各种过滤器查找连接到互联网的特定类型的计算机(网络摄像头,路由器,服务器等),官方网址:https://www.shodan.io/ 。例如搜索“product:“SSH””,能够得到相对应的IP地址,主机名,ISP(组织),对应的国家,Banner信息等信息。

7.3fofa
FOFA 作为一个搜索引擎,我们要熟悉它的查询语法,类似 google 语法,FOFA 的语法主要分为检索字段以及运算符,所有的查询语句都是由这两种元素组成的。目前支持的检索字段包括:domain,host,ip,title,server,header,body,port,cert,country,city,os,appserver,middleware,language,tags,user_tag 等等,等等,支持的逻辑运算符包括:=,==,!=,&&,||。
如果搜索 title 字段中存在后台的网站,只需要在输入栏中输入 title=“后台”,输出的结果即为全网 title 中存在后台两个字的网站,可以利用得到的信息继续进行渗透攻击,对于网站的后台进行密码暴力破解,密码找回等等攻击行为,这样就可以轻松愉快的开始一次简单渗透攻击之旅,而企业用户也可以利用得到的信息进行内部的弱口令排查等等,防范于未然。
- 搜索 QQ 所有的子域名:domain=“qq.com”
- 搜索 host 内所有带有 qq.com 的域名:host=“qq.com”
- 搜索某个 IP 上的相关信息:ip=“58.63.236.248”
- 搜索全球的 Apache:server=“Apache”
- 搜索非常火的海康威视:header=“Hikvsion”
- 假如搜索微博的后台,域名为:weibo.com 并且网页内 body 包含 “后台”:body=“后台”&& domain=“weibo.com”
常用语法:
- host=".xxx.edu.cn" && status_code="200"
- icon_hash="1574010831"
- (body="大学" || body="学院") && tittle="OA"
- host=".edu.cn" && title="OA"
- host=".edu.cn" && port=7001
- region="Jilin" && title="用友nc"
- server=weblogic && port=7001
- title="目标名称" && region=“xx省”
- cert=“目标域名或者证书关键字” && region=“xx省”
- ((title="目标名称" || host="目标域名")&&country="CN")&®ion!="HK"
7.4钟馗之眼

8.子域名
首推OneForAll,Layer 子域名挖掘机
如果提前知道目标,还可以提前收集一波子域,然后项目快开始的时候,再收集一波子域,将两次收集的结果做下对比,优先打新增子域。
尽量多凑一点 API,fofa 可以找人借一些 api,越多越好。
8.1在线子域名查询
在线平台
在线工具
8.2工具: ksubdomain

8.3工具: OneForAll

8.4工具:layer

执行命令: 常用的获取子域名有 2 种选择,一种使用 --target 指定单个域名,一种使用 --targets 指定域名文件。
- python3 oneforall.py --target example.com run
- python3 oneforall.py --targets ./domains.txt run
- python3 oneforall.py --target xxx.cn run
9.后台目录收集
扫描网站的目录结构,收集铭感信息,利于对目标网站的渗透,部分敏感信息如下表:

9.1御剑后台扫描
9.2 7kbstorm
使用方法:在扫描目录输入目标域名,点击开始即可。

9.3 Dirsearch
dirsearch 是一款用于目录扫描的开源工具,旨在帮助渗透测试人员和安全研究人员发现目标网站上的隐藏目录和文件。与 dirb 类似,它使用字典文件中的单词构建 URL 路径,然后发送 HTTP 请求来检查这些路径是否存在。
特点:
多线程扫描: dirsearch 支持多线程扫描,提高目录扫描的效率。
灵活的配置: 用户可以通过配置文件自定义扫描的参数,包括使用代理、设置 User-Agent 等。
自定义报告: 支持生成自定义格式的报告,以便更好地整理和分享扫描结果。
支持多种扫描方式: 除了常规目录扫描,还支持文件扫描、扩展名扫描等多种扫描方式。
常用命令:
注:若不指定自定则使用软件默认的字典
//默认方式扫描单个url
python3 dirsearch.py -u https://target
//使用文件拓展名为php和txt以及js的字典扫描目标
python3 dirsearch.py -e php,txt,js -u https://target
//采用指定路径的wordlist且拓展名为php,txt,js的字典扫描目标url
python3 dirsearch.py -e php,txt,js -u https://target -w /path/to/wordlist
//采用递归扫描
python3 dirsearch.py -e php,txt,js -u https://target -r
//采用递归扫描递归层数为三层
python3 dirsearch.py -e php,txt,js -u https://target -r -R 3
python dirsearch.py -u http://xxxx -r -t 30 --proxy 127.0.0.1:8080 //使用代理
python dirsearch.py -l D:\dirsearch-master\url\url.txt -w D:\dirsearch-master\db\01-Spring.txt -i 200 使用指定字典扫描批量url的目录,保留状态码200
默认的字典位置:
9.4 Dirb
dirb是一个基于字典的web目录扫描工具,采用递归的方式来获取更多的目录,可以查找到已知的和隐藏的目录,它还支持代理和http认证限制访问的网站在渗透测试过程中,是一个非常好用的工具。
格式:
dirb <url_base> [<wordlist_file(s)>] [options]
-a 设置user-agent
-p <proxy[:port]>设置代理
-c 设置cookie
-z 添加毫秒延迟,避免洪水攻击
-o 输出结果
-X 在每个字典的后面添加一个后缀
-H 添加请求头
-i 不区分大小写搜索
1.使用/usr/share/wordlists/dirb/big.txt 字典来扫描Web服务
dirb 百度一下,你就知道 /usr/share/wordlists/dirb/big.txt
2.将扫描结果保存到文件中
dirb https://www.baidu.com/ -o output.txt /usr/share/wordlists/dirb/big.txt
3.列举指定后缀名目录
dirb https://www.baidu.com -X .php /usr/share/wordlists/dirb/big.txt
10.网站结构
针对网站的架构,主要收集:服务器操作系统、网站服务组件和和脚本类型、CMS类型、WAF等信息。
10.1服务器类型
服务器类型包括常用的操作系统:Linux还是Windows,使用nmap能够辨别。
指令: nmap -A -T4 -v IP地址

10.2网站服务组件和脚本类型
网站服务组件和脚本而理性可以利用linux的网站指纹识别工具:
whatweb和浏览器插件Wappalyzer Whatweb

Wappalyzer 一款Chrome浏览器的插件,可以查询网站是用什么技术进行编写的。 插件可以自行到Chrome扩展商店进行下载
10.3CMS识别(*)
CMS可以说指的是网站的源码,如果能识别出一个网站使用的哪一种CMS的话,那么可以通过搜索引擎去发现相应的漏洞,若网站管理员没有处理的话,则可以直接突破站点。
CMS是一个内容管理系统,允许用户将内容直接发布到Web的接口 主流的cms有drupal,joomla,wordpress,dedecms判断出目标网站CMS,可以根据对应的CMS类型的漏洞进行攻击。目标网站的CMS识别和CMS安全检测,可以利用onlinetools工具分析。
网站:
Whatweb:http://www.whatweb.net
潮汐指纹:http://finger.tidesec.com/
微步社区:https://x.threatbook.com/
工具:Ehole
使用方法:
- ./Ehole-darwin -l url.txt//URL 地址需带上协议,每行一个
- ./Ehole-darwin -f 192.168.1.1/24 // 支持单 IP 或 IP 段,fofa 识别需要配置 fofa 密钥和邮箱
- ./Ehole-darwin -l url.txt -json export.json// 结果输出至 export.json 文件
10.4防火墙识别
WAF(防火墙)是WEB应用的保护措施。目标网站的防火墙信息可以使用nmap和WAFW00F获取。
在线工具:第一影院-好看的高清电影_全网热播VIP电视剧大全免费
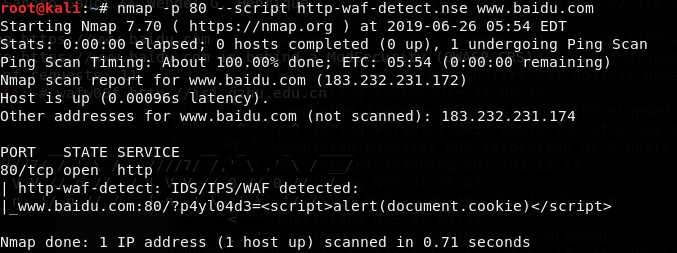
nmap 指令:nmap -p 80–script http-waf-detect.nse 域名
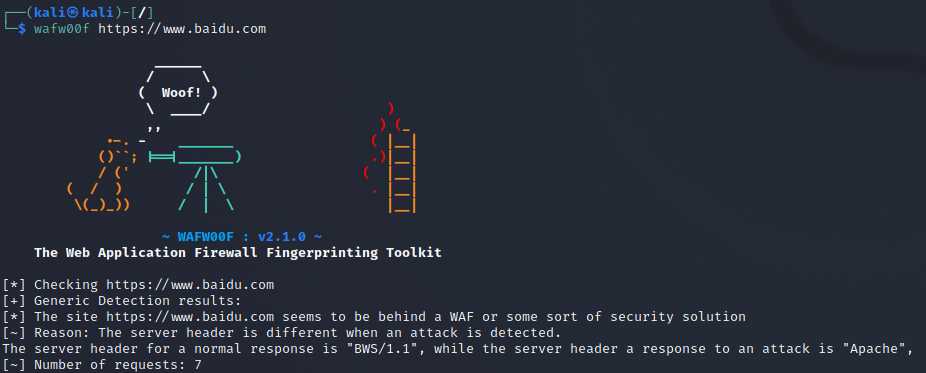
WAFW00F
WAFW00F是linux一款探测目标防火墙信息的工具。
指令:waf00f 域名。
11.旁站和C段
11.1旁站
和目标网站在同一台服务器上的其它的网站。 使用同一个 IP 地址
在目标网站无法攻击成功时,若他的旁站可以成功攻击并获取相应的系统权限,这势必会影响到目标网站的安全性,因为已经获取到同一台服务器的权限了。
在线网站:
11.2 C段
和目标服务器IP地址处在同一个C段的其它服务器。
可以利用onlinetools工具和在线网站http://www.webscan.cc获取。
onlinetools:
这是一款线上工具箱,收集整理了一些渗透测试过程中常见的需求。
现在已经包含的功能有:在线cms识别|信息泄露|工控|系统|物联网安全|cms漏洞扫描|nmap端口扫描|子域名获取
部署方法:
git clone https://github.com/iceyhexman/onlinetools.git
cd onlinetools
pip3 install -r requirements.txt
nohup python3 main.py &Docker 部署:
git clone https://github.com/iceyhexman/onlinetools.git
cd onlinetools
docker build -t onlinetools .
docker run -d -p 8000:8000 onlinetools
#浏览器打开:http://localhost:8000/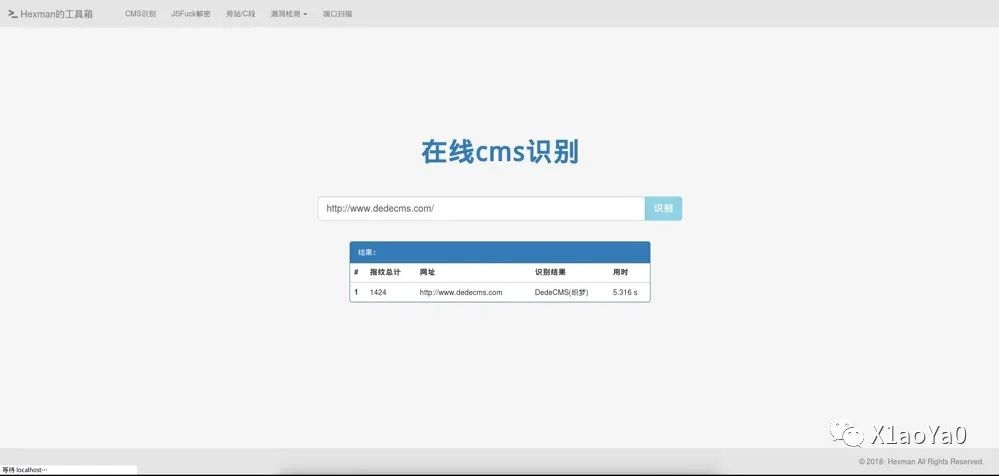
12. 公众号服务号收集
搜狗搜索引擎
13. 设备信息收集
如果拿到一个防火墙或者路由器设备,而且能配置vpn的这种,那就相当于拿到了内网的钥匙,只需要能够访问到内网,就算内网穿透,所以在hvv开始前,就会有很多队伍收集这些设备,而且如果是弱口令就会直接修改密码。
如果能拿到有些政府单位的vpn,那就更舒服了,因为大概率就可以进到政务外环网,这个网是外网ip,但是外网是访问不到的,是政务内网和外网之间的一层网络,这里面的好东西也是不少,不过,最近几年打的多了,里面的资产也是防护越来越厉害了。
所以需要去收集一些设备的语法,例如:
app="HUAWEI-Home-Gateway-HG659"
title="Web user login"
app="Ruijie-EG易网关"对于这些设备的账号密码可以直接百度,也可以直接在这个网站上搜设备名,大部分都有。
14. 社会工程学
社会工程学(Social Engineering) 是一种通过人际交流的方式获得信息的非技术渗透手段。不幸的是,这种手段非常有效,而且应用效率极高。事实上,社会工程学已是企业安全最大的威胁之一。狭义与广义社会工程学最明显的区别就是是否会与受害者产生交互行为。广义是有针对性的去对某一单一或多一目标进行攻击的行为。
常见社工:
社工三大法宝:网络钓鱼、电话钓鱼、伪装模拟
狭义三大法宝:谷歌、社工库、QQ
社工师的分类:黑客、渗透测试、JD、GOV、公司内部员工、欺骗人员、猎头、销售人员、普通人。
信息泄露方式:
在网上注册时,垃圾网站被黑客攻入(服务器或者数据库被攻击),黑客获取信息
网站内部人员将信息贩卖,然后获取信息
通讯被窃听,http协议用post或者get提交时,使用火狐进行拦截
撞库,比如你在这个A网站注册时,使用了一个密码,在B网站也使用这个密码,知道A网站的密码,自己也可以用这个密码登录B网站,这就是撞库
社会工程学攻击四个阶段:
研究:信息收集(WEB、媒体、垃圾桶、物理),确定并研究目标
钩子:与目标建立第一次交谈(HOOK、下套)
下手:与目标建立信任并获取信息
退场:不引起目标怀疑的离开攻击现场
常见信息:
真实姓名、性别、出生日期、身份证号、身份证家庭住址、身份证所在公安局、快递收货地址、大致活动范围、QQ号、手机号、邮箱、银行卡号(银行开户行)、共同朋友的资料、支付宝、贴吧、百度、微博、猎聘、58、同城、网盘、微信、常用ID、学历(小/初/高/大学/履历)、目标性格详细分析、常用密码、照片EXIF信息。
常见可获取信息系统:
中航信系统、春秋航空系统、12306系统、三大运营商网站、全国人口基本信息资源库、全国机动车/驾驶人信息资源库、各大快递系统(越权)、全国出入境人员资源库、企业相关系统、信息资源库等。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









