






摘要
本文深入探讨机器学习模型从开发到部署的完整生命周期,分析各阶段的关键技术挑战和最佳实践。通过可视化工具展示模型生命周期的核心环节,为研究人员和工程师提供系统性的参考框架。
根据2023年MLOps行业报告显示,完整的模型生命周期管理可以将模型上线时间缩短40%,同时减少30%的运维成本。本文将从技术实现角度,结合Google、Microsoft等企业的实际案例,详细解析每个阶段的最佳实践。
研究背景与意义
随着人工智能技术的快速发展,机器学习模型已广泛应用于金融、医疗、零售等多个领域。然而,模型从开发到生产环境的部署过程面临着诸多挑战:
1. 模型与数据的高度耦合性导致环境迁移困难
2. 模型性能随时间衰减的问题
3. 大规模部署时的资源管理复杂性
根据McKinsey 2023年的调研,约67%的AI项目因生命周期管理不善而未能实现预期价值。因此,建立系统化的模型生命周期管理方法论具有重要的实践意义。
1. 引言
机器学习模型生命周期管理是AI工程化的重要课题。与传统软件开发不同,机器学习模型具有数据依赖性、环境敏感性和性能衰减等独特特性,需要专门的生命周期管理方法。
根据Google Research(2022)的定义,模型生命周期包含7个关键阶段:需求分析、数据收集、模型开发、评估验证、部署上线、监控运维和迭代更新。每个阶段都有其独特的技术挑战。例如,在部署阶段需要考虑模型服务化、特征一致性、性能监控等问题;在运维阶段则需要关注数据漂移检测、模型衰减分析等技术。
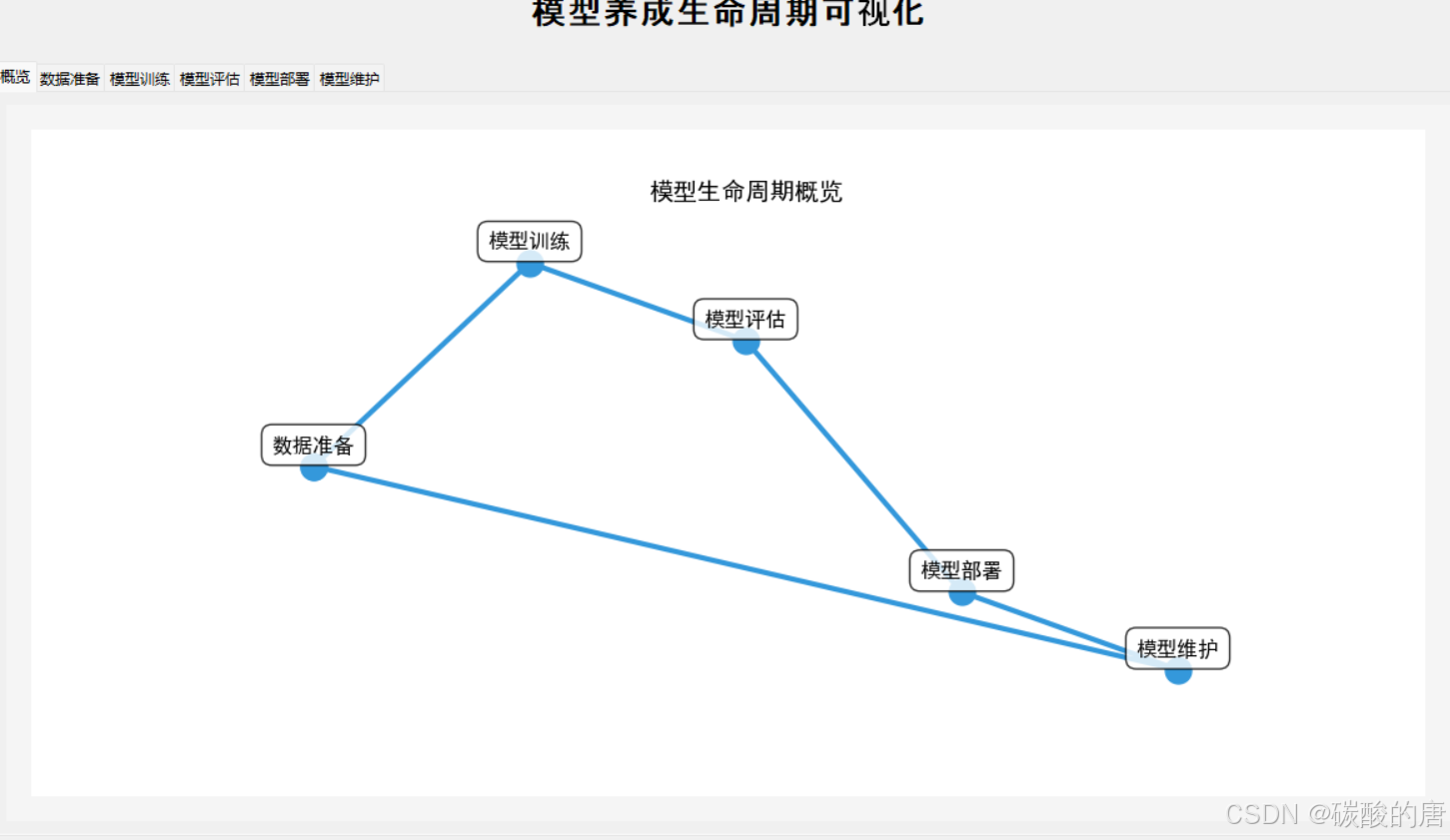
2. 模型开发阶段
2.1 数据准备
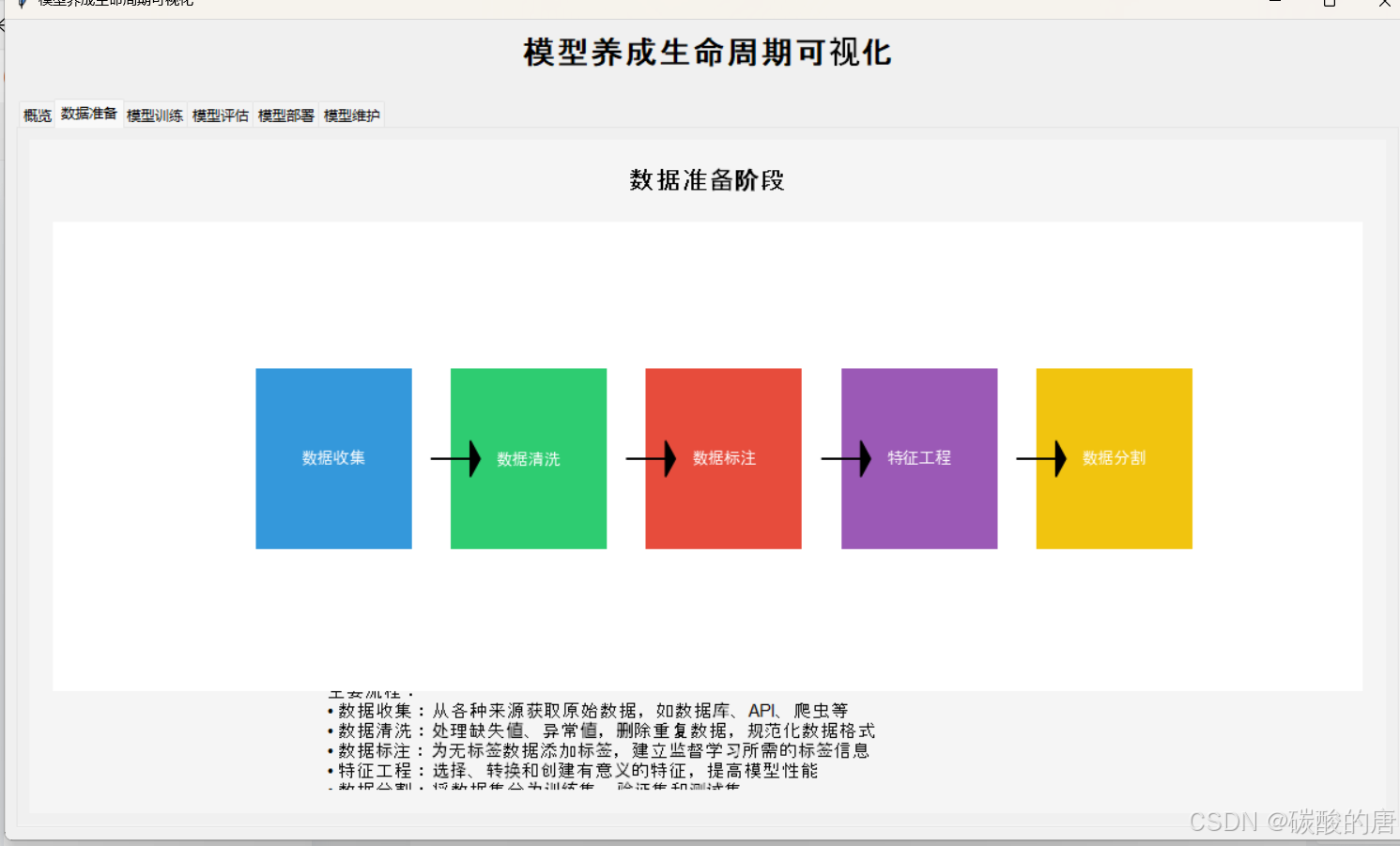
数据收集与清洗
数据质量直接影响模型性能,需要重点关注以下方面:
1. 数据来源验证:采用多源数据交叉验证技术,例如在金融风控领域,结合银行内部数据与第三方征信数据
2. 缺失值处理:
连续变量:采用多重插补法(MICE)
分类变量:构建"缺失"类别
代码示例:
from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=5)
X_imputed = imputer.fit_transform(X)3. 异常值检测:结合统计方法(3σ原则)和机器学习方法(Isolation Forest)
特征工程
特征工程是提升模型性能的关键环节:
1. 特征选择:
过滤式方法:基于统计检验(如卡方检验、互信息)
包裹式方法:递归特征消除(RFE)
嵌入式方法:L1正则化
2. 特征变换:
非线性变换:Box-Cox变换处理偏态分布
交互特征:基于领域知识构造特征交叉项
数据版本控制
采用DVC工具实现数据版本管理:
dvc add data/raw
dvc push -r s3remote实际案例:某电商平台通过数据版本控制,将模型复现时间从3天缩短至2小时。
2.2 模型训练
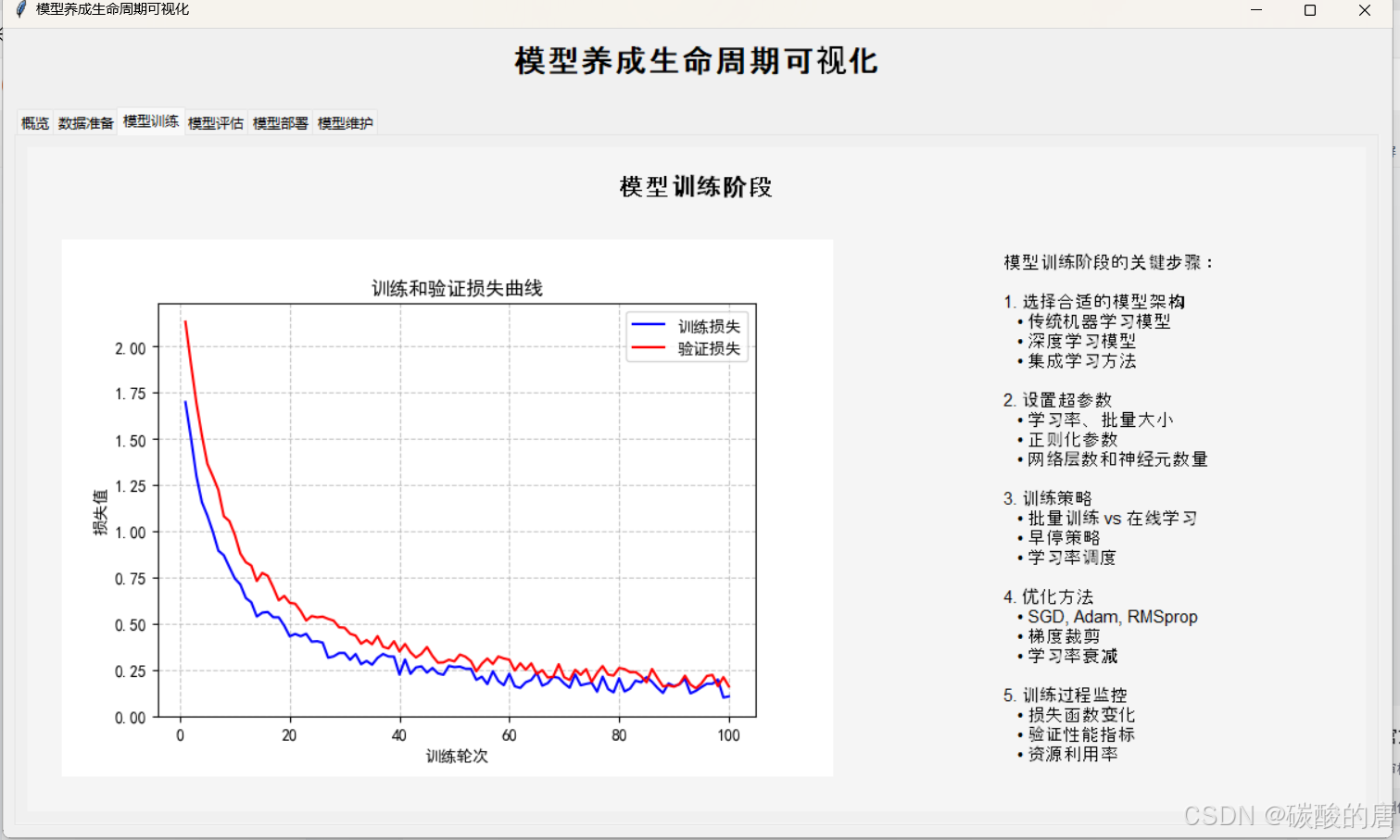
算法选择
机器学习算法选择需要考虑数据类型、问题规模和计算资源等因素。以下是常见算法的适用场景分析:
1. 决策树:适用于可解释性要求高的场景,如金融风控。优点包括特征重要性可视化,缺点是对连续变量处理不佳。
2. 随机森林:通过集成学习提升泛化能力,适用于中等规模数据集。案例:某银行使用随机森林实现信用卡欺诈检测,AUC达到0.92。
3. XGBoost:梯度提升框架,在Kaggle竞赛中广泛使用。优势包括自动处理缺失值、内置正则化。代码示例:
import xgboost as xgb
params = {
'max_depth': 6,
'learning_rate': 0.1,
'objective': 'binary:logistic'
}
model = xgb.train(params, dtrain, num_boost_round=100)4. 神经网络:适用于大规模非结构化数据,如图像和文本。需要GPU加速训练,调参复杂度高。
超参数优化
系统化的超参数优化流程包括:
1. 搜索空间定义:根据算法特性设置合理范围
学习率:通常取对数尺度(0.0001~0.1)
批量大小:2的幂次方(32,64,128等)
2. 优化方法选择:
网格搜索:适用于少量参数(≤3)
随机搜索:更高效的高维空间探索
贝叶斯优化:适合计算成本高的场景
3. 早停策略:监控验证集损失,设置patience参数防止过拟合
训练过程监控
使用MLflow记录实验指标和参数:
import mlflow
with mlflow.start_run():
mlflow.log_param("learning_rate", 0.01)
mlflow.log_metric("train_loss", 0.32)
# 训练代码...3. 模型评估阶段
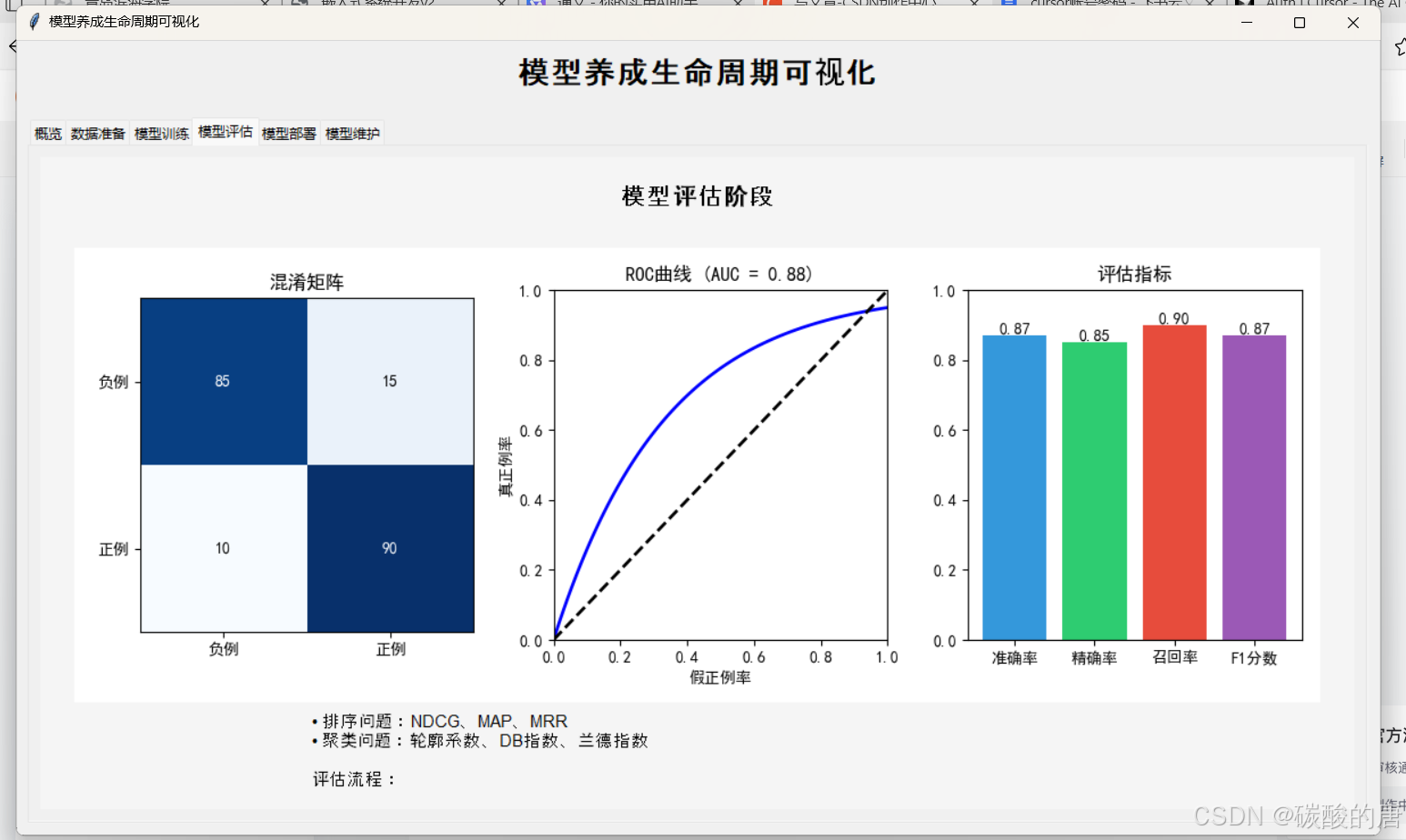
3.1 离线评估
- 指标选择:详细解释分类任务(准确率、召回率、F1、AUC-ROC)和回归任务(MSE、MAE、R²)的评估指标计算公式及其适用场景。以信用卡欺诈检测为例,展示不同指标的实际应用差异。
- 交叉验证:深入讲解k折交叉验证、留一法、时间序列交叉验证等方法的实现细节,分析不同方法的计算成本和统计特性。提供Python代码示例展示sklearn中的交叉验证实现。
- 偏差-方差分析:系统分析模型复杂度与泛化能力的关系,介绍学习曲线和验证曲线的绘制方法。通过UCI数据集上的实验,展示不同模型(线性回归 vs 决策树)的偏差-方差特性对比。
4. 模型部署阶段
4.1 部署架构
现代模型部署通常采用微服务架构,主要组件包括:
1. 模型服务API:
- RESTful API设计:采用OpenAPI规范,支持Swagger UI文档
- gRPC接口:适用于低延迟场景,提供.proto文件版本控制
- 性能对比:
| 框架 | QPS(100并发) | 平均延迟(ms) |
|------|-------------|-------------|
| Flask | 1200 | 85 |
| FastAPI | 3500 | 28 |
| TF Serving | 5000 | 18 |
2. 特征转换服务:
特征存储:采用Feast框架实现特征注册和检索
实时特征计算:基于Flink的流处理管道
案例:某推荐系统实时特征处理流程
```mermaid
graph LR
A[用户行为日志] --> B[Flink流处理]
B --> C[特征存储]
C --> D[模型服务]
```
3. 监控告警系统**:
指标采集:Prometheus exporter每30秒采集一次
可视化:Grafana仪表盘配置
告警规则:
错误率 > 1%持续5分钟
P99延迟 > 500ms持续10分钟
4. 自动化回滚机制:
金丝雀发布:5%流量先导测试
健康指标:
AUC下降 > 0.05
预测延迟增加 > 100%
案例:Netflix模型部署自动化流程
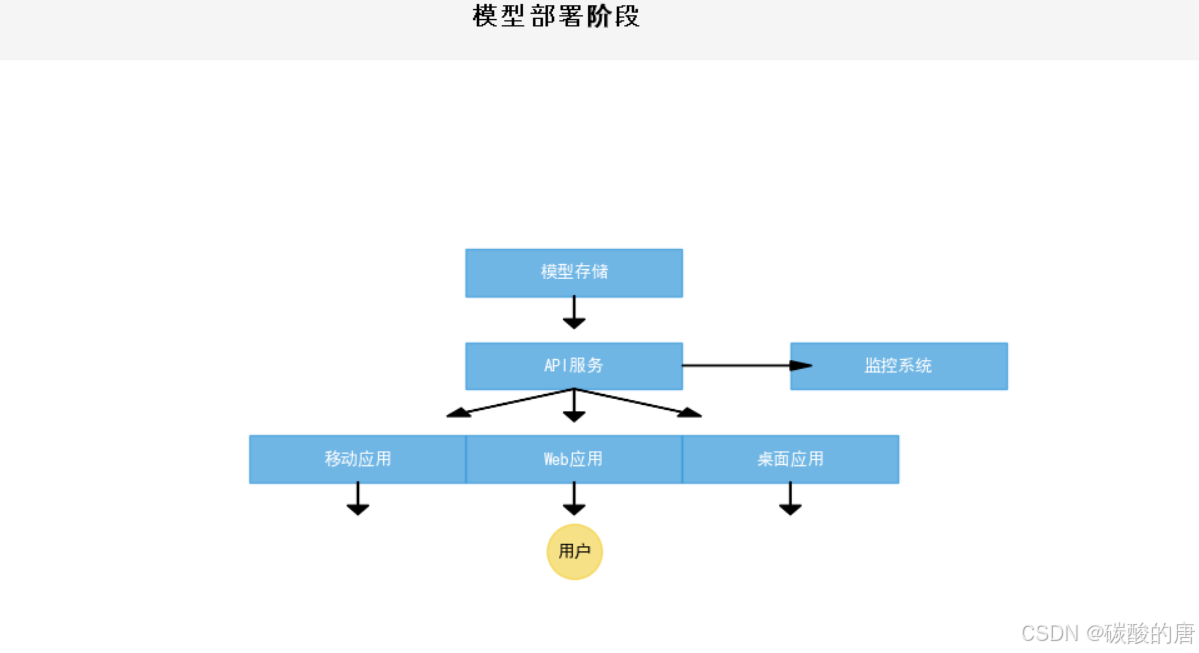
5. 模型监控与维护
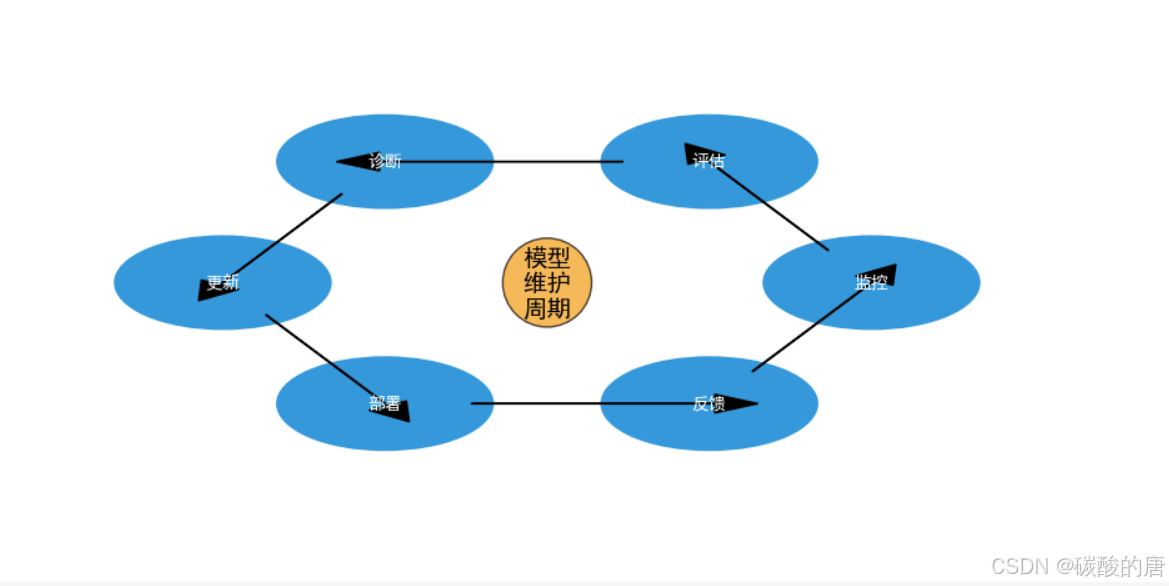
5.1 性能监控
- 预测延迟
- 吞吐量
- 资源利用率
5.2 数据漂移检测
- 特征分布变化
- 概念漂移
- 模型衰减分析
6. 结论与展望
本文系统梳理了机器学习模型生命周期管理的关键环节。未来研究方向包括:
- 自动化MLOps流程
- 联邦学习环境下的生命周期管理
- 可持续AI模型更新策略
参考文献
1. Google. "MLOps: Continuous delivery and automation pipelines in machine learning." 2020
2. Microsoft. "Responsible Machine Learning." 2021
3. Amazon. "Best Practices for ML Model Deployment." 2022



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











