







目录
编译到可执行程序
编译的整体过程分为四步:开始是C语言代码(以C语言为例),结果是exe文件(可执行程序);
第一步:预处理,将源代码中的头文件,宏替换为库中的代码,并取消注释;
第二步:编译,将C语言代码处理为汇编语言;
第三步:汇编,将汇编代码进一步处理为机器识别的代码(二进制指令,我们看起来就是乱码),名为可重定向文件;
第四步:链接,生成可执行程序;
1.预处理(.c文件->.i文件)
目的:将头文件和宏进行替换,取消注释;
文件从code.c->code.i 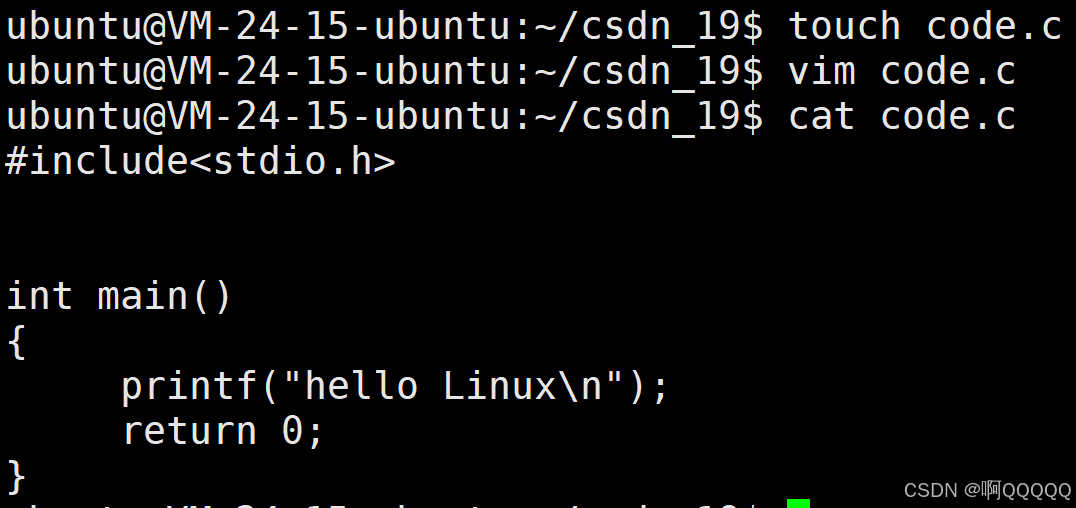
现在我使用指令对.c文件进行预处理,我们来看看预处理后的代码;
gcc -E code.c -o code.i 可以看到头文件的确被库<stdio.h>中的代码替换了;而其他的代码保持不变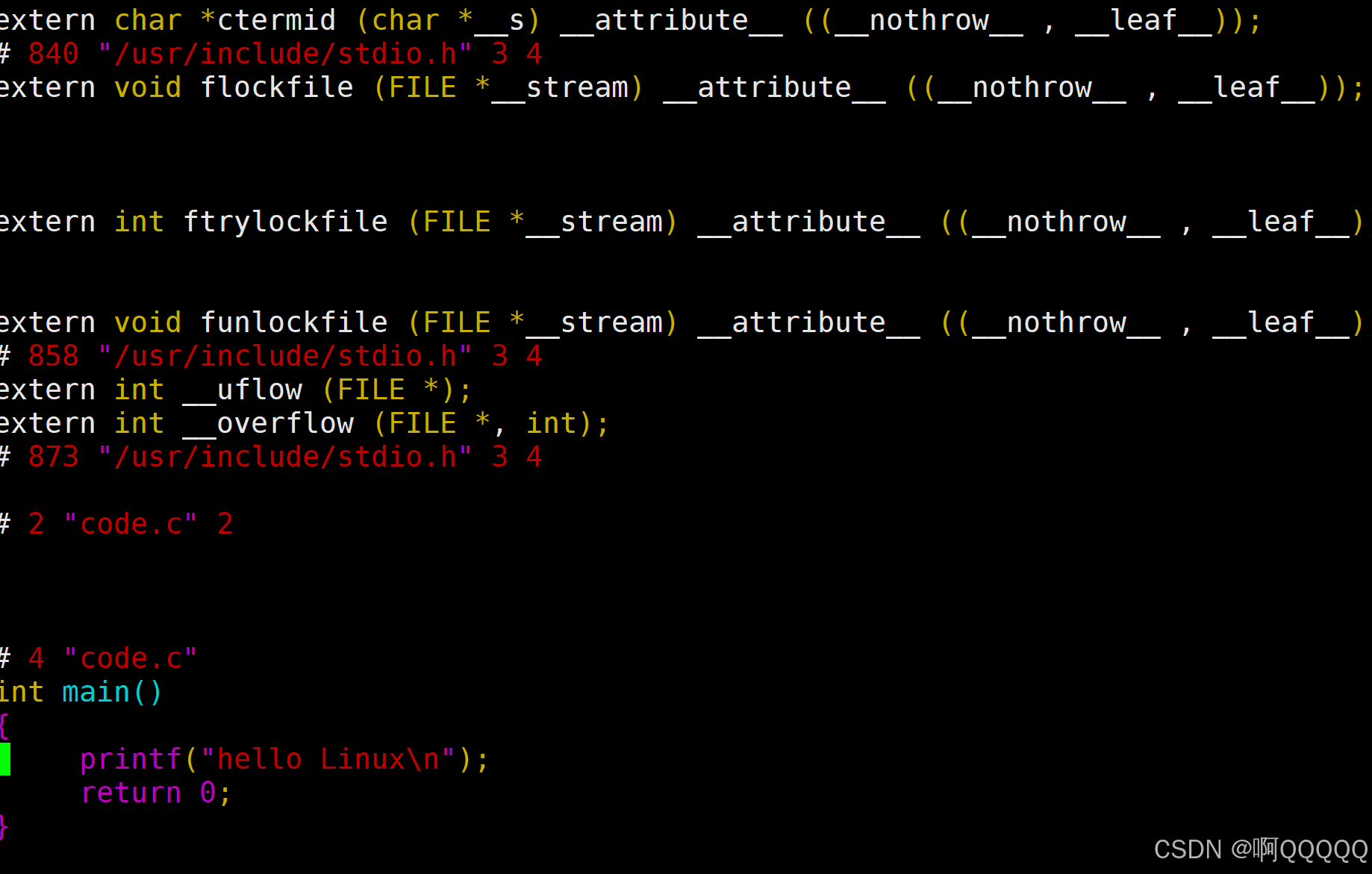
注意:替换后的代码仍然是C语言代码,变的更加的干净了(没有注释);
2.编译(.i文件->.s文件)
目的:将C语言代码处理为汇编代码;
这次我们直接使用预处理过的文件进行下一步的汇编:
gcc -S code.i -o code.s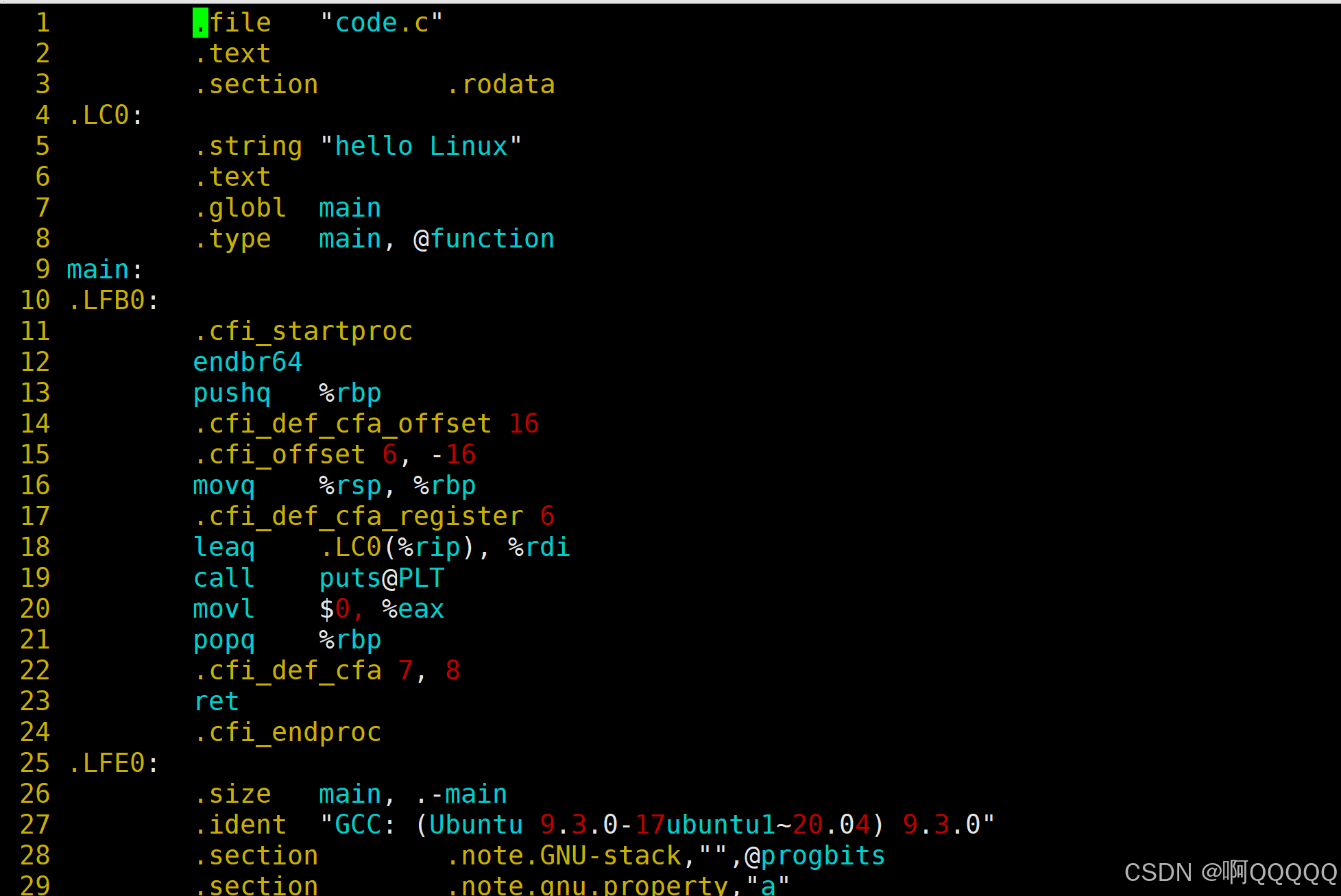
我们发现这次处理后的代码,就已经是我们看不懂的了,这就是已经从C代码转换为了汇编代码;
3.汇编(.s文件->.o文件)
目的:进一步处理汇编代码,形成机器可识别代码(可重定向目标文件)
这次我们使用上一次的code.s文件继续编译,是会报错的;所以我们这次使用code.c来进行处理;
gcc -c code.c -o code.o
这次的代码和上次的有变化,但是还是看不懂,我们记住是从汇编代码处理为了机器可识别代码,变成了可重定向目标文件;
4.链接(.o文件->exe文件)
目的:产生可执行文件
这次使用.o文件链接为exe文件;
gcc code.o -o code
E,S,c选项
上述的四个过程,gcc 依次使用了指令选项 -E,-S,-c ;如果我们不使用选项的话,那么会直接从.c文件直接编译到可执行文件,而这三个选项的作用就是程序进行完这一步后停下编译;
正好我们键盘的左上角的按键就是[Esc],但是需要注意的是E和S选项必须是大写的,c选项是小写的,如果我们大小写搞错编译后的文件就是乱码,而且会影响后面的文件;
总结:-E---.i文件(替换后的C代码)
-S---.s文件(汇编代码)
-c---.o文件(二进制代码)
先有语言还是先有编译器?
答案是现有语言,但是并不是现有当前编译器的语言;
在最早的时期,人们都是使用二进制语言来编写程序的;但是呢,为了更加的方便的写代码,所以使用二进制编写了汇编代码;故此汇编语言产生,然后人们又使用汇编代码开发出了汇编代码编译器;这个过程就叫做语言自举;
动态连接和静态连接
库的位置
我们平时使用的头文件都是声明,实现都在库文件中,库一般都在/usr/include目录下;
连接方式分为动态链接和静态连接
动态连接:指明地址,向动态库中调用,实现在库中;
动态库一般是共享的,每次使用就需要向库中调用,缺点就是如果出现问题,所有人都使用不了;我们常使用的stdio.h就是动态库;
优点:节省资源 ,可执行程序体积小;缺点:出问题就完蛋了静态连接:将库中的代码块的实现拷贝到可执行程序中;拷贝的代码块和库中的代码块并没有直接关联;如提前拷贝好,即使库中的出现问题也不会有任何影响;
优点:不依赖库 缺点:比较浪费资源,可执行程序体积大,一般是动态连接可执行程序的几百倍;
查看文件使用的哪种库?
根据红色的部分判断是什么库?
在Linux中:.so(动态库) .a(静态库)
在Windows中:.dill(动态库) .lib(静态库)
云服务器默认没有装C/C++静态标准库 ,我们可以使用yum按照下面的指令安装;
sudo yum install libstdc++-staticMakefile自动构建化工具
我们可以把makefile理解为指令的集合;makefile文件里有我们写好的很多指令,然后我们对makefile进行操作就可以对更加便捷的调用其内部的指令;
举个例子;比如有一份proc.c的C语言文件,我们在使用的过程中需要多次的对文件编译,正常情况下每次编译都要使用gcc proc.c -o proc;生成可执行文件proc;这样操作是很麻烦的;makefile工具可以很好的解决这种频繁调用编译的问题;
makefile的使用
makefile其实就是一个文件;但是不是个普通的文件;
makefile本质上是一个依赖关系和依赖方法的集合;
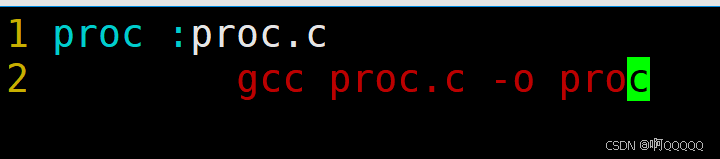
第一行:proc是生成的文件;proc.c是依赖文件;冒号代表的是依赖关系;
第二行需要空一个Tab键的长度(不能使用空格);然后输入要执行的命令;
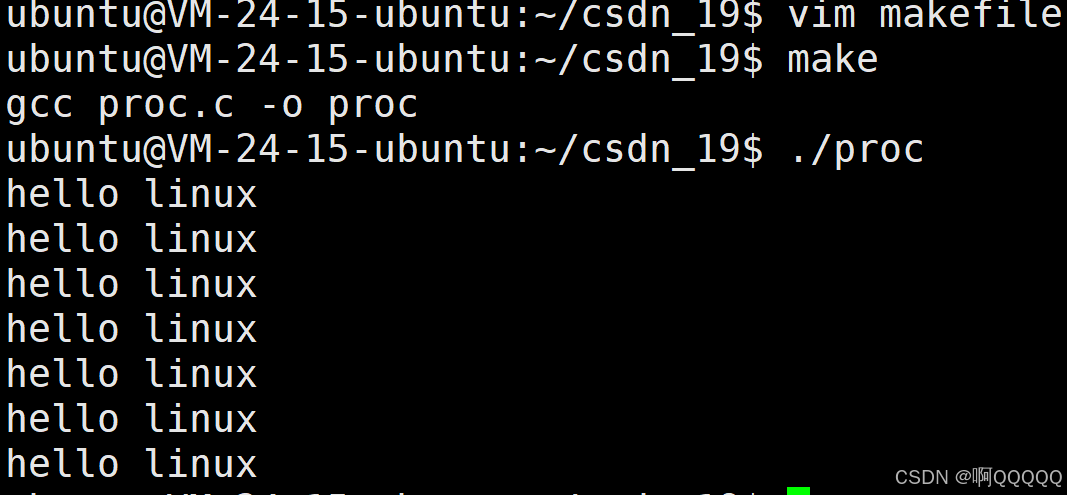
我们直接使用指令"make"就可以调用gcc proc.c -o proc指令了;这样使用起来是不是会很方便;
那是不是也可以这样方便的清理文件呢?
答案是可以的,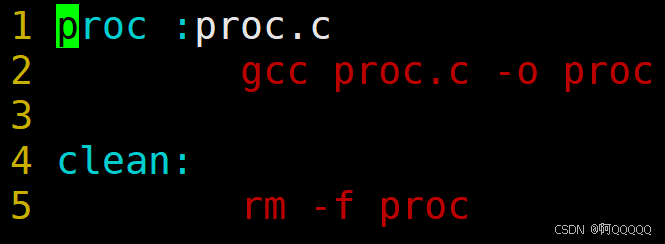
不同的是删除代码不需要依赖任何文件,所以没有依赖文件;
我们需要使用"make clean"来调用清除可执行程序的指令;
为什么gcc proc.c -o proc直接使用make 就可以呢?
这是因为代码的执行顺序是从上到下的,make默认调用第一个依赖关系命令,这里实际上make 的完整指令应该是"make proc";
目标的调用顺序
现在来写一下C语言编译的完整过程: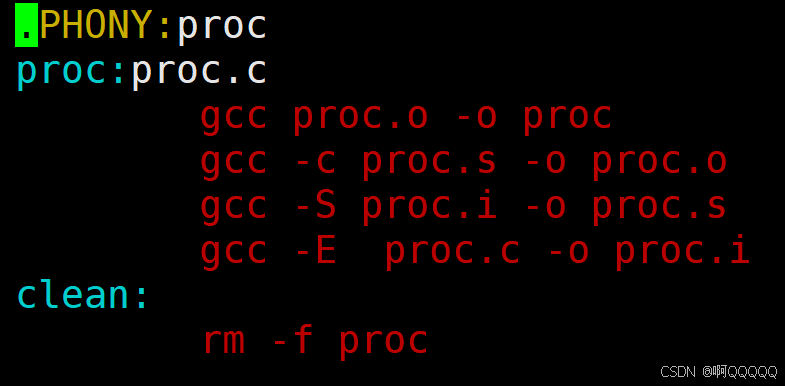
程序执行的顺序是从上往下执行的,当执行gcc proc.o -o proc时,这时候还没有proc.o文件,所以就会先把这一行的指令放入堆栈中,依次类推,直到最后gcc -E proc.c -o proc.i产生了proc.i文件,紧接着指令依次出栈;最后执行完毕;
.PHNOY伪目标
.PHNOY:让目标总是执行;
作用:忽略时间带来的限制;
在没有使用.PHMOY的情况下,proc.c文件在最新版本时候,是只能make一次的;这样做的目的提高效率;
在此编译会给出"proc is up to date" proc可执行程序是最新的,不需要再次编译;
如何查看文件是否是最新的?
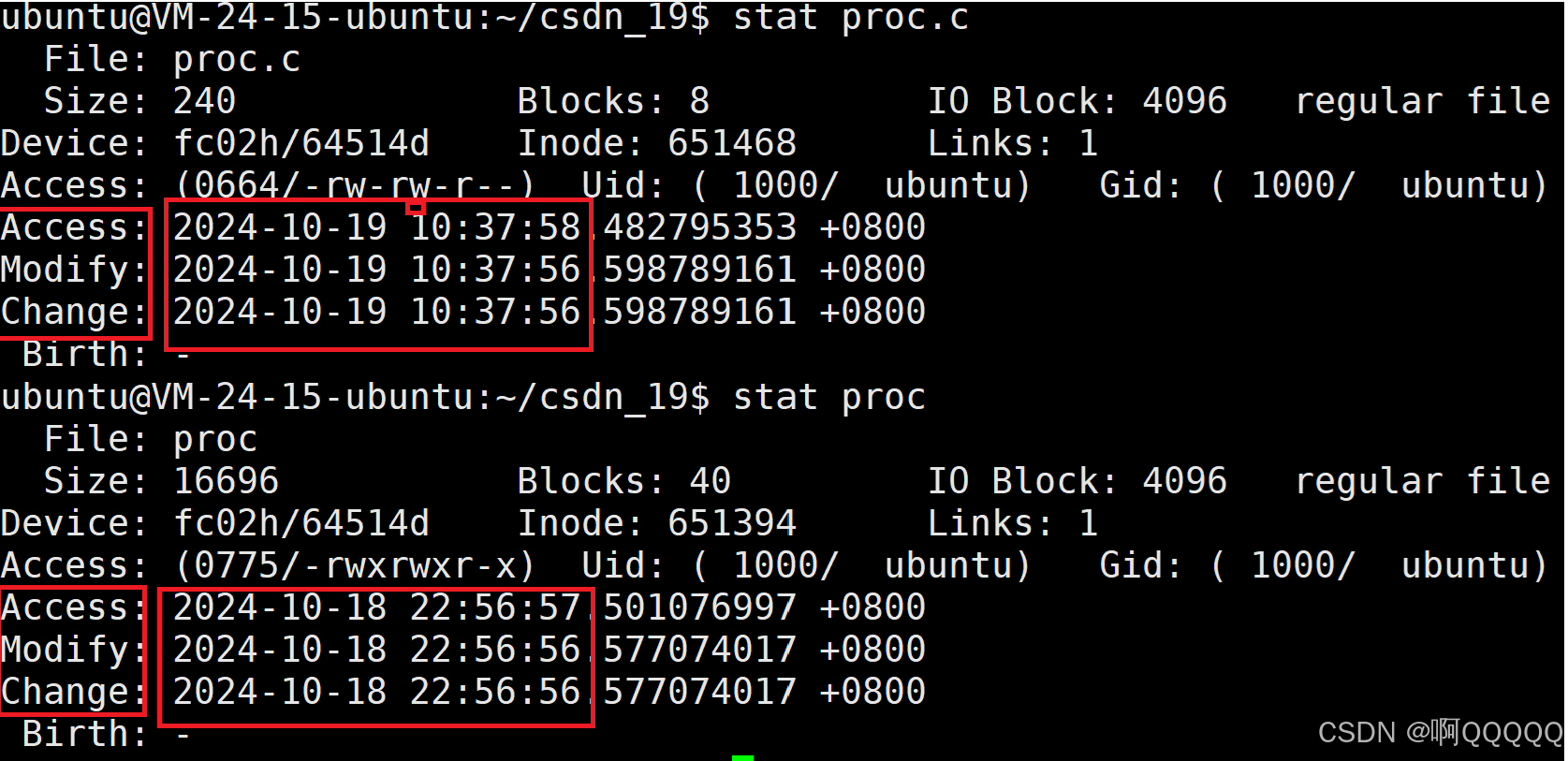
stat 文件名:查看文件的最近一次的更改时间相关的信息;
正常情况下,proc.c文件的时间应该是在proc之前的,因为先有proc.c再有proc;这是我刚才更新了一下proc.c文件,这时候proc.c比proc还要新,所以这个时候是可以重新编译的;
文件=内容+属性
Modify:最近内容被改变的时间
change:最近属性被改变的时间
在一个文件不存在的时候,touch的作用是将该文件新建出来,但是如果这个文件存在的话,touch就可以将三个时间都修改成当前的时候,或者是用-a -m -c 选项来强制修改其中一个。
使用伪目标忽略时间
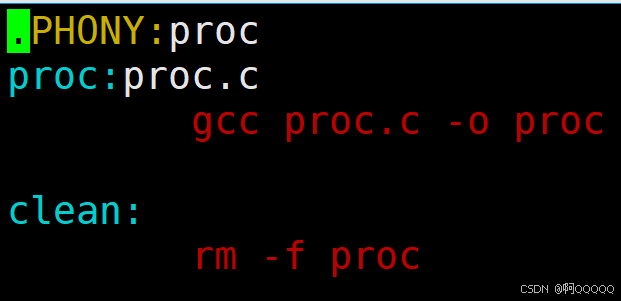
如果我们对make proc设置伪目标,那样就可以无限次的编译了;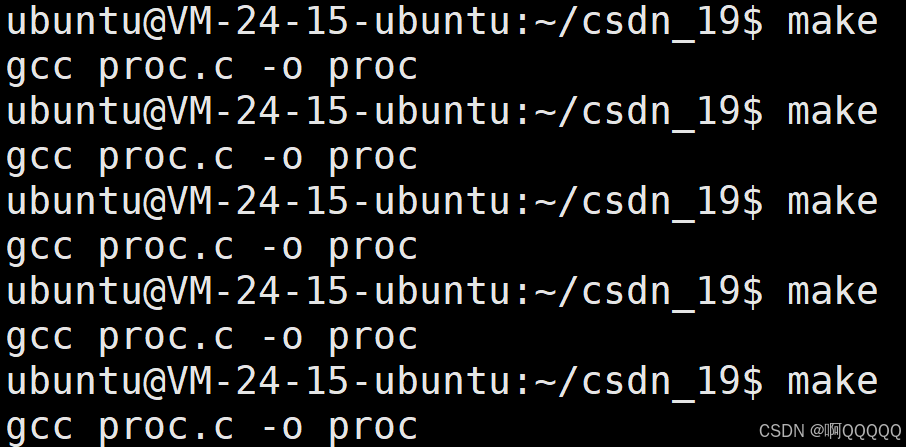
总结
1.makefile文件,会被make从上到下开始扫描,一个目标名,是缺省形成的,如果我们想执行其他组依赖关系和依赖方法,就要使用make name;
2.make makefile在执行gcc 命令的时候,如果发生了语法错误,就会终止推导过程;
3.make解释makefile的时候,是会自动推导的,一直推导,推导过程,不执行依赖方法,直到推导到有依赖文件存在,然后逆向的执行所有的依赖方法;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









