






接下来,我们会复习MySQL的基础知识,希望对你有用。(跳过了软件的安装)
前提知识:
1.SQL语言在功能的分类:
- 1.DDL :数据定义语言这些语句定义了不同的数据库、表、视图、索引等数据库对象,还可以用来创建、删除、修改数据库和数据表的结构。关键词:
CREATE(创建)、DROP(删除)、ALTER(修改)等。 - 2.DML:数据操作语言,用于添加、删除、更新和查询数据库记录,并检查数据完整性。关键字包括
INSERT、DELETE、UPDATE、SELECT等。其中***SELECT是重中之重***。 - 3.DCL:数据控制语言,用于定义数据库、表、字段、用户的访问权限和安全级别。关键字包括
GRANT、REVOKE、COMMIT、ROLLBACK、SAVEPOINT等。(使用的频率低)
2.注释:
1.单行注释:#注释文字(MySQL特有的方式)
2.单行注释:-- 注释文字(–后面必须包含一个空格。)
3.多行注释:/* 注释文字 */
3.命名规则
- 数据库、表名不得超过30个字符,变量名限制为29个
- 必须只能包含 A–Z, a–z, 0–9, _共63个字符
- 数据库名、表名、字段名等对象名中间不要包含空格
- 同一个MySQL软件中,数据库不能同名;同一个库中,表不能重名;同一个表中,字段不能重名
- 必须保证你的字段没有和保留字、数据库系统或常用方法冲突。如果坚持使用,请在SQL语句中使用`(着重号)引起来
- 保持字段名和类型的一致性,在命名字段并为其指定数据类型的时候一定要保证一致性。假如数据类型在一个表里是整数,那在另一个表里可就别变成字符型了
一.SQL之SELECT使用篇
1.基本的SELECT语句
SELECT的结构:
语法:
SELECT 标识选择哪些列
FROM 标识从哪个表中选择
1.选择全部列:
SELECT *
FROM 表名 ;
2.去重复行,别名,过滤数据:
SELECT (DISTINCT 去除重复行) 列名 (空一格,写别名,也可用AS) ,列名......
FROM 表名
WHERE 过滤条件,WHERE子句紧随 FROM子句;
3.空值参与运算:
所有运算符或列值遇到null值,运算的结果都为null,但在 MySQL 里面, 空值不等于空字符串。
一个空字符串的长度是 0,而一个空值的长度是空。而且,在 MySQL 里面,空值是占用空间的。
4. 着重号(`列名`):
避免与保留字与数据库系统或常见方法冲突。
5.显示表结构:
DESCRIBE 表名;
或
DESC 表名;
2:运算符
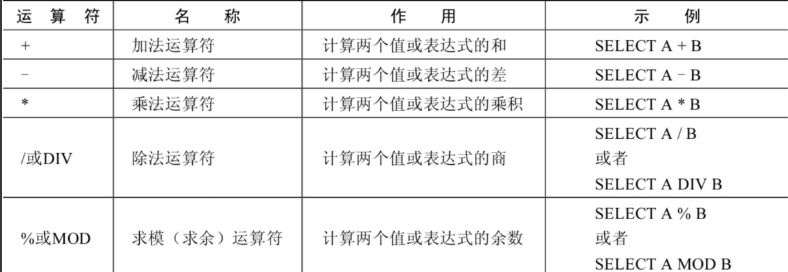
2.1.算术运算符:
算术运算符主要用于数学运算,其可以连接运算符前后的两个数值或表达式,对数值或表达式进行加(+)、减(-)、乘(*)、除(/)和取模(%)运算。
SELECT 100, 100 + 0, 100 - 0, 100 + 50, 100 + 50 * 30, 100 + 35.5, 100 - 35.5
FROM DUAL;#DAUL 空表
在SQL中,+没有连接的作用,就表示加法运算。此时,会将字符串转换为数值(隐式转换)
SELECT 100 + '1' # 在Java语言中,结果是:1001。
FROM DUAL;
SELECT 100 + 'a' #此时将'a'看做0处理
FROM DUAL;
SELECT 100 + NULL # null值参与运算,结果为null
FROM DUAL;
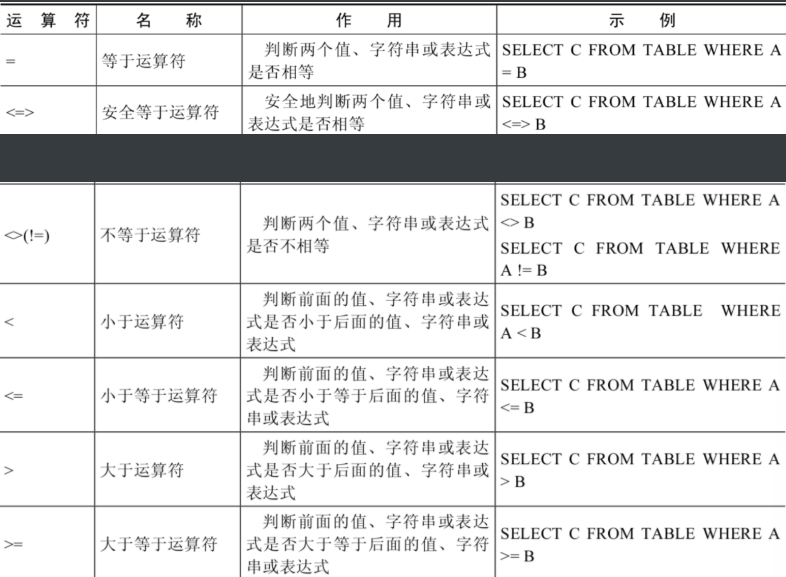
2.2 比较运算符
比较运算符用来对表达式左边的操作数和右边的操作数进行比较,比较的结果为真则返回1,比较的结果为假则返回0,其他情况则返回NULL。
比较运算符经常被用来作为SELECT查询语句的条件来使用,返回符合条件的结果记录。
= 的使用
SELECT 1 = 2,1 != 2,1 = '1',1 = 'a',0 = 'a' #字符串存在隐式转换。如果转换数值不成功,则看做0
FROM DUAL;# 0 1 1 0 1
SELECT 'a' = 'a','ab' = 'ab','a' = 'b' #两边都是字符串的话,则按照ANSI的比较规则进行比较。
FROM DUAL;# 1 1 0
SELECT 1 = NULL,NULL = NULL # 只要有null参与判断,结果就为null
FROM DUAL; # NULL NULL
<=>:安全等于,为了NULL而生
SELECT 1 <=> 2,1<=>'1',1<=>'a',0<=>'a'
FROM DUAL;# 0,1,0,1
SELECT 1<=>NULL,NULL<=>NULL
FROM DUAL;# 0 1
非符号类型的运算符:
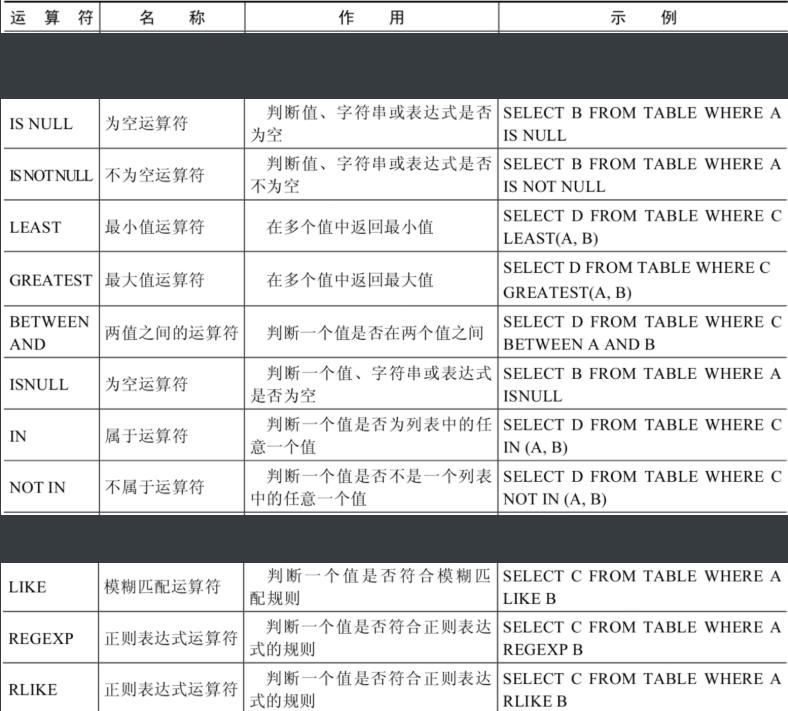
①BETWEEN 条件下界1 AND 条件上界2 (查询条件1和条件2范围内的数据,包含边界)
SELECT employee_id,last_name,salary
FROM employees
WHERE salary BETWEEN 6000 AND 8000;
WHERE salary NOT BETWEEN 6000 AND 8000;#不在6000 到 8000的员工信息
② in (set)\ not in (set) 属于运算符 不属于运算符
#练习:查询部门为10,20,30部门的员工信息
SELECT last_name,salary,department_id
FROM employees
WHERE department_id IN(10,20,30);
③ LIKE :模糊查询
# % : 代表不确定个数的字符 (0个,1个,或多个)
SELECT last_name
FROM employees
WHERE last_name LIKE '%a%';
前面一个% 表示a可以不是第一个
后面一个% 表示a可以不是最后一个
④ _ : 代表一个不确定的字符
SELECT last_name
FROM employees
WHERE last_name LIKE '_a%';#Pataballa _a表示a前面可以有一个随机数值
# __a表示a前面可以有二个随机数值
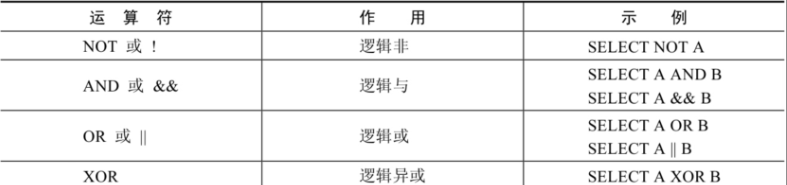
2.3 逻辑运算符
逻辑运算符主要用来判断表达式的真假,在MySQL中,逻辑运算符的返回结果为1、0或者NULL。
MySQL中支持4种逻辑运算符如下:
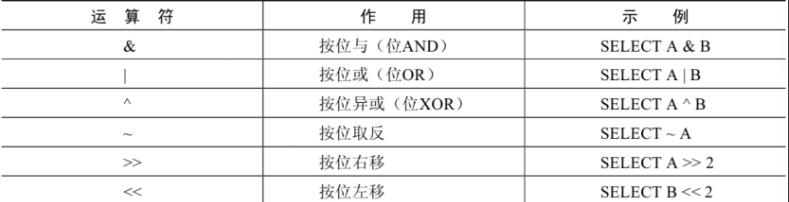
2.4 位运算符
位运算符是在二进制数上进行计算的运算符。位运算符会先将操作数变成二进制数,然后进行位运算,最后将计算结果从二进制变回十进制数。
MySQL支持的位运算符如下: 位运算符
2.5 运算符的优先级
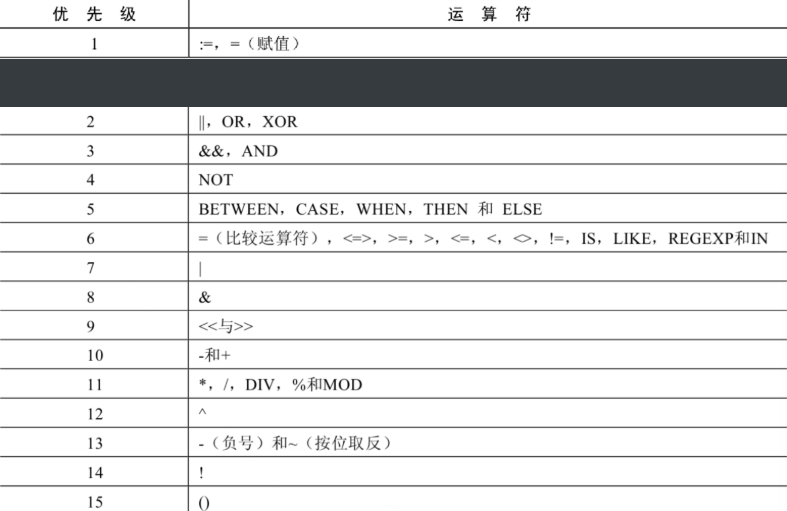
数字编号越大,优先级越高,优先级高的运算符先进行计算。可以看到,赋值运算符的优先级最低,使用“()”括起来的表达式的优先级最高。
3:排序与分页
3.1 排序规则
- 使用 ORDER BY 子句排序
- ASC(ascend): 升序
- DESC(descend):降序 - ORDER BY 子句在SELECT语句的结尾。
结构:
1.单列排序
SELECT last_name, job_id, department_id, hire_date
FROM employees
ORDER BY hire_date DESC/ASC ;
2.多列排序
SELECT last_name, department_id, salary
FROM employees
ORDER BY department_id , salary DESC/ASC;
注意:在对多列进行排序的时候,首先排序的第一列必须有相同的列值,才会对第二列进行排序。如果第一列数据中所有值都是唯一的,将不再对第二列进行排序。
3.2 分页
实现规则
-
分页原理
所谓分页显示,就是将数据库中的结果集,一段一段显示出来需要的条件。
-
MySQL中使用 LIMIT 实现分页
-
格式:
LIMIT [位置偏移量,] 行数第一个“位置偏移量”参数指示MySQL从哪一行开始显示,是一个可选参数,如果不指定“位置偏移量”,将会从表中的第一条记录开始(第一条记录的位置偏移量是0,第二条记录的位置偏移量是1,以此类推);第二个参数“行数”指示返回的记录条数。
--前10条记录:
SELECT *
FROM 表名 LIMIT 0,10;
或者
SELECT *
FROM 表名 LIMIT 10;
--第11至20条记录:
SELECT *
FROM 表名 LIMIT 10,10;
--第21至30条记录:
SELECT *
FROM 表名 LIMIT 20,10;
- 分页显式公式:(当前页数-1)每页条数,每页条数*
SELECT * FROM table
LIMIT(PageNo - 1)*PageSize,PageSize;
- 注意:LIMIT 子句必须放在整个SELECT语句的最后!
- 使用 LIMIT 的好处
约束返回结果的数量可以减少数据表的网络传输量,也可以提升查询效率。如果我们知道返回结果只有 1 条,就可以使用LIMIT 1,告诉 SELECT 语句只需要返回一条记录即可。这样的好处就是 SELECT 不需要扫描完整的表,只需要检索到一条符合条件的记录即可返回。
4:SQL99语法实现多表查询
多表查询,也称为关联查询,指两个或更多个表一起完成查询操作。
前提条件:这些一起查询的表之间是有关系的(一对一、一对多),它们之间一定是有关联字段,这个关联字段可能建立了外键,也可能没有建立外键。比如:员工表和部门表,这两个表依靠“部门编号”进行关联。
4.1基本语法
- 使用JOIN…ON子句创建连接的语法结构:
SELECT table1.column, table2.column,table3.column
FROM table1
JOIN table2 ON table1 和 table2 的连接条件
JOIN table3 ON table2 和 table3 的连接条件
4.2 自连接与非自连接
- 自连接:在一个表内进行判断
- 非自连接:在多个表内进行判断
4.3 内连接与外连接
A .内连接
合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行
语法:
SELECT 字段列表
FROM A表 INNER JOIN B表
ON 关联条件
WHERE 等其他子句;
例子:
SELECT e.employee_id, e.last_name, e.department_id,
d.department_id, d.location_id
FROM employees e JOIN departments d
ON (e.department_id = d.department_id);
这用了 表的别名,使用别名可以简化查询,列名前使用表名前缀可以提高查询效率。
但需要注意的是,如果我们使用了表的别名,在查询字段中、过滤条件中就只能使用别名进行代替,不能使用原有的表名,否则就会报错。
B.外连接:
合并具有同一列的两个以上的表的行, 结果集中除了包含一个表与另一个表匹配的行之外,还查询到了左表 或 右表中不匹配的行。
B1. 左外连接(LEFT OUTER JOIN)
语法:
#实现查询结果是A
SELECT 字段列表
FROM A表 LEFT JOIN B表
ON 关联条件
WHERE 等其他子句;
例子:
SELECT e.last_name, e.department_id, d.department_name
FROM employees e
LEFT JOIN departments d
ON (e.department_id = d.department_id) ;
B2.2 右外连接(RIGHT OUTER JOIN)
- 语法:
#实现查询结果是B
SELECT 字段列表
FROM A表 RIGHT JOIN B表
ON 关联条件
WHERE 等其他子句;
例子:
SELECT e.last_name, e.department_id, d.department_name
FROM employees e
RIGHT JOIN departments d
ON (e.department_id = d.department_id) ;
C.7种SQL JOINS的实现
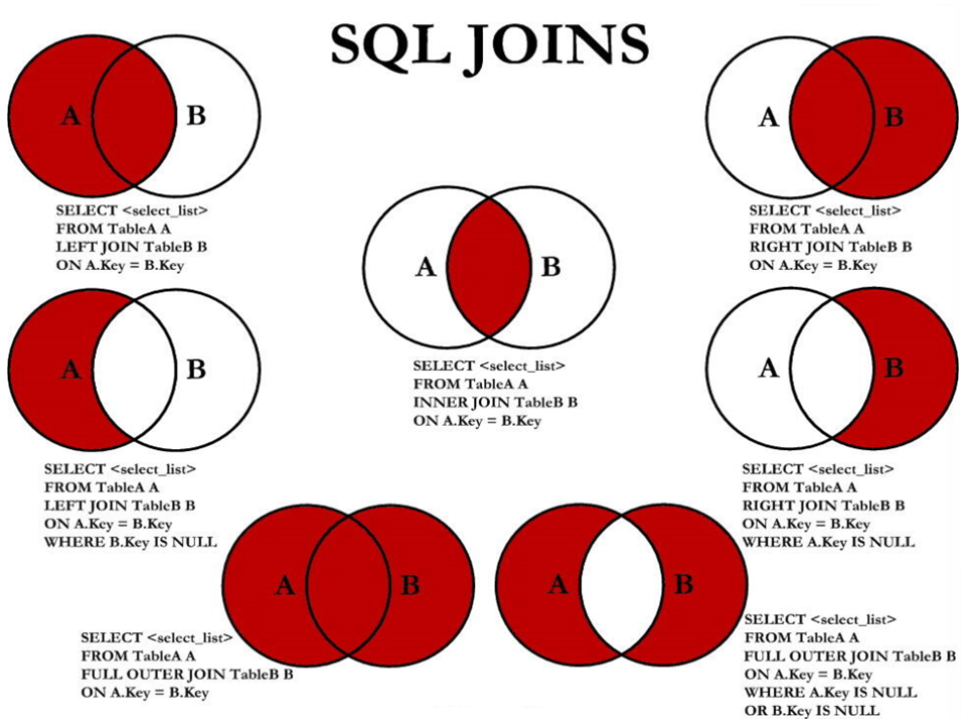
代码实现:
中图:内连接 A∩B
SELECT employee_id,last_name,department_name
FROM employees e JOIN departments d
ON e.`department_id` = d.`department_id`;
左上图:左外连接
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`;
右上图:右外连接
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;
左中图:A - A∩B
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
右中图:B-A∩B
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL
左下图:满外连接
左中图 + 右上图 A∪B
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL #没有去重操作,效率高
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;
右下图
左中图 + 右中图 A ∪B- A∩B 或者 (A - A∩B) ∪ (B - A∩B)
SELECT employee_id,last_name,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_id` IS NULL
UNION ALL
SELECT employee_id,last_name,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL
5:聚合函数
5.1 聚合函数介绍
- 什么是聚合函数
- 聚合函数作用于一组数据,并对一组数据返回一个值。
- 聚合函数类型
- AVG()
- SUM()
- MAX()
- MIN()
- COUNT()
5.2 COUNT函数
- COUNT(*)返回表中记录总数,适用于任意数据类型
- COUNT(expr) 返回expr不为空的记录总数
SELECT COUNT(*)
FROM employees
WHERE department_id = 50;
- 问题:能不能使用count(列名)替换count(*)?
- 不要使用 count(列名)来替代
count(*),count(*)是 SQL92 定义的标准统计行数的语法,跟数据库无关,跟 NULL 和非 NULL 无关。 - 说明:count(*)会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行。
5.3 GROUP BY
基本使用

可以使用GROUP BY子句将表中的数据分成若干组
SELECT column, group_function(column)
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[ORDER BY column];
明确:WHERE一定放在FROM后面**
2.2 使用多个列分组
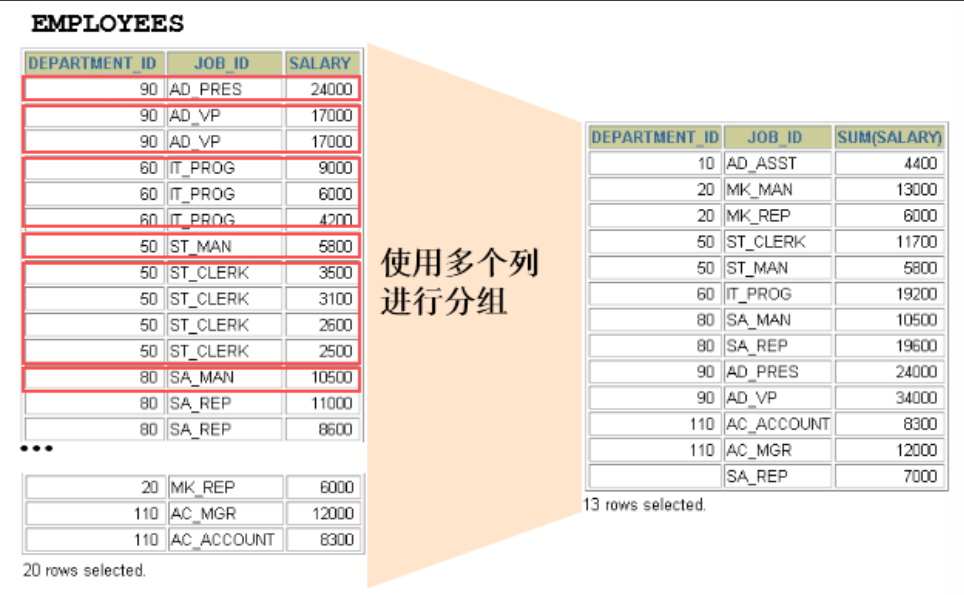
SELECT department_id dept_id, job_id, SUM(salary)
FROM employees
GROUP BY department_id, job_id ;
5.4 HAVING(过滤分组)
使用的条件:
-
- 行已经被分组。
-
- 使用了聚合函数。
-
- 满足HAVING 子句中条件的分组将被显示。
-
- HAVING 不能单独使用,必须要跟 GROUP BY 一起使用。
SELECT department_id, MAX(salary)
FROM employees
GROUP BY department_id
HAVING MAX(salary)>10000 ;
5.5 SELECT的执行过程
4.1 查询的结构
#方式1:
SELECT ...,....,...
FROM ...,...,....
WHERE 多表的连接条件
AND 不包含组函数的过滤条件
GROUP BY ...,...
HAVING 包含组函数的过滤条件
ORDER BY ... ASC/DESC
LIMIT ...,...
#方式2:
SELECT ...,....,...
FROM ... JOIN ...
ON 多表的连接条件
JOIN ...
ON ...
WHERE 不包含组函数的过滤条件
AND/OR 不包含组函数的过滤条件
GROUP BY ...,...
HAVING 包含组函数的过滤条件
ORDER BY ... ASC/DESC
LIMIT ...,...
#其中:
#(1)from:从哪些表中筛选
#(2)on:关联多表查询时,去除笛卡尔积
#(3)where:从表中筛选的条件
#(4)group by:分组依据
#(5)having:在统计结果中再次筛选
#(6)order by:排序
#(7)limit:分页
4.2 SELECT执行顺序
你需要记住 SELECT 查询时的两个顺序:
1. 关键字的顺序是不能颠倒的:
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ... LIMIT...
2.SELECT 语句的执行顺序(在 MySQL 和 Oracle 中,SELECT 执行顺序基本相同):
FROM -> WHERE -> GROUP BY -> HAVING -> SELECT 的字段 -> DISTINCT -> ORDER BY -> LIMIT
6:子查询
子查询的基本使用
- 子查询的基本语法结构:
SELECT select_list
FROM table
WHERE expr operator(
SELECT select_list
FROM table
);
- 子查询(内查询)在主查询之前一次执行完成。
- 子查询的结果被主查询(外查询)使用 。
- 注意事项
- 子查询要包含在括号内
- 将子查询放在比较条件的右侧
- 单行操作符对应单行子查询,多行操作符对应多行子查询
- 子查询的分类
- 按内查询的结果返回一条还是多条记录,将子查询分为
单行子查询、多行子查询。 - 按内查询是否被执行多次,将子查询划分为
相关(或关联)子查询(多次)和不相关(或非关联)子查询(一次)。
- 按内查询的结果返回一条还是多条记录,将子查询分为
6.1单行子查询
单行比较操作符:
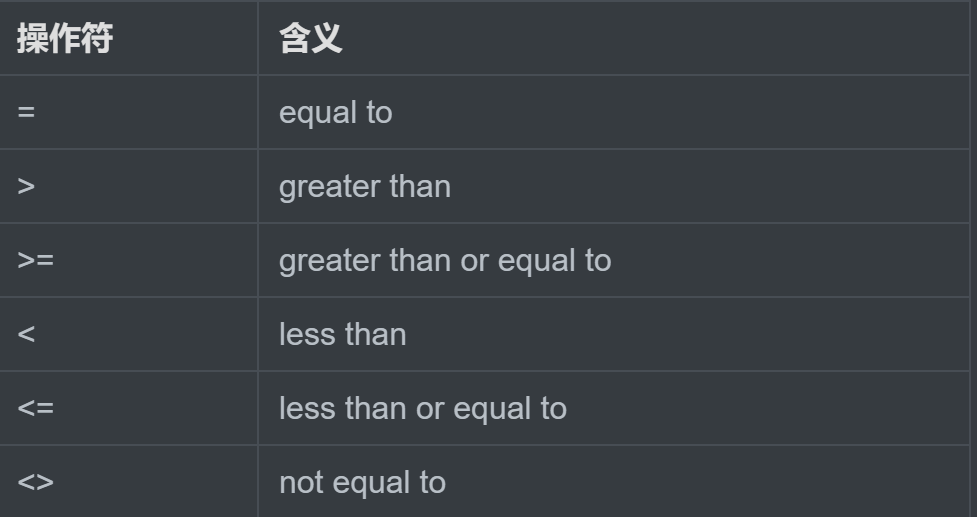
题目:返回job_id与141号员工相同,salary比143号员工多的员工姓名,job_id和工资
SELECT last_name, job_id, salary
FROM employees
WHERE job_id = (SELECT job_id
FROM employees
WHERE employee_id = 141
)
AND salary > (SELECT salary
FROM employees
WHERE employee_id = 143
);
6.2多行子查询
-
也称为集合比较子查询
-
内查询返回多行
-
使用多行比较操作符
多行比较操作符
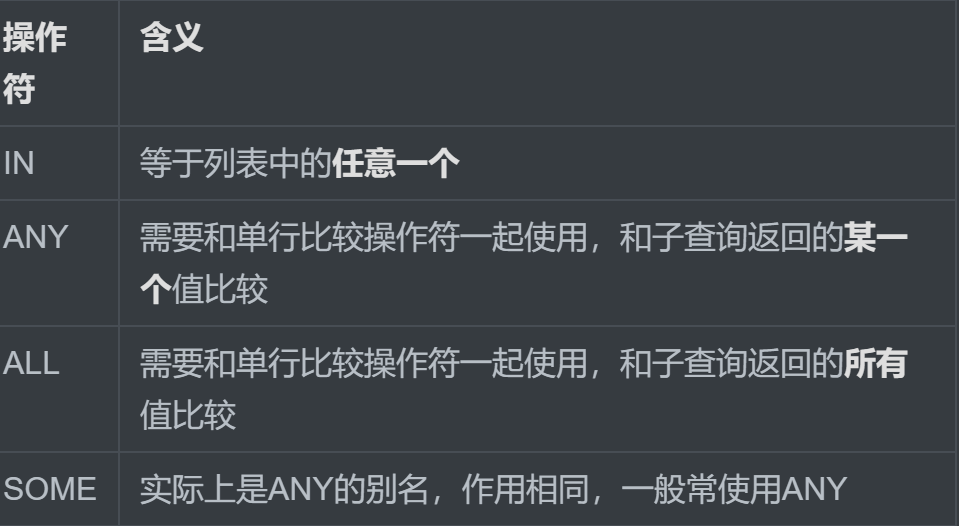
题目:查询平均工资最低的部门id
#方式1:
SELECT department_id
FROM employees
GROUP BY department_id
HAVING AVG(salary) = (
SELECT MIN(avg_sal)
FROM (
SELECT AVG(salary) avg_sal
FROM employees
GROUP BY department_id
) dept_avg_sal
);
#方式2:
SELECT department_id
FROM employees
GROUP BY department_id
HAVING AVG(salary) <= ALL (
SELECT AVG(salary) avg_sal
FROM employees
GROUP BY department_id
)
空值问题:
SELECT last_nameFROM employeesWHERE employee_id NOT IN ( SELECT manager_id FROM employees );
6.4 EXISTS 与 NOT EXISTS关键字
- EXISTS 存在
- NOT EXISTS 不存在
题目:查询公司管理者的employee_id,last_name,job_id,department_id信息
方式1:自连接
SELECT DISTINCT mgr.employee_id,mgr.last_name,mgr.job_id,mgr.department_id
FROM employees emp JOIN employees mgr
ON emp.employee_id = mgr.employee_id;
方式2:子查询
SELECT employee_id,last_name,job_id,department_id
FROM employees
WHERE employee_id IN (
SELECT DISTINCT manager_id
FROM employees
);
方式3:使用EXISTS
SELECT employee_id,last_name,job_id,department_id
FROM employees e1
WHERE EXISTS (
SELECT *
FROM employees e2
WHERE e1.`employee_id` = e2.`manager_id`
);
二. SQL之DDL、DML、DCL使用篇
1:创建和管理表
1.1 MYSQL中的数据结构
建议:
- 整数型:INT(或 INTEGER)
- 浮点型:DECIMAL(定点数类型,高精度小数)
- 日期时间类型:DATE
- 文本字符串类型:VARCHAR(可变长字符数据,根据字符串实际长度保存,必须指定长度)
1.2创建数据库与管理数据库
1.创建数据库
判断数据库是否已经存在,不存在则创建数据库,并指定字符集
CREATE DATABASE IF NOT EXISTS 数据库名 CHARACTER SET 字符集;
2.使用数据库
SHOW DATABASES;#查看当前所有的数据库
SELECT DATABASE();#查看当前正在使用的数据库
SHOW TABLES FROM #数据库名;查看指定库下所有的表
SHOW CREATE DATABASE 数据库名;#查看数据库的创建信息
USE 数据库名;#使用/切换数据库
3.修改数据库
ALTER DATABASE 数据库名 CHARACTER SET 字符集;
4.删除数据库
DROP DATABASE IF EXISTS 数据库名;
1.3 表
A.创建表
a.创建方式1:一般情况:
CREATE TABLE [IF NOT EXISTS] 表名(
字段1, 数据类型 [约束条件] [默认值],
字段2, 数据类型 [约束条件] [默认值],
字段3, 数据类型 [约束条件] [默认值],
……
[表约束条件]
);
例如:
-- 创建表
CREATE TABLE emp (
-- int类型
emp_id INT,
-- 最多保存20个中英文字符
emp_name VARCHAR(20),
-- 总位数不超过15位
salary DECIMAL,
-- 日期类型
birthday DATE
);
b.方式2:将创建表和插入数据结合起来
CREATE TABLE 表名
AS
SELECT 表的列名
FROM 已存在的表
例如:
CREATE TABLE dept80
AS
SELECT employee_id, last_name, salary*12 ANNSAL, hire_date
FROM employees
WHERE department_id = 80;
- 指定的列和子查询中的列要一一对应
- 通过列名和默认值定义列
B.修改表
1.追加一个列
ALTER TABLE 表名 ADD 字段名 字段类型 【FIRST|AFTER 字段名】;
例如:ALTER TABLE dept80 ADD job_id varchar(15);
2. 修改一个列:可以修改列的数据类型,长度、默认值和位置
ALTER TABLE 表名 MODIFY 字段名1 字段类型 【DEFAULT 默认值】【FIRST|AFTER 字段名2】;
例如:ALTER TABLE dept80 MODIFY salary double(9,2) default 1000;
3. 重命名一个列
ALTER TABLE 表名 CHANGE 列名 新列名 新数据类型;
例如:ALTER TABLE dept80 CHANGE department_name dept_name varchar(15);
4. 删除一个列
ALTER TABLE 表名 DROP COLUMN 字段名
例如:ALTER TABLE dept80 DROP COLUMN job_id;
5. 重命名表
RENAME TABLE 表名前 TO 表名后;
例如:RENAME TABLE emp TO myemp;
6. 删除表
DROP TABLE [IF EXISTS] 数据表1 [, 数据表2, …, 数据表n];#DROP TABLE 语句不能回滚
7.清空表:删除表中所有的数据,(不建议使用)
TRUNCATE TABLE 表名;#TRUNCATE语句**不能回滚**
2:数据处理之增删改
2.1 插入数据
- 方式1:VALUES的方式添加:
为表的指定字段插入数据,并可以同时插入多条记录
INSERT INTO table_name(column1 , column2, …, columnn)
VALUES
(value1 ,value2, …, valuen),
(value1 ,value2, …, valuen),
……
(value1 ,value2, …, valuen);
例如:
INSERT INTO emp1(id,NAME,salary)
VALUES
(4,'Jim',5000),
(5,'张俊杰',5500);
- 方式2:将查询结果插入到表中
INSERT INTO 目标表名(tar_column1 [, tar_column2, …, tar_columnn])
SELECT(src_column1 [, src_column2, …, src_columnn])
FROM 源表名
[WHERE condition]
- 在 INSERT 语句中加入子查询。
- 不必书写 VALUES 子句。
- 子查询中的值列表应与 INSERT 子句中的列名对应。
举例:
INSERT INTO emp2
SELECT *
FROM employees
WHERE department_id = 90;
INSERT INTO sales_reps(id, name, salary, commission_pct)
SELECT employee_id, last_name, salary, commission_pct
FROM employees
WHERE job_id LIKE '%REP%';
2.2 更新数据(修改数据)
UPDATE table_name
SET column1=value1, column2=value2, … , column=valuen
[WHERE condition]
-
可以一次更新多条数据。
-
如果需要回滚数据,需要保证在DML前,进行设置:SET AUTOCOMMIT = FALSE;
例如:
UPDATE employees
SET department_id = 70
WHERE employee_id = 113;
2.3 删除数据
1.使用 DELETE 语句从表中删除数据
DELETE FROM table_name #table_name指定要执行删除操作的表;
[WHERE <condition>];#为可选参数,指定删除条件,如果没有WHERE子句,DELETE语句将删除表中的所有记录。
例如:
1.删除指定的记录。
DELETE FROM departments
WHERE department_name = 'Finance';
2.如果省略 WHERE 子句,则表中的全部数据将被删除
DELETE FROM copy_emp;
3:约束
3.1 什么是约束
约束是表级的强制规定。
可以在创建表时规定约束(通过 CREATE TABLE 语句),或者在表创建之后通过 ALTER TABLE 语句规定约束。
3.2 约束的分类
- **根据约束数据列的限制,**约束可分为:
- 单列约束:每个约束只约束一列
- 多列约束:每个约束可约束多列数据
- 根据约束的作用范围,约束可分为:
- 列级约束:只能作用在一个列上,跟在列的定义后面
- 表级约束:可以作用在多个列上,不与列一起,而是单独定义
位置 支持的约束类型 是否可以起约束名
列级约束: 列的后面 语法都支持,但外键没有效果 不可以
表级约束: 所有列的下面 默认和非空不支持,其他支持 可以(主键没有效果)
- 根据约束起的作用,约束可分为:
- NOT NULL 非空约束,规定某个字段不能为空
- UNIQUE 唯一约束,规定某个字段在整个表中是唯一的
- PRIMARY KEY 主键(非空且唯一)约束
- FOREIGN KEY 外键约束
- CHECK 检查约束(MySQL不支持check约束)
- DEFAULT 默认值约束
3.3 非空约束
3.3.1作用:
限定某个字段/某列的值不允许为空
3.3.2 关键字
NOT NULL
3.3.3 特点
-
默认,所有的类型的值都可以是NULL,包括INT、FLOAT等数据类型
-
非空约束只能出现在表对象的列上,只能某个列单独限定非空,不能组合非空
-
一个表可以有很多列都分别限定了非空
-
空字符串’'不等于NULL,0也不等于NULL
3.3.4 添加非空约束
(1)建表时
CREATE TABLE 表名称(
字段名 数据类型,
字段名 数据类型 NOT NULL,
字段名 数据类型 NOT NULL
);
举例:
CREATE TABLE emp(
id INT(10) NOT NULL,
NAME VARCHAR(20) NOT NULL,
sex CHAR NULL
);
2)建表后
alter table 表名称 modify 字段名 数据类型 not null;
举例:
ALTER TABLE emp
MODIFY sex VARCHAR(30) NOT NULL;
2.5 删除非空约束
alter table 表名称 modify 字段名 数据类型 NULL;#去掉not null,相当于修改某个非注解字段,该字段允许为空
或
alter table 表名称 modify 字段名 数据类型;#去掉not null,相当于修改某个非注解字段,该字段允许为空
举例:
ALTER TABLE emp
MODIFY sex VARCHAR(30) NULL;
3.4 唯一性约束
3.4.1 作用
用来限制某个字段/某列的值不能重复。
3.4.2 关键字
UNIQUE
3.4.3 特点
- 同一个表可以有多个唯一约束。
- 唯一约束可以是某一个列的值唯一,也可以多个列组合的值唯一。
- 唯一性约束允许列值为空。
- 在创建唯一约束的时候,如果不给唯一约束命名,就默认和列名相同。
- MySQL会给唯一约束的列上默认创建一个唯一索引。
3.4.4 添加唯一约束
(1)建表时
create table 表名称(
字段名 数据类型,
字段名 数据类型 unique,
字段名 数据类型 unique key,
字段名 数据类型
);
create table 表名称(
字段名 数据类型,
字段名 数据类型,
字段名 数据类型,
[constraint 约束名] unique key(字段名)
);
举例:
create table student(
sid int,
sname varchar(20),
tel char(11) unique,
cardid char(18) unique key
);
CREATE TABLE USER(
id INT NOT NULL,
NAME VARCHAR(25),
PASSWORD VARCHAR(16),
-- 使用表级约束语法
CONSTRAINT uk_name_pwd UNIQUE(NAME,PASSWORD)
);
(2)建表后指定唯一键约束
#字段列表中如果是一个字段,表示该列的值唯一。如果是两个或更多个字段,那么复合唯一,即多个字段的组合是唯一的
#方式1:
alter table 表名称 add unique key(字段列表);
#方式2:
alter table 表名称 modify 字段名 字段类型 unique;
举例:
ALTER TABLE USER
ADD UNIQUE(NAME,PASSWORD);
ALTER TABLE USER
MODIFY NAME VARCHAR(20) UNIQUE;
3.4.5删除唯一约束
- 添加唯一性约束的列上也会自动创建唯一索引。
- 删除唯一约束只能通过删除唯一索引的方式删除。
- 删除时需要指定唯一索引名,唯一索引名就和唯一约束名一样。
- 如果创建唯一约束时未指定名称,如果是单列,就默认和列名相同;如果是组合列,那么默认和()中排在第一个的列名相同。也可以自定义唯一性约束名。
SELECT * FROM information_schema.table_constraints
WHERE table_name = '表名'; #查看都有哪些约束
ALTER TABLE USER
DROP INDEX uk_name_pwd;
3.5 PRIMARY KEY 约束
3.5.1 作用
用来唯一标识表中的一行记录。
3.5.2 关键字
primary key
3.5.3 特点
- 主键约束相当于唯一约束+非空约束的组合,主键约束列不允许重复,也不允许出现空值。
3.5.4添加主键约束
(1)建表时指定主键约束
create table 表名称(
字段名 数据类型 primary key, #列级模式
字段名 数据类型,
字段名 数据类型
);
create table 表名称(
字段名 数据类型,
字段名 数据类型,
字段名 数据类型,
[constraint 约束名] primary key(字段名) #表级模式
);
举例:
- 列级约束
CREATE TABLE emp4(
id INT PRIMARY KEY AUTO_INCREMENT ,
NAME VARCHAR(20)
);
- 表级约束
CREATE TABLE emp5(
id INT NOT NULL AUTO_INCREMENT,
NAME VARCHAR(20),
pwd VARCHAR(15),
CONSTRAINT emp5_id_pk PRIMARY KEY(id)
);
(2)建表后增加主键约束
ALTER TABLE 表名称
ADD PRIMARY KEY(字段列表); #字段列表可以是一个字段,也可以是多个字段,如果是多个字段的话,是复合主键
ALTER TABLE student ADD PRIMARY KEY (sid);
3.5.5 删除主键约束
alter table 表名称 drop primary key;
举例:
ALTER TABLE student DROP PRIMARY KEY;
说明:删除主键约束,不需要指定主键名,因为一个表只有一个主键,删除主键约束后,非空还存在。
3.6 自增列:AUTO_INCREMENT
3.6.1 作用
某个字段的值自增
3.6.2 关键字
auto_increment
3.6.3 特点和要求
(1)一个表最多只能有一个自增长列
(2)当需要产生唯一标识符或顺序值时,可设置自增长
(3)自增长列约束的列必须是键列(主键列,唯一键列)
(4)自增约束的列的数据类型必须是整数类型
(5)如果自增列指定了 0 和 null,会在当前最大值的基础上自增;如果自增列手动指定了具体值,直接赋值为具体值。
create table employee(
eid int primary key,
ename varchar(20) unique key auto_increment
);
# ERROR 1063 (42000): Incorrect column specifier for column 'ename' 因为ename不是整数类型
3.6.4 如何指定自增约束
(1)建表时
create table 表名称(
字段名 数据类型 primary key auto_increment,
字段名 数据类型 unique key not null,
字段名 数据类型 unique key,
字段名 数据类型 not null default 默认值,
);
create table 表名称(
字段名 数据类型 default 默认值 ,
字段名 数据类型 unique key auto_increment,
字段名 数据类型 not null default 默认值,,
primary key(字段名)
);
create table employee(
eid int primary key auto_increment,
ename varchar(20)
);
(2)建表后
alter table 表名称 modify 字段名 数据类型 auto_increment;
例如:
alter table employee modify eid int auto_increment;
####3.6.5 如何删除自增约束
#alter table 表名称 modify 字段名 数据类型 auto_increment;#给这个字段增加自增约束
alter table 表名称 modify 字段名 数据类型; #去掉auto_increment相当于删除
alter table employee modify eid int;

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









