








注意:提示中的条件一定不能漏,所给的root至少有两个节点(也就是p和q)
解法一(找路径)
1.思路
在一颗树中,从根节点开始,分别找出p和q的路径(也就是节点顺序)
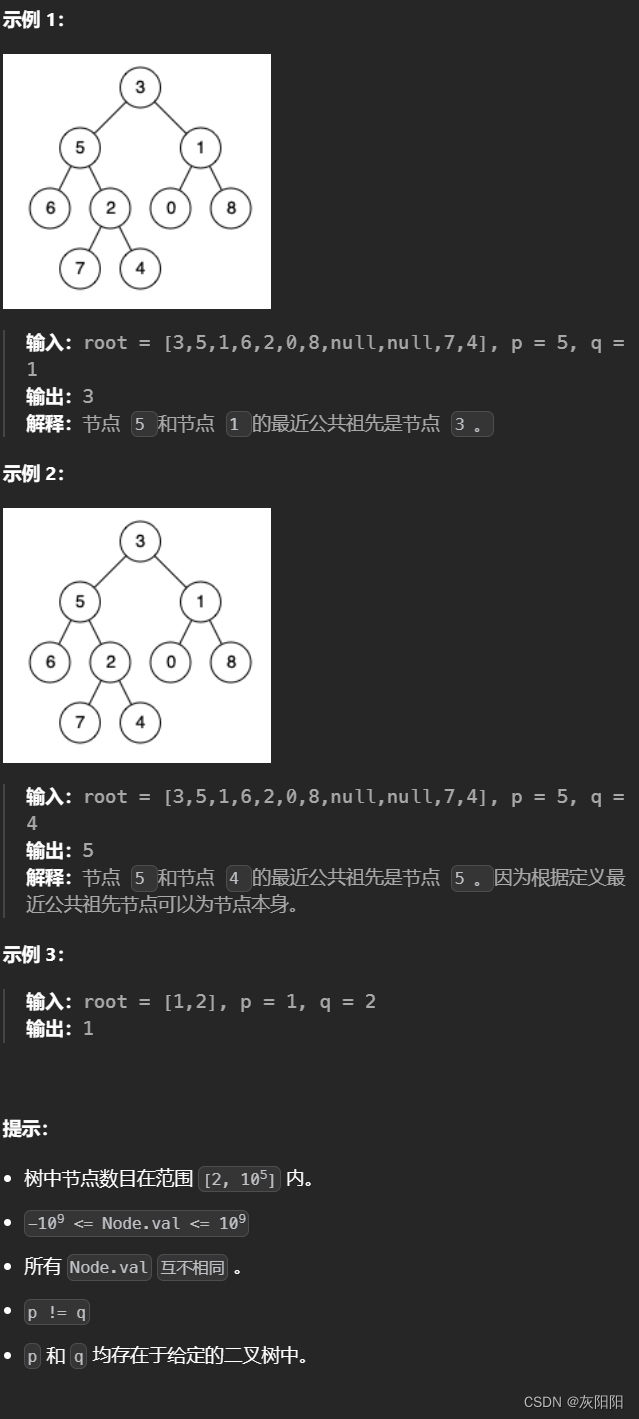
以下面这颗树为栗子:
P==6
Q==7
则
pathP:3->5->6
pathQ:3->5->2->7
我们认为的观察一下,显然结点5是P和Q的最近公共祖先。
那么P和Q的路径都知道了,该怎么去按照程序找到结点5呢?
其实也不难,在寻找这两条路径的同时,我们可以分别建立一个栈,把每个路径的节点都压入栈中。
如图:
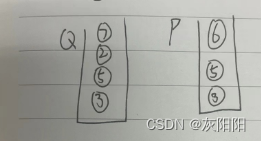
到了这一步,那找到5号结点就很容易了:
1.计算P和Q两个栈,栈的大小。
2.大的栈,出栈,直到两个栈大小一致。
3.两个栈同时出栈,出栈时比较元素是否相等,如果相等返回这个元素,这个元素就是要的最近公共结点。
2.代码书写
其是想要用程序实现这个思路,难点就在于如何去寻找两个节点的路径,我们先把简单的框架搭好,在来解决这个棘手的问题。
请仔细看下面的代码以及注释:
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
//建立两个栈,分别记录p q两个节点的路径
Stack<TreeNode> stackp=new Stack<>();
Stack<TreeNode> stackq=new Stack<>();
//如果获得路径等一下再讨论,把简单的框架做好先,逐个问题击破
getPath(root,p,stackp);
getPath(root,q,stackq);
//把大的栈先出栈,直到两个栈大小相同
int pSize=stackp.size();
int qSize=stackq.size();
int up=qSize<pSize?pSize-qSize:qSize-pSize;
while(up>0){
if(pSize<qSize){//q的路径大
stackq.pop();
}else{//p的路径大
stackp.pop();
}
up--;
}
//程序到达当前注释行,两个栈的大小一致了
//接下来两个栈一起出栈,同时比较出栈元素是否相等,相等返回此元素(也就是结点)
while(true){
TreeNode pNode=stackp.pop();
TreeNode qNode=stackq.pop();
if(pNode.val==qNode.val){//题目已经说明,所有节点的val各不相同
return qNode;
}
}
}
好了,现在只要把getPath方法实现,这题就大工搞成了!
目光全部聚集到getPath方法的实现上
核心思路就是深度优先搜索,不断压栈,出栈,直到找到目标节点返回
代码及其注释解析:
public boolean getPath(TreeNode root, TreeNode tar, Stack<TreeNode> stack) {
if (root == null) return false;//当前节点是空的,肯定没有找到,返回假
stack.push(root);//只要没到路的尽头,闭着眼睛压栈(记录路径)
if (root == tar) return true;//当前节点就是要找的目标,那么成功找到,路径已经被记录到栈中了,直接返回真就可以了
else {//当前节点不是要找的目标节点(p或者q),就深度优先遍历,一直往下找
boolean left = getPath(root.left, tar, stack);
if (left == true) return true;//如果当前根节点的左子树中找到了tar,任务完成,就直接返回真,
boolean right = getPath(root.right, tar, stack);
if ((right == true)) return true;//如果当前根节点的右子树中找到了tar,任务完成,就直接返回真,
//程序执行到这一步,说明当前根节点,及其左右子树都不存在tar,那么当前路径就是无效路径,需要出栈一次,然后返回假
stack.pop();
return false;
}
}完整解题代码:
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
//建立两个栈,分别记录p q两个节点的路径
Stack<TreeNode> stackp = new Stack<>();
Stack<TreeNode> stackq = new Stack<>();
//如果获得路径等一下再讨论,把简单的框架做好先,逐个问题击破
getPath(root, p, stackp);
getPath(root, q, stackq);
//把大的栈先出栈,直到两个栈大小相同
int pSize = stackp.size();
int qSize = stackq.size();
int up = qSize < pSize ? pSize - qSize : qSize - pSize;
while (up > 0) {
if (pSize < qSize) {//q的路径大
stackq.pop();
} else {//p的路径大
stackp.pop();
}
up--;
}
//程序到达当前注释行,两个栈的大小一致了
//接下来两个栈一起出栈,同时比较出栈元素是否相等,相等返回此元素(也就是结点)
while (true) {
TreeNode pNode = stackp.pop();
TreeNode qNode = stackq.pop();
if (pNode.val == qNode.val) {//题目已经说明,所有节点的val各不相同
return qNode;
}
}
}
public boolean getPath(TreeNode root, TreeNode tar, Stack<TreeNode> stack) {
if (root == null) return false;//当前节点是空的,肯定没有找到,返回假
stack.push(root);//只要没到路的尽头,闭着眼睛压栈(记录路径)
if (root == tar) return true;//当前节点就是要找的目标,那么成功找到,路径已经被记录到栈中了,直接返回真就可以了
else {//当前节点不是要找的目标节点(p或者q),就深度优先遍历,一直往下找
boolean left = getPath(root.left, tar, stack);
if (left == true) return true;//如果当前根节点的左子树中找到了tar,任务完成,就直接返回真,
boolean right = getPath(root.right, tar, stack);
if ((right == true)) return true;//如果当前根节点的右子树中找到了tar,任务完成,就直接返回真,
//程序执行到这一步,说明当前根节点,及其左右子树都不存在tar,那么当前路径就是无效路径,需要出栈一次,然后返回假
stack.pop();
return false;
}
}
}
评分:
解法二(纯递归)
解法二相较于解法一,时间和空间复杂度都有大幅的优化,因为解法一其实也用了递归,而且递归搜索了两次(找p和q的路径),其次,还建立了两个栈。
下面讲完这个纯递归方法就明白了。
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if(root==null)return null;//root实际上当然不为空,不过我们要递归搜索整棵树,当到达某一个叶子结点时,root会是空
if(p==root||q==root)return root;//递归当前根节点,就直接返回当前节点
//程序执行到这一步,说明递归到当前的节点,还没有找到p或者q,那么就深度优先搜索,往下继续找
TreeNode left=lowestCommonAncestor(root.left,p,q);
TreeNode right=lowestCommonAncestor(root.right,q,p);
if(left!=null&&right!=null){//这说明当前root就时q和p的最近祖先啊
return root;
}else if(left==null&&right!=null){
return right;//返回找到的那个节点
}else{
return left;//返回找到的那个节点
}
}
}诶,我想问一个问题
left和right真假的情况不是应该有4中吗,怎么代码里只有三种,left==null并且right==null这个情况去哪里了?
因为题目已经说了所给的这颗树,至少有两个节点啊,按照递归分治思想,那么left==null并且right==null这个情况是不可能出现的。
评分:
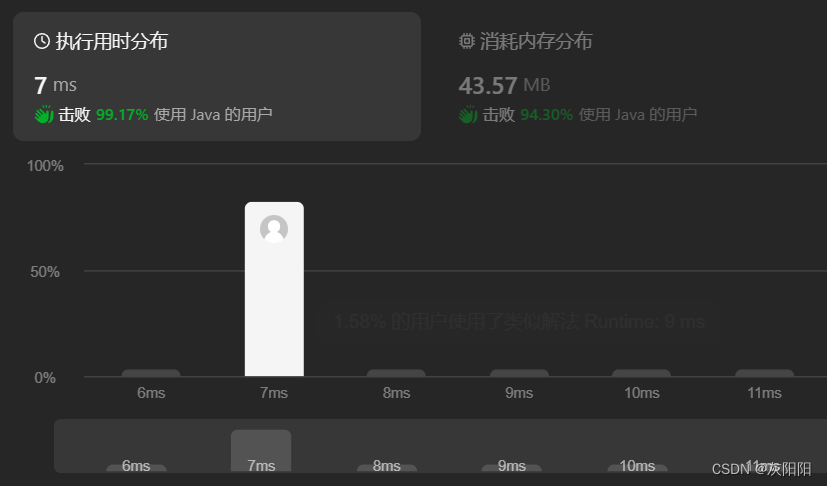
相较于解法一,高了许多















 1585
1585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









