






意识流写文,看不明白的可以之间看看结尾的结论,第一次写求轻喷
这次在写花指令的时候碰到了这样一条加密语句:
for ( i = 0; i < 29; ++i )
Str1[i] = (Str1[i] + Str1[(i * i + 123) % 21]) % 96 + 32;
if ( !j_strcmp(Str1, "~4G~M:=WV7iX,zlViGmu4?hJ0H-Q*") )
puts("right!");
else
puts("nope!");
很显然,语句Str1[i] = (Str1[i] + Str1[(i * i + 123) % 21]) % 96 + 32;就是该加密程序的主体,但在我自己尝试编写逆向程序的时候却发现了一个问题:%96这一步运算该如何逆向呢?
%运算也叫模运算,原理是取除法运算的余数,只取余数的性质导致了该运算在进行时必然会导致原文信息的丢失,比如我们知道某数与5进行模运算后的结果为3,我们只能知道该数为k · n + 3,其中k、n均未知,这也就是“丢失的信息”
卡在这里了,AI也写不出逆向脚本,搜了一下密文找到了原题WP,人居然写出了逆向脚本,不得不说AI果然永远无法取代人类~
enc = '~4G~M:=WV7iX,zlViGmu4?hJ0H-Q*'
print(len(enc))
print()
arr = []
for i in range(len(enc)):
arr.append(ord(enc[i]))
for i in range(len(arr) - 1, -1, -1):
arr[i] = arr[i] - 32 - arr[(i * i + 123) % 21]
if arr[i] < 96:
arr[i] += 96
for i in range(len(enc)):
while arr[i] < 32 or arr[i] > 128:
arr[i] += 96
arr[i] %= 128
for i in range(len(arr)):
print(chr(arr[i]), end='')
print()
print(arr)下面来逐步分析一下逆向过程:
enc = '~4G~M:=WV7iX,zlViGmu4?hJ0H-Q*'
print(len(enc))
print()
arr = []
这三条语句测定了密文的长度,格式化了一下控制台的输出,并且定义了一个名为arr的数组用于解密
for i in range(len(enc)):
arr.append(ord(enc[i]))
这里进行一个循环,将密文中的字符逐个转化为ASCII码值并存入数组arr中
for i in range(len(arr) - 1, -1, -1):
arr[i] = arr[i] - 32 - arr[(i * i + 123) % 21]
if arr[i] < 96:
arr[i] += 96
这里再进行一个循环,range(len(arr) - 1, -1, -1) ,从len(arr) - 1(即列表的最后一个元素的索引)开始,到-1(即列表的第一个元素的索引)结束,步长为-1,意味着每次迭代都会减少1 ,下面是一个执行例子:
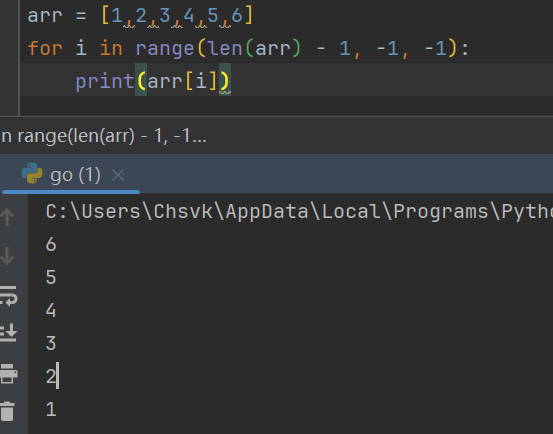
也就是说这样的循环主要时起一个反向遍历的作用
关于为什么range函数的第二个参数是-1却指向数组arr的第一个元素:
首先我们来了解一下range函数的几个参数:
range(start, stop, step)
其中start参数是包括在内的第一个数,stop参数是包括在内的最后一个数,step参数是两个数之间的差,即步长,stop参数本身是range结束的条件,而不是结束的索引,所以将start设置为len(arr)-1令开始range的数组索引为数组长度-1,即数组尾元素的索引,步长为-1,每次返回一个索引值后-1,也就是说,遍历至1时返回1,减1后为0,返回0,减1后为-1,满足stop条件,结束遍历(也就是判断stop条件的优先级是比返回值的优先级是要高的),我们也可以据此写出等价的C语言语句来帮助理解:
int i;
for(i=strlen(arr);i>-1;i--){
······································
}
我们继续脚本的分析:
arr[i] = arr[i] - 32 - arr[(i * i + 123) % 21]
这里是对加密主体的逆向,我们对比原加密语句:
Str1[i] = (Str1[i] + Str1[(i * i + 123) % 21]) % 96 + 32;
原语句的计算详解:
计算i*i+123,结果与21取余(确保值不超过21)作为处理对象的数组索引,再与索引为i的数组元素相加(指ASCII码值相加),结果与96取余(确保值不超过96),再加上32,最后存入索引为i的数组元素
逆向计算详解:
对已经转换为ASCII码值的数组,从最后一个对象开始,先计算i*i+123%21的值,再依次以该对象作为被减数,减去32和arr[i*i+123%21]的ASCII码值
为什么这么做:
我们注意到,原加密语句是对特定索引对象的值的运算加密,并没有更换了这个索引的值,也就是说,我们可以通过密文值的索引知悉与他进行运算的对象的索引值,即arr[i]总是与arr[i*i+123%21]进行运算
减去32,逆向至Str1[i] = (Str1[i] + Str1[(i * i + 123) % 21]) % 96
减去arr[(i * i + 123) % 21]:
这里引入一下模运算的特殊性质:
令:@符为+-*/中的任意一种
则有:
(a @ b) % n = (a % n @ b % n) % n
再来回顾我们的解密思路:
逆向至Str1[i] = (Str1[i] + Str1[(i * i + 123) % 21]) % 96这一步,我们期望能够逆向“%96”这个运算,但实际上并不存在这样一种运算
我们假设存在运算#,它是%运算的逆运算,那么它将具有%运算的性质
那么我们想要的语句即为:
arr[i] = arr[i] # 96 - arr[(i * i + 123) % 21]
同时我们应注意到的是:
在大多数编程语言中,包括Python、Java、C、C++等,数学运算符(如加法+、减法-、乘法*、除法/等)的优先级高于百分比运算符%。这意味着当一个表达式中同时包含这些运算符时,数学运算符会首先被计算。
注意到:
在原加密中(Str1[i] + Str1[(i * i + 123) % 21]) % 96 + 32;
加法部分是被括起来的(不影响优先级),而我们的期望逆向语句中:
arr[i] = arr[i] # 96 - arr[(i * i + 123) % 21]
是没有括号的,也就是说在这条语句的实际执行情况下,是会先计算
- arr[(i * i + 123) % 21]部分的,也就是#部分的逆向我们可以后置不管
继续我们的分析:
if arr[i] < 96:
arr[i] += 96
这里的if语句判断我们计算后的结果是否小于96,否则加96,以确保接下来对%96的逆向过程正常进行
for i in range(len(enc)):
while arr[i] < 32 or arr[i] > 128:
arr[i] += 96
arr[i] %= 128
这里是解密的关键部分,for条件设置为遍历数组的长度(即i的值从1到字符串的长度值之间递增)
对于while部分:如果arr[i]的值小于32或者大于128,则将其加96或与128取余, 以确保每个 ASCII 值在可打印字符的范围内(32 至 128)
总的来说,对于取模运算的逆向,在没有逆运算符存在的情况下,我们需要利用模运算的特点,即取余出来的这个数一定是原数的“特征”,这个“特征数”加上n个模数一定能够得到原数,利用这一特点进行逆向即可
如何防止得不到原数?就是上面的while语句的作用















 2711
2711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









