






哈希表理论基础
哈希表是根据关键码的值而直接进行访问的数据结构。
在 Python 中,哈希表可以通过多种数据结构来实现,其中包括数组、集合和字典。这些数据结构在不同的场景下可以用作哈希表的实现。
拿数组为例,哈希表中关键码就是数组的索引下标,然后通过下标直接访问数组中的元素。
使用哈希表解决什么问题
一般哈希表都是用来快速判断一个元素是否出现集合里,以及解决冲突,又称哈希碰撞,指的是指的是两个或多个键被映射到了相同的槽位上。
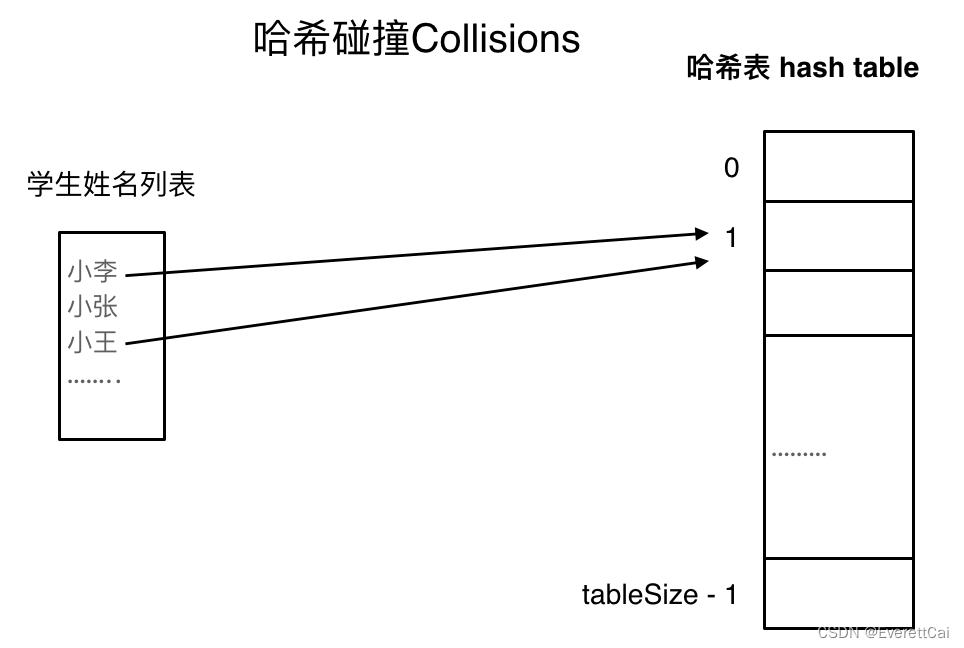
哈希碰撞解决办法
拉链法
哈希表的每个槽位维护一个链表(或其他数据结构),用于存储冲突的元素。当发生冲突时,新的元素会被添加到对应槽位的链表中。这样,每个槽位上可以存储多个元素。在查找元素时,首先根据键的哈希值找到对应的槽位,然后在链表中顺序查找目标元素。
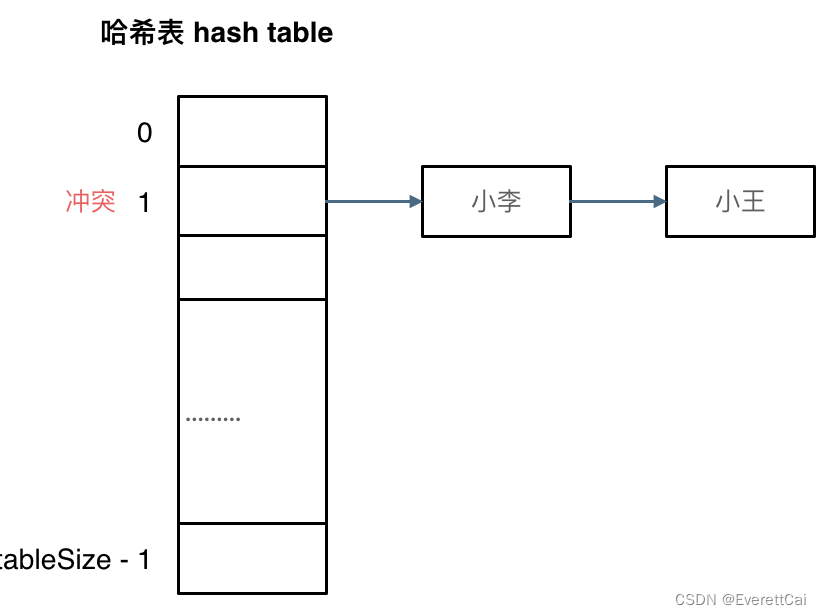
但拉链法的的存在并不意味着我们不用在意哈希表的tablesize和数据规模datasize了,我们依旧要选择适当的哈希表的大小,这样既不会因为数组空值而浪费大量内存,也不会因为链表太长而在查找上浪费太多时间。
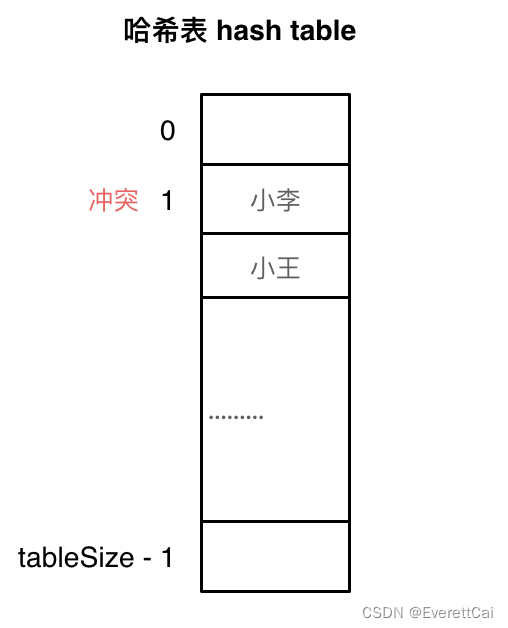
线性探测法
当发生冲突时,会在哈希表的下一个槽位中寻找空闲的位置来存储冲突的元素。如果下一个槽位也被占用了,就继续往后寻找,直到找到空槽位。在查找元素时,根据键的哈希值找到初始槽位,然后依次探测下一个槽位,直到找到目标元素或者遇到空槽位。使用线性探测法,一定要保证tableSize大于dataSize。 我们需要依靠哈希表中的空位来解决碰撞问题。
242. 有效的字母异位词
此题方法多样,均可以尝试。从哈希表角度想,就是去找一个key对value的关系形式来访问数据。由于输入的s和t是字符串,我们可以从数组的索引和值关系来入手。
我们可以利用ord()函数来返回字符对应的ASCII值,我们将其作为count链表里的索引,方便我们访问;因为本题s和t只包含小写,因此我们可以设置一个长度为26的链表,来对出现的字母进行计数。收集完s的出现字母后,由于字母异位词满足每个字符出现的次数都相同的条件,因此两个字符串收集完字母的count应该是一样的,意味着我们用收集完s的count,若在t中找到相同字母,减去其数值,最后,count里全是0则两个字符串是字母异位词 。
# 数组
class Solution:
def isAnagram(self, s: str, t: str) -> bool:
count=[0]*26
# 要为count设置长度,是因为count计数不是按照索引顺序计入的,而是跳着计入的
# 当列表是一个空列表,尝试通过索引操作对列表中的元素进行增减时,会引发IndexError,因为列表中没有对应的索引位置。
for i in s:
count[ord(i)-ord('a')]+=1 # 把字符转换成对应ASCII值作为count的索引,记录出现的次数
for i in t:
count[ord(i)-ord('a')]-=1 # 把字符转换成对应ASCII值作为count的索引,抵消之前字符串里各字母出现的次数
for k in range(26):
if count[k]!=0: # 若出现非0的数值,则说明两个字符串有的字符出现次数不同
return False
return True
同理,既然数组可以实现哈希表,那么按照我们之前说的字典和集合也可以实现。字典由于是无序的数据结构,因此不必像链表那样要按照索引顺序去探索,也就不必初始化链表长度,防止out of range。
# 字典
class Solution:
def isAnagram(self, s: str, t: str) -> bool:
count=dict()
for i in s:
count[ord(i)-ord('a')]=count.get(ord(i)-ord('a'),0)+1
for i in t:
count[ord(i)-ord('a')]=count.get(ord(i)-ord('a'),0)-1
for value in count.values():
if value!=0:
return False
return True
文章还介绍了两个defaultdict和Counter两个解题思路,defaultdict和字典思路相似。
defaultdict 在创建时需要传入一个默认工厂函数,用于提供默认值。当访问字典中不存在的键时,defaultdict 会自动使用默认工厂函数生成一个默认值,并将其关联到该键上。
class Solution:
def isAnagram(self, s: str, t: str) -> bool:
from collections import defaultdict # 导入defaultdict函数
sdict=defaultdict(int)
tdict=defaultdict(int)
# 创建一个默认值为0的 defaultdict
for i in s:
sdict[i]+=1 # 出现某个字母就+1,最后每个数字对应其总的出现频率
for i in t:
tdict[i]+=1
if sdict==tdict: # 若每个字符串出现频率一致,是字母异位词
return True
else: return False
Counter用于计数可哈希对象的出现次数。它是 dict 的一个子类,可以接受可迭代对象作为输入,并返回一个字典,其中包含了每个元素及其出现的次数。
class Solution:
def isAnagram(self, s: str, t: str) -> bool:
from collections import Counter
c1=Counter(s)
c2=Counter(t)
# print出来类似于Counter({'a': 3, 'n': 1, 'g': 1, 'r': 1, 'm': 1}),就是一个字典,所以采用和defaultdict一样的字典结果比较方法。
return Counter(s)==Counter(t)
349. 两个数组的交集
Leetcode 349 原题链接
考虑到此题要求结果中的每个元素一定是唯一 的(不重复)。那么我们可以使用集合(set)来解决这个问题。
最简单的办法无疑是用set处理完列表后,返回他们的交集,并转换成列表(list)。
class Solution:
def intersection(self, nums1: List[int], nums2: List[int]) -> List[int]:
return list(set(nums1)&set(nums2))
还一个办法就是用字典和集合(字典确实是一个实现哈希表的好的数据结构!!!)
class Solution:
def intersection(self, nums1: List[int], nums2: List[int]) -> List[int]:
table={} # 创造一个字典
for num in nums1:
table[num]=table.get(num,0)+1 # 对每个数字进行计数,非0即出现
joint=set() # 创造收集交集的集合
for num in nums2:
if num in table:
joint.add(num) # 说明两个列表都有这个数,收集起来
del table[num] # joint里有了就直接删掉,其实不删也行,因为set不会对重复元素计入,但如果是joint是List必须删掉
return list(joint)
class Solution:
def intersection(self, nums1: List[int], nums2: List[int]) -> List[int]:
table={}
for num in nums1:
table[num]=table.get(num,0)+1
joint=[] # 和集合差别就在于这里直接创造一个列表
for num in nums2:
if num in table:
joint.append(num)
del table[num]
# table[num]-=1会导致多次出现的重复数值在被删除后,再下一次循环还会在被计入joint,由于joint不是集合set,重复元素会被计入。
return joint
数组在这题也可行,因为题目给定了0 <= nums1[i], nums2[i] <= 1000。但若道题目没有限制数值的大小,就无法使用数组来做哈希表了。而且如果哈希值比较少、特别分散、跨度非常大,使用数组就造成空间的极大浪费。
class Solution:
def intersection(self, nums1: List[int], nums2: List[int]) -> List[int]:
count1=[0]*1001 # 由于会用有的数字作为索引,对应的value为其出现频率,因此要初始化链表长度
count2=[0]*1001
for num in nums1:
count1[num]+=1
for num in nums2:
count2[num]+=1
joint=[]
for i in range(1001):
if count1[i]*count2[i]>0: # 若乘积为0,说明至少一方出现次数为0,也就是并不是在两个列表中都出现过
joint.append(i)
return joint
202. 快乐数
写起来挺快乐的,呵呵。
「快乐数」 定义为:
- 对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。
- 然后重复这个过程直到这个数变为1,也可能是无限循环但始终变不到1
- 如果这个过程结果为1,那么这个数就是快乐数。
无限循环的判定需要稍微想一想。要想无限循环,一定是数字平方和一直等于除1以外的值,但既然是无限,就说明中间一定是出现过重复的数字平方和,才会一直变不到1。因此,我们可以收集循环过程中的数字平方和,若循环过程中出现了以往出现过的数字平方和,那么自然这个数就不是快乐数了。而当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法了。
这道题目使用哈希法,来判断这个sum是否重复出现,如果重复了就是return false, 否则一直找到sum为1为止。所以,循环的条件就是,目前的n未出现在记录里或者目前的n不等于1,具体代码根据设置循环条件而变。
class Solution:
def isHappy(self, n: int) -> bool:
record=[] # 创造一个记录出现过的数字平方和的列表
while n not in record:
record.append(n)
sum=0
for i in str(n):
sum+=int(i)**2
if sum==1: return True
else: n=sum
return False
class Solution:
def isHappy(self, n: int) -> bool:
record=set()
while n not in record:
record.add(n)
sum=0
for i in str(n):
sum+=int(i)**2
if sum==1: return True
else: n=sum
return False
上述判断循环的条件是数字平方和是否在记录里,或者我们可以直接判断数字平方和是否为1,不是的话继续循环,同时保留记录出现过的数字平方和的思路,若循环过程出现已出现的数字平方和,return FALSE
class Solution:
def isHappy(self, n: int) -> bool:
seen=[]
while n!=1:
n=sum(int(i) ** 2 for i in str(n)) # 直接更新n为数字平方和
if n in seen:
return False
else: seen.append(n)
return True
class Solution:
def isHappy(self, n: int) -> bool:
seen=set()
while n!=1:
n=sum(int(i)**2 for i in str(n))
if n not in seen:
seen.add(n)
else: return False
return True
1. 两数之和
如果不要求方法的话,很简单的一题,但如果要用哈希法解决的话,需要搞清楚key和value在此题到底分别对应什么。
土办法就是双重for:
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
for i in range(len(nums)):
for j in range(i+1, len(nums)):
if nums[i] + nums[j] == target:
return [i,j]
本题要我们返回的是index,但是是通过比较对应的value来判断返回的索引的。如果我们尝试使用数组的方法去写的话,最差的情况也是遍历完整个数组,因为数组是有序的,需要按照顺序去访问。所以应该用字典或集合来做。
# 字典
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
records={}
for index,num in enumerate(nums):
# records[num]=index在这里加上这句反而会导致错误
# 假如target-num=num,即target是num两倍
# 如果先执行把num:index计入字典,再查找互补数,那么会导致系统判定当前数字是互补数,又返回来当数字。那么它会把一个数字重复计算两次,违背题意
if target-num in records:
return [records[target-num],index]
records[num]=index
return []
# 集合
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
record=set()
for i,num in enumerate(nums):
if target-num in record:
return [nums.index(target-num),i]
# list.index(value)用于在列表中寻找目标value对应的索引index
record.add(num)
return []
提高双指针法作为参考
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
# 对输入列表进行排序
nums_sorted = sorted(nums)
# 使用双指针
left = 0
right = len(nums_sorted) - 1
while left < right:
current_sum = nums_sorted[left] + nums_sorted[right]
if current_sum == target:
# 如果和等于目标数,则返回两个数的下标
left_index = nums.index(nums_sorted[left])
right_index = nums.index(nums_sorted[right])
if left_index == right_index:
right_index = nums[left_index+1:].index(nums_sorted[right]) + left_index + 1
# 加入两个数字分别在index=4,7位置,从第一个数字之后开始往后看,索引为[5,7],对应为[0,2],因此右边数字索引为4+2+1=7
return [left_index, right_index]
elif current_sum < target:
# 如果总和小于目标,则将左侧指针向右移动
left += 1
else:
# 如果总和大于目标值,则将右指针向左移动
right -= 1
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









