



spark是什么?
Apache Spark™ is a multi-language engine for executing data engineering, data science, and machine learning on single-node machines or clusters.(Apache Spark™是一个多语言引擎,用于在单节点机器或集群上执行数据工程、数据科学和机器学习)
Spark和Hadoop MapReduce的区别
共同点:都是两种常用的大数据处理框架
-
内存计算能力:Spark具有内存计算能力,可以将数据存储在内存中进行快速计,而MapReduce则需要将数据写入盘,导致开销较大。
-
运行速度:由于Spark的内存计算能力,相对于MapReduce它可以更快地处理大规模数据。Spark采用了弹性分布式数据集(RDD)的概念,可以在内存中缓存数据,从而避免了磁盘IO的开销。Spark的运行速度是Hadoop MapReduce运行速度的100多倍。一般情况下,对于迭代次数较多的应用程序
内存运行速度 磁盘运行速度 spark 100x 10x Hadoop MapRrduce x x -
编程模型:Spark提供了更为灵活的编程模型,支持多种编程语言(如Scala、Java、Python和R),并且提供了丰富的高级API(如Spark SQL、Spark Streaming和MLlib等),使得开发者可以更方便地进行数据处理和分析。而MapReduce则需要使用Java编程语言,并且编写Map和Reduce函数。
-
数据处理方式:Spark支持多种数据处理方式,包括批处理、交互式查询和流式处理等,而MapReduce主要用于批处理任务。
-
容错性:Spark具有更好的容错性,当节点发生故障时,可以快速恢复并继续执行任务。而MapReduce需要将中间结果写入磁盘,导致容错性较差。
结构化和非结构化,半结构化数据是什么?
1.结构化数据:即行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据。
2.非结构化数据:不方便用数据库二维逻辑表来表现的数据,包括所有格式的办公文档、文本、图片、XML、HTML、各类报表、图像和音频/视频信息等等。
3.半结构化数据:就是介于完全结构化数据(如关系型数据库、面向对象数据库中的数据)和完全无结构的数据(如声音、图像文件等)之间的数据,HTML文档就属于半结构化数据。它一般是自描述的,数据的结构和内容混在一起,没有明显的区分。
spark通用性指的什么?
Spark SQL(即席查询),Spark Streaming(实时流处理),Spark MLlib(机器学习库),Spark GraphX(图计算)

spark 的组件

1 Spark Core
包含了Spark的基本功能,包含任务调度,内存管理,容错机制等等。
内部定义了RDD(弹性分布式数据集)
提供了很多APIs来创建和操作这些RDD
应用场景:为其他组件提供底层的服务
2 Spark SQL
是Spark处理结构化数据的库,就像Hive SQL,Mysql一样。
应用场景:企业中用来做报表统计
3 Spark Streaming
是实时数据流处理组件,类似Storm
Spark Streaming提供了API操作实时流数据
应用场景:企业中用来从Kafka接收数据做实时统计。
4 Mlib
一个包含通用机器学习功能的包,Machine learning lib
包含分类、聚类、回归等,还包括模型评估和数据导入。
MLib提供的上面这些方法,都支持集群上的横向扩展。
应用场景:机器学习
5 Graphx
是处理图的库(例如,社交网络图),并进行图的并行计算。
像Spark Streaming,Spark SQL一样,它也继承了RDD API。
它提供了各种图的操作,和常用的图算法,例如PangeRank算法。
应用场景:图计算。
6 Cluster Managers
就是集群管理,Spark自带一个集群管理是单独调度器。
常见集群管理包括Hadoop YARN,Apache Mesos
运行模式
1.standalone模式
与MapReduce1.0框架类似,Spark框架本身也自带了完整的资源调度管理服务,可以独立部署到一个集群中,而不需要依赖其他系统来为其提供资源管理调度服务。在架构的设计上,Spark与MapReduce1.0完全一致,都是由一个Master和若干个Slave构成,并且以槽(slot)作为资源分配单位。不同的是,Spark中的槽不再像MapReduce1.0那样分为Map 槽和Reduce槽,而是只设计了统一的一种槽提供给各种任务来使用。
2.Spark on Mesos模式
Mesos是一种资源调度管理框架,可以为运行在它上面的Spark提供服务。Spark on Mesos模式中,Spark程序所需要的各种资源,都由Mesos负责调度。由于Mesos和Spark存在一定的血缘关系,因此,Spark这个框架在进行设计开发的时候,就充分考虑到了对Mesos的充分支持,因此,相对而言,Spark运行在Mesos上,要比运行在YARN上更加灵活、自然。目前,Spark官方推荐采用这种模式,所以,许多公司在实际应用中也采用该模式。
3.Spark on YARN模式
YARN是一种统一资源管理机制,在其上面可以运行多套计算框架。目前的大数据技术世界,大多数公司除了使用Spark来进行数据计算,由于历史原因或者单方面业务处理的性能考虑而使用着其他的计算框架,比如MapReduce、Storm等计算框架。Spark基于此种情况开发了Spark on YARN的运行模式,由于借助了YARN良好的弹性资源管理机制,不仅部署Application更加方便,而且用户在YARN集群中运行的服务和Application的资源也完全隔离,更具实践应用价值的是YARN可以通过队列的方式,管理同时运行在集群中的多个服务。
YARN模式
Spark on YARN模式根据Driver在集群中的位置分为两种模式:一种是YARN-Client模式,另一种是YARN-Cluster(或称为YARN-Standalone模式)
一.YARN-Client模式(YARN客户端模式)的作业运行流程及解说
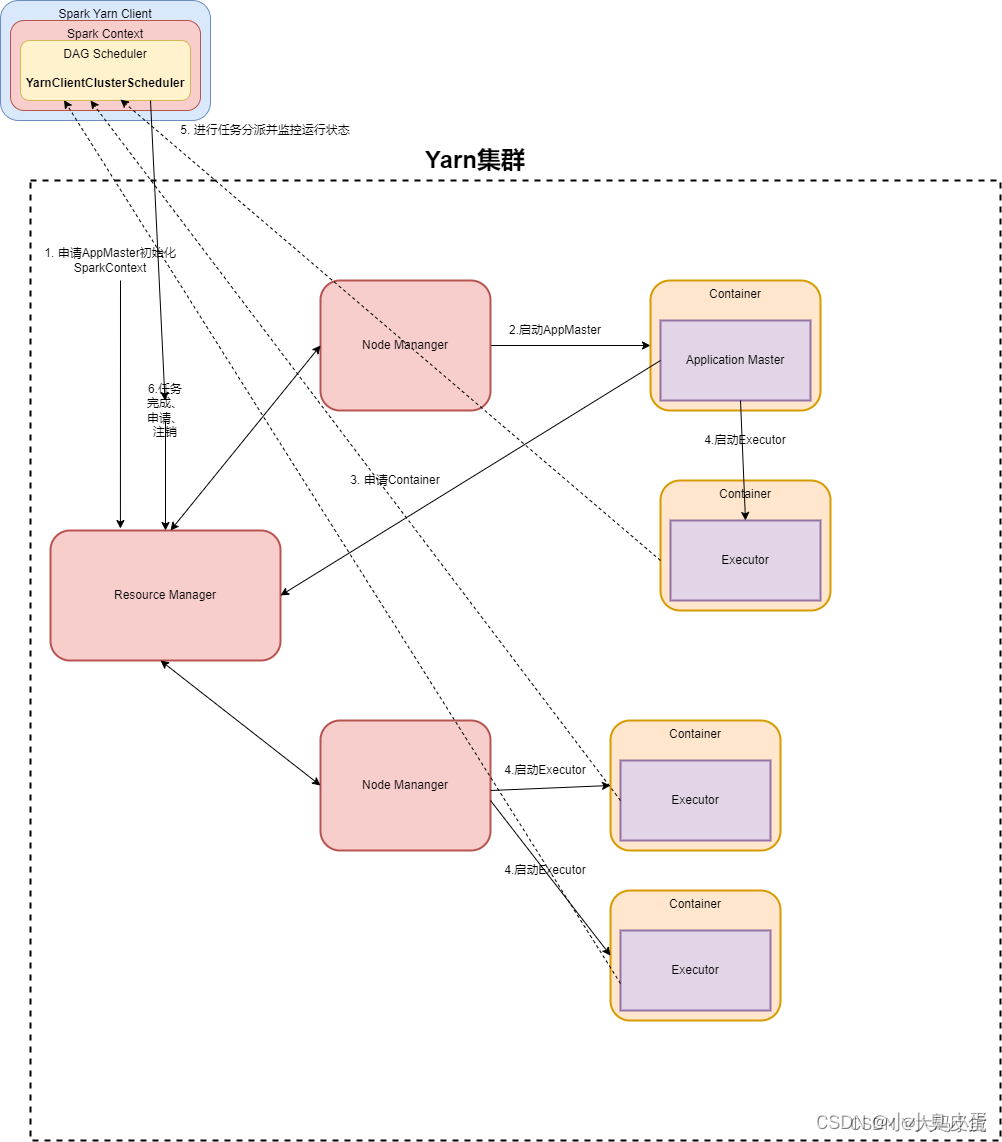
ResourceManager=年级主任 NodeManager=班主任
Application Master=实习班主任 小美 Executor=其他实习班主任小帅
其工作流程如下:
1.校长(客户端) 分配任务给年级主任(resourcemanager)
2.yarn框架的年级主任指定某个班主任启动container,并且将实习生小美分配给了某个班主任
3.某个班主任收到年级主任的分配后,告知并启动实习生小美并初始化作业,此时的某个班主任成为DRIVER
4.实习生小美向年级主任申请资源,在年级主任分配资源的同时还要通知其他实习生班主任小帅,并启动学生(executor)
5.学生向本地启动的实习班主任小美注册汇报并完成相应内容
二.YARN-Cluster
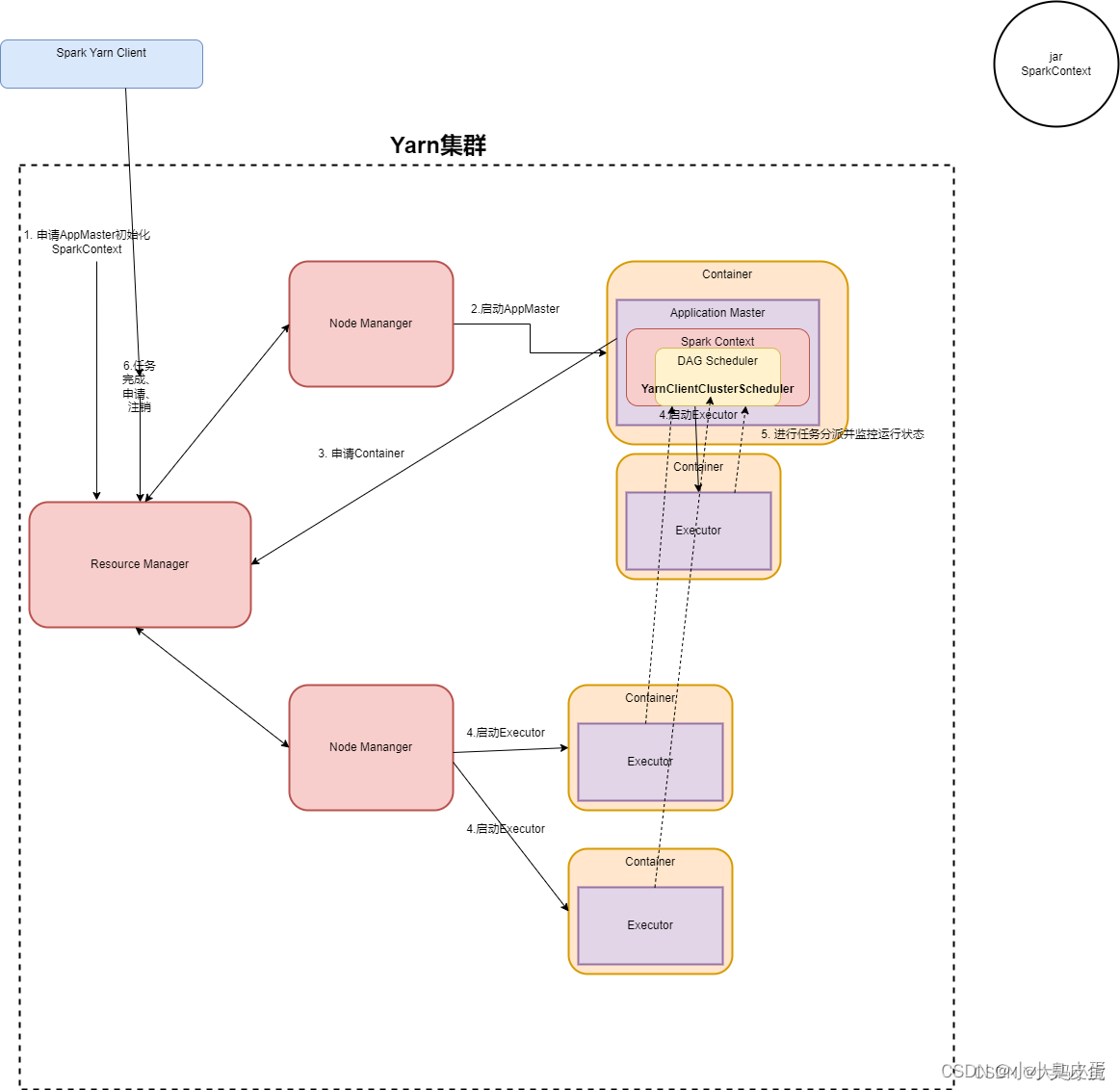
1.校长(客户端) 分配任务给年级主任(resourcemanager)
2.yarn框架的年级主任指定某个班主任启动container,并且将实习生小美分配给了某个班主任
3.某个班主任收到年级主任的分配后,告知并启动实习生小美并初始化作业,此时的某个班主任成为DRIVER
4.实习生小美向年级主任申请资源,在年级主任分配资源的同时还要通知其他实习生班主任小帅,并启动学生(executor){以上流程和客户端模式一样}
5.学生最后向班主任一起的实习班主任小美进行注册回报并完成任务(和客户端区别于一个是向本地方的实习班主任小美(application master),一个是向与班主任一起的小美。
Spark 核心原理
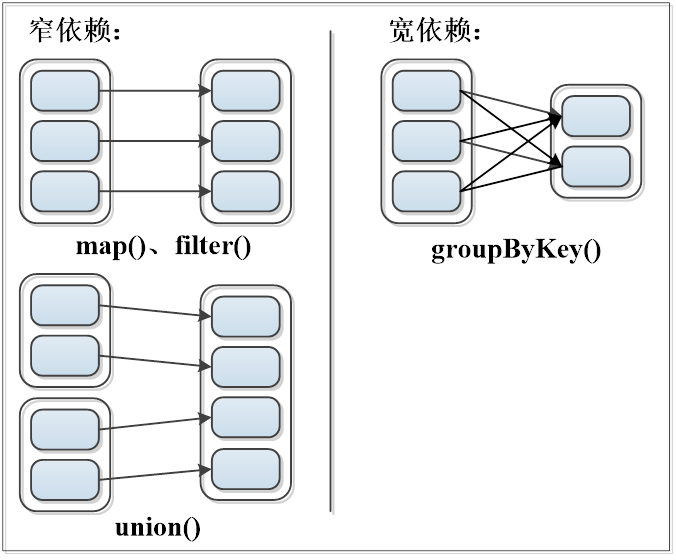
stage
spark中还有一个重要概念stage
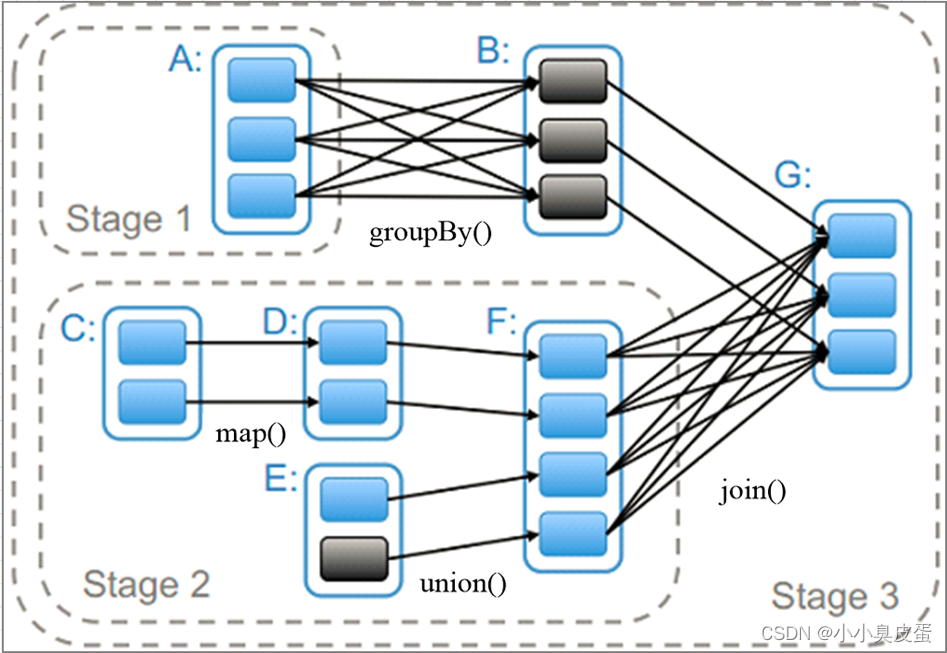
如图中stage1(RDDA)
stage2(RDDC,RDDD,RDDE,RDDF)
stage3(RDD)
Stage划分的依据是?
spark遇到宽依赖则划分一个Stage,遇到窄依赖则将这个RDD的操作加入到该stage,Shuffle操作定义于stage边界。

















 751
751




 到【灌水乐园】发言
到【灌水乐园】发言







